Innodb存储引擎
1 Innodb存储引擎索引数据结构
B+树
2 B+树与hash表结构、二叉树、红黑树、B树的区别?
hash表结构,hash结构查找非常快,但是无法支持范围查找
二叉树是非平衡树,当有序插入时,会形成链表结构,树的高度太高
红黑树虽然是平衡树,但是每个节点只能存储一个数据,树的高度会随着数据增加而增长,效率依然不高
B树比较符合,但是每个叶节点都存储了整条数据,空间利用率不够;并且不同分支的叶子节点没有关联,这不利于范围查询
B+树优化了B树,只有叶子节点存放数据,则每个叶节点就能存储更多的索引数据,且相邻叶子节点之间相互存储的彼此的地址,可以支持范围查找
3 聚簇索引、覆盖索引
聚簇索引不是单独的索引类型,而是一种数据存储方式,是指叶子节点包含了所有数据的索引,比如Innodb引擎中表的主键索引
覆盖索引不是索引,而是指查询的列全部被索引包含
4 Innodb与MyIsam的区别
- MyIsam的数据和索引是分开存储的,索引存在MYI文件中,数据存在MYD文件中。
Innodb的索引和数据是存在同一个文件中,数据结构存放在frm文件中,数据和索引在idb文件中- MyIsam不支持事务,Innodb支持,这也决定了count(*)时,MyIsam可以直接得到结果,但Innodb需要去统计,因为在不同事务中的结果是不一样的。
- InnoDB支持表、行(默认)级锁,而MyISAM只支持表级锁
- InnoDB表必须有唯一索引(如主键)(用户没有指定会自己找/创建一个隐藏列Row_id来充当默认主键),而Myisam可以没有
5 后台线程
- master thread :核心线程
- purge thread :用于回收已经使用并分配的undo页,使用show variables like 'innodb_purge_threads’查看
- page clearer thread :作用是脏页的刷新操作放到单独的线程中,以减轻master thread的负担,进一步提高性能
master thread
具有最高的线程优先级。有多个循环组成:主循环(loop)、后台循环(background loop)、刷新循环(flush loop)、暂停循环(suspend loop)。
主循环(loop)
主循环有两个操作,每秒和每10秒的操作
每秒操作的工作:
1)将redo log buffer刷新到redo log,即使事务还没提交(总是)这也是为什么事务再大,提交依然很快的原因
2)合并插入缓冲(可能)
3)至多刷新100个缓冲池的脏页到磁盘(可能)
4)如果当前没有用户活动,则切换到后台循环(可能)
每10秒操作的工作:
1)刷新100个脏页到磁盘(可能)
2)合并至多5个插入缓冲(总是)
3)将redo log buffer刷新到redo log(总是)
4)删除无用的undo log(总是)
5)刷新100个或者10个脏页到磁盘
后台循环(background loop)
当主循环没有用户活动或者数据库关闭时,就会切到后台循环。
1)删除无用的undo log(总是)
2)合并20个插入缓冲(总是)
3)跳回主循环(总是)
4)不断刷新100个页,直到符合条件(可能,跳到flush loop中完成)
刷新循环(flush loop)
不断刷新100个页,直到符合条件.如果flush loop也没有事情时,会切换到suspend loop
暂停循环(suspend loop)
将主线程挂起,等待事件发生
1.0.x之后,将许多硬编码的值改为可配置,甚至自适应;1.2.x之后,进一步将磁盘刷新工作放到单独的线程 page cleaner thread中。
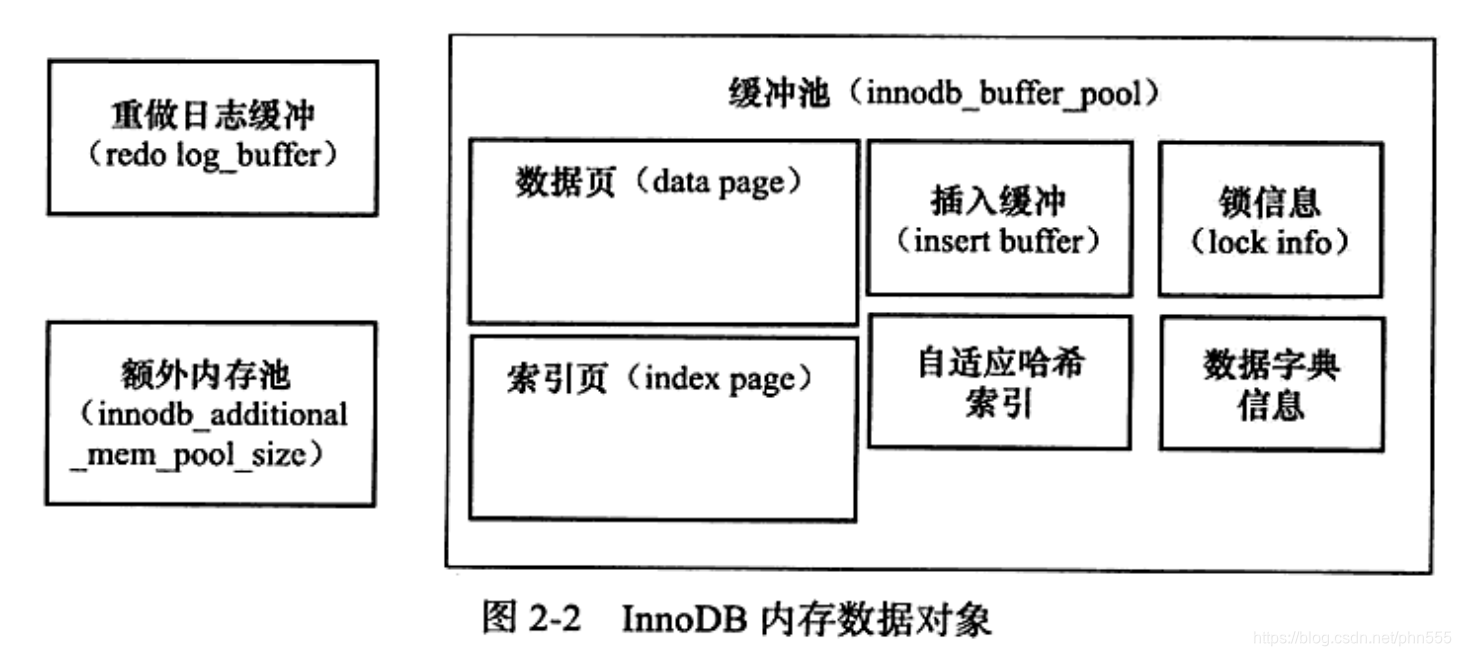
6 buffer pool
缓冲池用于弥补磁盘速度慢对数据库性能的影响。数据库中对页的操作,首先修改缓冲池中的页,在通过一定的频率刷新到磁盘。页从缓冲池刷新到磁盘的操作并不是每次页发生更新的时候触发,而是通过checkpoint的机制刷新回磁盘。
缓存池中包含索引页、数据页、插入缓冲、自适应哈希索引、innodb存储的锁信息、数据字典信息等
1 查看缓冲池信息
show variables like ‘innodb_buffer_pool_%’ ; 查看缓冲池的相关信息
select * from INNODB_BUFFER_POOL_STATS; 查看各个实例信息
| variable_name | value | des |
|---|---|---|
| innodb_buffer_pool_size | 15032385536 | 缓存池大小 |
| innodb_buffer_pool_instances | 16 | 缓存池实例个数 |
2 LRU List
Innodb引擎如何管理缓冲池?
通过LRU(最近最少使用) 算法来进行管理。但是mysql对LRU做了优化,并不是简单的将读到的新页直接放到LRU列表首部,而是放到midpiont位置。midpiont大概是列表的5/8处,可以通过show variables like 'innodb_old%'查看。将该位置之后的成为OLD列表,将之前的成为NEW列表。
| variable_name | value | des |
|---|---|---|
| innodb_old_blocks_pct | 37 | midpiont的位置 |
| innodb_old_blocks_time | 1000 | midpiont的数据多久后放入首部默认1s,1s后如果还在则放到热端 |
为什么不使用传统的LRU算法呢?
如果直接将读取到的页放到LRU列表首部,那么某些sql操作(比如索引或数据的扫描操作)可能会使缓冲池中的页被刷出,从而影响缓冲池的效率。而这些操作通常仅本次需要,不是热点数据,如果将其插入LRU列表首部,很可能将真正的热点数据挤出列表,导致下次访问热点数据需要再次从磁盘读取。
那么读取到的页究竟什么时候才能放到LRU列表热端呢?
innodb_old_blocks_time,根据该值,在等待超过这个时间后,如果数据还在,才放到热端
unzip_LRU是怎么从缓冲池中分配内存的?
首先,unzip_LRU会对不同大小的页进行分别管理,再根据伙伴算法进行分配。
以需要从缓冲池获取4kb的大小为例:
首先检查4kb的unzip_LRU列表中是否有空闲页;
有,就直接使用
否则,检查8KB的unzip_LRU列表;
有则分为两个4KB的页,存放到4kb的unzip_LRU列表中;
没有,则从LRU列表获取一个16KB的空闲页,分为一个8KB和两个4KB.
3 Free List
Free List的作用
LRU列表用来管理已经读取的页,但数据库刚启动时,LRU列表时空的,这是页都存在Free List中。当需要从缓冲池分页时,首先从Free List中查找是否有空闲的页,如果有则从Free List中删除,添加到LRU list.否则,根据LRU算法,删除LRU末端的页,将该内存分给新的页。
page made young :当页从LRU列表的old部分加入到new部分时发生的操作。
page not made young :因为innodb_old_blocks_time的设置而导致页没有从old部分移动到new部分的操作
show engine innodb status查询信息解释
Per second averages calculated from the last 14 seconds 表示并不是事实的,而是最近14的数据库状态
BUFFER POOL AND MEMORY
Total large memory allocated 15392047104
Dictionary memory allocated 2930908
Buffer pool size 917504 缓冲池的页数 大小=917504 * 16kb
Free buffers 907333 Free list的页数
Database pages 10092 LRU list的页数
Pages made young 2420 LRU从old移动到new的页数
not young 1976 LRU被innodb_old_blocks_time阻止,没有移的页数
0.00 youngs/s 每秒操作多少次
0.00 non-youngs/s
Buffer pool hit rate 1000 / 1000 缓存池命中率,该值不应该小于95%
, young-making rate 0 / 1000 not 0 / 1000
LRU len: 10092, LRU list的页数 这个包含unzip_LRU的数量
unzip_LRU len: 0 压缩页的数量
3 Flush List
Flush List的作用
在LRU list中的页被修改后,该页称为脏页。这时数据库会通过checkpoint机制将数据刷会磁盘,而flush list中的页即为脏页列表。
脏页既存在于LRU list也存在与flush list。LRU list用来管理缓冲池中页的可用性,flush list用来管理将页刷新到磁盘,两者互不影响
查询Flush list:
select TABLE_NAME,SPACE,PAGE_NUMBER,PAGE_TYPE from INNODB_BUFFER_PAGE_LRU where OLDEST_MODIFICATION > 0;
4 redo log buffer
Innodb引擎首先会将重做日志缓存到redo log buffer,再根据一定的频率将数据写道redo log。redo log buffer不需要很大,一般每秒会刷一次到redo log。show variables like ‘innodb_log_buffer_size’;进行查看大小
下面三种情况会将redo log buffer刷新到redo log
- Mater Thread每秒会将redo log buffer刷新到redo log
- 每个事务提交时会将redo log buffer刷新到redo log
- 当redo log buffer剩余空间小于1/2时,会将redo log buffer刷新到redo log
5 额外的内存池
在对一些数据结构本身的内存分配时,需要从额外的内存池中申请,当该区域内存不足时,会从缓冲池申请。比如分配了缓冲池,但是每个缓冲池的帧缓冲还有对应的缓冲控制对象,这些对象记录了LRU、锁、等待的信息,而这些对象的内存需要从额外的内存池获取。
7 checkpoint
1 write ahead log 提前写日志策略
当事务提交时,先修改redo log,再修改页。当数据库宕机导致数据丢失时,通过redo log来完成数据恢复。
2 既然redo log拥有完整数据,为什么还要多此一举,将数据写道磁盘?
- 缓冲池无法缓存所有的数据
- redo log日志非常大后,运维成本太高。
- 当redo log日志太大后,利用redo log恢复数据也会非常慢
3 checkpoint解决了什么问题?
- 缩短数据库的恢复时间。 数据库宕机重启,不需要重做所有的日志,只需要重做checkpoint之后的数据
- 缓冲池不够用时,将脏页刷新到磁盘。 根据LRU算法,移除页如果为脏页,此时需要强制执行checkpoint,将数据刷回磁盘
- redo log不可用时,刷新脏页。 因为事务系统对redo log的设计是循环可用的,并不是让其无线增大。可重用的部分是指当宕机重启时,不需要再根据该部分的redo log,那这部分就是可以覆盖重用的。若此时redo log还需要使用,那么必须checkpoint,将缓冲池的页至少刷新到当前redo log的位置。
4 如何标记上次恢复到什么位置,本次从哪里开始恢复呢?
通过LSN(log sequence number) 标记版本,LSN是8个字节,每个页有LSN,redo log也有LSN,checkpoint也有LSN。
通过show engine innodb status可以看到:
Log sequence number 3277001970
Log flushed up to 3277001970
Pages flushed up to 3277001970
Last checkpoint at 3277001879
5 checkpoint类型
sharp checkpoint 发生在数据库关闭时,将缓冲池中的页刷回磁盘。
fuzzy checkpoint
1)Master Thread checkpoint: 差不多每秒或每10秒将缓冲池中的页按一定比例异步刷回磁盘。
2)flush_lru_list checkpoint: Innodb引擎需要保证LRU list中有一定数据量的空闲页可供使用。如果没有,就需要将末端的移除,若有脏页,需要刷回磁盘异步。可通过innodb_lru_scan_depth控制LRU list的可用页数量
3)Dirty page too mach checkpoint: 脏页数据太多,导致Innodb引擎强制执行checkpoint,刷新100页到磁盘。
show variables like ‘innodb_max_dirty_pages_pct’;可以看到触发比例,当脏页数量超过该值,就会触发。
4)Async/sync Flush checkpoint: 当redo log 不可用时,需要将一些页刷回磁盘。计算规则略。
8 Innodb关键特性
1 插入缓存
insert buffer并不是缓冲池的一部分,虽然缓冲池中有insert buffer的信息,但它和数据页一样,也是物理页的一个组成部分。
对于非聚集索引的插入和更新,不是每一次直接插入到索引页中,而是先判断插入的索引页是否在缓冲池中,如果在,则直接插入,如果不在,则先放入到一个inset buffer对象中。然后再以一定的频率和情况进行insert buffer与索引页的marge操作,这样通常能将多个插入合并到一个操作中,大大提升非聚集索引的插入性能
1 insert buffer使用需要同时满足两个条件
- 索引是辅助索引
- 索引不是唯一的
2 insert buffer可能带来的问题
- 如果应用使用了insert buffer,进行了大量的插入操作,这时突然宕机,那会有大量的insert buffer没有合到非聚集索引中去,因此恢复可能需要很长时间。
- 如果有大量的写操作,insert buffer会占用过多的缓冲池内存,默认最高可达1/2.可通过修改 IBUF_POOL_SIZE_PER_MAX_SIZE 来调整比例
3 insert buffer的实现原理
insert buffer也是一颗B+树,全局只有一颗,存放在共享表空间中。非叶子节点存放查询的search key 。
search key的结构 space|marker|offset
space:表示待插入记录所在的表空间的id;
marker:用于兼容老版本的Insert buffer
offset:表示页所在的偏移量
4 什么时候 marge insert buffer?
- 辅助索引被读到缓冲池时。
- insert buffer bitmap页追踪到该辅助索引已无可用空间时
- master thread每秒或每10秒的操作
5 change buffer
对insert buffer的升级,不仅insert可以,update和delete也支持。insert-insert buffer, delete-delete buffer, update-update buffer;可以使用innodb_change_buffer_max_size来调整比例,最高50%
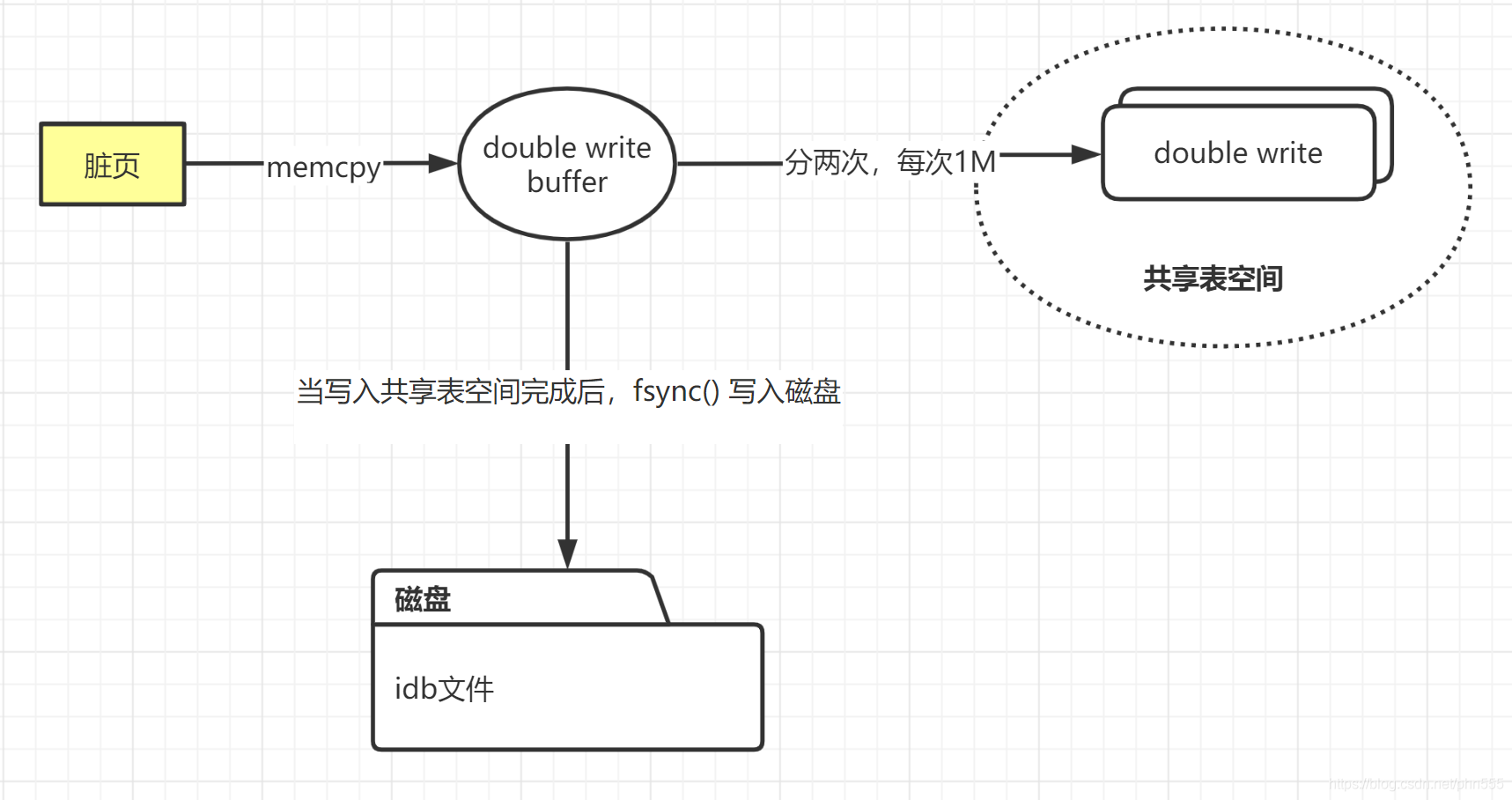
2 两次写(double write)
两次写为Innodb引擎带来数据页的可靠性。比如innodb引擎正在读取某个页写入表,而这个页只写了一部分,然后就宕机了,这种情况称为部分写失效。发生写失效时,可以使用redo log进行数据恢复。但是redo log 中记录的是对页的物理操作,如果这个页本身已经损坏,则重做就没有意义。所以在应用重做日志之前,需要有一个副本,在发生写失效时,先根据该副本还原该页,在进行重做。这就是doublewrite
1 double write的具体过程
double write由两部分组成,一部分是内存中的doublewrite buffer,大小2M,另一部分是物理磁盘上共享表空间的128个页,也是2M.在对缓冲池的脏页进行刷新时,并不是直接写入磁盘,而是先将脏页数据复制(memcpy函数)到内存的doublewrite buffer中,之后通过doublewrite buffer再分两次,每次1M写入物理磁盘上共享表空间,然后同步(fasyn函数)磁盘。
3 自适应哈希索引AHI
innodb引擎会监控对表上各索引页的搜索,自动根据访问频率和模式来为某些热点页建立哈希索引。
4 异步I/O
AIO除了异步优势外,还有一个优势是可以进行IO Merge操作,也就是将多个IO合并为一个IO,这样可以提高IOPS性能。
5 刷新邻接页
当刷新一个脏页时,Innodb引擎会检查该页所在区的所有页,如果是脏页,则一起刷新。根据AIO,可以将多个IO操作合并为一个,在传统机械磁盘上有明显优势。但是对于固态硬盘,则不一定需要。