网址:http://www.szse.cn/disclosure/supervision/check/index.html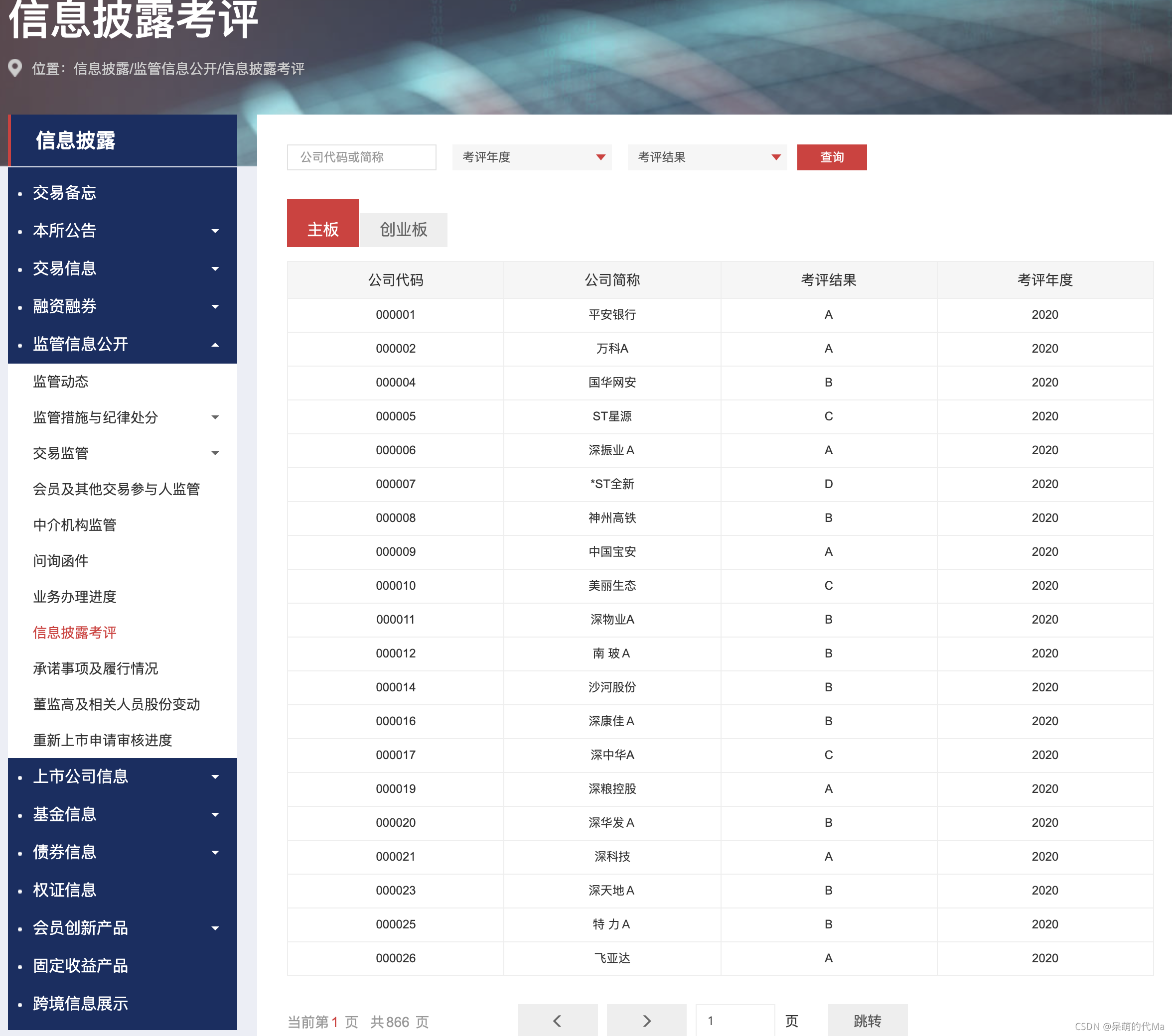
步骤一:selenium爬虫代码
import time
from selenium import webdriver
option = webdriver.ChromeOptions()
option.add_argument('--disable-gpu')
option.add_argument('lang=zh_CN.UTF-8')
# option.add_argument('headless') # 无界面
prefs = {
"profile.managed_default_content_settings.images": 2, # 禁止加载图片
# 'permissions.default.stylesheet': 2, # 禁止加载css
}
option.add_experimental_option("prefs", prefs)
browser = webdriver.Chrome(options=option)
browser.implicitly_wait(10) # 等待元素最多10s
browser.set_page_load_timeout(10) # 页面10秒后强制中断加载
browser = webdriver.Chrome(options=option)
browser.get("http://www.szse.cn/disclosure/supervision/check/index.html")
time.sleep(3)
all_page = 866 # 全部的界面数量
i = 1
while all_page != 0:
# 得到数据
try:
data_div = browser.find_element_by_id("1760_zsn_nav1").find_element_by_class_name("reporttboverfow-out")
with open("supervision.csv", 'a') as file:
for tr_data in data_div.find_elements_by_tag_name("tr")[1:]:
text = tr_data.text
file.write(",".join(text.split(' ')) + '\n')
except Exception as e:
print(e)
# 下一页
next_page_button = browser.find_element_by_class_name("next")
next_page_button.click() # 这里模拟点击
all_page -= 1
print("finish page " + str(i))
i += 1
time.sleep(3) # 程序中断3秒,这是为了限制爬虫的速率
步骤2:清洗数据
由于爬取后的数据有很多数据被split(" ")误伤了,因此这里是为了解决这个问题
with open("supervision.csv") as file:
lines = file.readlines()
with open("super.csv", 'w') as write_file:
for line in lines:
line = line.split(',')
if len(line) == 4:
write_file.write(",".join(line))
else:
my_list = []
my_list.append(line[0])
my_list.append("".join(line[1:line.__len__() - 2]))
my_list.append(line[line.__len__() - 2])
my_list.append(line[line.__len__() - 1])
write_file.write(",".join(my_list))
print(line)
步骤3. 整理格式并导出excel
import pandas as pd
df = pd.read_csv("super.csv", header=None, )
df.columns = ['公司代码', '公司简称', '考评结果', '考评年度']
df.drop_duplicates(inplace=True)
df.to_excel("supervision.xlsx", index=False)
附:百度网盘-信息考评数据文件
链接: https://pan.baidu.com/s/1s9n5pD1pUsldWM_zAl6BYg 提取码: 3fsf