html界面如下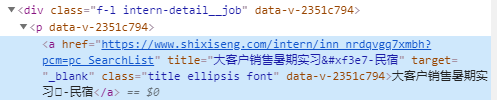
首先导入requests和BeautifulSoup模块
import requests
from bs4 import BeautifulSoup
header = {'user-agent': 'Mozilla/5.0'} #模拟浏览器,防止被禁
req = requests.get(url, headers = header)
html = req.text
soup = BeautifulSoup(html, 'lxml')
之前一直分不清.select() 和.find_all()
这次分别使用了两种方法都可以
1. select()
for item in soup.select('div[class="f-l intern-detail__job"] p a'):
detail_url = item.get('href')
print(detail_url)
2. find_all()
for items in soup.find_all('div',class_='f-l intern-detail__job'):
item = items.select('p a')[0]
detail_url = item.get('href')
print(detail_url)
输出结果:
版权声明:本文为DFFFAN原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。