

本文字数:11845字
预计阅读时间:30分钟
❝用最通俗的语言,描述最难懂的技术
锁是什么
用于防止多线程访问同一份资源而造成资源竞争的计算机锁(生产者消费模式是衍生品,请勿杠精)
锁的动作
既然是锁,那肯定就是有两个动作,一个是加锁,另外就是解锁
常见锁的说明
自旋锁/空转锁(Spin Lock)
伪代码
while(抢锁(lock) == 没抢到) {
}只要没有锁上,就不断重试。很显然,如果某个线程长期持有该锁,那么这个线程就会一直不停的检查是否能够加锁,浪费CPU做无用功
所以,没有必要一直尝试加锁,因为只要锁的状态没有改变,加锁操作就肯定失败。理论上抢锁失败后只要锁的持有状态一直没有改变,那就让出CPU给别的线程进行执行就好了
互斥锁(Mutual-Exclude Lock)
伪代码
while(抢锁(lock) == 没抢到) {
// 当前线程先去睡了,当这把锁的状态发生改变时再唤醒(lock);
}操作系统负责线程调度,为了实现锁的状态发生改变时再唤醒,就需要把锁也交给操作系统管理
所以互斥锁的加解锁操通常都需要涉及到上下文切换,操作花销自然比自旋锁要大一些
信号量
1965年,荷兰学者Dijkstra提出的信号量(Semaphores)机制是一种卓有成效的进程同步工具
// 初始化同步对象
dispatch_semaphore_t lock = dispatch_semaphore_create(1);
// 对同步对象进行-1操作
dispatch_semaphore_wait(lock, DISPATCH_TIME_FOREVER);
// ... 你想要的动作
// 对同步对象进行+1操作
dispatch_semaphore_signal(lock);是一个同步对象,用于保持在0至指定最大值之间的一个计数值。当线程完成一次对该semaphore对象的等待(wait)时,该计数值减一;当线程完成一次对semaphore对象的释放(release)时,计数值加一。
当计数值为0,则线程等待该semaphore对象不再能成功直至该semaphore对象变成signaled状态。semaphore对象的计数值大于0,为signaled状态;计数值等于0,为nonsignaled状态.
锁有什么用
防止多线程访问同一份资源而造成资源竞争出现程序异常
如何使用
我们先看下iOS下的锁都有那些,从加解锁执行的时间复杂度,这个复杂度并不代表锁的效率,下文会举例说明
OSSpinLock
OSSpinLock lock = OS_SPINLOCK_INIT;
for (int i = 0; i < count; i++) {
OSSpinLockLock(&lock);
// ...
OSSpinLockUnlock(&lock);
}该锁是自旋锁,由于优先级反转问题,已经被Apple放弃使用,具体请参考这里
pthread_mutex
一组跨平台的组件
pthread_mutex_t lock;
pthread_mutex_init(&lock, NULL);
pthread_mutex_lock(&lock);
// ...
pthread_mutex_unlock(&lock);NSCondition
iOS下封装的互斥锁和条件变量的高级条件变量对象
NSCondition *lock = [NSCondition new];
[lock lock];
// ...
[lock unlock];NSLock
iOS使用跨平台封装的高级互斥锁
NSLock *lock = [NSLock new];
[lock lock];
// ...
[lock unlock];dispatch_semaphore
GCD组件下的信号量
dispatch_semaphore_t lock = dispatch_semaphore_create(1);
dispatch_semaphore_wait(lock, DISPATCH_TIME_FOREVER);
// ...
dispatch_semaphore_signal(lock);pthread_mutex(recursive)
跨平台下的另一种类型的递归锁
pthread_mutex_t lock;
pthread_mutexattr_t attr;
pthread_mutexattr_init(&attr);
pthread_mutexattr_settype(&attr, PTHREAD_MUTEX_RECURSIVE);
pthread_mutex_init(&lock, &attr);
pthread_mutexattr_destroy(&attr);
pthread_mutex_lock(&lock);
// ...
pthread_mutex_unlock(&lock);NSRecursiveLock
iOS下封装跨平台的高级递归锁
NSRecursiveLock *lock = [NSRecursiveLock new];
[lock lock];
// ...
[lock unlock];@synchronized
iOS下最简单的高级递归锁
NSObject *lock = [NSObject new];
@synchronized(lock) {
// ...
}NSConditionLock
iOS下封装的高级条件锁
NSConditionLock *lock = [[NSConditionLock alloc] initWithCondition:1];
[lock lock];
// ...
[lock unlock];pthread_rwlock_t
跨平台下的一组读写锁
// 声明一个读写锁属性
pthread_rwlockattr_t rwattr;
// 初始化一个读写锁属性
pthread_rwlockattr_init(&rwattr);
// 设置一个读写锁属性
pthread_rwlockattr_setpshared(&rwattr, PTHREAD_PROCESS_PRIVATE);
// 声明一个读写锁
pthread_rwlock_t rwLock;
// 初始化一个读锁
pthread_rwlock_init(&rwLock, &rwattr);
// 请求一个读锁
pthread_rwlock_rdlock(&rwLock);
// 以非阻塞的方式请求一个读锁
pthread_rwlock_tryrdlock(&rwLock);
// 请求一个写锁
pthread_rwlock_wrlock(&rwLock);
// 以非阻塞的方式请求一个写锁
pthread_rwlock_trywrlock(&rwLock);
// 释放一个写锁
pthread_rwlock_unlock(&rwLock);实际应用
在笔者的某个项目中有一个场景,App从后台回到前台的时候会有大量的异步操作,而且不同的业务可能会读取同一个配置,这个时候就是用了锁取防止资源竞争;笔者利用宏定义在公共头文件进行了声明,然后全局应用,而且命名也比较清晰,按照作用类_作用名_锁类型_当前坐标进行命名
/// Public Class .h
/// Userinfo's attrbute pid mutex lock
static pthread_mutex_t kUserInfo_pid_mutex_0 = PTHREAD_MUTEX_INITIALIZER;
/// UserInfo.m
+ (NSString*)pid {
// lock
pthread_mutex_lock(&kUserInfo_pid_mutex_0);
SNUserinfoEx *userInfo = [SNUserinfoEx userinfoEx];
// unlock
pthread_mutex_unlock(&kUserInfo_pid_mutex_0);
return userInfo.pid;
}底层原理
OSSpinLock
在ibireme的文章中我们已经看到了OSSpinLock不再安全,从iOS 10以后被禁用了,主要原因就是低优先级线程拿到锁时,高优先级线程进入忙等(busy-wait)状态,消耗大量CPU时间,从而导致低优先级线程拿不到CPU时间,也就不能完成任务进行释放,这种问题被称为优先级反转
那么问题来了,为什么低优先级拿不到时间片,这得从计算机设计原理开始说起,现代的操作系统在管理普通线程的时候,通常会采用时间片轮询算法(Round Robin,简称RR)。每个线程会被分配一段时间片,通常在0-100ms左右。当线程用完属于自己的时间片以后,就会被操作系统挂起,放入等待队列中,直到被下一次分配时间片。
自旋锁的原理
自旋锁的目的就是为了保证相关任务同一时间只有一个线程访问,伪代码如下
// 全局变量
BOOL lockStatus;
// 一直尝试上锁
while (YES) {
// 获取锁的状态
lockStatus = [self getLockStatus];
// 如果没有上锁,就进行上锁操作,并跳出循环;否则再次获取锁的状态
if (!lockStatus) {
lockStatus = YES;
break;
}
}
// 上锁后执行相关任务
// ...
// 执行完毕,释放锁
lockStatus = NO;细心的同学就会发现,如果有两个线程同时进入if语句,同时获取锁,导致锁不生效
原子操作
在单处理器下(现在肯定是很少了)表示一条不可打断的操作,也就是说线程在执行过程中,不会被系统挂起,而是一定会执行完成
在多处理器下,能够被多个处理器同时执行的操作肯定不算原子操作。因此,真正的原子操作必须由硬件支持,比如x86平台上如果指令前面加上LOCK前缀,对应的机器码在执行时会把总线锁住,这样其他CPU不能再执行相同操作,从而从硬件层面确保了操作的原子性
伪代码优化
// getAndSetLockStatus是一个原子操作,执行成功后把lockStatus设置为YES
while (![self getAndSetLockStatus]) {
continue;
}
// 上锁后执行相关任务
// ...
// 执行完毕,释放锁
lockStatus = NO;自旋锁总结
如果相关任务执行时间过长,使用自旋锁会导致性能低下,这也是文章开头说的加解锁速度和效率是不同的概念,虽然自旋锁加解锁时间复杂度低,但是不适用于执行任务过长的操作,比如文件的读写,如果用了自旋锁的话就会适得其反;
上文也提到了时间片轮询算法,线程在多种情况下退出自己的时间片,其中一种是用完了自己的时间片,被操作系统强制抢占。
当线程进行
I/O操作,或进入睡眠状态时,都会主动让出时间片,显然while循环中,线程处于忙等待状态,白白浪费CPU时间,最终因为超时被操作系统抢占时间片。如果执行任务时间比较长,比如文件读写,这种忙等是没必要的,所以如果相关任务执行过长使用自旋锁不是一个好的选择。
pthread_mutex
pthread表示POSIX(Portable Operating System Interface)thread,中文翻译为可移植的操作系统接口,定义了一组跨平台的线程相关的接口
pthread_mutex代表跨平台的互斥锁。互斥锁的实现原理和信号量相似,也在文章开头进行了简单介绍,不是使用忙等,而是阻塞线程并睡眠,操作系统进行上下文的切换
pthread_mutex_t lock;
pthread_mutexattr_t attr;
pthread_mutexattr_init(&attr);
// 互斥类型属性
/*
* Mutex type attributes
*/
#define PTHREAD_MUTEX_NORMAL 0 // 正常
#define PTHREAD_MUTEX_ERRORCHECK 1 // 错误检查
#define PTHREAD_MUTEX_RECURSIVE 2 // 递归
#define PTHREAD_MUTEX_DEFAULT PTHREAD_MUTEX_NORMAL // 同正常
// 定义互斥类型属性
pthread_mutexattr_settype(&attr, PTHREAD_MUTEX_NORMAL);
// 锁的初始化
pthread_mutex_init(&lock, &attr);
// 锁属性的销毁
pthread_mutexattr_destroy(&attr);
// 请求锁,如果当前mutex已经被锁,那么这个线程就会卡在这,直到mutex释放
pthread_mutex_lock(&lock);
// 执行相关操作
// 解锁
pthread_mutex_unlock(&lock);
// 尝试请求锁,适用于线程已经获得互斥锁;如果当前mutex已经被锁或者不可用,这个函数就直接return了,不会把线程卡住
pthread_mutex_trylock(pthread_mutex_t *mutex);通俗来说一个线程只能申请一次互斥锁,只能在获得互斥锁的情况下才能释放锁,多次申请锁或释放未获得的锁都会导致崩溃。假设在已经获得锁的情况下在此申请锁,线程会因为等待锁的释放而进入睡眠状态,就不可能再释放锁,从而导致死锁。
通过以上注释可以看出,这组跨平台组件同样支持递归,也就是在执行相关操作的范围内允许一个线程递归的申请锁,只要把pthread_mutexattr_settype(&attr, PTHREAD_MUTEX_NORMAL);改成pthread_mutexattr_settype(&attr, PTHREAD_MUTEX_RECURSIVE);即可。
互斥锁的实现
互斥锁在申请锁时,调用了
pthread_mutex_lock方法,它在不同操作系统实现的方式不一样,但是结果是一样的;在iOS系统下是使用lll_futex_wait函数,使线程休眠由于
pthread_mutex有多种类型,可以支持递归等功能,因此在申请加锁时,需要对类型加以判断
NSCondition
NSCondition的OC底层是通过条件变量(condition variable)pthread_cond_t来实现。条件变量类似信号量,提供了线程阻塞和信号机制,因为可以用来阻塞某个线程,并等待某个操作就绪,随后唤醒线程,比如常见的生产者-消费者模式。
需要与互斥锁配合使用
void consumer(void) {
pthread_mutex_t mutex;
pthread_mutex_init(&mutex, NULL);
pthread_cond_t condition_variable_signal;
NSData *data = [NSData new];
pthread_mutex_lock(&mutex);
while (!data) {
pthread_cond_wait(&condition_variable_signal, &mutex);
}
// 发现新的数据
// 处理数据 [self processeData:data];
pthread_mutex_unlock(&mutex);
}
void producer(void) {
pthread_mutex_t mutex;
pthread_mutex_init(&mutex, NULL);
pthread_cond_t condition_variable_signal;
pthread_mutex_lock(&mutex);
// 生产数据,发出信号给消费者,有新的数据
pthread_cond_signal(&condition_variable_signal);
pthread_mutex_unlock(&mutex);
}看以上代码你可能会有疑问,如果不用互斥锁会怎么样,那样的话处理数据那个逻辑就是线程不安全的,也许你在读取data的时候,已经有别的线程进行了修改,因为需要保证消费者拿到的数据是线程安全的
wait方法除了会被signal方法唤醒,有时还会被虚假唤醒,所以这里while循环中的判断来做二次确认
NSCondition的实现
内部其实封装了一个互斥锁和一个条件变量,它把互斥锁的lock方法和条件变量的wait/signal统一放在了NSCondition对象中,暴露给使用者
- (void)signal {
pthread_cond_signal(&_condition);
}
// 这个函数通过宏定义来的,展开后就是这个样子
- (void)lock {
int err = pthread_mutex_lock(&mutex);
}它的加解锁速度与NSLock几乎一致,在实际测试中在10000及以下的量级中是一致的,其余见扩展部分的测试表,个人猜测,该对象在现代系统中进行了优化,时间复杂度略小于NSLock
// 100000
NSCondition: 0.89 ms
NSLock: 0.92 ms
// 1000000
NSCondition: 9.03 ms
NSLock: 9.39 ms
// 10000000
NSCondition: 90.23 ms
NSLock: 94.06 msNSLock
这个就是纯iOS下高级对象的封装了,实现很简单,通过宏定义了lock方法
#define MLOCK \
- (void) lock\
{\
int err = pthread_mutex_lock(&_mutex);\
// 错误处理 ……
}NSLock本质在内部封装了一个pthread_mutex,属性为PTHREAD_MUTEX_ERRORCHECK,会损失一定性能换来错误提示
使用宏定义是为了简化方法对定义,OC内部还有其他几种锁,他们的lock方法都是一样的,仅仅是内部pthread_mutex互斥锁类型不同。
NSLock比pthread_mutex略慢点原因在于它需要经过方法的调用,同时由于缓存的存在,多次方法调用不会对性能产生太大影响。
NSRecursiveLock
这个的内部封装同样也是pthread_mutex_lock函数来实现,pthread_mutex_t的互斥属性类型为PTHREAD_MUTEX_RECURSIVE;在函数内部会判断函数类型,如果传入的是递归锁,就允许递归调用,将内部的一个全局变量计时器进行+1,锁的释放过程也是同样的道理
@synchronized
这个锁是OC层面的锁,牺牲性能换来语法上的简洁与可读,加解锁的时间复杂度倒数第二?
该锁的用法后面是传入一个OC对象,内部其实把这个对象当锁来使用。调用 @sychronized 的每个对象Objective-C runtime 都会为其分配一个递归锁并存储在哈希表中,当然对于哈希冲突内部也是做了优化,具体的原理可以参考这里:http://yulingtianxia.com/blog/2015/11/01/More-than-you-want-to-know-about-synchronized/)
NSConditionLock
NSConditionLock本质是内部封装了NSCondition,本质就是生产者-消费者模式。条件被满足可以理解为消费者接收广播开始消费内容。
NSConditionLock内部持有一个NSCondition对象,以及_condition_value属性;初始化的时候就对这个属性赋值
- (instance)initWithCondition:(NSInteger)conditionValue {
self = [super init];
if(!self) return nil;
_condition = [NSCondition new];
_condition_value = conditionValue;
return self;
}lockWhenCondition的实现
- (void)lockWhenCondition:(NSInteger)conditionValue {
[_condition lock];
while(conditionValue != _condition_value) {
[_condition wait];
}
}对应的unlockWhenCondition方法,使用broadcast方法通知了所有的消费者
- (void)unlockWhenCondition:(NSInteger)conditionValue {
_condition_value = conditionValue;
[_condition broadcast];
[_condition unlock];
}pthread_rwlock_t
上面提到的mutex lock,会有一个问题,那就是只要是被锁住临界区,其余的线程都无法访问。设想这么一个场景,一个写的线程,二个读的线程,当其中一个读的线程锁住临界区的时候,其余的线程都无法访问,理论上读数据不影响数据本身,另外的读线程应该也可以读才合理,这样CPU时间得到合理使用,效率更高,于是便有了这种读写锁
特性:读写锁里,读锁能允许多个线程同时去读,但是写锁在同一时刻只允许一个线程去写。
static pthread_rwlock_t rwLock;
pthread_rwlock_init(&rwLock, NULL);
NSArray *dataArray = @[@"Augus",@"Zhang",@"San",@"Li",@"Si",@"Wang",@"Wu",@"Zhao",@"Liu",@"Gao"];
SNPerson *person = [[SNPerson alloc] init];
person.name = @"Augus";
for (int i = 0; i < 100000; i++) {
// read
dispatch_async(dispatch_get_global_queue(0, 0), ^{
pthread_rwlock_rdlock(&rwLock);
NSLog(@"1 thread read name %d: %@",i,person.name);
pthread_rwlock_unlock(&rwLock);
});
// read
dispatch_async(dispatch_get_global_queue(0, 0), ^{
pthread_rwlock_rdlock(&rwLock);
NSLog(@"2 thread read name %d: %@",i,person.name);
pthread_rwlock_unlock(&rwLock);
});
// write
dispatch_async(dispatch_get_global_queue(0, 0), ^{
pthread_rwlock_wrlock(&rwLock);
NSInteger index = arc4random() % self.dataArray.count;
person.name = dataArray[index];
NSLog(@"3 thread write name %d: %@",i,person.name);
pthread_rwlock_unlock(&rwLock);
});
}注意点
由于读写锁的本质,在默认情况下很容易出现写线程饥饿。因为它必须要等到所有读锁都释放之后,才能成功申请写锁。不同系统的实现对写线程的优先级实现不同,在
iOS下默认是读线程优先,比如在写线程阻塞的时候,有很多读线程是可以一个接一个地在那插队,因为读的优先级高于写,那么写线程就不知道什么时候才能申请成功写锁,就会出现饥饿的情况为了控制写线程的饥饿,必须要在创建读写锁的时候设置
PTHREAD_RWLOCK_PREFER_WRITER_NONRECURSIVE,不去使用PTHREAD_RWLOCK_PREFER_WRITER_NP/** PTHREAD_RWLOCK_PREFER_READER_NP This is the default. A thread may hold multiple read locks; that is, read locks are recursive. According to The Single Unix Specification, the behavior is unspecified when a reader tries to place a lock, and there is no write lock but writers are waiting. Giving preference to the reader, as is set by PTHREAD_RWLOCK_PREFER_READER_NP, implies that the reader will receive the requested lock, even if a writer is waiting. As long as there are readers, the writer will be starved. PTHREAD_RWLOCK_PREFER_WRITER_NP This is intended as the write lock analog of PTHREAD_RWLOCK_PREFER_READER_NP. This is ignored by glibc because the POSIX requirement to support recursive read locks would cause this option to create trivial deadlocks; instead use PTHREAD_RWLOCK_PREFER_WRITER_NONRECURSIVE_NP which ensures the application developer will not take recursive read locks thus avoiding deadlocks. PTHREAD_RWLOCK_PREFER_WRITER_NONRECURSIVE_NP Setting the lock kind to this avoids writer starvation as long as any read locking is not done in a recursive fashion. */ pthread_rwlockattr_t attributes; pthread_rwlockattr_setkind_np (&attributes,PTHREAD_RWLOCK_PREFER_WRITER_NONRECURSIVE _NP);总的来说,这样的锁建立之后一定要设置优先级,不然就容易出现线程饥饿。读写锁适合于多读少写的情况,如果读写一样多,那么选择
mutex lock。
iOS下的读写锁的封装
上面代码也已经举例了,如果出现了线程饥饿使用pthread_rwlock_tryrdlock(&rwLock)和pthread_rwlock_trywrlock(&rwLock)以非阻塞的方式进行加解锁,也就是线程已经拥有读/写锁。其实本质就是内部进行了读写锁优先级的设置
关于PTHREAD_PROCESS_PRIVATE和PTHREAD_PROCESS_SHARED,设置读写锁进行共享属性
PTHREAD_PROCESS_SHARED:如果设置该属性,那么允许该读写锁被任何可以访问分配给该读写锁的内存的线程操作,即使该读写锁被分配到多个进程共享内存中。PTHREAD_PROCESS_PRIVATE:设置该属性,则读写锁只能由与初始化读写锁的线程在同一进程中创建的线程操作;如果不同进程的线程试图对这样的读写锁进行操作,将不会有效果,默认是该属性。
扩展
在10000000量级下加解锁时间测试对比数据,纵轴单位为毫秒
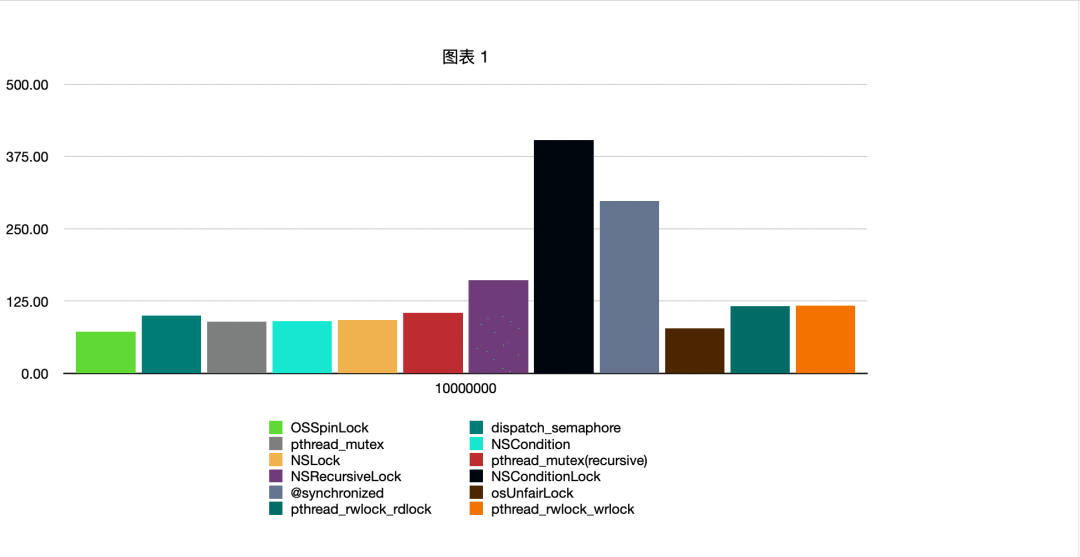
测试demo地址
https://github.com/venn0126/iOS-Study/tree/master/2021/0120/TesLock
参考文档
pthread_mutex_lock https://pubs.opengroup.org/onlinepubs/7908799/xsh/pthread_mutex_lock.html)
ThreadSafety https://developer.apple.com/library/archive/documentation/Cocoa/Conceptual/Multithreading/ThreadSafety/ThreadSafety.html
pthread_mutex_lock.c https://github.com/lattera/glibc/blob/master/nptl/pthread_mutex_lock.c
pthread的各种同步机制 https://casatwy.com/pthreadde-ge-chong-tong-bu-ji-zhi.html
pthread_cond_wait.c https://android.googlesource.com/platform/external/pthreads/+/master/pthread_cond_wait.c
conditional-variable-vs-semaphore https://stackoverflow.com/questions/3513045/conditional-variable-vs-semaphore)
pthread_rwlockattr_setkind_np
https://man7.org/linux/man-pages/man3/pthread_rwlockattr_setkind_np.3.html


也许你还想看
(▼点击文章标题或封面查看)




