kotlin 协程一
使用Koltin有一段时间了,自然对于Kotlin大名鼎鼎的协程也是闻名已久,但是在使用的过程中一直是一知半解,对于很多的概念每一个 名词我都能看的懂,但是我就是不知道你到底在说些什么。迫不得已只好自己去阅读源码,在读源码 的过程中去理解与学习。由于协程的源码读起来比较费劲.特别是对于初学者更加晦涩。我尽量以比较通俗的方式去想大家介绍Kotlin的协程原理,逐步的带领大家领略协程的源码。
本文不会对于协程的基本使用做过多介绍,所以在阅读本文之前,希望各位对于协程的基本使用做个了解。
最后由于Koltin的协程大量使用了编译技术,源码读起来相当艰难,假如遇见了实在看不懂的地方,建议各位反编译成JAVA 代码之后再行阅读,想来会有一定的帮助。
一、协程是什么以及协程与线程的区别
协程的开发人员 Roman Elizarov 是这样描述协程的:协程就像非常轻量级的线程。线程是由系统调度的,线程切换或线程阻塞的开销都比较大。而协程依赖于线程,但是协程挂起时不需要阻塞线程,几乎是无代价的,协程是由开发者控制的。所以协程也像用户态的线程,非常轻量级,一个线程中可以创建任意个协程。
协程的官方描述是:协程通过将复杂性放入库来简化异步编程。程序的逻辑可以在协程中顺序地表达,而底层库会为我们解决其异步性。
这两句话很好了描述的什么是协程以及协程的作用。下面我们来具体的解释一下这段讲话的含义
1.1
线程是由系统调度的,线程切换或线程阻塞的开销都比较大。这句话我想不需要我多解释大家都应该明白,线程的切换设计到cpu上下文的切换,所以消耗比较大,而且线程的调度完全是cpu的管理,用户无法感觉到这个过程,同时也无法控制这个过程。
1.2
协程依赖于线程,但是协程挂起时不需要阻塞线程,几乎是无代价的,协程是由开发者控制的。所以协程也像用户态的线程,非常轻量级,一个线程中可以创建任意个协程。
协程依赖线程这也比较好理解,因为最终协程里面的代码必然还是要运行在某一个线程里面。但是协程什么时候运行,什么挂起,挂起之后什么时候恢复这个是可以由用户控制的,而且Kotlin 也确实给我们暴露了对应的API。
关于协程的调度即协程的挂起与恢复会在后面结合源码详细解释。
fun testScope() {
GlobalScope.launch (Dispatchers.Default){
println("before --线程id is ${Thread.currentThread().id}")
//切换线程,这句话起到的作用就是挂起当前协程,开启一个新的协程
withContext(Dispatchers.Default) {
delay(1000)
println("withContext --线程id is ${Thread.currentThread().id}")
//当执行到这里的时候会恢复GlobalScope.launch 创建的协程,然后执行下面的
//打印
}
println("after --线程id is ${Thread.currentThread().id}")
}
}输出的结果如下,整个程序是顺序执行的。
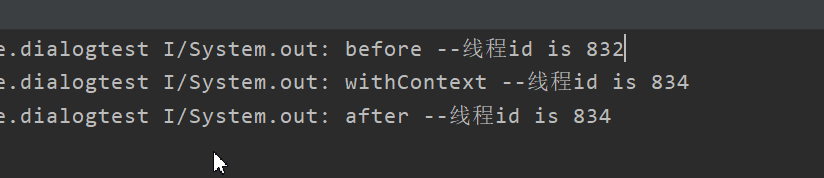
首先 Global.launch 用来创建一个新的协程,这个协程会被抛到一个线程池里面运行。在Global.launch 内部调用了withContext 方法, withConntext 的作用就是挂起当前协程,并创建一个新的协程,这个新的协程也会抛到一个线程池内运行,当withContext内部
的代码执行完成之后再恢复 Global.launch 创建的协程,继续接着执行,这里就是执行最后一句输出语句。实际上withContext 对于协程的挂起与恢复 依然比较抽象,因为对于协程的挂起与恢复封装在了withContext内部,下面我们在举一个例子
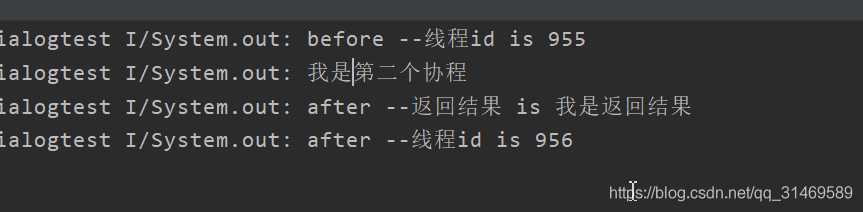
fun testScop3() {
GlobalScope.launch (Dispatchers.Default){
println("before --线程id is ${Thread.currentThread().id}")
//阻塞当前协程,就是后面的输出3与输出4的代码暂时停止执行
//等待有另一个协程恢复当前协程的时候在输出
var outcome=suspendCoroutine<String> {
//创建一个新的协程,运行在一个新的线程里面
launch {
println("我是第二个协程")
//恢复GlobalScope.launch 所创建的协程
it.resumeWith(Result.success("我是返回结果"))
}
}
println("after --返回结果 is $outcome")//输出3
println("after --线程id is ${Thread.currentThread().id}")//输出4
}
}
无论是suspendCoroutine还是withContext最终都是调用的suspendCoroutineUninterceptedOrReturn 方法来挂起当前协程,Koltin 内部提供的yield ,delay,withContext,withTimeout 等等最终都是通过suspendCoroutineUninterceptedOrReturn 来达到挂起当前协程。
suspendCoroutineUninterceptedOrReturn 是怎么实现的这里大家先不要追究,我们放到后面讲。挂起一个协程之后,一般我们会在另一个协程里调用it.resumeWith恢复被挂起的协程,it可以看成是之前被挂起的协程。注意:挂起协程与恢复被挂起的协程的一般是运行在两个不一样的线程里面,如果你非得想知道有没有可能是在同一个线程里面,我可以告诉你是有可能的,
第一种情形
比如我们不开启一个新的协程而是直接在当前协程调用恢复协程的方法,var outcome= suspendCoroutine<String> { it.resumeWith(Result.success("我是返回结果")) }。也就是当前协程恢复当前协程,实际上这样写的话当前协程因为根本就没有被挂起,你调用resumeWith 实际也就无所谓恢复协程。具体原理我们在以后的文章里面讲解。
第二种情形
每一个协程都是放到线程池里面运行的,就这一点而言,协程可以看成是一个线程池里面的任务。所以可能一个线程在执行一个协程的时候这个协程挂起了,然后这个线程会接着去任务池里面获取另一个协程接着执行,而后面这个协程恢复了前面那个挂起的协程。
上面解释了一下协程与线程之间的区别,但是我们仍然没有说明协程的挂起究竟是个什么东西。实际挂起就是当前协程暂停执行,那么暂停执行又是什么意思。我们接着解释,挂起就是协程当前所在的线程执行完了,cpu开始调度另一个线程,在这个新的线程里面有一个新的协程,当这个新的协程恢复前面那个挂起的协程,被挂起的协程就又开始执行了。读到这里你有没有什么想法?你有没有发现,一个协程里面的代码可能会执行在多个线程,你若是不信,你可以看看上面的打印log,第一句打印与第三句打印居然不在一个线程里面,第二句打印居然跟第三局打印是在一个线程里面。有没有豁然开朗的感觉。这也是协程比较有意思的一点。
解释到这我们总结一下
1> 俩个协程可能会运行在一个线程里面
2> 两个协程可能运行在两个线程里面
3>一个协程可能运行在多个线程里面
第一种与第二种比较好理解,实际就是线程池的任务调度导致,那么第三种的原因可能大家还是不太明白,实际上每一个协程都类似一个回调方法,这个回调内部有一个状态机,这个回调可能会在多个线程被多次调用,每一次调用就相当于执行了一次挂起与恢复。这里比较重要的是状态机,这个是协程比较核心的东西,这个状态机是在编译期间编译器根据我们的代码自动生成的。
下面我们祭出大招,模拟一个协程的实现,实际这个模拟就是根据反编译的代码简化的,虽然很粗糙,但是可以帮助大家更好的理解协程的原理。
协程的写法:
fun testScope() {
GlobalScope.launch (Dispatchers.Default){
println("before --线程id is ${Thread.currentThread().id}")
//阻塞当前协程
var outcome= suspendCoroutine<String> {
//开启新的协程
launch {
println("我是第二个协程")
//恢复GlobalScope.launch 所创建的协程
it.resume("我是返回结果")
}
}
println("after --返回结果 is $outcome")
println("after --线程id is ${Thread.currentThread().id}")
}
}
模拟:
var lable = 0
var result:Any?=null
fun mockScope() {
//将thread 看成是
thread {
task.run()
}
}
//可以看成是一个GlobalScope.launch创建的协程,
//内部是一个状态机
var task = java.lang.Runnable {
if (lable == 0) {
lable++
println("before --线程id is ${Thread.currentThread().id}")
suspendCoroutine()
} else if (lable == 1) {
lable++
println("after --返回结果 is $result")
println("after --线程id is ${Thread.currentThread().id}")
}
}
//看成是第二个协程,实际上这里面也应该是一个状态机
//但是我们这里省略了,看上面那个状态机就可以了
fun suspendCoroutine() {
thread {
println("withContext --线程id is ${Thread.currentThread().id}")
//保存运算结果
result="我是返回结果"
//回调,相当于恢复协程
//可以看到恢复的协程运行在一个新的线程里面
task.run()
}
}

label 就是用来记录状态机的状态,当label 等于0的时候运行在一个线程里面,当label 为1的时候也就是协程被挂起再恢复的时候运行在了另一个线程。
可以看到task可能会被执行很多次,但是由于每次状态机的label的不同,每次执行的分支都不一样。 实际上Kotlin的协程代码在被编译之后跟我们当前这个例子结构是类似的,大家结合这个例子理解协程以及我们上面的解释应该好理解一些。
至此我们也可以解释为什么协程的挂起与恢复几乎是无代价的。
二、协程的作用
我们上面简单的解释了一下协程的原理以及协程与线程的区别。但是协程的作用是什么或者说协程的好处体现在哪里。
协程的官方描述是:协程通过将复杂性放入库来简化异步编程。程序的逻辑可以在协程中顺序地表达,而底层库会为我们解决其异步性。
在没有协程之前,我们访问网络获取的数据的时候不得不借助回调
fun testScope3() {
println("获取网络数据之前")
//通过回调获取数据
fetchDataFromNet3(object : CallBack {
override fun success(outcome: String?) {
println("获取网络数据成功")
}
override fun error(throwable: Throwable?) {
println("获取网络数据失败")
}
})
println("获取网络数据之前")
}
fun fetchDataFromNet3(callback: CallBack) {
val url = "http://wwww.baidu.com"
val okHttpClient = OkHttpClient()
val request: Request = Request.Builder()
.url(url)
.build()
val call: Call = okHttpClient.newCall(request)
call.enqueue(object : Callback {
override fun onFailure(call: Call?, e: IOException?) {
callback.error(e!!)
}
@Throws(IOException::class)
override fun onResponse(call: Call?, response: Response) {
var outcome= response.body()?.string()
callback.success(outcome)
}
})
}假如有了协程之后,此时就不需要回调这种复杂方式了,按照同步代码的方式书写就可以达到异步的效果
fun testScope() {
GlobalScope.launch(Dispatchers.Default) {
println("before --线程id is ${Thread.currentThread().id}")
//直接返回结果,不必回调
var outcome = fetchDataFromNet()
println("after --返回结果 is $outcome")
}
}
suspend fun fetchDataFromNet(): String {
var outcome= withContext<String>(Dispatchers.IO){
val url = "http://wwww.baidu.com"
val okHttpClient = OkHttpClient()
val request: Request = Request.Builder()
.url(url)
.build()
val call: Call = okHttpClient.newCall(request)
var response=call.execute()
response.body()?.string()?:"error"
}
return outcome
}
如上,代码写的比较简化,有的地方不规范,理解这种意思即可。
这种异步代码的同步话的原理大家依然可以结合上面那个模拟协程来理解。