一、容器是什么?
容器本质上是Linux系统上一种特殊的进程。
容器经常会拿来和虚拟机做对比,下图是常见的一张容器和虚拟机的对比图。
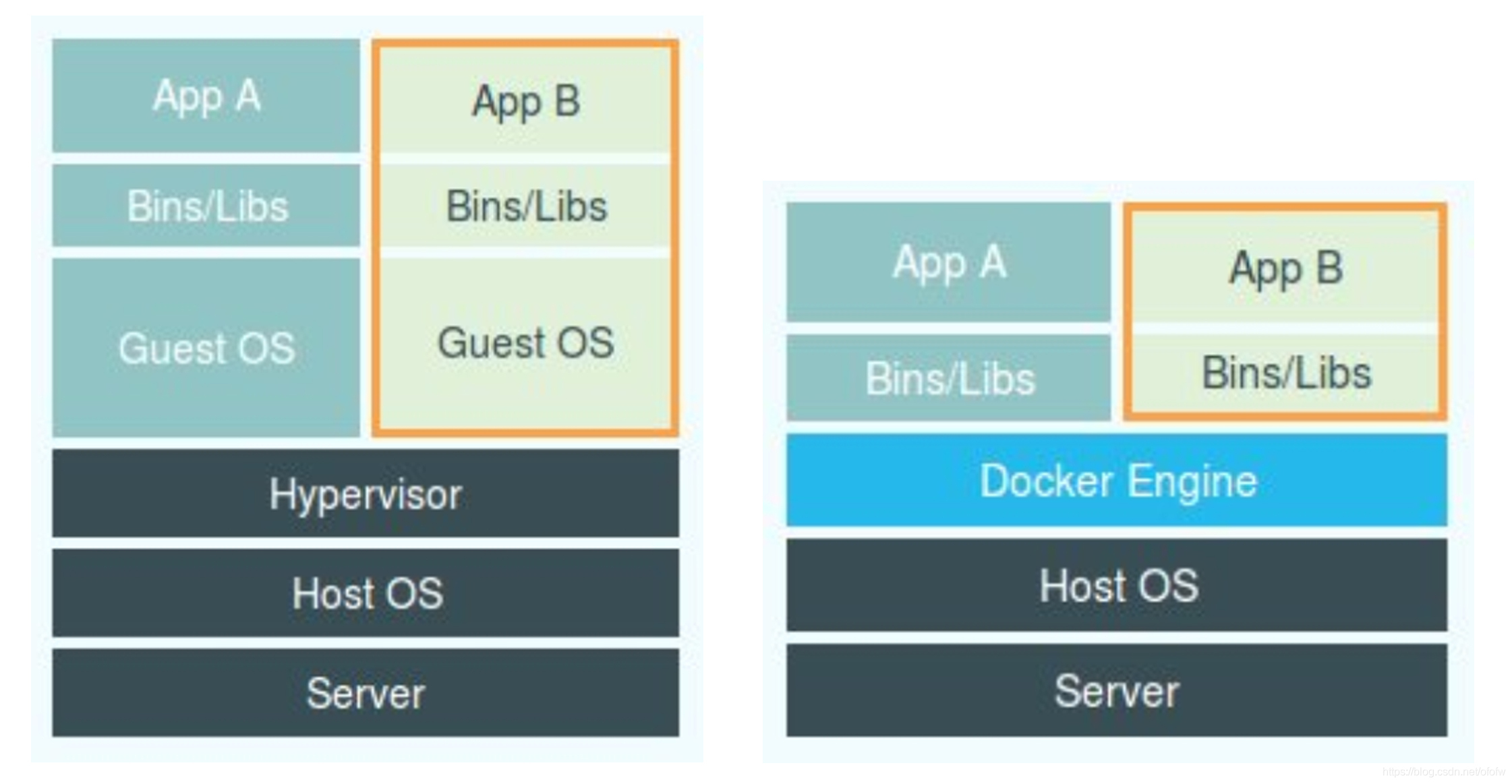
可以看到虚拟机在操作系统层面通过硬件虚拟化,模拟出操作系统需要的各种硬件,然后在虚拟的硬件上安装新的操作系统。
容器是基于Linux内核的一些隔离和限制的特性去创造一个“边界”,营造一个沙箱环境。
其中:
隔离功能主要是由Linux的Namespace技术实现。Linux提供的Namespace有很多种,比如有:Pid Namespace(进程隔离)、Network Namespace(网络隔离)、Mount Namespace(挂载点隔离)、IPC Namespace(进程间通信隔离)、User Namespace(用户隔离)等等。容器通过设置各种Namespace的参数实现对资源的“隔离”。
限制功能主要由Cgroups技术来实现。
Cgroups主要作用是限制一个进程组能够使用的资源上限,包括CPU、内存、磁盘、网络等等。
所以一个运行的容器实际上是通过Namespace对使用的资源做隔离的进程,然后再通过Cgroups对这个进程所能使用的资源量做限制。
常常有人把容器比喻成集装箱,那么Namespace就是这个集装箱的铁皮,然后Cgroups就是对这个铁皮大小的限制。
二、Docker是什么?
容器并不等于Docker,实际上还有其他使用Namespace和Cgroups实现的容器产品,比如CoreOS公司的Rocket/rkt。但是因为Docker太强大,所以目前的现状是大家默认容器就等于Docker了。
下面是一张Docker的命令导图:
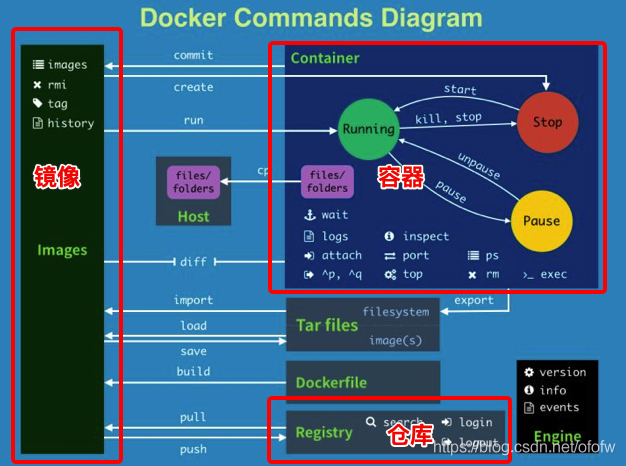
从图中可以看出Docker有三个重要的概念:容器(Container)、镜像(Images)、仓库(Registry)。
镜像是静态的,可以通过给镜像添加各种参数,生成并启动一个容器。
仓库是存放镜像的地方。
镜像是Docker的核心。
PS:windows和mac上的安装的docker也是基于虚拟机实现的。
三、镜像是什么?
Docker的强大很重要的一个原因就是Docker的镜像功能。
镜像本质上就是一个压缩包,一个特殊的文件系统。包括操作系统文件和目录以及应用依赖的所有程序、资源、库、配置等。 一般linux发行版的Docker镜像,如:Ubuntu、CentOS、Debian等称作base镜像,base镜像仅包含linux的用户空间。
注意base镜像是不包括kernel的,所以也无法使用镜像对linux kernel进行升级,如果应用对内核有要求,就不建议用容器了,建议用虚拟机。
镜像有一个分层的概念,大致分为两层:容器层和镜像层(实际是三层,忽略init层)
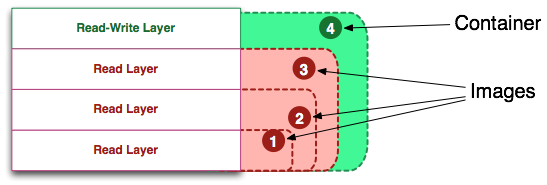
镜像层的操作是增量式的,层层叠加,只能读不能写。
镜像的读取是从上往下读取,如果不同层有相同路径的文件,优先读取上层的文件。即在上层镜像中找到该文件就不会再往下继续查找了。
容器层位于顶层,对容器的改动,无论添加、删除、修改文件都只会发生在容器层,不会影响镜像层。
- 添加文件:直接在容器层创建
- 读取文件:从容器层开始往镜像层从上至下逐层查找
- 修改文件:先读取文件,然后复制到容器层再修改
- 删除文件:在容器层标记此删除操作
四、kubernetes是什么
Docker以非常轻量级的方式实现了一个沙箱环境,解决了应用打包过程中因为依赖环境的差异带来复杂性问题。但是基于容器的服务,如何部署、如何管理以及如何调度依然是非常复杂的问题。
而kubernetes正是解决这些问题的利器。kubernetes项目提供了一整套的容器编排工具对容器进行管理。
kubernetes中间“ubernete”刚好8个字母,所以也简称k8s。
k8s可以做哪些事情呢?
启动容器
容器灾难恢复
应用的水平伸缩
应用的滚动更新和回滚
服务的发现和负载均衡
五、kubernetes的架构是怎样的?
k8s项目源自Google内部的服务编排系统——Brog,架构上沿袭了Brog系统沉淀了十几年的优秀设计。
1、集群设计
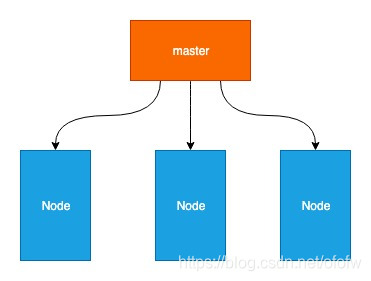
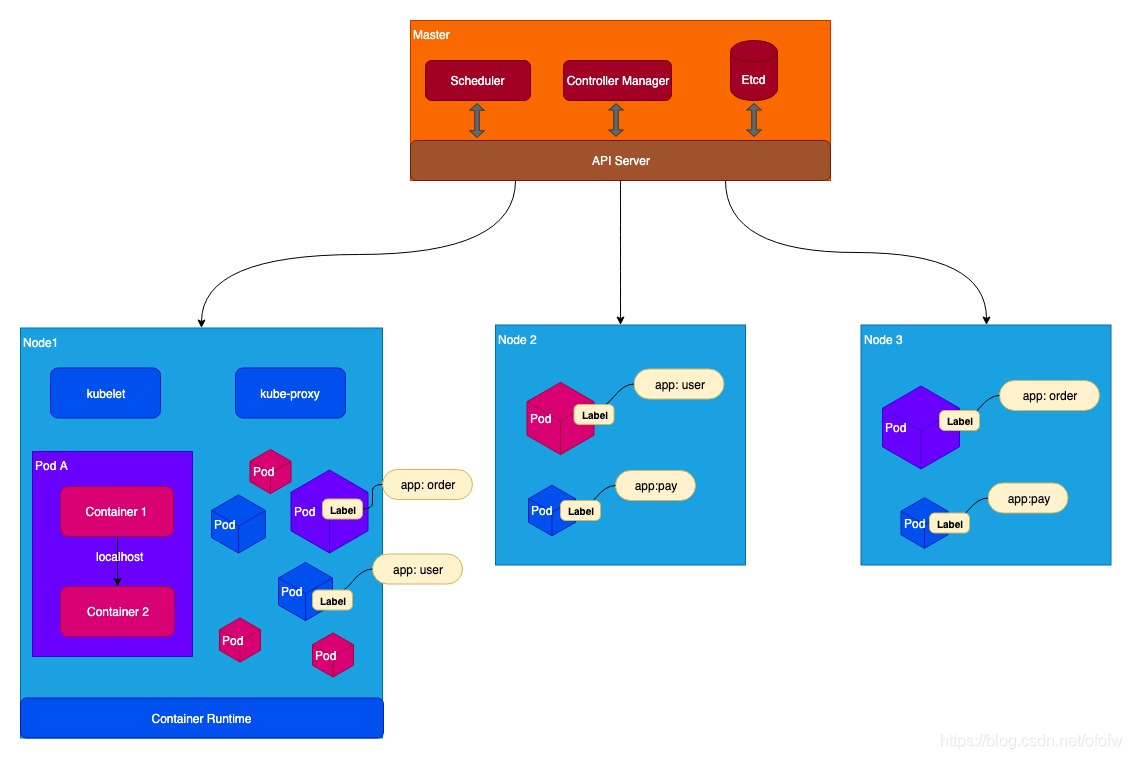
架构整体上由Master和Node两种节点组成。
Master是集群的“大脑”,主要负责调度。Master不存储应用容器,但它决定应用容器运行在哪个Node上。一个集群可以部署一个或者多个Master(多个Master主要是为了做高可用)。Master可以运行在物理机或者虚拟机上。
Node是k8s的资源池,负责运行容器应用、承接负载,由Master管理,一个Master一般对应多个Node节点。Node可以运行在物理机或者虚拟机上。
2、Master
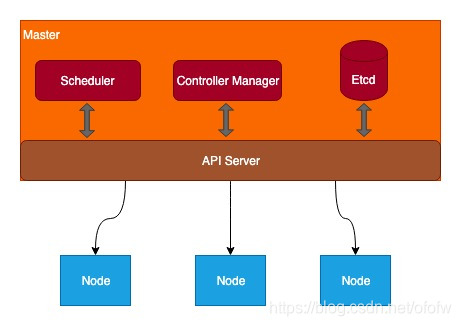
Master包括几个重要的组件:
Api Server:负责操作Api,属于K8s的网关,所有的组件都会跟Api Server连接,组件之间不直接通信,所有的请求都会经过Api Server。
Controller Manager:控制器,负责容器编排,保证资源的处于预期的状态。主要执行集群级别的功能,如复制组件、处理节点失败等。Controller Manager里面有数十个Controller,其中比较重要的两个Controller是Deployment和ReplicaSet(后面详细描述)
Scheduler:调度器,负责容器调度。根据集群的负载情况,决定容器放在哪个Node上运行。
Etcd:是一个分布式的存储系统,用于存储集群的配置信息和资源状态信息。
3、Node
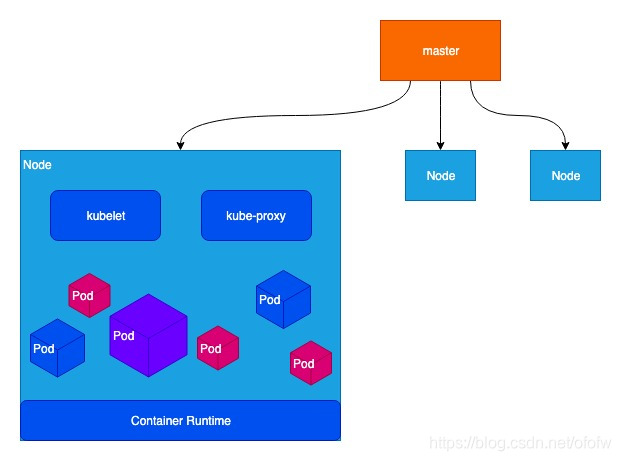
容器是运行在Node上的,Node的核心组件有:
kubelet:kubelet是Node的总管家,负责运行、监控和管理运行在Node上的容器。在Node上的操作指令都由kubelet执行。
Pod:k8s不直接管理容器,而是将容器封装在Pod里。Pod是k8s的最小资源和调度单元。
Container Runtime:容器运行时,是容器运行环境,k8s支持Docker,也支持前文提到的CoreOS公司的rkt以及其他容器。
PS:这三个组件关系很密切,前文提到的Master的Scheduler在确定某个容器放在哪个Node上运行以后,就会通过Api Server把相关信息传递给kubelet,kubelet就会去调Container Runtime去配置和启动这个Pod。
kube-proxy: 代理服务。负责负载均衡,在多个Pod之间做负载均衡。
4、Pod
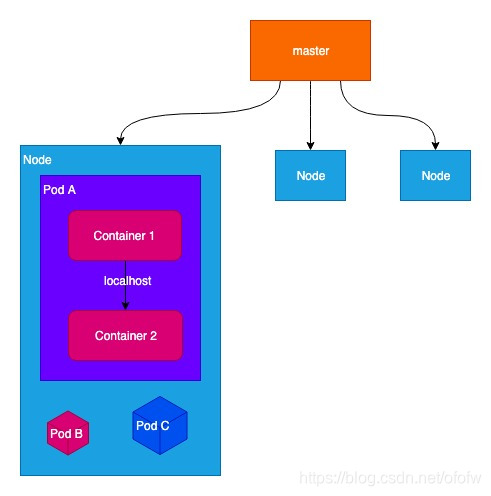
Pod实际上也是一个容器,这个容器里面装的是Docker创建的容器。它是一个独立的沙箱环境,有自己的IP和hostname,可以理解为传统环境中的虚拟机的角色。
Pod内部可以有一个或者多个容器。在部署的是时候,通常一个Pod部署一个服务,或者部署一组关联性比较强的服务。比如某个服务A需要搭配一个日志收集的服务,服务A和日志收集服务有非常强的关联性,那么就可以把这两个服务放在同一个Pod进行部署。
Pod内部共享同一个运行环境,内部的容器之间的访问使用localhost的方式,跟访问本地服务一样。但这也意味着一个Pod部署多个服务的时候不能使用相同的端口号。
5、Labels
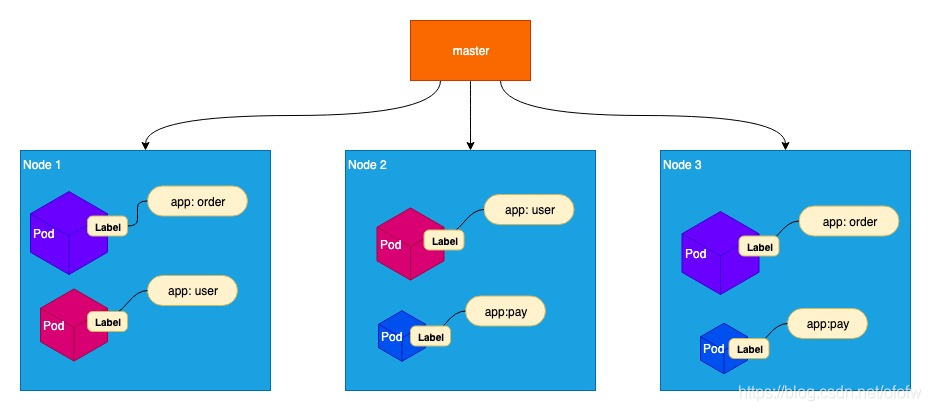
Labels是标签,标签是用来对Pod进行分组的,可以是任意的键值对。比如上图的Labels以app为key,并分别以order、user、pay做value对订单、用户、支付三个服务进行分组。
Labels有两个重要的用途(Deployment、Service后面详细介绍):
- 关联Deployment和Pod
- 关联Service和Pod
6、完整架构
六、k8s是如何实现灾难恢复的?
前文提到k8s有两个很重要的Controller是Deployment和ReplicaSet。
它们关系是Deployment管理的ReplicaSet,ReplicaSet管理Pod。如图所示:
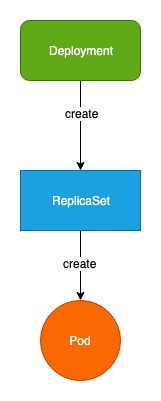
ReplicaSet是副本控制器。它的主要作用就是:控制Pod副本的数量,永远和预期设定的数量保持一致。 如果一组Pod(即一个服务集群)副本数设置的为3,那么ReplicaSet将会永远保证实际副本数等于3。当其中一个Pod故障宕机时,ReplicaSet会马上重建一个Pod,达到故障恢复的目的。
Deployment是部署对象。Deployment管理ReplicaSet,是ReplicaSet的实际操作者。
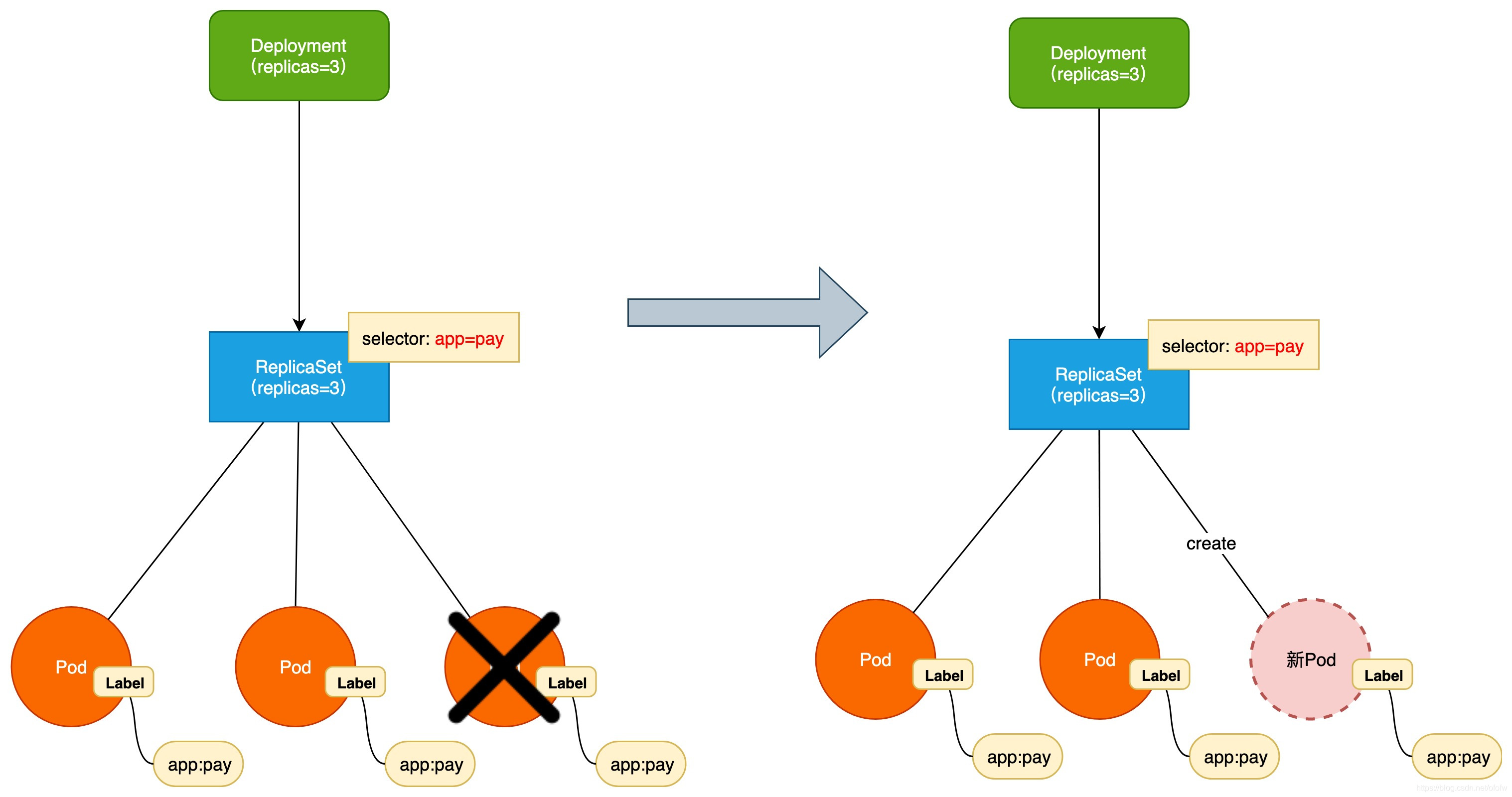
ReplicaSet是如何知道哪些Pod是一组(及属于同一个服务集群)呢?答案是通过前文提到的Labels(标签),在创建Pod时可以为其定义一个标签或多个标签。比如下图定义label为app:pay,ReplicaSet便可以通过标签选择器Selector选择所有label为app:pay的Pod为同一组Pod。如果把Pod上的label类比喻为数据库表中的数据,那么这个标签选择器Selector就类似于sql的where条件。
七、k8s是如何实现服务的扩/缩容的?
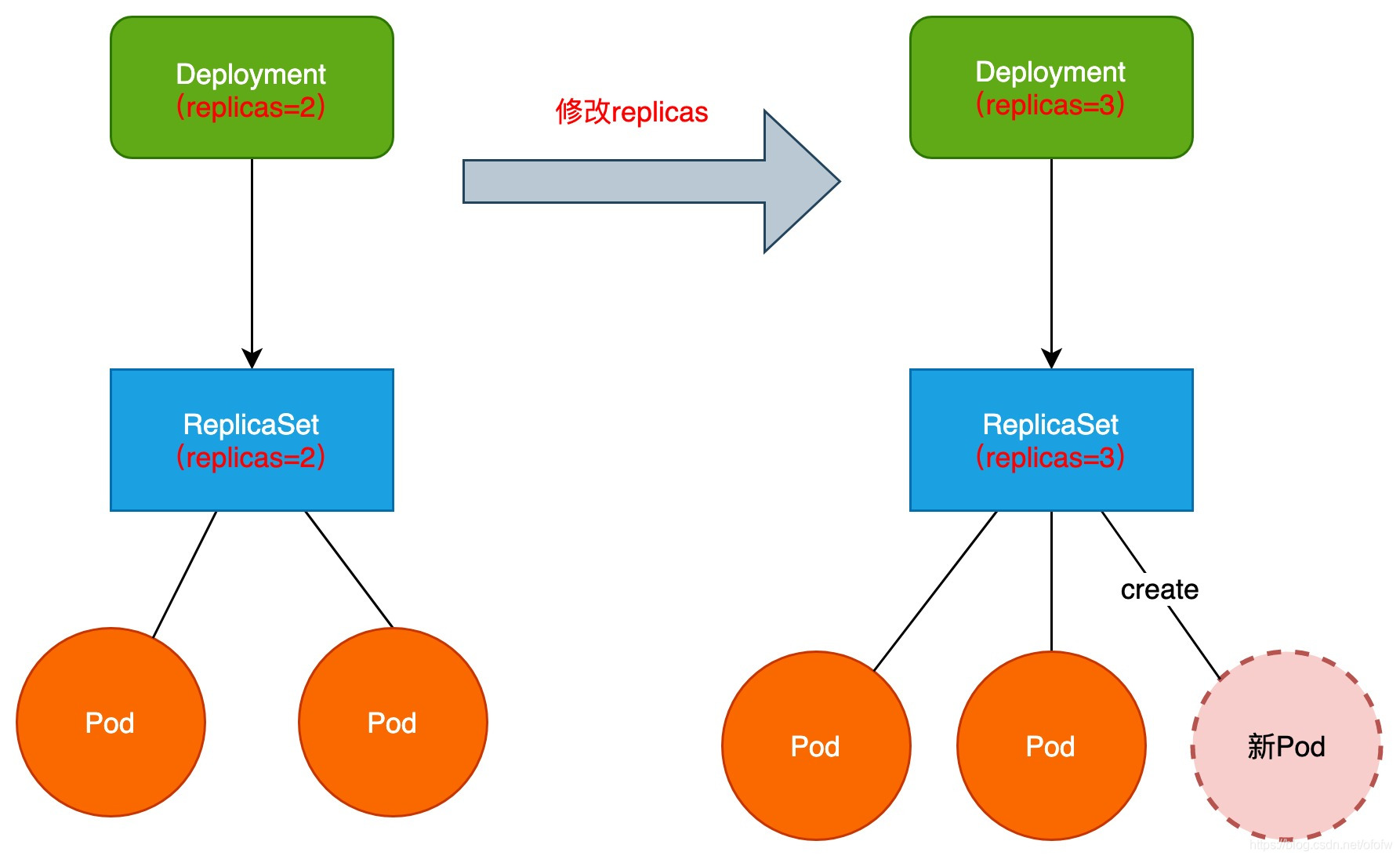
k8s要实现服务的扩/缩容是非常容易的,扩/缩容对应的实际上是Pod数量的增加和减少。所以要实现服务的扩/缩容,只需要修改ReplicaSet的Pod的副本个数即可。
比如下图将Deployment的replicas(replicas用于定义集群中的期望的副本数)的值由2改为3,即把服务集群期望的副本数修改为3,Controller便会把修改后的replicas值同步到ReplicaSet中。ReplicaSet发现当前只有2个Pod,不满足3个副本的期望,就会创建一个新的Pod,达到3个副本的期望数量,最终实现“水平扩容”。
反之,如果将3改为2,则会删除一个Pod,达到2个副本的期望数量,最终实现”水平缩容“。
八、k8s是如何实现应用的滚动更新和回滚的?
为了保证版本发布过程中服务的可用性,k8s采用滚动更新的方式进行版本升级。
前文提到Deployment和ReplicaSet的架构关系是Deployment管理的ReplicaSet,ReplicaSet管理Pod。升级的过程实际上是Deployment建立新的ReplicaSet,再由ReplicaSet创建新的Pod。
如图所示:
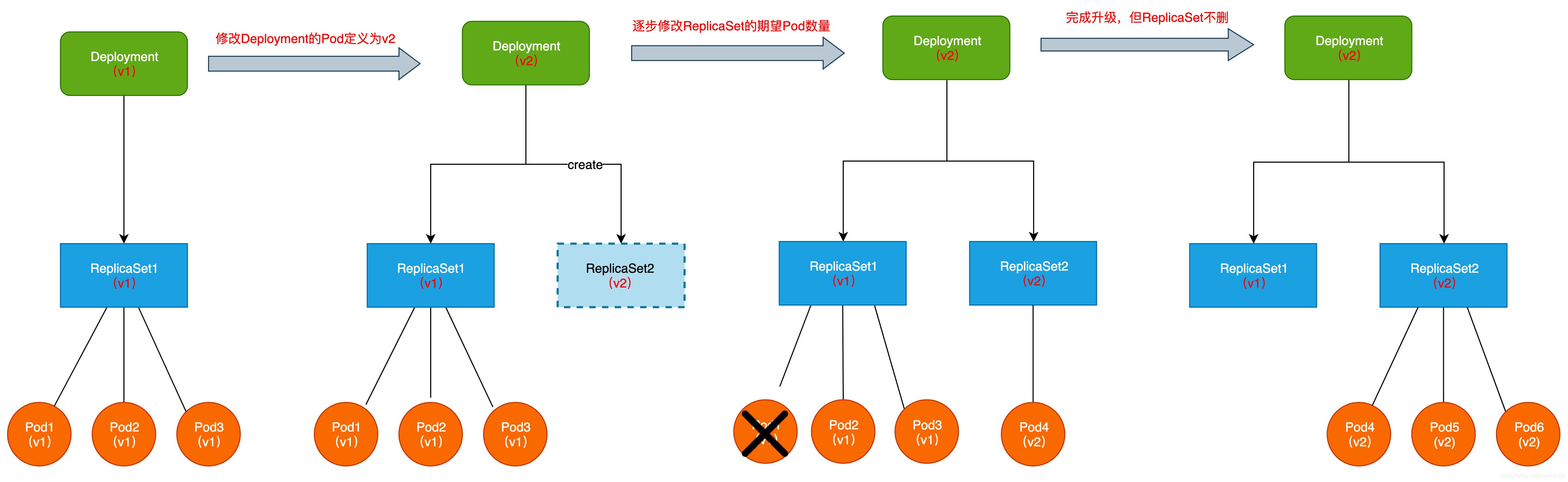
服务由v1升级为v2,修改Deployment定义的服务版本为v2后,Deployment就会创建一个新的ReplicaSet。
这个“新的ReplicaSet”(即ReplicaSet2)对应的版本是v2,初始管理的Pod副本数量是0。
接着逐步删除“旧的ReplicaSet”(即ReplicaSet1)的控制的Pod,同时在ReplicaSet2上创建新的Pod。
最终ReplicaSet1下旧的Pod(Pod1、Pod2、Pod3)全部被删除,在ReplicaSet2上创建出同等数量的新的Pod(Pod4、Pod5、Pod6),完成v1到v2的升级。
升级完成后,旧的ReplicaSet不会被删除,这样便于回滚。
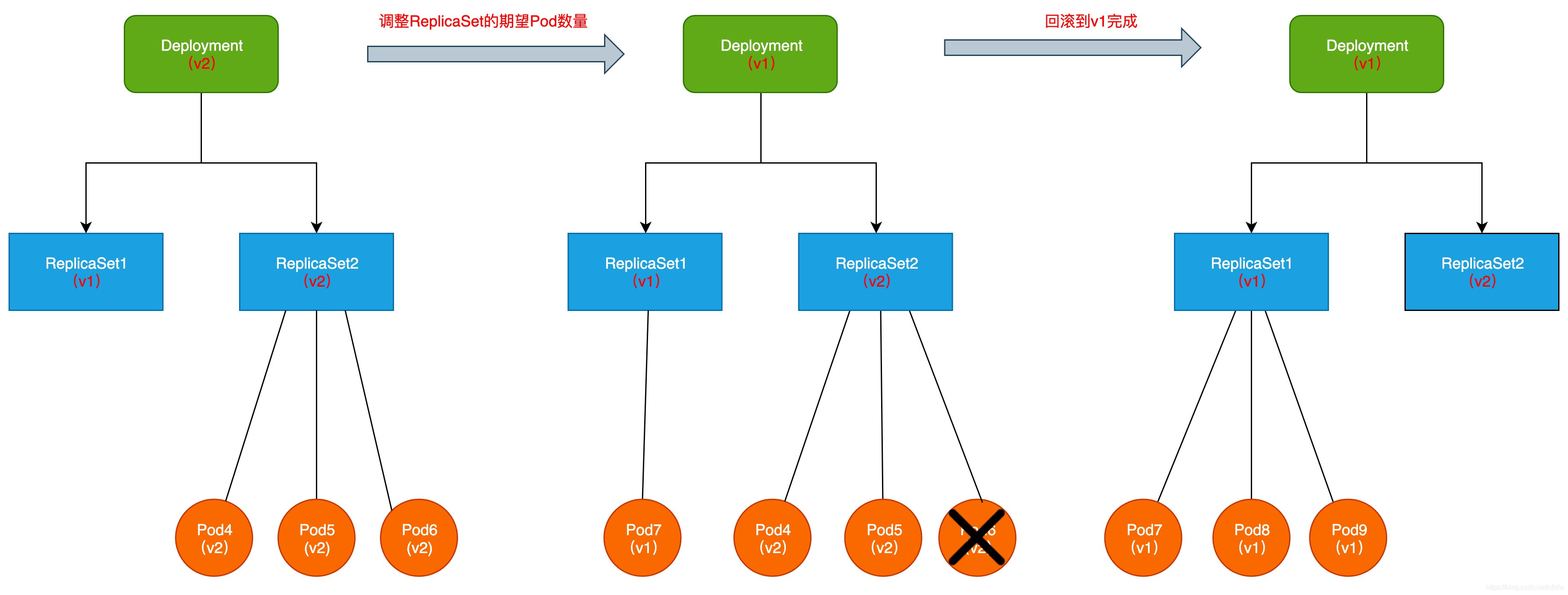
回滚的过程与升级类似,如果v2有问题,需要回滚到v1。这时候因为ReplicaSet1并没有被删除,所以不需要重新创建新的ReplicaSet,而是只需要将ReplicaSet期望的Pod副本数改回来即可。
回滚过程如图所示:
九、k8s是如何实现服务的发现和负载均衡?
前文提到,应用服务运行在Pod上,Pod是一个独立的沙箱环境,有自己的IP和hostname。但是在应用服务宕机或者滚动升级的时候,Pod都会被销毁后创建一个新的Pod,IP地址就会发生变化,Pod是有生命周期的,Pod的IP是不稳定的。另外,Pod本质上也是一个进程,没有对应的物理网卡。所以Pod无法直接对外提供服务,需要服务发现。
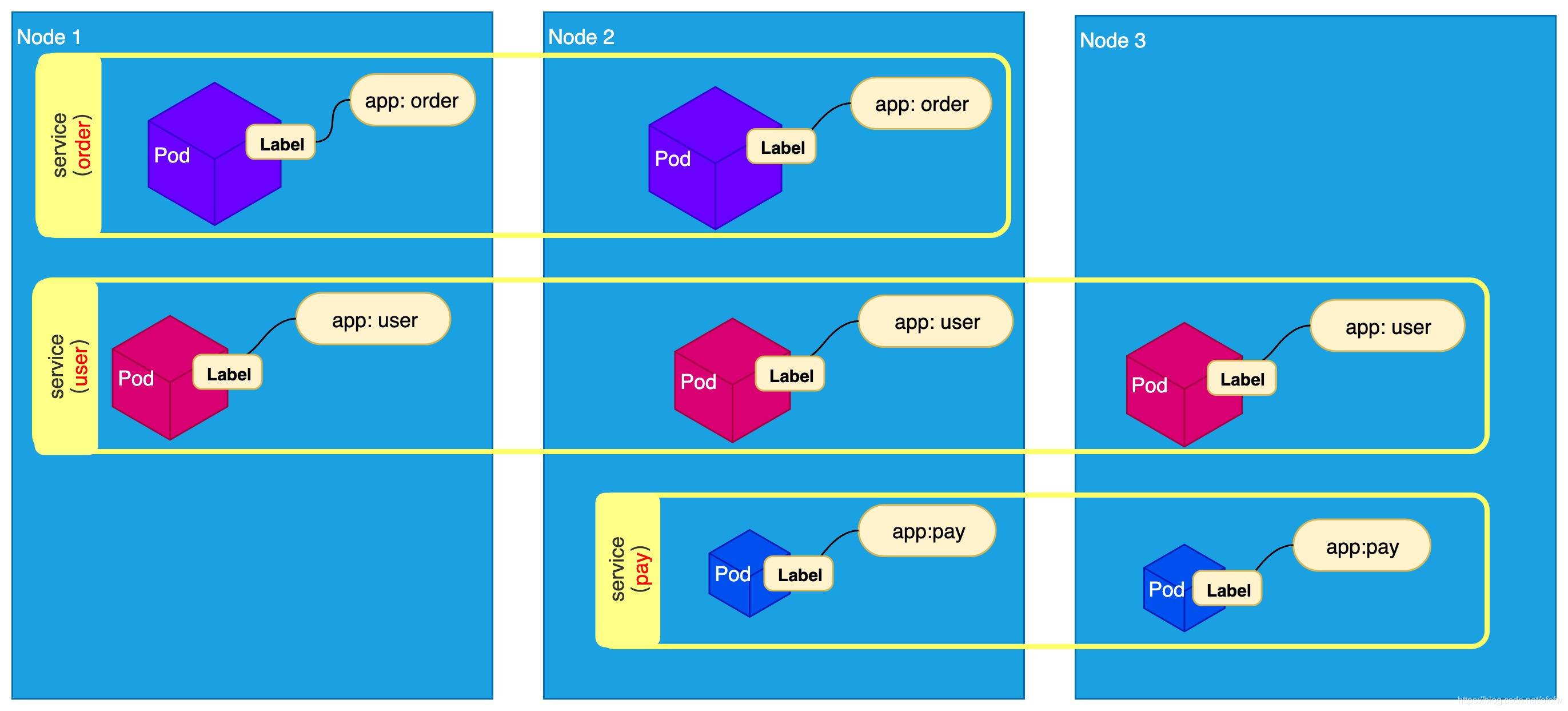
Service:服务发现完成的工作,是针对客户端访问的服务,找到对应的的后端服务实例。Service对象便是k8s中负责服务发现和负载均衡的资源对象。每个Service会对应一个集群内部固定的虚拟IP,集群内部通过这个虚拟IP访问一个服务。
Service和Pod也是通过标签(Labels)来进行关联,这个实现方式上和Deployment类似,但Service和Deployment功能上是有差异的,Deployment保证应用服务集群的Pod数量,Service解决如何访问应用服务的问题。
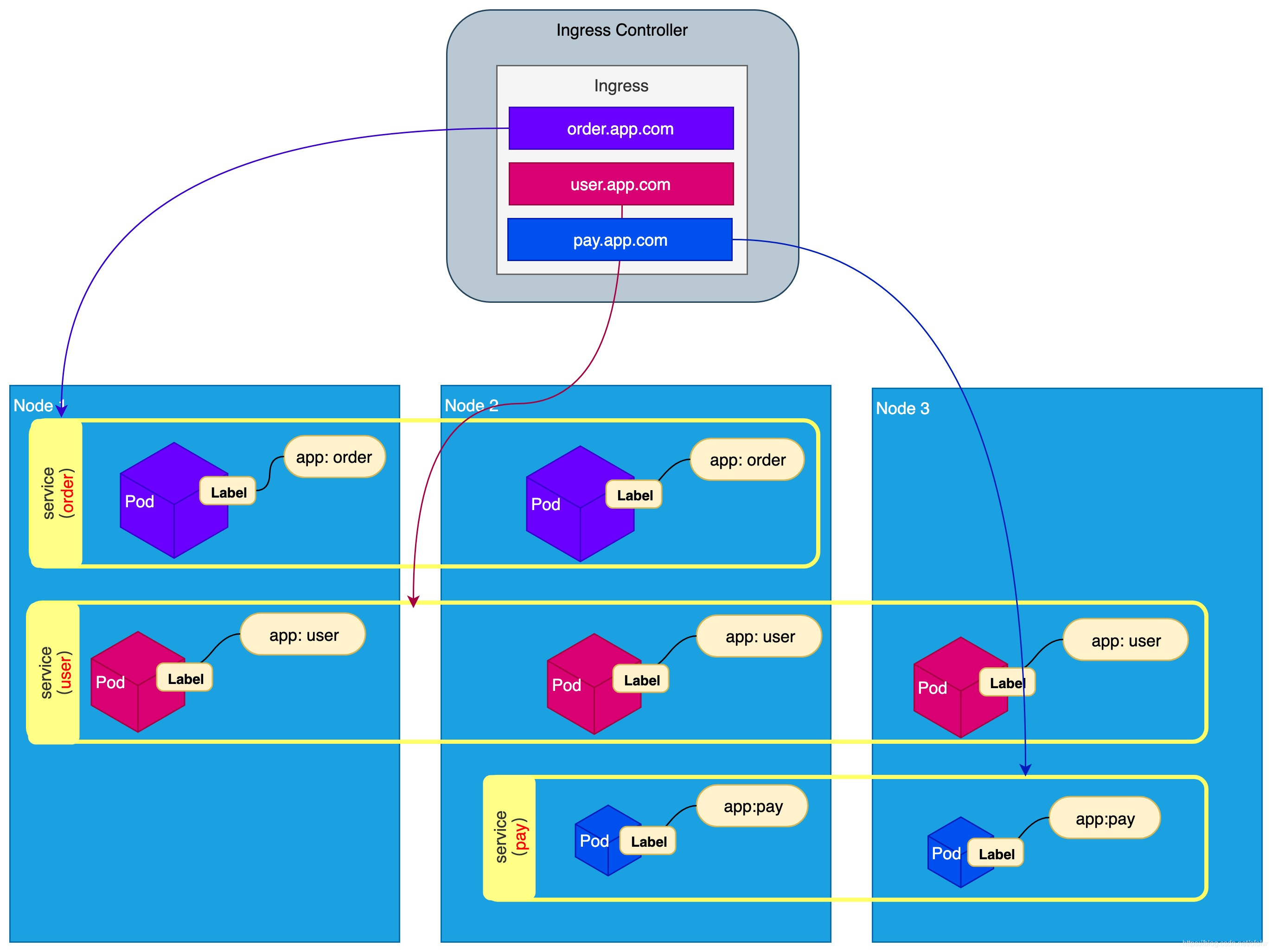
Ingress:虽然Service解决了服务发现和负载均衡的问题,但是Service的虚拟IP也是仅限于k8s集群内通信的,集群外不可达。要将集群外的访问流量引入集群内部,就需要用的Ingress对象。可以理解为Service是Pod的代理,而Ingress是Service的代理。
Ingress包括两个组件:Ingress和Ingress Controller。
- Ingress是反向代理的规则,描述具体的路由规则。用来定义某个HTTP/S请求应该被转发到哪个Service上
- Ingress Controller是具体的实现,负责解析Ingress定义的规则,并将接受到流量按照规则转发到对应的Service。可以理解为Ingress Controller是Ingress的实现。
Traefik:k8s并不自带Ingress Controller,它只是一种标准,具体的实现有很多种,需要另外安装。比较常用的有Nginx和Traefik。Traefik和Nginx差不多,也是一种反向代理、负载均衡软件。Traefik因为其轻量、高性能、支持动态配置,而且与k8s结合的非常好等特性目前已经成为k8s架构下主流的网关。