一、前言
Lucene 是 apache 软件基金会的一个子项目,由 Doug Cutting 开发,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的库,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene 的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene 是一套用于全文检索和搜寻的开源程式库,由 Apache 软件基金会支持和提供。
Lucene 提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在 Java 开发环境里 Lucene 是一个成熟的免费开源工具。就其本身而言,Lucene 是当前以及最近几年最受欢迎的免费 Java 信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
最开始 Lucene 只由 java 开发,供 java 程序调用,随着 python 越来越火,Lucene 官网也提供了 python 版本的 lucene 库,供 python 程序调用,即 PyLucene。
二、什么是全文检索
全文检索技术被广泛的应用于搜索引擎,查询检索等领域。我们在网络上的大部分搜索服务都用到了全文检索技术。
对于数据量大、数据结构不固定的数据可采用全文检索方式搜索,比如百度、Google等搜索引擎、论坛站内搜索、电商网站站内搜索等。
全文数据库是全文检索系统的主要构成部分。所谓全文数据库是将一个完整的信息源的全部内容转化为计算机可以识别、处理的信息单元而形成的数据集合。全文数据库不仅存储了信息,而且还有对全文数据进行词、字、段落等更深层次的编辑、加工的功能,而且所有全文数据库无一不是海量信息数据库。
非结构化数据的查询方法
结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
非结构化数据:指不定长或无固定格式的数据,如邮件,word文档等磁盘上的文件。
非结构化数据查询有两种办法:
(1)顺序扫描法(Serial Scanning)
所谓顺序扫描,比如要找内容包含某一个字符串的文件,就是一个文档一个文档的看,对于每一个文档,从头看到尾,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,直到扫描完所有的文件。如利用windows的搜索也可以搜索文件内容,只是相当的慢。
(2)全文检索(Full-text Search)
将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引。
例如:字典。字典的拼音表和部首检字表就相当于字典的索引,对每一个字的解释是非结构化的,如果字典没有音节表和部首检字表,在茫茫辞海中找一个字只能顺序扫描。然而字的某些信息可以提取出来进行结构化处理,比如读音,就比较结构化,分声母和韵母,分别只有几种可以一一列举,于是将读音拿出来按一定的顺序排列,每一项读音都指向此字的详细解释的页数。我们搜索时按结构化的拼音搜到读音,然后按其指向的页数,便可找到我们的非结构化数据——也即对字的解释。
这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
虽然创建索引的过程也是非常耗时的,但是索引一旦创建就可以多次使用,全文检索主要处理的是查询,所以耗时间创建索引是值得的。
那么如何实现全文检索呢?
三、Lucene
提到全文检索,不得不提到的一个技术就是Lucene,Lucene是apache下的一个开放源代码的全文检索引擎工具包。提供了完整的查询引擎和索引引擎,部分文本分析引擎。我们所熟知的全文检索引擎Solr和ES都是基于Lucene的。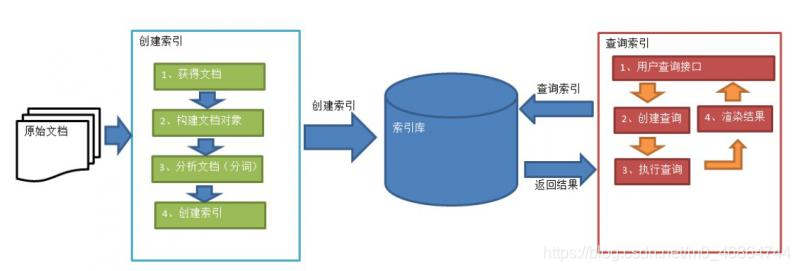
1、绿色表示索引过程,对要搜索的原始内容进行索引构建一个索引库,索引过程包括:
确定原始内容即要搜索的内容->采集文档->创建文档->分析文档->索引文档
2、红色表示搜索过程,从索引库中搜索内容,搜索过程包括:
用户通过搜索界面->创建查询->执行搜索,从索引库搜索->渲染搜索结果。
创建索引
也就是对文档索引的过程,将用户要搜索的文档内容进行索引,索引存储在索引库(index)中。
我们要分析文档中所有的单词,将单词、文档名建立映射关系。
(对于单词的切分包括了对原始文档提取单词、去除停用词等过程,这个过程被称为分词)
我们分析一篇文档Lucene.txt:
原文档内容:
Lucene is a Java full-text search engine. Lucene is not a complete
application, but rather a code library and API that can easily be used
to add search capabilities to applications.
我们可以分析后得到语汇单元:
lucene、java、full、search、engine。。。。
另一个文档flink.txt加入几个单词:
java flink kakfa
我们也可以得到语汇单元:
java flink kakfa
这样我们就建立了映射关系,lucene、java、full、search在Lucene.txt中,而flink不在Lucene.txt中,但是在flink.txt中。java即在Lucene.txt中,也在flink.txt中。
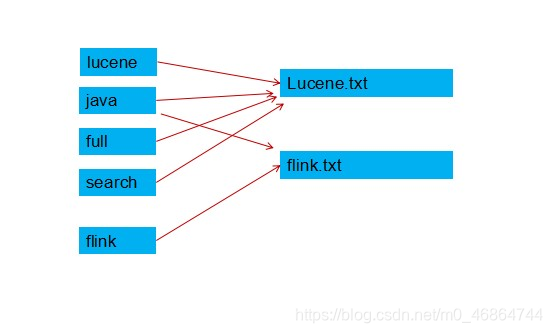
那当我们查找lucene这个词,就在Lucene.txt中,但是查找java时可以获悉其在这两个文件中。
创建索引是对语汇单元索引,通过词语找文档,这种索引的结构就叫做叫倒排索引结构。
传统方法是根据文件找到该文件的内容,在文件内容中匹配搜索关键字,这种方法是顺序扫描方法,数据量大、搜索慢。
倒排索引结构是根据内容(词语)找文档,如下图:
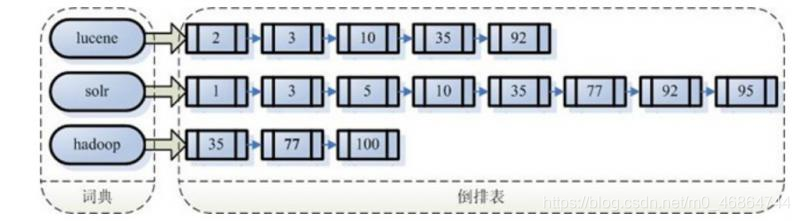
倒排索引结构也叫反向索引结构,包括索引和文档两部分,索引即词汇表,它的规模较小,而文档集合较大。
有倒排索引,对应肯定,有正向索引。 正向索引其实就是顺序扫描所有文件,这样本身效率是极低的。
查询索引
查询索引也是搜索的过程。搜索就是用户输入关键字,从索引(index)中进行搜索的过程。根据关键字搜索索引,根据索引找到对应的文档,从而找到要搜索的内容(这里指磁盘上的文件)。
我们这里就是通过查询索引表,找到文档所在的位置,就完成了查询,但其他的场景可以灵活的把查询出来的结果展示出去,比如我们的百度搜索时,为我们展示的是相关网页。
四、Lucene简单实例
<dependencies>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>5.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>5.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>5.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-smartcn</artifactId>
<version>5.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
<version>5.3.1</version>
</dependency>
</dependencies>
创建索引的简单实例
package com.lilike.music.lucene;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.IntField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.nio.file.Paths;
@Component
public class LuceneIndexer {
private final static String INDEX_DIR = "D:\\lucene";
private LuceneIndexer(){
}
private static class SingletonHolder{
private final static LuceneIndexer instance=new LuceneIndexer();
}
public static LuceneIndexer getInstance(){
return SingletonHolder.instance;
}
public boolean createIndex(String indexDir) throws IOException {
//加点测试的静态数据
Integer ids[] = {1 , 2 , 3 , 4};
String titles[] = {"九月十日即事","九日齐山登高","菊花","过故人庄"};
String tcontents[] = {
"昨日登高罢,今朝更举觞。\n" +
"菊花何太苦,遭此两重阳?",
"江涵秋影雁初飞,与客携壶上翠微。\n" +
"尘世难逢开口笑,菊花须插满头归。\n" +
"但将酩酊酬佳节,不用登临恨落晖。\n" +
"古往今来只如此,牛山何必独霑衣",
"待到秋来九月八,我花开后百花杀。\n" +
"冲天香阵透长安,满城尽带黄金甲。",
"故人具鸡黍,邀我至田家。\n" +
"绿树村边合,青山郭外斜。\n" +
"开轩面场圃,把酒话桑麻。\n" +
"待到重阳日,还来就菊花。"
};
long startTime = System.currentTimeMillis();//记录索引开始时间
Analyzer analyzer = new SmartChineseAnalyzer();
Directory directory = FSDirectory.open(Paths.get(indexDir));
IndexWriterConfig config = new IndexWriterConfig(analyzer);
IndexWriter indexWriter = new IndexWriter(directory, config);
for(int i = 0; i < ids.length;i++){
Document doc = new Document();
//添加字段
doc.add(new IntField("id", ids[i],Field.Store.YES)); //添加内容
doc.add(new TextField("title", titles[i], Field.Store.YES)); //添加文件名,并把这个字段存到索引文件里
doc.add(new TextField("tcontent", tcontents[i], Field.Store.YES)); //添加文件路径
indexWriter.addDocument(doc);
}
indexWriter.commit();
System.out.println("共索引了"+indexWriter.numDocs()+"个文件");
indexWriter.close();
System.out.println("创建索引所用时间:"+(System.currentTimeMillis()-startTime)+"毫秒");
return true;
}
public static void main(String[] args) {
try {
boolean r = LuceneIndexer.getInstance().createIndex(INDEX_DIR);
if(r){
System.out.println("索引创建成功!");
}else{
System.out.println("索引创建失败!");
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行结果:
共索引了4个文件
创建索引所用时间:1831毫秒
索引创建成功!
全局搜索索引:
package com.lilike.music.lucene;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.search.highlight.*;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import java.io.IOException;
import java.io.StringReader;
import java.nio.file.Paths;
public class SearchBuilder {
public static void doSearch(String indexDir , String queryStr) throws IOException, ParseException, InvalidTokenOffsetsException {
Directory directory = FSDirectory.open(Paths.get(indexDir));
DirectoryReader reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
Analyzer analyzer = new SmartChineseAnalyzer();
QueryParser parser = new QueryParser("tcontent",analyzer);
Query query = parser.parse(queryStr);
long startTime = System.currentTimeMillis();
TopDocs docs = searcher.search(query,10);
System.out.println("查找"+queryStr+"所用时间:"+(System.currentTimeMillis()-startTime));
System.out.println("查询到"+docs.totalHits+"条记录");
SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("","");
QueryScorer scorer = new QueryScorer(query);//计算查询结果最高的得分
Fragmenter fragmenter = new SimpleSpanFragmenter(scorer);//根据得分算出一个片段
Highlighter highlighter = new Highlighter(simpleHTMLFormatter,scorer);
highlighter.setTextFragmenter(fragmenter);
//遍历查询结果
for(ScoreDoc scoreDoc : docs.scoreDocs){
Document doc = searcher.doc(scoreDoc.doc);
String tcontent = doc.get("tcontent");
if(tcontent != null){
TokenStream tokenStream = analyzer.tokenStream("tcontent", new StringReader(tcontent));
String summary = highlighter.getBestFragment(tokenStream, tcontent);
System.out.println(summary);
System.out.println();
}
}
reader.close();
}
public static void main(String[] args){
String indexDir = "D:\\lucene";
String q = "菊花"; //查询这个字符串
try {
doSearch(indexDir, q);
} catch (Exception e) {
e.printStackTrace();
}
}
}
运行结果:
查找菊花所用时间:32
查询到3条记录
昨日登高罢,今朝更举觞。
菊花何太苦,遭此两重阳?
故人具鸡黍,邀我至田家。
绿树村边合,青山郭外斜。
开轩面场圃,把酒话桑麻。
待到重阳日,还来就菊花。
江涵秋影雁初飞,与客携壶上翠微。
尘世难逢开口笑,菊花须插满头归。
但将酩酊酬佳节,不用登临恨落晖。
古往今来只如此,牛山何必独霑衣
五、Lucene重要类解释
IndexWriter: lucene 中最重要的的类之一,它主要是用来将文档加入索引,同时控制索引过程中的一些参数使用。
Analyzer:分析器,主要用于分析搜索引擎遇到的各种文本。常用的有StandardAnalyzer分析器,StopAnalyzer 分析器,WhitespaceAnalyzer 分析器等。
Directory:索引存放的位置;lucene 提供了两种索引存放的位置,一种是磁盘,一种是内存。一般情况将索引放在磁盘上;相应地lucene 提供了FSDirectory 和RAMDirectory 两个类。
Document:文档;Document 相当于一个要进行索引的单元,任何想要被索引的文件都必须转化为Document 对象才能进行索引。
Field:字段。
IndexSearcher:是lucene 中最基本的检索工具,所有的检索都会用到IndexSearcher工具;
Query:查询,lucene 中支持模糊查询,语义查询,短语查询,组合查询等等,如有
TermQuery,BooleanQuery,RangeQuery,WildcardQuery 等一些类。
QueryParser:是一个解析用户输入的工具,可以通过扫描用户输入的字符串,生成Query对象。
Hits:在搜索完成之后,需要把搜索结果返回并显示给用户,只有这样才算是完成搜索的目的。在lucene 中,搜索的结果的集合是用Hits 类的实例来表示的。