声明:XX话题批量获取分析仅用于研究和学习,如有侵权,可联系删除
大家好,本期分享的内容是一个关于批量获取话题的案例!示例URL:aHR0cHM6Ly93d3cuemhpaHUuY29tL3RvcGljLzIxMjM4NDE4L3RvcC1hbnN3ZXJz
整体过程跟 案例12这篇案例很像,部分细节不在重复,只说差异:
下面会进行以下几步进行分析(下方演示过程全部使用chrome浏览器);
1.首页能获取到数据
话题接口aHR0cHM6Ly93d3cuemhpaHUuY29tL2FwaS92NS4xL3RvcGljcy8yMTIzODQxOC9mZWVkcy90b3BfYWN0aXZpdHk/b2Zmc2V0PTAmbGltaXQ9MTAm 的第一页能获取到数据,这个地方跟上一片根据问题获取答案不同;
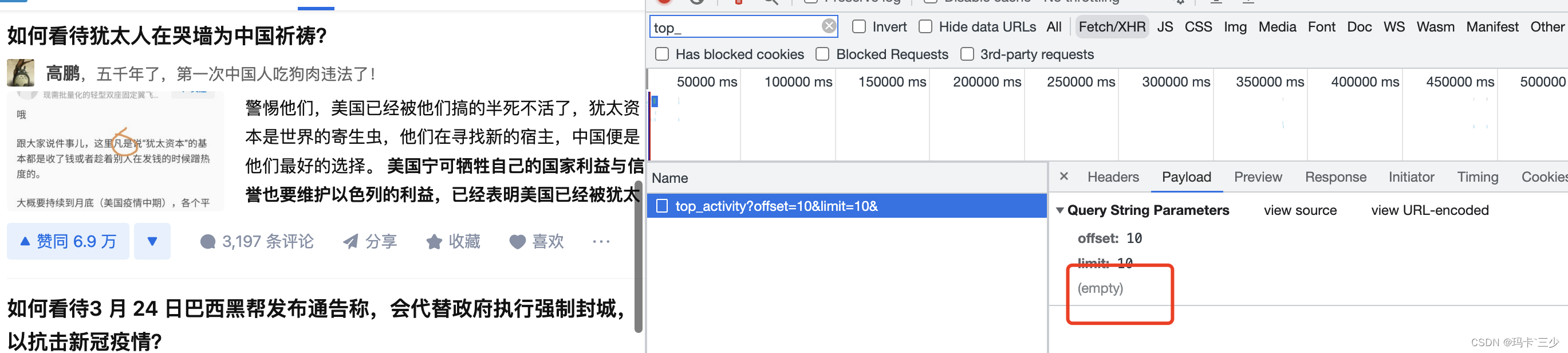
2.注意参数里又个空值
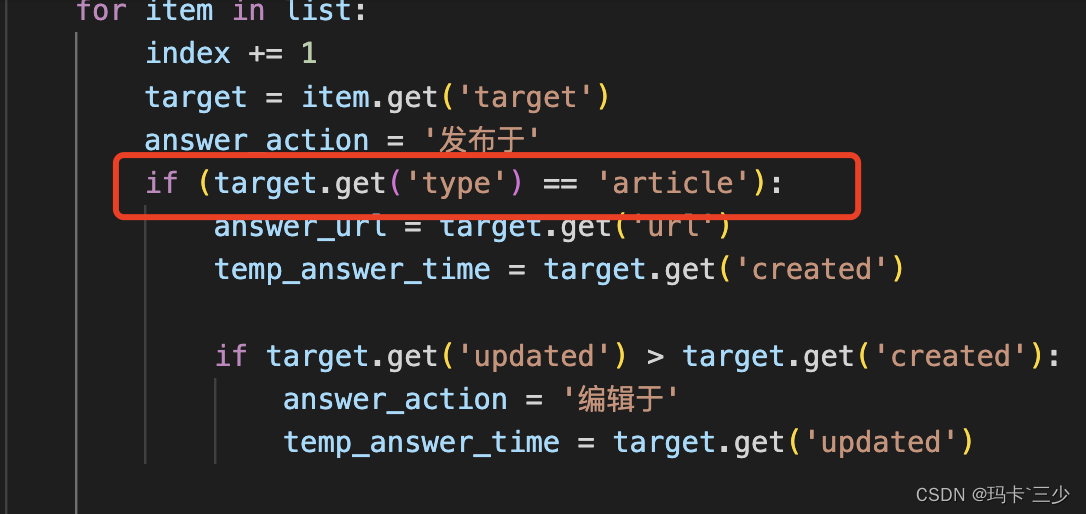
3.解析结果时需要根据具体的类型处理
4.目录
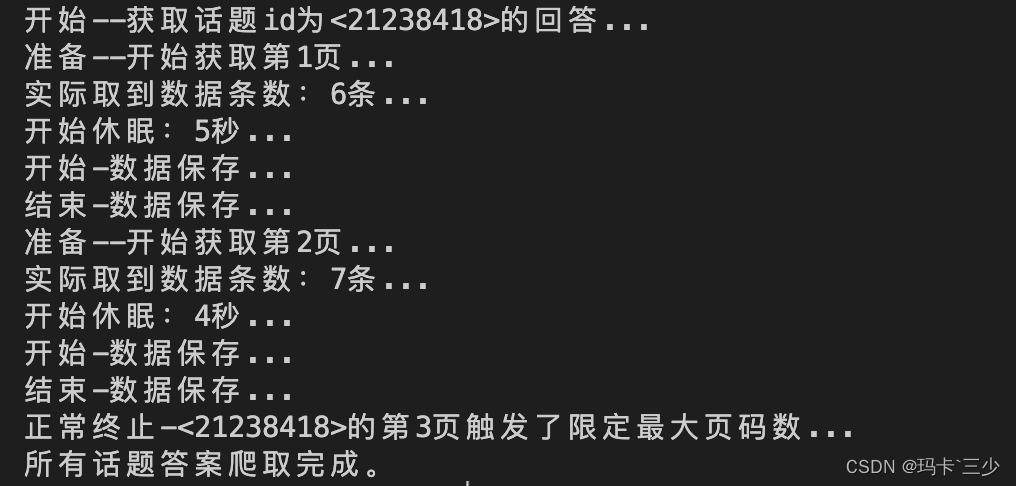
5.日志
def get_answers(id, max_page):
print('开始--获取话题id为<{}>的回答...'.format(id))
index = 1
while True:
params = {
'offset': (index - 1) * config['limit'],
'limit': config['limit']
}
print('准备--开始获取第{}页...'.format(index))
params_url = get_sign_url(id, params)
str_96 = get_zst_96(params_url)
headers = config['headers']
headers.update({
'Cookie': get_random_cookie(),
'x-zse-96': str_96,
})
r_url = get_request_url(id, params)
res = requests.get(r_url, headers=headers).json()
datas = res.get('data')
print('实际取到数据条数:{}条...'.format(len(datas)))
sleep = random.randint(config['random_start'], config['random_end'])
print('开始休眠:{}秒...'.format(sleep))
time.sleep(sleep) # 下次请求之前随机暂停几秒,防止被封号
if len(datas) <= 0:
print("异常结束-<{}>的第{}页无数据...".format(id, index + 1))
break
saveDataTool.format_data_to_save(datas)
# 只要达到了最大页码条数,无论后面还有没有下一页,当前问题的答案到此为止
if (max_page > 0) and max_page <= index:
print("正常终止-<{}>的第{}页触发了限定最大页码数...".format(id, index + 1))
break
if res.get('paging').get('is_end'):
print("结束-<{}>的第{}页已是最后一页...".format(id, index + 1))
break
else:
index += 1
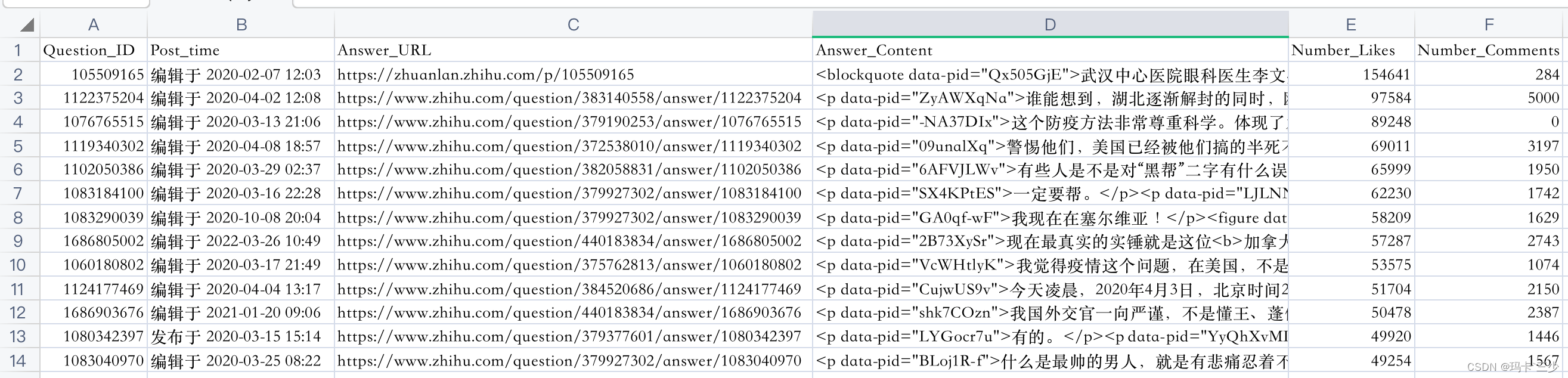
6.CSV
后期会持续分享爬虫案例-100例,不想自己造轮子的同学可加入我的知识星球,有更多技巧、案例注意事项、案例坑点终结、答疑提问特权等你哦!!!
版权声明:本文为li11_原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。