环境
import requests
from bs4 import BeautifulSoup
from lxml import etree
一、session登录github
先到该页面下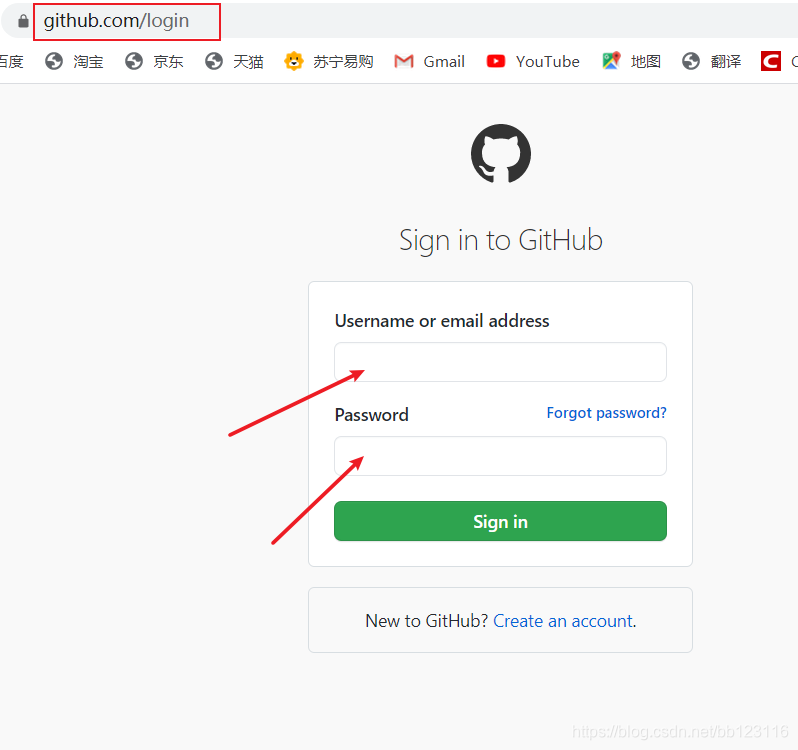
先F12到network下 输入email和password network下会出现session文件
只有该文件是post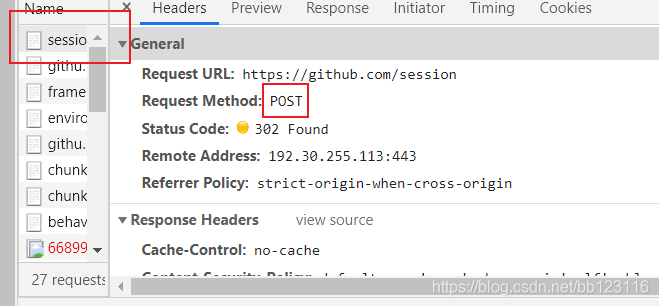
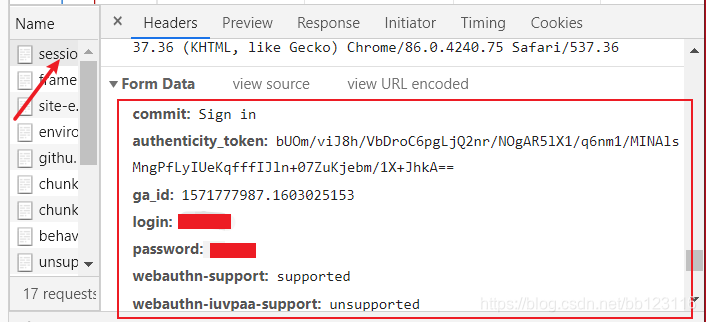
要传入commit、authenticity_token、login、password这几个重要参数
(具体为什么其他不用传我还不知道 嘿嘿)
并且authenticity_token需要从页面中爬取获得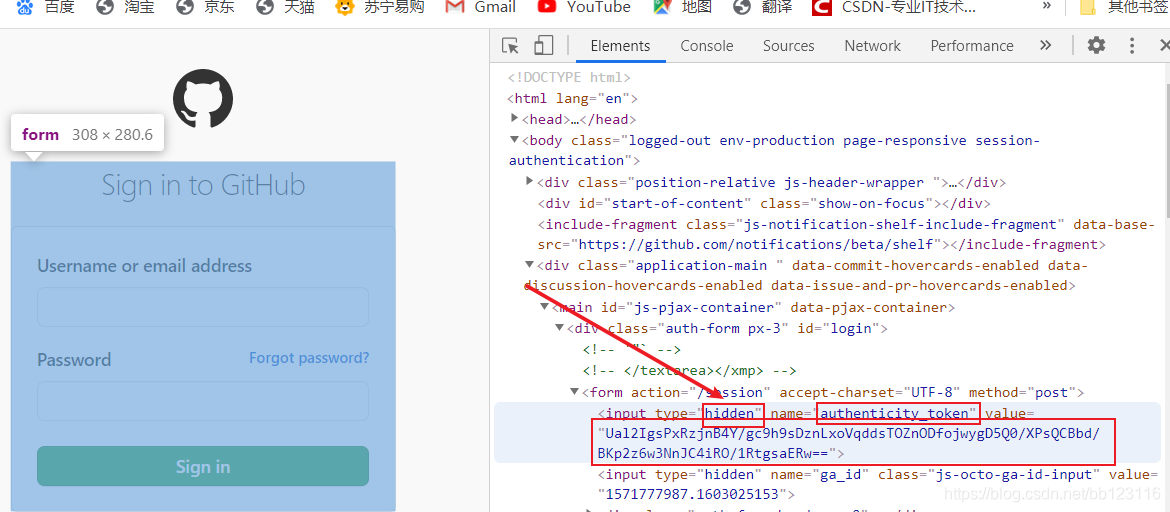
具体代码:
session=requests.Session()
url="https://github.com/login"
res=session.get(url)
html = BeautifulSoup(res.text, 'html.parser')
token = html.find('input',{'name':'authenticity_token'})['value'] # 获取到token的值
data={
'commit': 'Sign in',
'authenticity_token':token,
'login': '你的邮箱',
'password': '你的密码'
}
二、登录后页面的爬取
具体代码:
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'
}
url1='https://github.com/session'
post=session.post(url1,data=data,headers=headers)
#soup=BeautifulSoup(post.text,'html.parser')
html1 = etree.HTML(post.text)
html_data=html1.xpath('//*[@id="repos-container"]/ul/li/div/a/span[1]/text()')[1]
html_data2=html1.xpath('//*[@id="repos-container"]/ul/li/div/a/span[2]/text()')[1]#因为这里有两个该标签 输出结果为两次所以要加【1】
print(html_data)
print(html_data2)
这里的url1必须重新赋值 并且网址后面要带/session 虽然在浏览器中带不带都会出现登录页面,但是这里不加输出结果就会为空
输出结果展示:
对应爬取的仓库名字: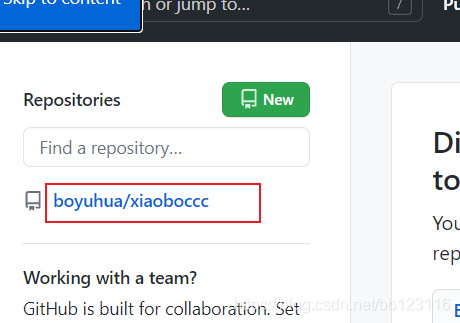
版权声明:本文为bb123116原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。