前言
本文主要对以下几种Normalization方法进行讨论:
- Batch Normalization(BN)
- Instance Normalization(IN)
- Layer Normalization(LN)
- Group Normalization(GN)
- Conditional Batch Normalization(CBN)
- Conditional Instance Normalization(CIN)
- Adaptive Instance Normalization(AdaIN)
- SPatially-Adaptive (DE) normalization(SPADE)
以下Normalization方法本文不做讨论,请自行搜索相应资料。
- Local Response Normalization (LRN)
- Weight Normalization (WN)
- ······
Normalization方法
一、什么是Normalization?
Normalization一般被译为“规范化”或是“归一化”,是一种对数值的特殊函数变换方法。假设原始某个数值是x xx,采用定义对规范化函数对数值x xx进行转换,形成一个规范化后的数值y yy。准确来说它是一个统计学概念,并不是一个完全定义好的数学操作,可以根据需要自己定义规范化方式。它通过将数据进行偏移和尺度缩放调整,在数据预处理时是非常常见的操作。
二、为什么需要Normalization?
这得从“白化(whitening)”说起,白化的目的是希望特征符合独立同分布i.i.d条件。包括:去除特征之间的相关性(独立),使得所有特征具有相同的均值和方差(同分布)。独立同分布的数据可以简化常规机器学习模型的训练、提升机器学习模型的预测能力。因此,在把数据输进机器学习模型之前,“白化”是一个重要的数据预处理步骤。
在深度学习中,因为网络的层数非常多,如果数据分布在某一层开始有明显的偏移,随着网络的加深这一问题会加剧(这一问题在BN的文章中被称之为internal covariate shift,ICS),进而导致模型优化的难度增加,甚至不能优化。所以,考虑通过使数据独立同分布来减缓这个问题。
要解决独立同分布的问题,“理论正确”的方法就是对每一层的数据都进行白化操作。然而标准的白化操作代价高昂,特别是我们还希望白化操作是可微的,保证白化操作可以通过反向传播来更新梯度。
因此,以 BN 为代表的 Normalization 方法退而求其次,进行了简化的白化操作。基本思想是:在将 x xx 送给神经元之前,先对其做平移和伸缩变换, 将 x xx 的分布规范化成在固定区间范围的标准分布。
三、Normalization有什么好处?
1、使得数据更加符合独立同分布条件,减少ICS导致的偏移。
2、使数据远离Sigmoid激活函数的饱和区,加快速度。
3、使网络不再依赖精细的参数初始化过程,可以调大学习率。
四、Normalization的一般形式
前面说到,Normalization是一个统计学概念,并不是一个完全定义好的数学操作,可以根据需要自己定义规范化方式。它通过将数据进行偏移和尺度缩放调整,通用的变换框架如下所示:
h = f ( g x − μ σ + b ) h=f(g\frac{x-\mu}{\sigma}+b)h=f(gσx−μ+b)
其中,
μ \muμ: 均值
σ \sigmaσ: 标准差
b bb: 再平移参数,新数据以b bb为均值
g gg: 再缩放参数,新数据以g 2 g^2g2为方差
通过μ \muμ和σ \sigmaσ这两个参数进行 shift 和 scale 变换得到的数据符合均值为 0、方差为 1 的标准分布:
x ^ = x − μ σ \hat x = \frac{x-\mu}{\sigma}x^=σx−μ
再通过b bb和g gg这两个参数将上一步得到的 x ^ \hat{x}x^ 进一步变换为:
y = g x ^ + b y = g{\hat x}+by=gx^+b
最终得到的数据符合均值为 b bb 、方差为 g 2 g^2g2 的分布。
这里需要指出的是,第一步已经得到的标准分布,第二步再进行变化,是为了保证模型的表达能力不因为规范化而下降。
第一步的变换将输入数据限制到了一个统一的确定范围(均值为 0、方差为 1)。底层神经元可能很努力地在学习,但其输出的结果在交给其上层神经元进行处理之前,都将被重新调整到这一确定范围,损失了底层神经元学习的部分效果。将规范化后的数据进行再平移和再缩放,使得每个神经元对应的输入范围是针对该神经元量身定制的一个确定范围(均值为b bb 、方差为g 2 g^2g2)。rescale 和 reshift 的参数都是可学习的,这就使得 Normalization 层可以充分利用底层学习的能力。
另一方面的重要意义在于保证获得非线性的表达能力。Sigmoid 等激活函数在神经网络中有着重要作用,通过区分饱和区和非饱和区,使得神经网络的数据变换具有了非线性计算能力。而第一步的规范化会将几乎所有数据映射到激活函数的非饱和区(线性区),仅利用到了线性变化能力,从而降低了神经网络的表达能力。而进行再变换,则可以将数据从线性区变换到非线性区,恢复模型的表达能力。
五、本文讨论的Normalization方法
(1)Batch Normalization(BN)
在Ioffe和Szegedy的论文《Batch normalization: Accelerating deep network training by reducing internal covariate shift》中提到BN层可以有效改善前馈网络的训练过程。
给定一个输入批次x ∈ R N × C × H × W x\in \R^{N×C×H×W}x∈RN×C×H×W,BN指在每一个单独的特征通道上做归一化:
B N ( x ) = γ ( x − μ ( x ) σ ( x ) ) + β (1) {\rm {BN}}(x)=\gamma(\frac{x-\mu(x)}{\sigma(x)})+\beta \tag{1}BN(x)=γ(σ(x)x−μ(x))+β(1)
其中,γ , β ∈ R C \gamma,\beta \in \R^Cγ,β∈RC是从数据中学习得到的仿射参数;μ ( x ) , σ ( x ) ∈ R C \mu(x), \sigma(x) \in \R^Cμ(x),σ(x)∈RC是在每一个独立的特征通道(C CC)上,跨越batch_size(N NN)和空间(H , W H,WH,W)计算得到的均值和标准差。
μ c ( x ) = 1 N H W ∑ n = 1 N ∑ h = 1 H ∑ w = 1 W x n c h w \mu_c(x)=\frac{1}{NHW}\sum_{n=1}^N\sum_{h=1}^H\sum_{w=1}^Wx_{nchw}μc(x)=NHW1n=1∑Nh=1∑Hw=1∑Wxnchw
σ c ( x ) = 1 N H W ∑ n = 1 N ∑ h = 1 H ∑ w = 1 W ( x n c h w − μ c ( x ) ) 2 + ϵ \sigma_c(x)=\sqrt{\frac{1}{NHW}\sum_{n=1}^N\sum_{h=1}^H\sum_{w=1}^W{(x_{nchw}-\mu_c(x))^2+\epsilon}}σc(x)=NHW1n=1∑Nh=1∑Hw=1∑W(xnchw−μc(x))2+ϵ
(2)Instance Normalization(IN)
Ulyanov等人在其论文《 Improved texture networks: Maximizing quality and diversity in feed-forward stylization and texture synthesis》中指出可以通过使用IN来替换BN提升效果。
I N ( x ) = γ ( x − μ ( x ) σ ( x ) ) + β (2) {\rm {IN}}(x)=\gamma(\frac{x-\mu(x)}{\sigma(x)})+\beta \tag{2}IN(x)=γ(σ(x)x−μ(x))+β(2)
与BN不同的是,这里的μ ( x ) \mu(x)μ(x)和σ ( x ) \sigma(x)σ(x)不再是仅对每一个独立的特征通道(C CC)计算了,而是变成对每一个样本(N NN)的每一个特征通道(C CC)上计算了。也就是说不再对同批次样本进行汇总计算了。
μ n c ( x ) = 1 H W ∑ h = 1 H ∑ w = 1 W x n c h w \mu_{nc}(x)=\frac{1}{HW}\sum_{h=1}^H\sum_{w=1}^Wx_{nchw}μnc(x)=HW1h=1∑Hw=1∑Wxnchw
σ n c ( x ) = 1 H W ∑ h = 1 H ∑ w = 1 W ( x n c h w − μ n c ( x ) ) 2 + ϵ \sigma_{nc}(x)=\sqrt{\frac{1}{HW}\sum_{h=1}^H\sum_{w=1}^W{(x_{nchw}-\mu_{nc}(x))^2+\epsilon}}σnc(x)=HW1h=1∑Hw=1∑W(xnchw−μnc(x))2+ϵ
另外一点IN与BN不同的地方是,对BN而言,测试(inference)的时候是单实例,不存在minibatch,所以就无法获得BN计算所需的均值和方差,一般的解决方法是采用训练(training)时记录的各个minibatch的统计量来推算全局的均值和方差,测试时采用推导出的统计量进行计算。整个过程存在训练和测试阶段统计量计算方式不一致的问题。而IN则不存在这个问题,其在训练和测试阶段保持同样的统计量计算方式。
(3)Layer Normalization(LN)
相比BN是对每一个特征通道(C CC)上,跨越batch_size(N NN)和空间(H , W H,WH,W)计算得到的均值和标准差,LN则是对batch_size(N NN)每一个样本,直接用同层所有输出的响应值来求均值和方差。对多层感知器MLP而言就是同层隐层神经元的响应值,对卷积神经网络CNN而言就是同层卷积层的所有输出(多个通道)。
L N ( x ) = γ ( x − μ ( x ) σ ( x ) ) + β (3) {\rm {LN}}(x)=\gamma(\frac{x-\mu(x)}{\sigma(x)})+\beta \tag{3}LN(x)=γ(σ(x)x−μ(x))+β(3)
其中,γ , β ∈ R C \gamma,\beta \in \R^Cγ,β∈RC是从数据中学习得到的仿射参数;μ ( x ) , σ ( x ) ∈ R C \mu(x), \sigma(x) \in \R^Cμ(x),σ(x)∈RC是在mini batch(N NN)的每一个样本上,跨越特征通道(C CC)和空间(H , W H,WH,W)计算得到的均值和标准差。
μ n ( x ) = 1 C H W ∑ c = 1 C ∑ h = 1 H ∑ w = 1 W x n c h w \mu_n(x)=\frac{1}{CHW}\sum_{c=1}^C\sum_{h=1}^H\sum_{w=1}^Wx_{nchw}μn(x)=CHW1c=1∑Ch=1∑Hw=1∑Wxnchw
σ n ( x ) = 1 C H W ∑ c = 1 C ∑ h = 1 H ∑ w = 1 W ( x n c h w − μ c ( x ) ) 2 + ϵ \sigma_n(x)=\sqrt{\frac{1}{CHW}\sum_{c=1}^C\sum_{h=1}^H\sum_{w=1}^W{(x_{nchw}-\mu_c(x))^2+\epsilon}}σn(x)=CHW1c=1∑Ch=1∑Hw=1∑W(xnchw−μc(x))2+ϵ
BN对batch_size的大小很敏感,如果batch_size太小,则计算的均值和方差会不足以代表整个数据的分布情况,合理的设定batch_size很重要。BN实际使用时需要计算并保存某一层神经网络batch的均值和方差等统计量,这对于固定深度的前向神经网络(DNN/CNN)而言比较方便有效,但对于样本长度不完全一致的RNN而言效果就没那么有效了。
而LN不依赖于batch_size大小和输入序列的深度,因此可以用于batch_size为1和RNN中对边长的输入序列的Normalize操作。事实上LN在RNN上应用的效果比较明显,但在CNN上一般不如BN。
(4)Group Normalization(GN)
LN是将同层所有神经元输出作为统计范围,而IN则是CNN中将同一卷积层中每个卷积核对应的输出通道单独作为自己的统计范围。那么有没有介于两者之间的统计范围呢?
通道分组是 CNN 常用的模型优化技巧,所以自然而然会想到对 CNN 中某一层卷积层的输出或者输入通道进行分组,在分组范围内进行统计。这就是GN的核心思想,它是何凯明研究组于2017年提出的。
G N ( x ) = γ ( x − μ ( x ) σ ( x ) ) + β (4) {\rm {GN}}(x)=\gamma(\frac{x-\mu(x)}{\sigma(x)})+\beta \tag{4}GN(x)=γ(σ(x)x−μ(x))+β(4)
其中,γ , β ∈ R C \gamma,\beta \in \R^Cγ,β∈RC是从数据中学习得到的仿射参数;μ ( x ) , σ ( x ) ∈ R C \mu(x), \sigma(x) \in \R^Cμ(x),σ(x)∈RC是在
mini batch(N NN)的每一个样本上,跨越特征通道(C CC)和空间(H , W H,WH,W)计算得到的均值和标准差。
μ i ( x ) = 1 m ∑ k ∈ S i x k \mu_i(x)=\frac{1}{m}\sum_{k\in S_i}x_{k}μi(x)=m1k∈Si∑xk
σ i ( x ) = 1 m ∑ k ∈ S i ( x k − μ i ( x ) ) 2 + ϵ \sigma_i(x)=\sqrt{\frac{1}{m}\sum_{k\in S_i}{(x_{k}-\mu_i(x))^2+\epsilon}}σi(x)=m1k∈Si∑(xk−μi(x))2+ϵ
最重要的是S i S_iSi的划分,
在BN中,
S i = { k ∣ k C = i C } S_i = \{k\mid k_C = i_C\}Si={k∣kC=iC}
在LN中,
S i = { k ∣ k N = i N } S_i = \{k\mid k_N = i_N\}Si={k∣kN=iN}
在IN中,
S i = { k ∣ k N = i N , k C = i C } S_i = \{k\mid k_N = i_N, k_C = i_C\}Si={k∣kN=iN,kC=iC}
而在GN中,需要做分组操作,
S i = { k ∣ k N = i N , ⌊ k C C / G ⌋ = ⌊ i C C / G ⌋ } S_i = \{k\mid k_N = i_N, \lfloor \frac{k_C}{C/G}\rfloor = \lfloor \frac{i_C}{C/G}\rfloor\}Si={k∣kN=iN,⌊C/GkC⌋=⌊C/GiC⌋}
其中,G GG是分组数,是预定义好的超参数(原论文默认值为32),C / G C/GC/G是每个组分得的通道数。
下面这张图很形象地说明了BN/LN/IN/GN的差异:
(5)Conditional Batch Normalization(CBN)
传统的BN中γ γγ和β ββ是通过损失函数反向传播学习得到参数值(这个值独立于每次输入的feature),而CBN中γ γγ和β ββ是输入的feature经过一个几层的小神经网络(原论文中是MLP)前向传播得到的网络输出。由于CBN的γ γγ和β ββ依赖于输入的feature这个Condition,因此这个改进版的BN叫做CBN。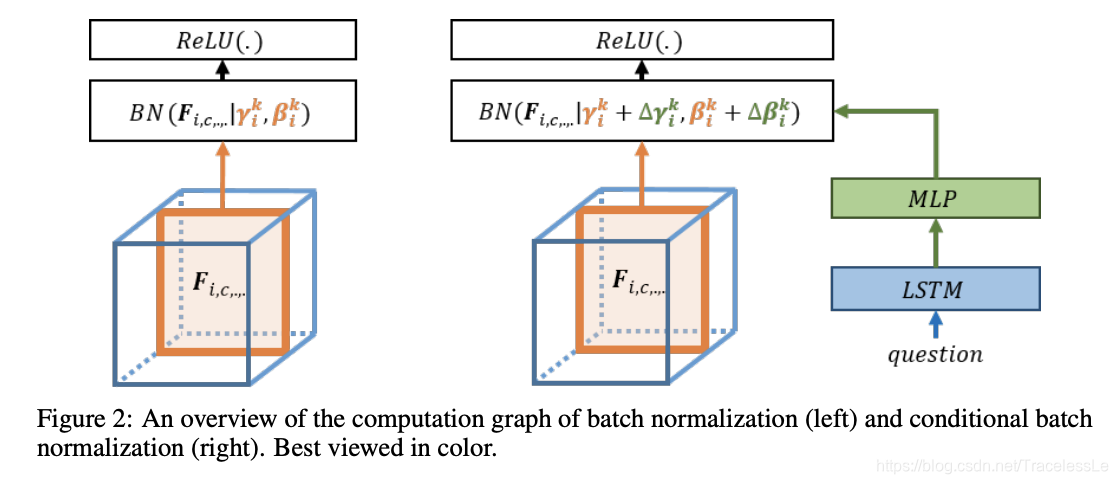
CBN这一思想在论文《Modulating early visual processing by language》中是为了解决“在预训练ResNet提取的图片底层信息中,融合进自然语言信息,用于辅助图片信息的提取”这一具体问题而提出的。而后面的《cGANs With Projection Discriminator》和《Self-Attention Generative Adversarial Networks》则是利用Condition的思想,把图片的 类别信息用来指导生成BN层的仿射参数。
(6)Conditional Instance Normalization(CIN)
CIN相比IN最大的变化就是IN是通过数据学习得到一个单一的仿射参数集合γ \gammaγ和β \betaβ,而CIN是对于引入的不同的style学习得到不同的仿射参数集合γ s \gamma^sγs和β s \beta^sβs。
C I N ( x ; s ) = γ s ( x − μ ( x ) σ ( x ) ) + β s (5) {\rm {CIN}}(x;s)=\gamma^s(\frac{x-\mu(x)}{\sigma(x)})+\beta^s \tag{5}CIN(x;s)=γs(σ(x)x−μ(x))+βs(5)
(7)Adaptive Instance Normalization(AdaIN)
AdaIN接收一个内容输入x xx和一个style输入y yy,通过将x xx的通道级(C CC)均值和标准差对齐匹配到y yy上以实现Normalization。相比BN/IN/CIN,AdaIN没有需要学习的仿射参数,其能够自适应地从style输入中计算仿射参数。
A d a I N ( x , y ) = σ ( y ) ( x − μ ( x ) σ ( x ) ) + μ ( y ) (6) {\rm {AdaIN}}(x,y)=\sigma(y)(\frac{x-\mu(x)}{\sigma(x)})+\mu(y) \tag{6}AdaIN(x,y)=σ(y)(σ(x)x−μ(x))+μ(y)(6)
AdaIN的IN是因为其和IN一样,也是对每一个样本(N NN)的每一个特征通道(C CC),在空间(H , W H,WH,W)计算均值和标准差。
(8)SPatially-Adaptive (DE) normalization(SPADE)
类似于BN,SPADE是在每一个单独的特征通道上做归一化。
给定语义分割的mask m ∈ L H × W m \in L^{H×W}m∈LH×W,其中L LL是指示语义标签的整数集,H HH和W WW是图像高度和宽度。
h hh是给定包含N个样本的批次经过网络后的某层特征图,在n ∈ N , c ∈ C , y ∈ H , x ∈ W n \in N, c ∈ C, y \in H, x \in Wn∈N,c∈C,y∈H,x∈W处的激活值为:
S P A D E ( h ; m ) = γ c , y , x ( m ) ( h n , c , y , x − μ c σ c ) + β c , y , x ( m ) (7) {\rm {SPADE}}(h;\bold m)=\gamma_{c,y,x}(\bold m)(\frac{h_{n,c,y,x}-\mu_c}{\sigma_c})+\beta_{c,y,x}(\bold m) \tag{7}SPADE(h;m)=γc,y,x(m)(σchn,c,y,x−μc)+βc,y,x(m)(7)
其中,h n , c , y , x h_{n,c,y,x}hn,c,y,x是经过normalization之前的激活值,μ c 和 σ c \mu_c和{\sigma_c}μc和σc是通道c上激活图的均值和标准差。
μ c ( x ) = 1 N H W ∑ n , y , x h n , c , y , x \mu_{c}(x)=\frac{1}{NHW}\sum_{n,y,x}h_{n,c,y,x}μc(x)=NHW1n,y,x∑hn,c,y,x
σ c ( x ) = 1 N H W ∑ n , y , x ( h n , c , y , x ) 2 − μ c 2 \sigma_{c}(x)=\sqrt{\frac{1}{NHW}\sum_{n,y,x}{(h_{n,c,y,x})^2-\mu_{c}^2}}σc(x)=NHW1n,y,x∑(hn,c,y,x)2−μc2
其中γ c , y , x ( m ) 和 β c , y , x ( m ) \gamma_{c,y,x}(\bold m)和\beta_{c,y,x}(\bold m)γc,y,x(m)和βc,y,x(m)是可学习参数,与BN不同的是它们取决于输入的语义分割mask,而且在不同的坐标( y , x ) (y,x)(y,x)处不同。
值得注意的是,如果对mask m \bold mm的任意两点( y 1 , x 1 ) (y_1,x_1)(y1,x1)和(y_2,x_2),y 1 , y 2 ∈ { 1 , 2 , 3... , H } y_1,y_2 \in \{1,2,3...,H\}y1,y2∈{1,2,3...,H}且x 1 , x 2 ∈ { 1 , 2 , 3... , W } x_1,x_2 \in \{1,2,3...,W\}x1,x2∈{1,2,3...,W},另仿射参数均相等,即γ c , y 1 , x 1 ≡ γ c , y 2 , x 2 \gamma_{c,y_1,x_1}\equiv\gamma_{c,y_2,x_2}γc,y1,x1≡γc,y2,x2且β c , y 1 , x 1 ≡ β c , y 2 , x 2 \beta_{c,y_1,x_1}\equiv\beta_{c,y_2,x_2}βc,y1,x1≡βc,y2,x2(仿射参数保持空间不变),则SPADE变成CBN(Conditional Batch Normalization)。
当用另外一张style图像替换mask图像后,令仿射参数保持空间不变且N=1,则SPADE变成AdaIN。
参考资料
[1] 【AI初识境】深度学习模型中的Normalization,你懂了多少?,有三AI公众号,https://mp.weixin.qq.com/s/Tuwg070YiXp5Rq4vULCy1w
[2] 详解深度学习中的Normalization,不只是BN,http://www.dataguru.cn/article-13031-1.html
[3]【算法】Normalization,https://www.cnblogs.com/dplearning/p/10145137.html
[4] 专栏 | 深度学习中的Normalization模型,https://www.sohu.com/a/250702875_129720
[5] BatchNormalization、LayerNormalization、InstanceNorm、GroupNorm、SwitchableNorm总结, https://blog.csdn.net/liuxiao214/article/details/81037416
[6] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, https://arxiv.org/pdf/1502.03167.pdf
[7] Instance Normalization: The Missing Ingredient for Fast Stylization, https://arxiv.org/abs/1607.08022
[8] Layer Normalization, https://arxiv.org/pdf/1607.06450.pdf
[9] Group Normalization, https://arxiv.org/pdf/1803.08494.pdf
[10] Modulating early visual processing by language, https://papers.nips.cc/paper/7237-modulating-early-visual-processing-by-language.pdf
[11] Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization,https://arxiv.org/abs/1703.06868
[12] Semantic Image Synthesis with Spatially-Adaptive Normalization,https://arxiv.org/abs/1903.07291v1
[13] Conditional Batch Normalization 详解,https://zhuanlan.zhihu.com/p/61248211