
举例分析
创建列表对象 numbers

列表对象有两种底层实现结构
1.压缩列表(zipList)实现的列表对象

压缩列表(zipList)是Redis为了节省内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型数据结构,一个压缩列表可以包含任意多个节点(entry),每个节点可以保存一个字节数组或者一个整数值,如图

 压缩列表的每个节点Entry构成如下
压缩列表的每个节点Entry构成如下

previous_entry_ength:以字节为单位,记录了压缩列表中前一个字节的长度。利用此原理即当前节点位置减去上一个节点的长度即得到上一个节点的起始位置,压缩列表可以从尾部向头部遍历,这么做很有效地减少了内存的浪费。
encoding:记录了节点的 content 属性所保存数据的类型以及长度。
content:保存节点的值,节点的值可以是一个字节数组或者整数,值的类型和长度由节点的 encoding 属性决定。
ZipList优缺点
压缩列表ziplist结构本身就是一个连续的内存块,由表头、若干个entry节点和压缩列表尾部标识符zlend组成,通过一系列编码规则,提高内存的利用率,使用于存储整数和短字符串。
压缩列表ziplist结构的缺点是:每次插入或删除一个元素时,都需要进行频繁的调用realloc()函数进行内存的扩展或减小,然后进行数据”搬移”,甚至可能引发连锁更新,造成严重效率的损失。
2. 双端链表(LinkedList)实现的列表对象
链表是一种常用的数据结构,C 语言内部是没有内置这种数据结构的实现,所以Redis自己构建了链表的实现。链表节点定义:

多个 listNode 可以通过 prev 和 next 指针组成双端链表,结构如下

另外提供了操作链表的list结构

list结构为链表提供了表头指针 head ,表尾指针 tail 以及链表长度计数器 len ,dup、free、match 成员则是用于实现多态链表所需的类型特定函数。
Redis链表实现的特性:
双端:链表节点带有 prev 和 next 指针,获取某个节点的前置节点和后置节点复杂度都是O(1)。
无环:表头节点的 prev 指针和表尾节点的 next 指针都指向 NULL,对链表的访问以NULL为终点。
带表头指针和表尾指针:通过list结构的 head 和 tail 指针,程序获取链表的表头节点和表尾结点的复杂度都是O(1)。
带链表长度计数器:程序使用 list 结构的 len属性对 list持有的链表节点进行计数,程序获取链表中节点数量的复杂度为O(1)。
多态:链表节点使用 void* 指针来保存节点值,并且通过 list 结构的 dup、 free、match 三个属性为节点值设置类型特定函数,所以链表可以用于保存各种不同类型的值。
ziplist 与 linkedlist 之间存在着一种编码转换机制,当列表对象可以同时满足下列两个条件时,列表对象采用ziplist编码,否则采用linkedlist编码:
(1)列表对象保存的所有字符串元素的长度都小于64字节;
(2)列表元素保存的元素数量小于512个;
以上两个条件的上限值可以在配置文件中修改 list-max-ziplist-value 选项和 list-max-ziplist-entries 选项 。
另外对于使用 ziplist 编码的列表对象,当以上两个条件中任何一个不能满足时,对象的编码转换操作就会执行,原本保存在压缩列表里面的所有列表元素都会被转移并保存到双端链表里面,对象的编码也从 ziplist 变为 linkedlist 。
 但是如果我们实际操作下的话,是这样懵逼的情况:
但是如果我们实际操作下的话,是这样懵逼的情况:
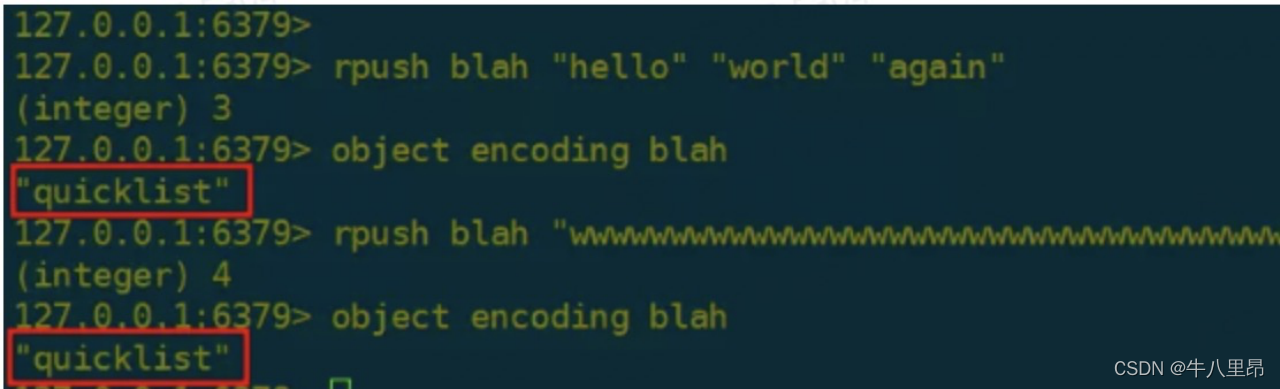

原来是redis 在 3.2 版本的时候,考虑到redis的空间存储效率和时间效率,引入了quicklist(快速列表)作为 list 的底层实现
quicklist
quicklist是由ziplist组成的双向链表,链表中的每一个节点都以压缩列表ziplist的结构保存着数据,而ziplist有多个entry节点,保存着数据。相当于一个quicklist节点保存的是一片数据,而不再是一个数据。
例如:一个quicklist有4个quicklist节点,每个节点都保存着1个ziplist结构,每个ziplist的大小不超过8kb,ziplist的entry节点中的value成员保存着数据。
根据以上描述,总结出一下quicklist的特点:
quicklist宏观上是一个双向链表,因此,它具有一个双向链表的优点,进行插入或删除操作时非常方便,虽然复杂度为O(n),但是不需要内存的复制,提高了效率,而且访问两端元素复杂度为O(1)。
quicklist微观上是一片片entry节点,每一片entry节点内存连续且顺序存储,可以通过二分查找以 log2(n)log2(n) 的复杂度进行定位。
总体来说,quicklist给人的感觉和B树每个节点的存储方式相似。

在quicklist表头结构中,有两个成员是fill和compress,其中” : “是位域运算符,表示fill占int类型32位中的16位,compress也占16位。
fill和compress的配置文件是redis.conf。
fill成员对应的配置:list-max-ziplist-size -2
当数字为负数,表示以下含义:
-1 每个quicklistNode节点的ziplist字节大小不能超过4kb。(建议)
-2 每个quicklistNode节点的ziplist字节大小不能超过8kb。(默认配置)
-3 每个quicklistNode节点的ziplist字节大小不能超过16kb。(一般不建议)
-4 每个quicklistNode节点的ziplist字节大小不能超过32kb。(不建议)
-5 每个quicklistNode节点的ziplist字节大小不能超过64kb。(正常工作量不建议)
当数字为正数,表示:ziplist结构所最多包含的entry个数。最大值为 215215。
compress成员对应的配置:list-compress-depth 0
后面的数字有以下含义:
0 表示不压缩。(默认)
1 表示quicklist列表的两端各有1个节点不压缩,中间的节点压缩。
2 表示quicklist列表的两端各有2个节点不压缩,中间的节点压缩。
3 表示quicklist列表的两端各有3个节点不压缩,中间的节点压缩。
以此类推,最大为 216216。

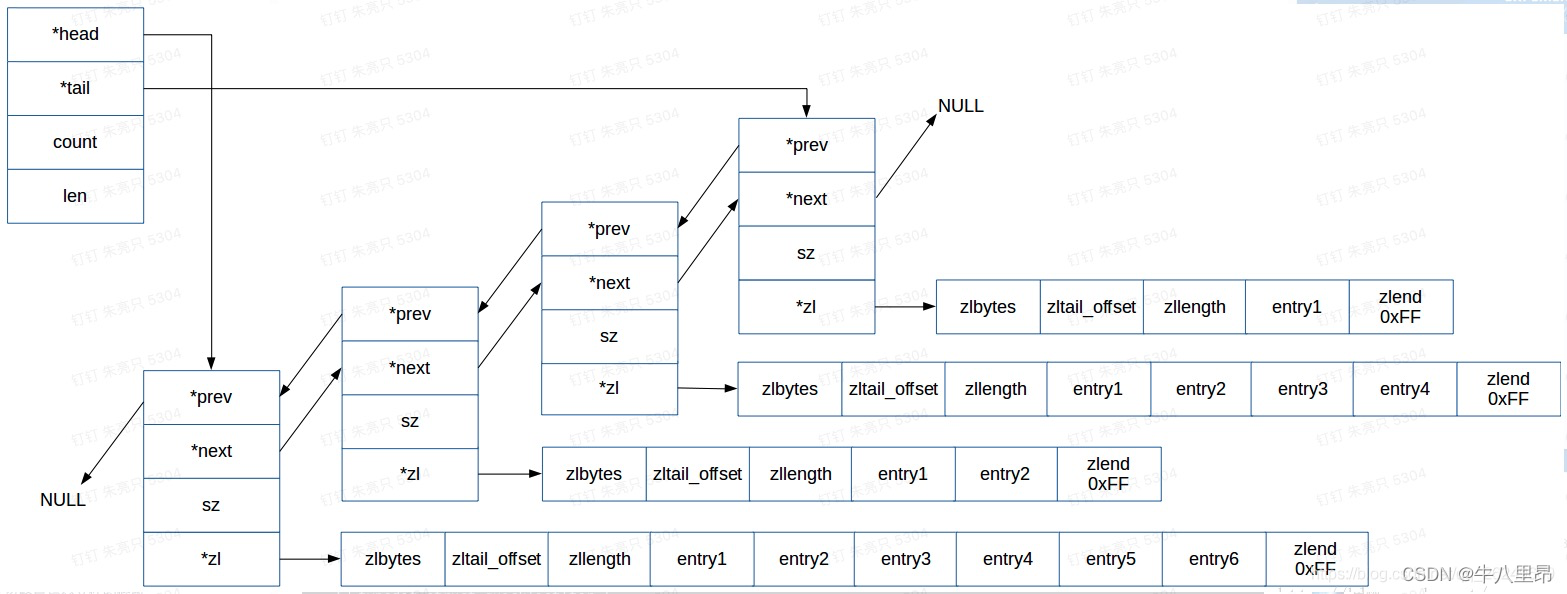
quicklist 结构图
根据上述结构体定义,咱们可以绘制一下 quicklist 的结构
总结
A、双端链表
1.双端链表便于在表的两端进行 push 和 pop 操作,但是它的内存开销比较大;
2.双端链表每个节点上除了要保存数据之外,还要额外保存两个指针;
3.双端链表的各个节点是单独的内存块,地址不连续,节点多了容易产生内存碎片;
B、压缩列表
1.ziplist 由于是一整块连续内存,所以存储效率很高;
2.ziplist 不利于修改操作,每次数据变动都会引发一次内存的 realloc;
3.当 ziplist 长度很长的时候,一次 realloc 可能会导致大批量的数据拷贝,进一步降低性能;
C、quickList
1.空间效率和时间效率的折中;
2.结合了双端链表和压缩列表的优点;
应用场景
接收关注的商品变动发消息
Lpush user1 sku01 sku02
lpush sku01msgId
Lpush sku01 msgid2
查询消息
Lrange user1 0 2
Lrange sku01 0 10
Lrange sku02 0 10