一.基于用户的协同过滤算法
基于用户的协同过滤(下文简称UserCF)的基本思想为:给用户推荐和他兴趣相似的用户感兴趣的物品。当需要为一个用户A进行推荐时,首先,找到和A兴趣相似的用户集合(用U表示),然后,把集合U中用户感兴趣而A没有听说过(未进行过操作)的物品推荐给A。算法分为两个步骤:首先,计算用户之间的相似度,选取最相似的N个用户,然后,根据相似度计算用户评分。
算法不足:
1.扩展性:用户人数和用户个人信息的大幅增加对协同过滤算法带来挑战。
2.准确性:一个用户可能买到系统其中不到1%的物品,不同用户之间买的物品重叠性较低,导致算法无法找到一个用户的邻居,即偏好相似的用户。因此,基于最近邻算法的推荐系统可能无法为特定用户推荐任何物品,建议的准确性可能很差。
二.基于物品的协同过滤算法
基于物品的协同过滤(下文简称ItemCF)是目前应用最为广泛的算法,该算法的基本思想为:给用户推荐和他们以前喜欢的物品相似的物品,这里所说的相似并非从物品的内容角度出发,而是基于一种假设:喜欢物品A的用户大多也喜欢物品B代表着物品A和物品B相似。基于物品的协同过滤算法能够为推荐结果做出合理的解释,比如电子商务网站中的“购买该物品的用户还购买了…”。ItemCF的计算步骤和UserCF大致相同:首先,计算物品相似度,选出最相似的N个物品,然后根据相似度计算用户评分。
建立模型的常用机器学习方法:
1.贝叶斯网络模型为协同过滤问题提供了一个概率模型,它在用户偏好模型构建较快,在用户偏好信息变换缓慢的环境中是非常实用的。但是不适用于用户偏好模型需要快速更新的环境。
2.聚类模型则把协同过滤看作一个分类问题,它的准确性较差,但是性能较佳(针对于计算量而言,因为一旦聚类完成,只需要分析很小的群组就可以了)。因此,是否预先聚类可能是精准性与吞吐量之间的一个值得的权衡的问题。
3.基于规则的方法,应用关联规则发现算法来寻找共同购买的商品之间的关联,然后根据商品之间的关联强度生成商品推荐。
(1)物品相似度的计算
Item-based算法首先需要计算物品之间的相似度,计算相似度的方法有以下几种:
1.基于余弦(Cosine-based)的相似度计算
通过计算两个向量之间的夹角余弦值来计算物品之间的相似性,公式如下: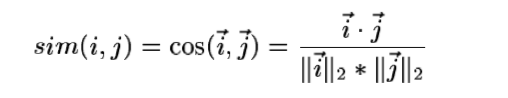
其中“.”表示两个向量的点积。
2.基于相关(Correlation-based)的相似度计算
计算两个向量之间的皮尔森(Pearson-r)相关系数,公式如下: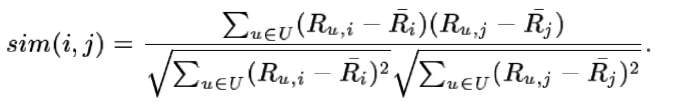
其中Ru,i表示用户u对物品i的打分,Ri表示第i个物品打分的平均值。
3.修正的余弦(Adjusted Cosine)相似度计算
基于余弦的相似度计算没有考虑不同用户的打分情况,可能有的用户偏向于给高分,而有的用户偏向于给低分,该方法通过减去用户打分的平均值消除不同用户打分习惯的影响,公式如下: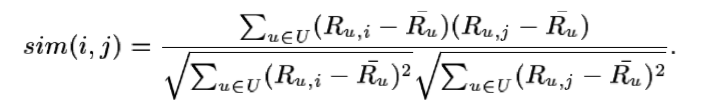
其中Ru表示用户u打分的平均值。
(PS:基于用户的协同过滤和基于物品的协同过滤,两者在计算相似度时最根本的不同是:基于用户的协同过滤的相似度是沿着矩阵的行进行计算的,而基于物品的协同过滤的相似度的计算,是沿着矩阵的列进行的。)
(2)预测值计算
根据之前算好的物品之间的相似度,接下来对用户未打分的物品进行预测,有两种预测方法:
1.加权求和
将用户u已打分的物品的分数进行加权求和,权值为各个物品与未打分物品i的相似度,计算得到用户u对物品i打分,公式如下: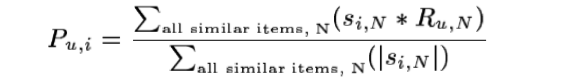
其中为Si,N是物品i与物品N的相似度,Ru,N为用户u对物品N的打分。
2.回归
这种方法和上面加权求和的方法类似,但它不是直接使用相似物品N的评分Ru,N,而是使用基于回归模型的评分近似值。因为用余弦法或Pearson关联法计算相似度时存在一个误区,因为不同用户的打分习惯不同,有的偏向打高分,有的偏向打低分。如果两个用户都喜欢一样的物品,因为打分习惯不同,他们的欧式距离可能比较远,但他们应该有较高的相似度。在这种情况下如果使用用户原始的相似物品的打分值进行计算会造成糟糕的预测结果。所有一般采取通过用线性回归的方式重新估算一个新的Ru,N值,运用上面同样的方法进行预测,重新计算Ru,N的方法如下: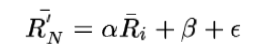
其中物品N是物品i的相似物品,a和b通过对物品N和i的打分向量进行线性回归计算得到,e为回归模型的误差。(具体怎么进行线性回归文章里面没有说明,需要查阅另外的相关文献。)
评价指标
1.统计精度指标(statistical accuracy metrics)
通过比较训练集得出的推荐分数和测试集实际用户评分来评估系统的准确性,计算方法是先对N对评分差进行求和,然后再计算平均值: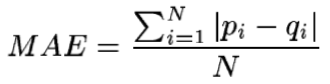
MAE越低,推荐引擎对用户评分的预测就越准确。
1.Item-based算法的预测结果比User-based算法的质量要高一点。
2.由于Item-based算法可以预先计算好物品的相似度,所以在线的预测性能要比User-based算法的高。
3.用物品的一个小部分子集也可以得到高质量的预测结果。
知识点补充:
基于物品的协同过滤和内容过滤有什么区别?
答:
基于物品的协同过滤,首先从数据库里获取他之前喜欢的东西,然后从剩下的物品中找到和他历史兴趣近似的物品推荐给他。核心是要计算两个物品的相似度。
内容过滤的基本思想是,给用户推荐和他们之前喜欢的物品在内容上相似的其他物品。核心任务就是计算物品的内容相似度。
可以注意到两者的相同点都是要计算两个物品的相似度,但不同点是前者是根据两个物品被越多的人同时喜欢,这两个物品就越相似,而后者要根据物品的内容相似度来做推荐,给物品内容建模的方法很多,最著名的是向量空间模型,要计算两个向量的相似度。
由此可以看到两种方法的不同点在于计算两个物品的相似度方法不同,一个根据外界环境计算,一个根据内容计算。
参考文献:
1.《Item-Based Collaborative Filtering Recommendation Algorithms》
2.http://blog.csdn.net/huagong_adu/article/details/7362908