我们拿到的原始数据通常都是一团糟的,缺失值尤其常见,自己在做论文的时候也常常被缺失数据困扰,所以打算写一些如何用python进行缺失值的处理。首先需要大家注意的是,数据的清理很枯燥,但是很重要,根据IBM的研究,数据科学家80%的时间都在做数据清理的工作。本文,我主要写最常见的数据清理任务,即清理缺失值。
数据导入
实例数据地址:https ://raw.githubusercontent.com/dataoptimal/posts/master/data%20cleaning%20with%20python%20and%20pandas/property%20data.csv
首先瞅一瞅数据集长啥样
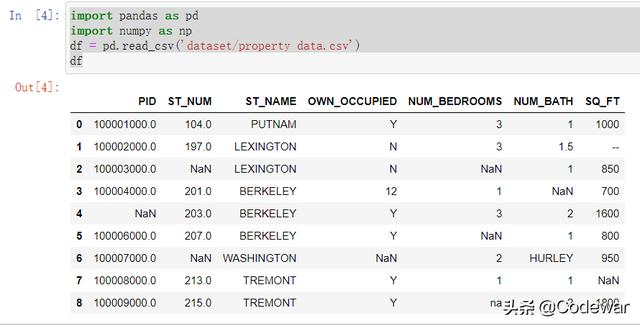
import pandas as pdimport numpy as npdf = pd.read_csv('dataset/property data.csv')df可以看到这是一个非常迷你的数据集,但是练习缺失值处理肯定够用了。
缺失数据识别
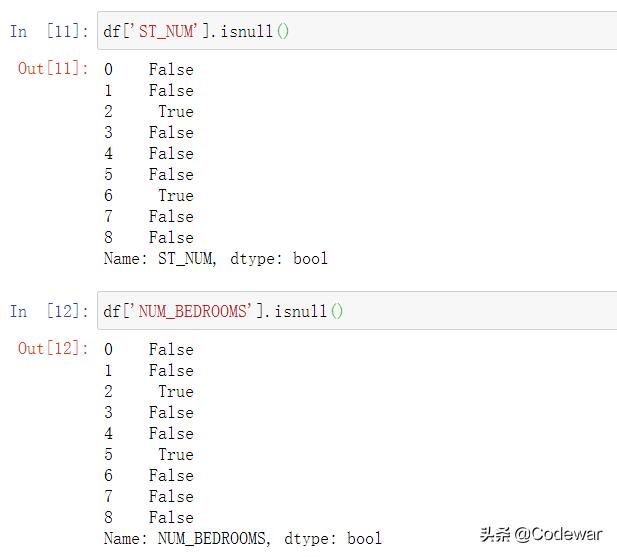
我们先看ST_NUM和NUM_BEDROOMS这两列,我们知道这个数据集的ST_NUM列有2个缺失,NUM_BEDROOMS这一列应该有3个缺失,运行以下代码,可以判断pandas是否可以将缺失值正确的识别出来
df['ST_NUM'].isnull()df['NUM_BEDROOMS'].isnull()运行后得到结果
可以看到,对于大写的NA或者空白缺失pandas都是可以正确的识别为缺失值的,这种缺失称为标准缺失,而小写的na在pandas会被认为是字符串输入而非缺失,其他也是同理,这种我们自己认为的缺失但pandas识别不出来,称为非标准缺失。
对于非标准缺失,我们首先得将其转化为标准缺失数据才好处理,怎么做呢?接着看
missing_values = [ "na", "--"]df = pd.read_csv("property data.csv", na_values = missing_values)df以上代码就是重新定义缺失值后再次读入数据集,再看
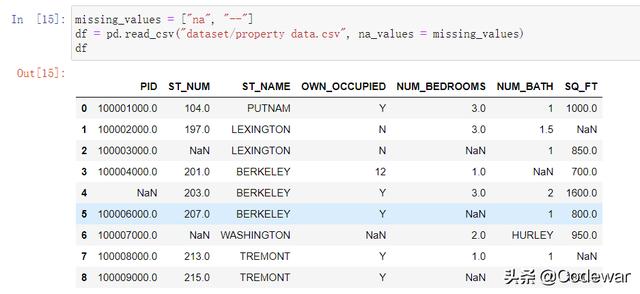
可以看到此时缺失数据都被识别出来了。
意外数据识别
但是你可能也注意到了在OWN_OCCUPIED这一列,这一列的意思是受否被占用,所以正确的输入数据应该是Y或者N,但是我们却发现了一个12,还有在NUM_BATH这一列却发现了“HURELY”这么一个字符串,这都是不正确的输入,处理方法也是想办法将其转化为缺失数据。
你会怎么转化?
这里我给出一种思路,对于OWN_OCCUPIED这一列可以将这一列的元素转化为整型,如果可以转化成功就将其定义为缺失,代码如下
cnt=0for row in df['OWN_OCCUPIED']: try: int(row) df.loc[cnt, 'OWN_OCCUPIED']=np.nan except ValueError: pass cnt+=1输出如下:
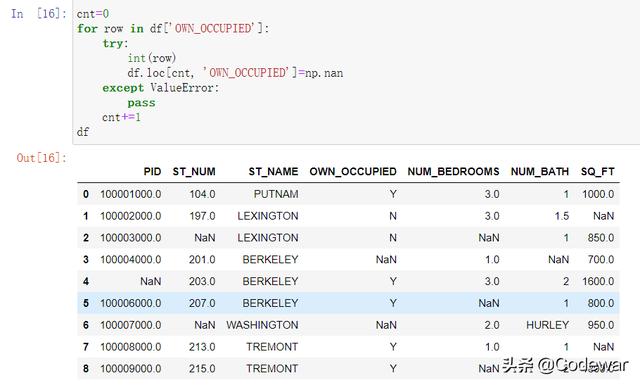
可以看到12已经被完美转化为缺失值了,相应的,同样的方法可以用在NUM_BATH列中,这儿就不演示了。
汇总缺失值
进行了基本的缺失值查找后我们就可以从整体上看一看自己数据库缺失值的情况
df.isnull().sum()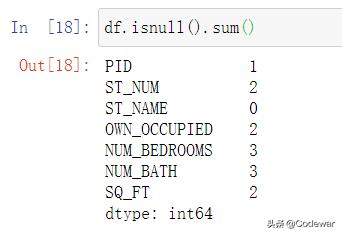
可以看到数据库每一列的缺失情况都可以显示出来,而且和我们预先设定的一模一样。
缺失替换
找到缺失值后你可以用另一个值替换它
df['ST_NUM'].fillna(125, inplace=True)或者可以直接基于位置替换
df.loc[2,'ST_NUM'] = 125更常见的是用该列数据的中位数或者均值替换
median = df['NUM_BEDROOMS'].median()df['NUM_BEDROOMS'].fillna(median, inplace=True)最后还要写一句,究竟用什么来替换缺失值,这里面有大学问,关注我,以后写写到底该用什么替换缺失。
好了,今天介绍了缺失值的查找汇总和简单的替换方法,感谢大家耐心看完。发表这些东西的主要目的就是督促自己,希望大家关注评论指出不足,一起进步。内容我都会写的很细,用到的数据集也会在原文中给出链接,你只要按照文章中的代码自己也可以做出一样的结果,一个目的就是零基础也能懂,因为自己就是什么基础没有从零学Python的,加油。
往期精彩:
Python初学者应避免的2个常见错误
python数据分析:使用applymap函数清洗整个数据集