参考
https://niyanchun.com/flink-quick-learning-6-operators.html
https://blog.csdn.net/a3125504x/article/details/108648709
任务之间的传输形式
任务之间的数据传递形式既有默认的,也有自己通过API设定的。
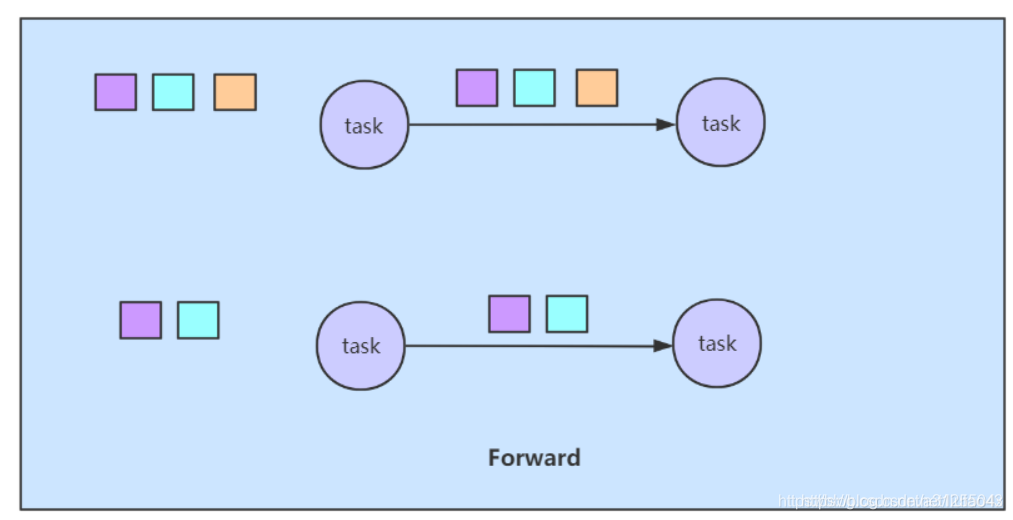
forward strategy(One-to-One)
一个task的输出只发送给一个task作为输入
如果两个task都在一个JVM中的话,那么就可以避免网络开销
一般以下算子就是这样:
map/flatmap:使用最多的算子,map是输入一个元素,输出一个元素;flatmap是输入一个元素,输出0个或多个元素。
filter:过滤,条件为真就继续往下传,为假就过滤掉了。
reduce算子:在KeyedStream上面使用,“滚动式”的操作流中的元素。
source和map、flatmap之间就是采用的是forward strategy。sum和sin之间也是。
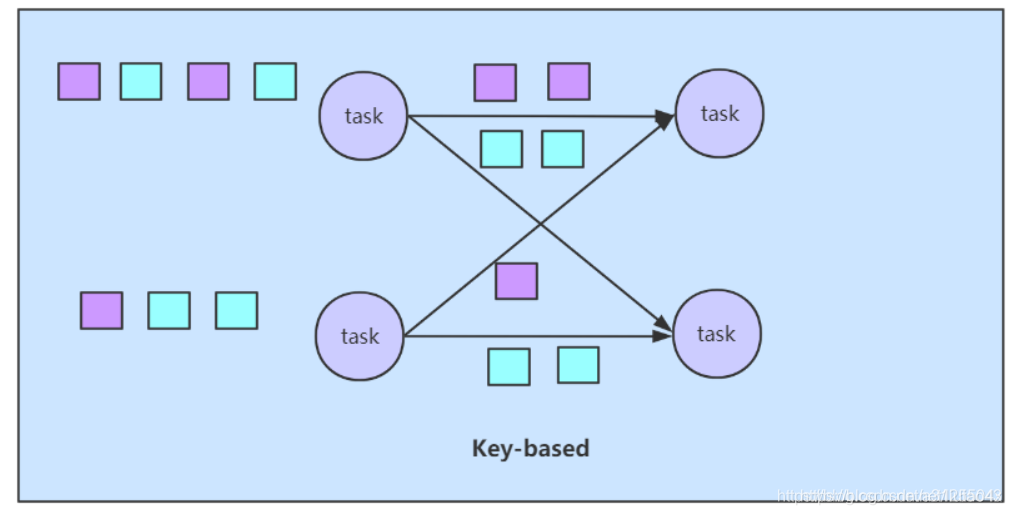
key-based strategy(Redistributing)
Redistributing就是的说流的分区会发生改变,每一个算子的子任务一句所选择的transformation发送数据到不同的目标任务。例如,keBy基于hashCode重分区,broadcast和rebanlance都会引起重分区。
即基于键值的策略
- 数据需要按照某个属性(我们称为 key)进行分组(或者说分区)
- 相同key的数据需要传输给同一个task,在一个task中进行处理
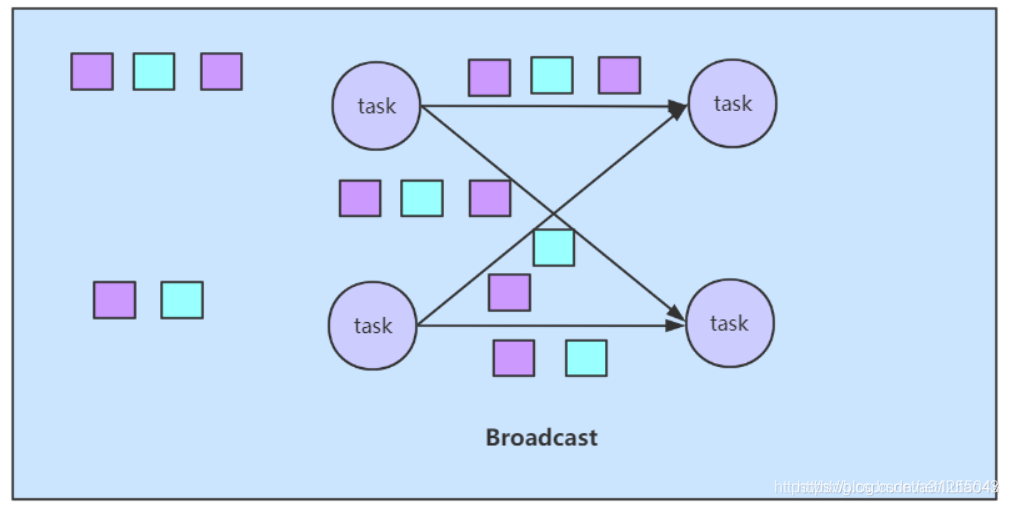
broadcast strategy(Redistributing)
即广播策略
数据随机的从一个task中传输给下一个operator所有的subtask。因为这种策略涉及数据复制和网络通信,所以成本相当高。
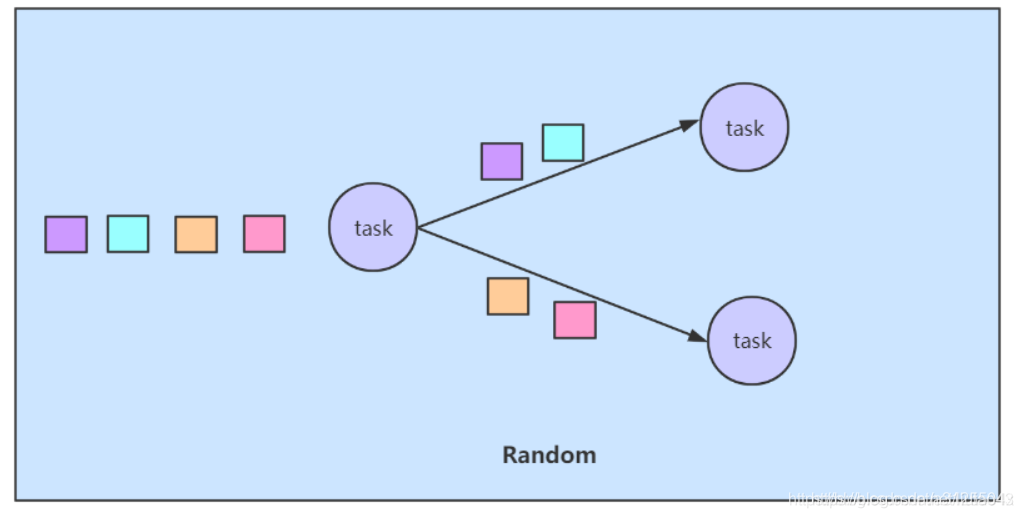
random strategy(Redistributing)
即随机策略,对应着就是rebanlance
数据随机的从一个task中传输给下一个operator所有的subtask
保证数据能均匀的传输给所有的subtask,以便在任务之间均匀地分配负载
总结
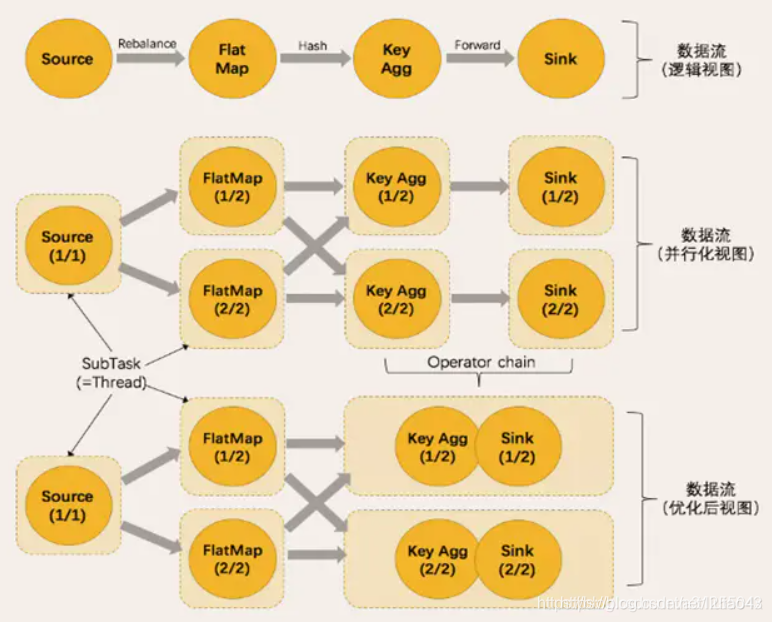
这些分区其实在web界面上能看见,其中source和map之间如果并行度相同就是one-to-one,但是不同一般就是rebanlance,sum和sink也是如此,所以大部分的操作原则上是one-to-one,但是并行度不同就不可能是one-to-one,要具体问题具体分析。
而且keyBy操作就不能算是一个任务,sum算子一般都是和别的算子一起使用,下图中的HASH对应的就是keyBy,keyBy只能算数据传输方式,所以不能设置并行度。。。。只有任务才能设定并行度。
Operator Chain
什么是Operator Chain?
就是将一些独立的小Operator合并为一个大的Operator,比如将Source和FlatMap合并在一起。
合并(chain)的条件是什么?
简单理解就是如果两个算子的数据是直接Forward,在同一个slot组并且并行度一致,那就可以合并。反过来,如果两个Operator之间有shuffle(比如keyBy)、rebalance(比如并行度不一样)之类的操作,或者一个Operator有多个上游(就是有多个operator),那就不能合并。实际使用的时候,我们一般尽量让整个系统里面的算子并行度一致即可,这样能够合并的一般都会合并。
合并的好处是什么?
Flink运行的时候,一个任务是在一个线程里面运行的,将小的Operator合并成大的Operator,也就相当于将小任务合并成了大任务,这样他们就会在一个线程里面执行,避免了网络IO和序列化操作,同时也减少了线程数。
下图中的KeyAgg和Sink之间是forword,并且并行度相同,所以就可以合并,反之,source共和map原则上也是forward可以合并的,但是并行度不同,所以source和map之间的数据传输方式就变成了rebalance,所以就不能合并。