Pearson相关系数
两个变量之间的皮尔逊相关系数定义为两个变量之间的协方差和标准差的商
从式子(1)能看到,Pearson 系数的取值范围在-1~+1之间,其中1是总正线性相关性,0是非线性相关性,并且-1是总负线性相关性。Pearson相关系数的一个关键数学特性是它在两个变量的位置和尺度的单独变化下是不变的。也就是说,我们可以将X变换为a+bX并将Y变换为c+dY,而不改变相关系数,其中a,b,c和d是常数,b,d > 0。请注意,更一般的线性变换确实会改变相关性。
Pearson 系数的使用场景:
- 适用于线性相关的情形
- 样本中存在的极端值对Pearson积差相关系数的影响极大,因此要慎重考虑和处理,必要时可以对其进行剔出,或者加以变量变换,以避免因为一两个数值导致出现错误的结论。
- Pearson积差相关系数要求相应的变量呈双变量正态分布,注意双变量正态分布并非简单的要求x变量和y变量各自服从正态分布,而是要求服从一个联合的双变量正态分布。
Spearman相关系数
Spearman相关系数衡量两个变量的依赖性的无母数 指标,定义如下
原始数据依据其在总体数据中平均的降序位置,被分配了一个相应的等级。 如下表所示:
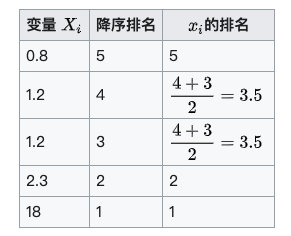
实际应用中, 变量间的连结是无关紧要的, 于是可以通过简单的步骤计算
Spearman相关系数对数据的分布没有要求,所以应用范围相比Pearson更加广泛,但是统计效能相比Pearson对更低一些,也就是不容易检测出两个变量之间存在相关关系。如果数据中没有重复值, 并且当两个变量完全单调相关时,斯皮尔曼相关系数则为 +1 或 −1 。
Kendall相关系数
Kendall 是一种秩相关系数,用于反映分类变量相关性的指标,适用于两个变量均为有序分类的情况。Kendall 系数是基于协同的思想。对于
相关性质:
- 如果两个排名之间的一致性是完美的(即两个排名相同),则系数的值为1。
- 如果两个排名之间的分歧是完美的(即,一个排名与另一个排名相反),则系数具有值-1。
- 如果X和Y是独立的,那么我们期望系数近似为零。
各种系数的计算
这里我们使用 python 来实战各种系数的计算,输入的数据如下
import numpy as np
import pandas as pd
A = np.array([
[1,2,3],
[4,5,6],
[3,2,4],
[-4,2,9]
])
A = pd.DataFrame(A)
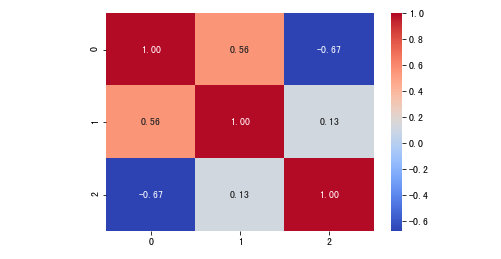
Pearson相关系数
import seaborn as sns
sns.heatmap(
A.corr("pearson"),
annot=True,
cmap="coolwarm",
fmt='.2f'
)
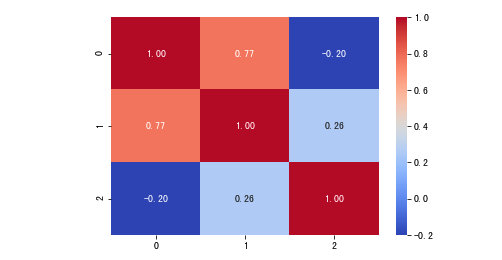
Spearman相关系数
import seaborn as sns
sns.heatmap(
A.corr("spearman"),
annot=True,
cmap="coolwarm",
fmt='.2f'
)
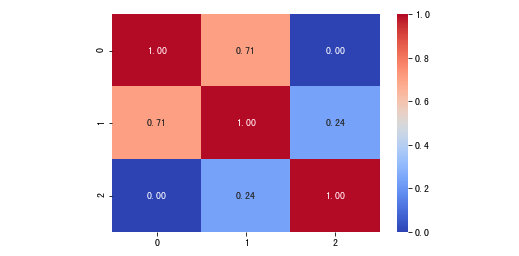
Kendall相关系数
import seaborn as sns
sns.heatmap(
A.corr("kendall"),
annot=True,
cmap="coolwarm",
fmt='.2f'
)
注意:三种相关系数都是对变量之间相关程度的度量,由于其计算方法不一样,用途和特点也不一样。
- Pearson相关系数是在原始数据的方差和协方差基础上计算得到,所以对离群值比较敏感,它度量的是线性相关。因此,即使Pearson相关系数为0,也只能说明变量之间不存在线性相关,但仍有可能存在曲线相关。
- Spearman相关系数和Kendall相关系数都是建立在秩和观测值的相对大小的基础上得到,是一种更为一般性的非参数方法,对离群值的敏感度较低,因而也更具有耐受性,度量的主要是变量之间的联系。
参考
[1] 维基百科:皮尔逊积矩相关系数
[2] 维基百科:斯皮尔曼等级相关系数
[3] CSDN:肯德尔等级相关系数
[4] 知乎:统计学习--三种常见的相关系数
版权声明:本文为weixin_42545292原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。