ES命令增删改查
Rest风格说明
一种软件架构风格,而不是标准,只是提供了一组设计原则和约束条件。它主要用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
基本Rest命令说明:
| method | url地址 | 描述 |
|---|---|---|
| PUT(创建,修改) | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) |
| POST(创建) | localhost:9200/索引名称/类型名称 | 创建文档(随机文档id) |
| POST(修改) | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE(删除) | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| GET(查询) | localhost:9200/索引名称/类型名称/文档id | 查询文档通过文档ID |
| POST(查询) | localhost:9200/索引名称/类型名称/文档id/_search | 查询所有数据 |
练习
1、创建一个索引,添加,在这里我创建了两个
在head里边可以更好的查看,这里我开了两个可视化软件
在如图所示的地方也可以查看
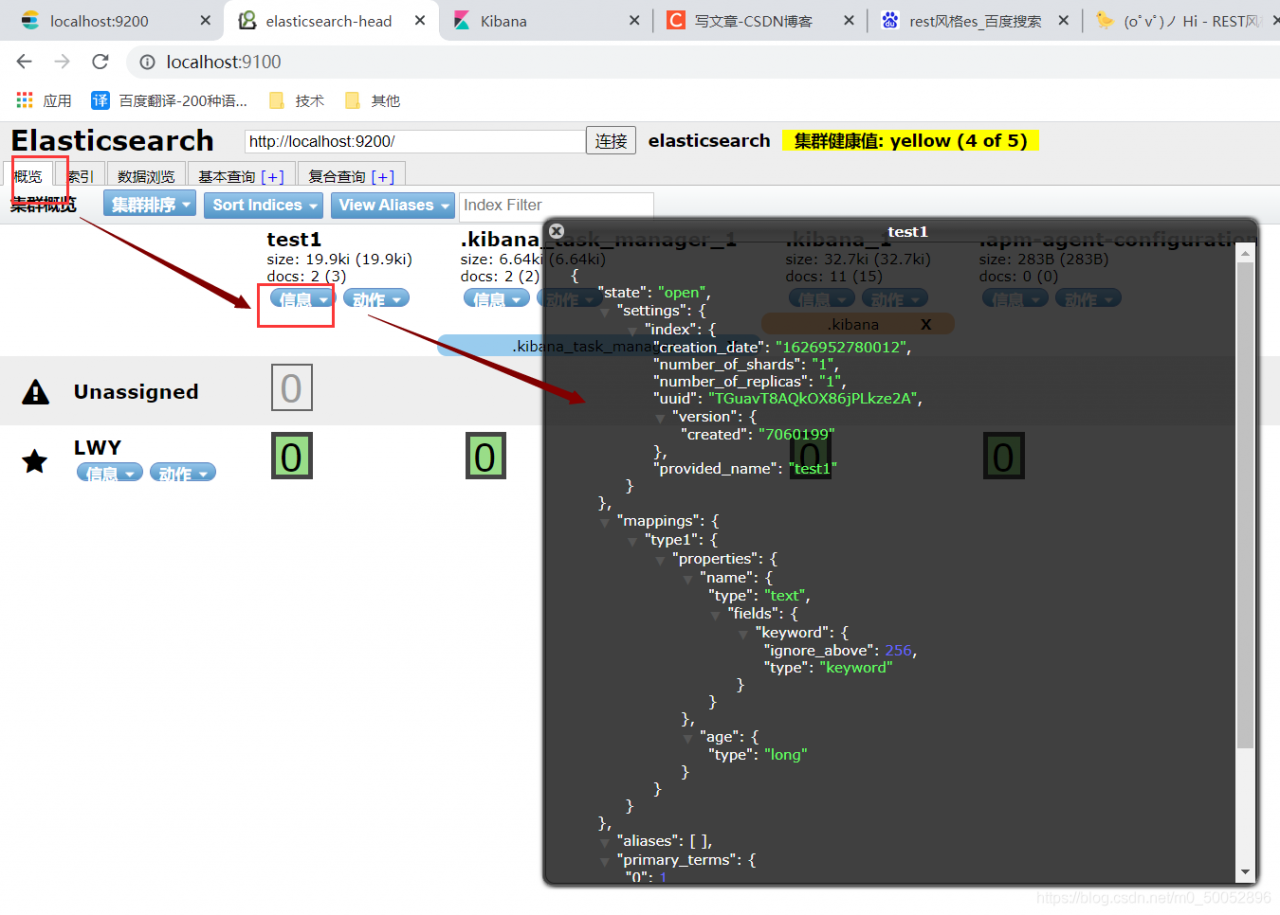
2、字段数据类型
字符串类型
text、keyword
text:支持分词,全文检索,支持模糊、精确查询,不支持聚合,排序操作;text类型的最大支持的字符长度无限制,适合大字段存储;
keyword:不进行分词,直接索引、支持模糊、支持精确匹配,支持聚合、排序操作。keyword类型的最大支持的长度为——32766个UTF-8类型的字符,可以通过设置ignore_above指定自持字符长度,超过给定长度后的数据将不被索引,无法通过term精确匹配检索返回结果。
数值型
long、Integer、short、byte、double、float、half float、scaled float
日期类型
date
te布尔类型
boolean
二进制类型
binary
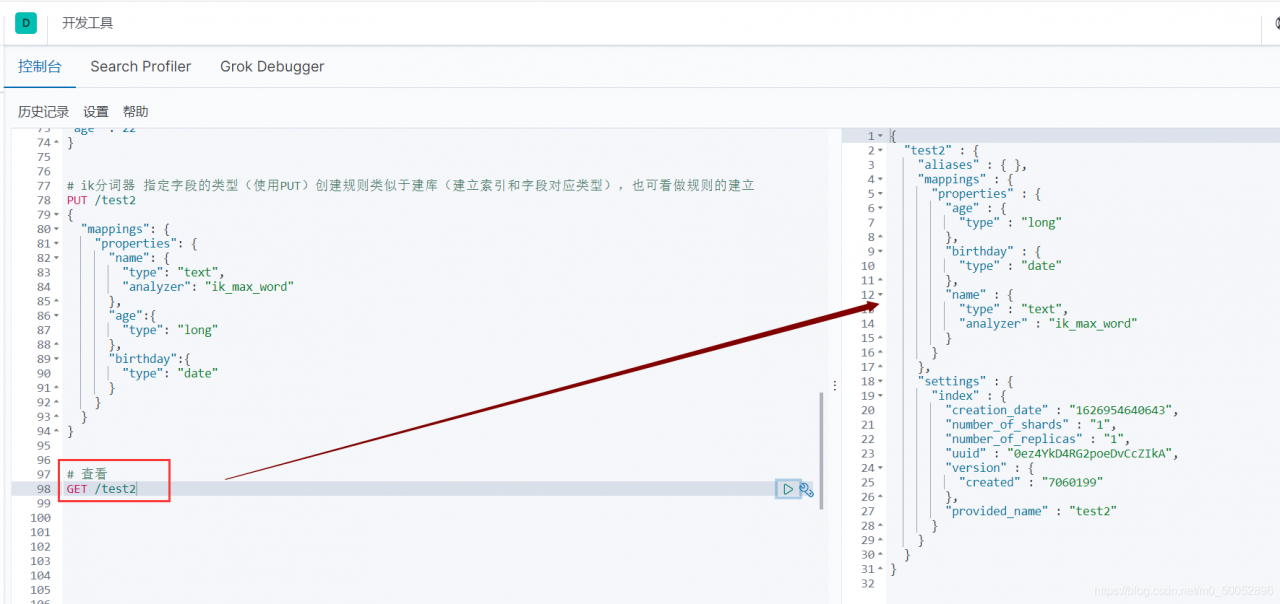
3、指定字段的类型(使用PUT)
创建规则 类似于建库(建立索引和字段对应类型),也可看做规则的建立
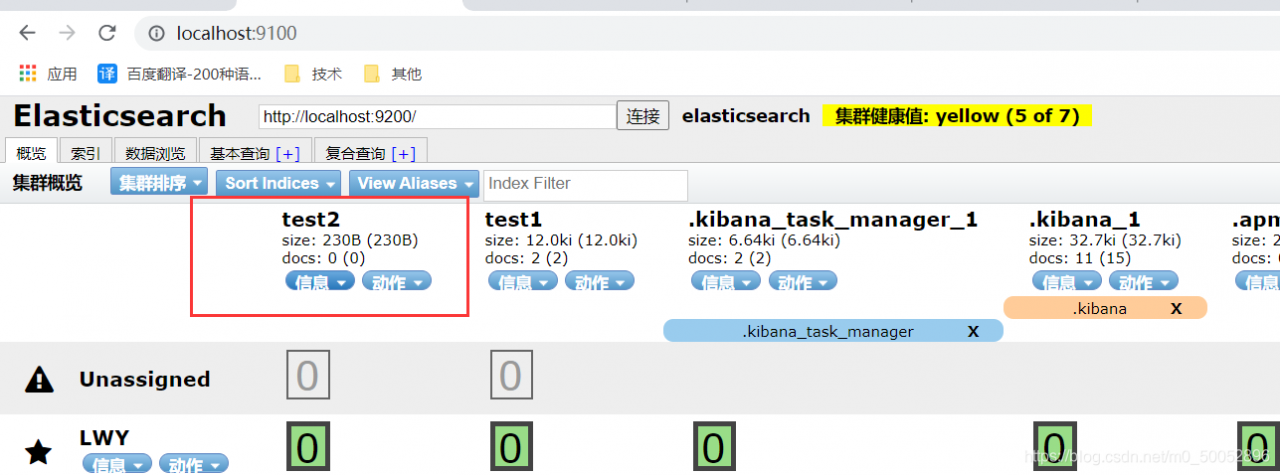
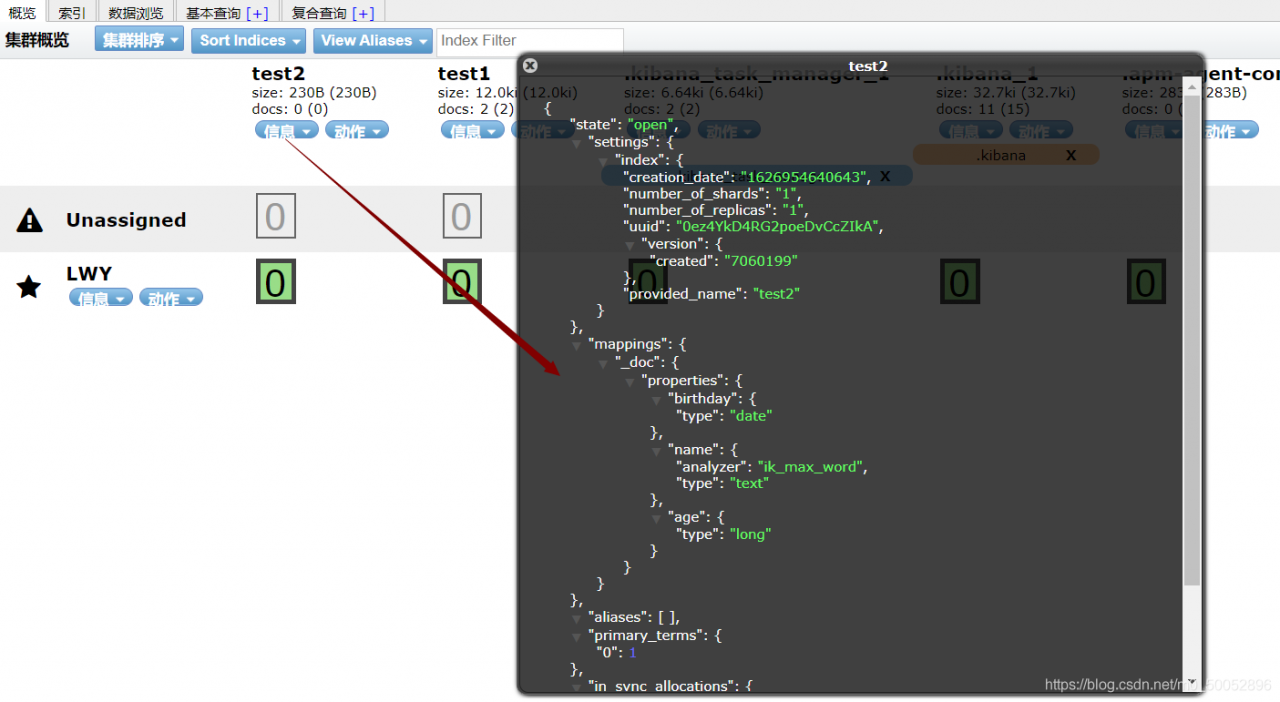
在Kibana也可以查看,使用GET命令
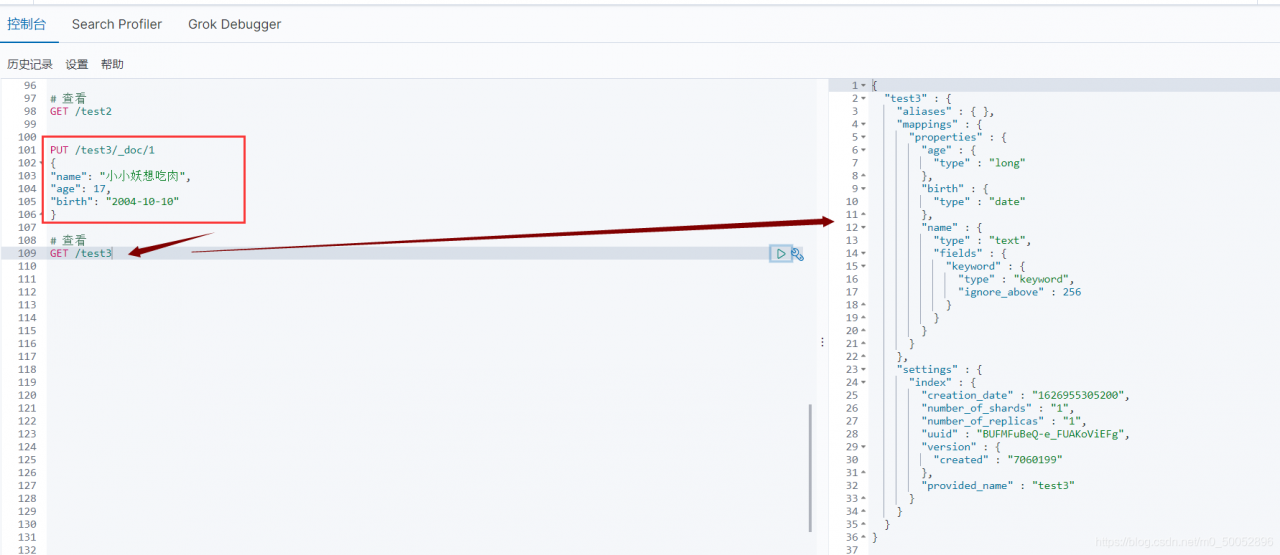
4、获取默认信息
_doc默认类型(default type),type 在未来的版本中会逐渐弃用,因此产生一个默认类型进行代替
查看一下test3 GET test3
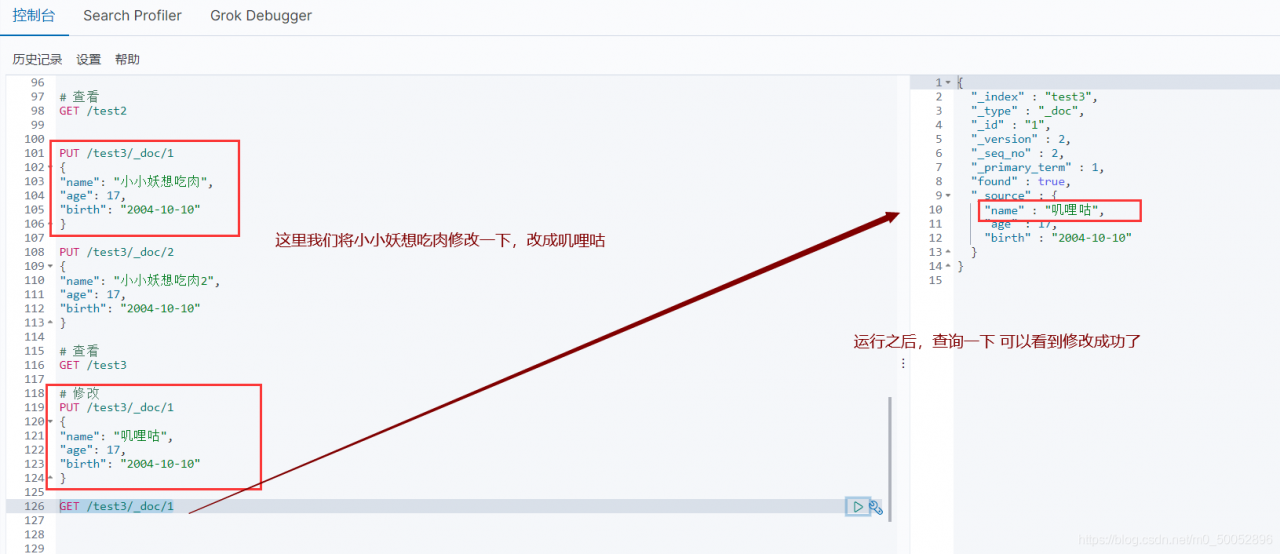
5、修改 有两种方案
①旧的(使用put覆盖原来的值)
版本+1(_version)
但是如果漏掉某个字段没有写,那么更新是没有写的字段 ,会消失
但是因为如果漏掉一个,就是丢失字段
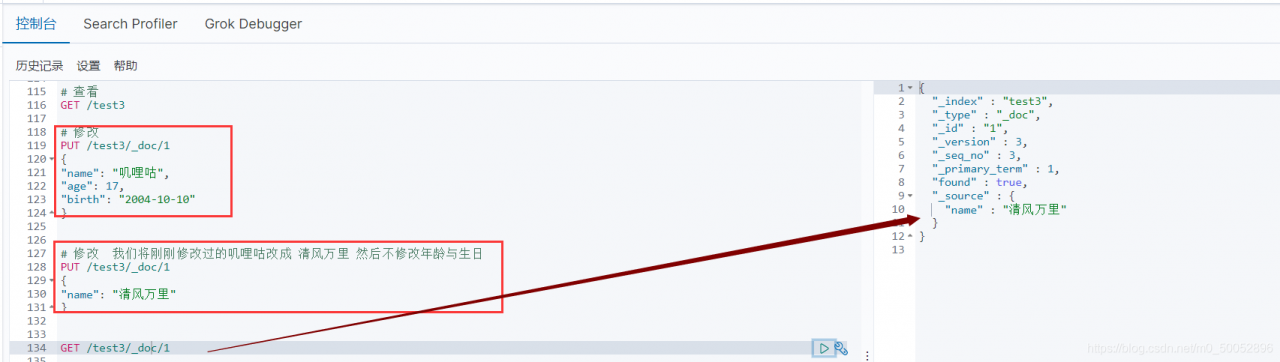
由于我们没有给年龄和生日,查询的时候就发现丢失了两条数据,我们也可以去head里边看一看
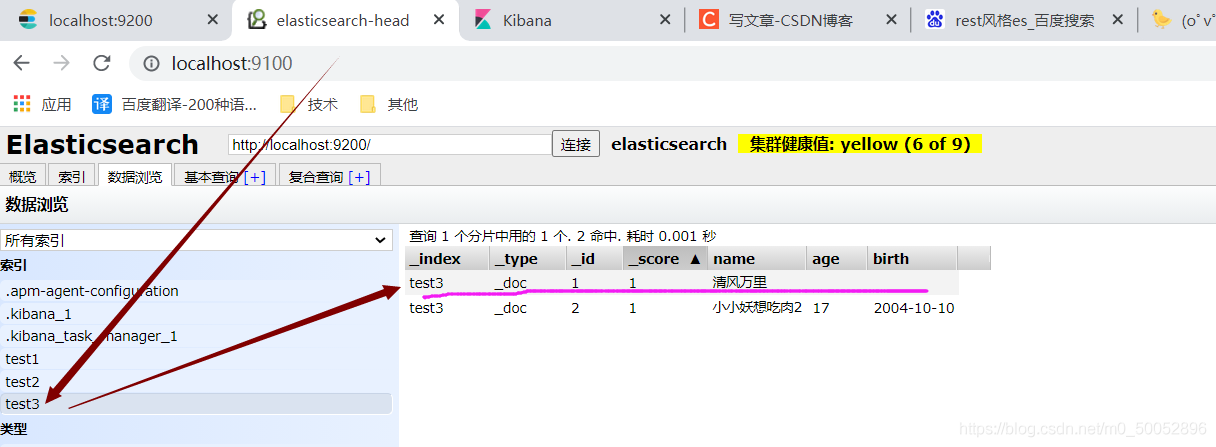
id为一的这一条是修改过的,发现他原本的年龄和生日没有了
②新的(使用post的update)记得加上"doc"要不然报400
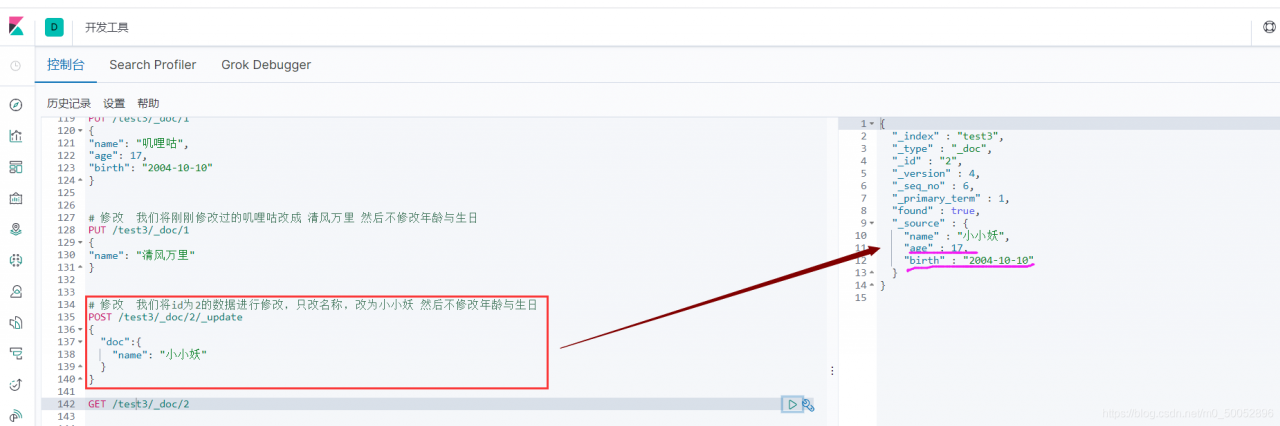
由图可见,这个方法只修改需要修改的字段,不会丢失字段
6、删除 直接delete加索引就可以
//获取 GET /test1 # 删除 DELETE /test1
查询有两条数据
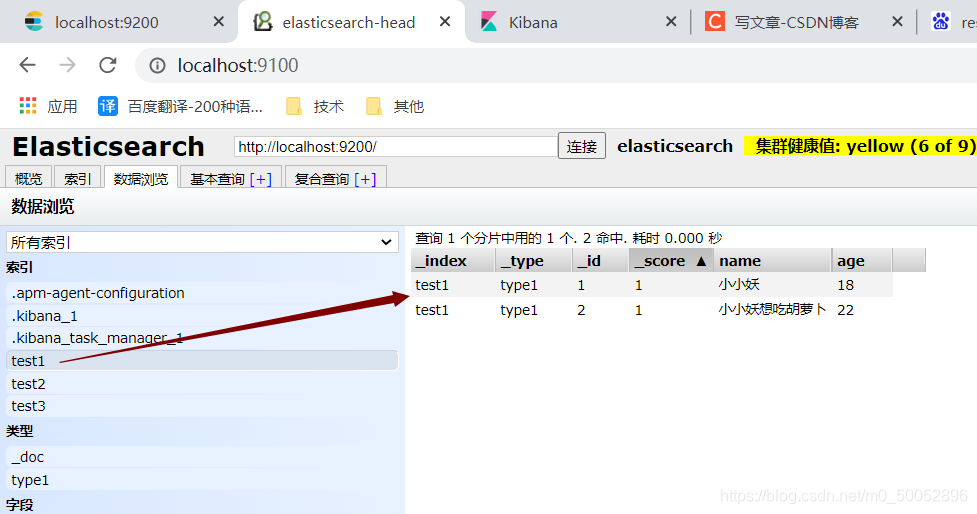
执行删除操作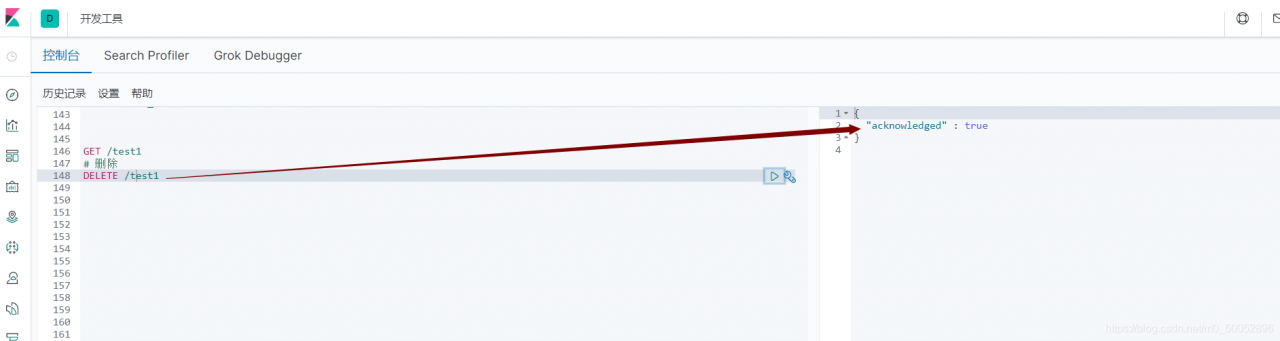
这里已经没有test1这个索引了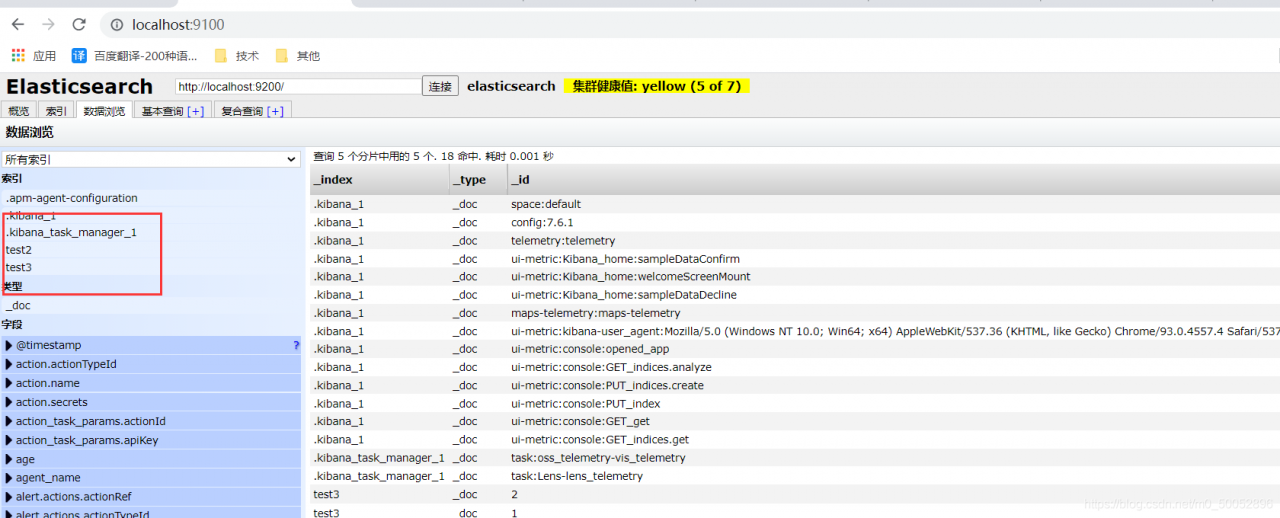
还有很多复杂的查询语句,就简单在演示几个,感兴趣的可以自己搜索一下
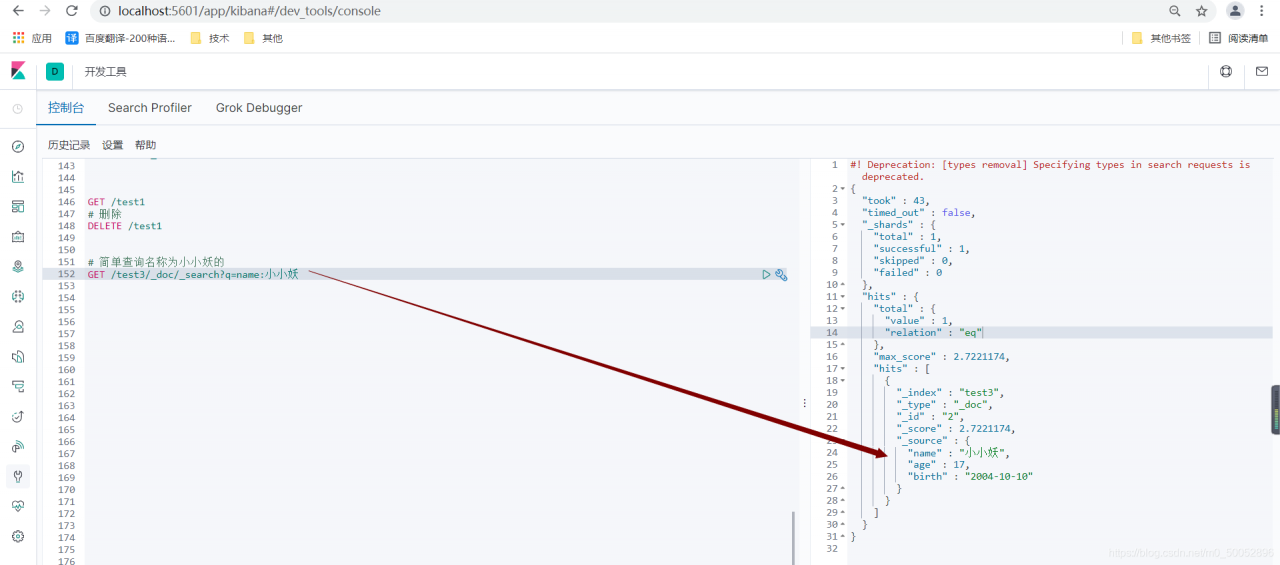
7、查询(简单条件)
GET /test3/_doc/_search?q=name:小小妖
由于我里边只有一个名字里边含有小小妖的,所以就直接查询出来一条,如果有两个及以上含有的,怎么排序呢?
如果含有两个及以上的名字里边有的,它里边有一个score,会根据最接近的依次排序
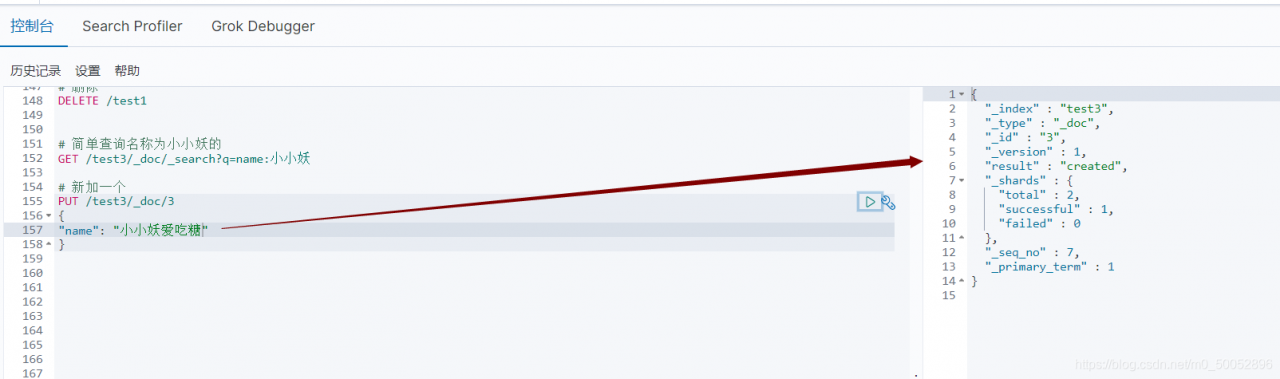
添加成功之后我们再查询依次
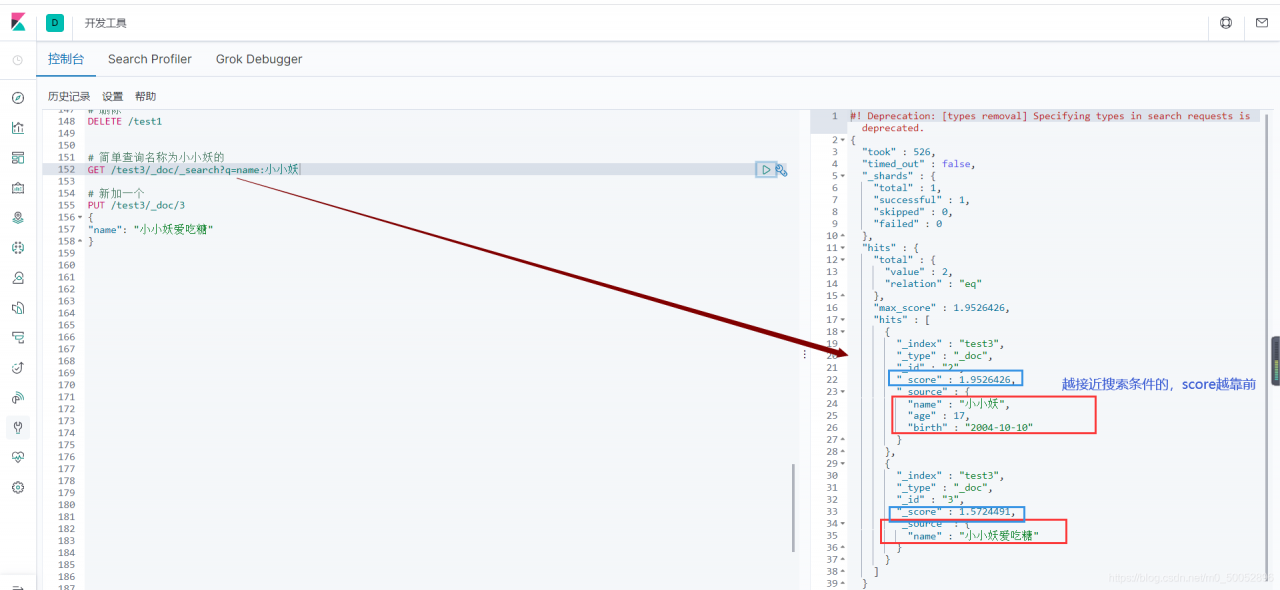
8、复杂查询 (我就不在测试了,感兴趣的可以自己搜索一下es的复杂查询,等有时间我再补上)
①查询匹配
match:匹配(会使用分词器解析(先分析文档,然后进行查询))_source:过滤字段sort:排序form、size分页
②多条件查询(bool)
must相当于andshould相当于ormust_not相当于not (... and ...)filter过滤
③匹配数组
貌似不能与其它字段一起使用
可以多关键字查(空格隔开)— 匹配字段也是符合的
match会使用分词器解析(先分析文档,然后进行查询)
④精确查询
term直接通过 倒排索引 指定词条查询适合查询 number、date、keyword ,不适合text
⑤text和keyword
text: 支持分词,全文检索、支持模糊、精确查询,不支持聚合,排序操作; text类型的最大支持的字符长度无限制,适合大字段存储;
keyword: 不进行分词,直接索引、支持模糊、支持精确匹配,支持聚合、排序操作。 keyword类型的最大支持的长度为——32766个UTF-8类型的字符,可以通过设置ignore_above指定自持字符长度,超过给定长度后的数据将不被索引,无法通过term精确匹配检索返回结果。