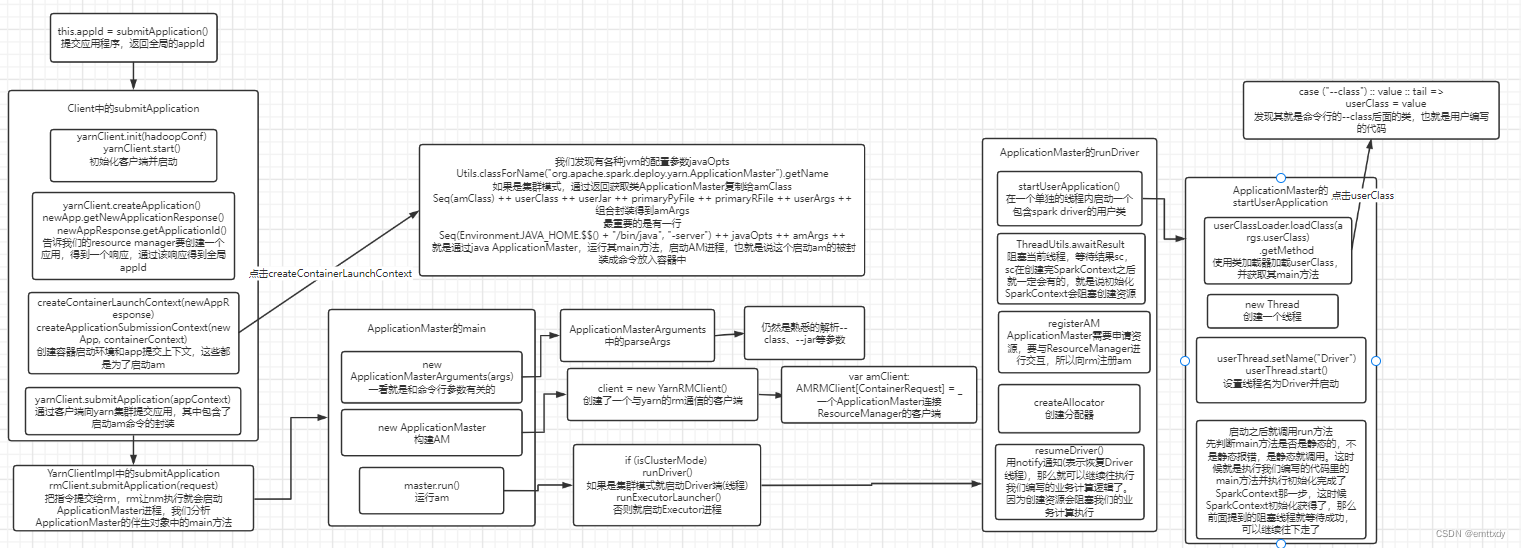
上一期指路
上一期我们分析到了YarnClusterApplication的start,我们继续从这里分析。
override def start(args: Array[String], conf: SparkConf): Unit = {
// SparkSubmit would use yarn cache to distribute files & jars in yarn mode,
// so remove them from sparkConf here for yarn mode.
conf.remove(JARS)
conf.remove(FILES)
new Client(new ClientArguments(args), conf, null).run()
}点击run
this.appId = submitApplication()
再点击submitApplication
1.Client#submitApplication
def submitApplication(): ApplicationId = {
ResourceRequestHelper.validateResources(sparkConf)
var appId: ApplicationId = null
try {
launcherBackend.connect()
yarnClient.init(hadoopConf)
yarnClient.start()
logInfo("Requesting a new application from cluster with %d NodeManagers"
.format(yarnClient.getYarnClusterMetrics.getNumNodeManagers))
// Get a new application from our RM
val newApp = yarnClient.createApplication()
val newAppResponse = newApp.getNewApplicationResponse()
appId = newAppResponse.getApplicationId()
// The app staging dir based on the STAGING_DIR configuration if configured
// otherwise based on the users home directory.
val appStagingBaseDir = sparkConf.get(STAGING_DIR)
.map { new Path(_, UserGroupInformation.getCurrentUser.getShortUserName) }
.getOrElse(FileSystem.get(hadoopConf).getHomeDirectory())
stagingDirPath = new Path(appStagingBaseDir, getAppStagingDir(appId))
new CallerContext("CLIENT", sparkConf.get(APP_CALLER_CONTEXT),
Option(appId.toString)).setCurrentContext()
// Verify whether the cluster has enough resources for our AM
verifyClusterResources(newAppResponse)
// Set up the appropriate contexts to launch our AM
val containerContext = createContainerLaunchContext(newAppResponse)
val appContext = createApplicationSubmissionContext(newApp, containerContext)
// Finally, submit and monitor the application
logInfo(s"Submitting application $appId to ResourceManager")
yarnClient.submitApplication(appContext)
launcherBackend.setAppId(appId.toString)
reportLauncherState(SparkAppHandle.State.SUBMITTED)
appId
} catch {
case e: Throwable =>
if (stagingDirPath != null) {
cleanupStagingDir()
}
throw e
}
}①yarnClient.init(hadoopConf)
yarnClient.start()
初始化客户端并启动
②yarnClient.createApplication() newApp.getNewApplicationResponse() newAppResponse.getApplicationId()
告诉我们的resource manager要创建一个应用,得到一个响应,通过该响应得到全局appId
③createContainerLaunchContext(newAppResponse)
createApplicationSubmissionContext(newApp, containerContext)
创建容器启动环境和app提交上下文,这些都是为了启动am
④yarnClient.submitApplication(appContext)
通过客户端向yarn集群提交应用,其中包含了启动am命令的封装
2.Client#createContainerLaunchContext
private def createContainerLaunchContext(newAppResponse: GetNewApplicationResponse)
: ContainerLaunchContext = {
logInfo("Setting up container launch context for our AM")
val appId = newAppResponse.getApplicationId
val pySparkArchives =
if (sparkConf.get(IS_PYTHON_APP)) {
findPySparkArchives()
} else {
Nil
}
val launchEnv = setupLaunchEnv(stagingDirPath, pySparkArchives)
val localResources = prepareLocalResources(stagingDirPath, pySparkArchives)
val amContainer = Records.newRecord(classOf[ContainerLaunchContext])
amContainer.setLocalResources(localResources.asJava)
amContainer.setEnvironment(launchEnv.asJava)
val javaOpts = ListBuffer[String]()
// Set the environment variable through a command prefix
// to append to the existing value of the variable
var prefixEnv: Option[String] = None
// Add Xmx for AM memory
javaOpts += "-Xmx" + amMemory + "m"
val tmpDir = new Path(Environment.PWD.$$(), YarnConfiguration.DEFAULT_CONTAINER_TEMP_DIR)
javaOpts += "-Djava.io.tmpdir=" + tmpDir
// TODO: Remove once cpuset version is pushed out.
// The context is, default gc for server class machines ends up using all cores to do gc -
// hence if there are multiple containers in same node, Spark GC affects all other containers'
// performance (which can be that of other Spark containers)
// Instead of using this, rely on cpusets by YARN to enforce "proper" Spark behavior in
// multi-tenant environments. Not sure how default Java GC behaves if it is limited to subset
// of cores on a node.
val useConcurrentAndIncrementalGC = launchEnv.get("SPARK_USE_CONC_INCR_GC").exists(_.toBoolean)
if (useConcurrentAndIncrementalGC) {
// In our expts, using (default) throughput collector has severe perf ramifications in
// multi-tenant machines
javaOpts += "-XX:+UseConcMarkSweepGC"
javaOpts += "-XX:MaxTenuringThreshold=31"
javaOpts += "-XX:SurvivorRatio=8"
javaOpts += "-XX:+CMSIncrementalMode"
javaOpts += "-XX:+CMSIncrementalPacing"
javaOpts += "-XX:CMSIncrementalDutyCycleMin=0"
javaOpts += "-XX:CMSIncrementalDutyCycle=10"
}
// Include driver-specific java options if we are launching a driver
if (isClusterMode) {
sparkConf.get(DRIVER_JAVA_OPTIONS).foreach { opts =>
javaOpts ++= Utils.splitCommandString(opts)
.map(Utils.substituteAppId(_, appId.toString))
.map(YarnSparkHadoopUtil.escapeForShell)
}
val libraryPaths = Seq(sparkConf.get(DRIVER_LIBRARY_PATH),
sys.props.get("spark.driver.libraryPath")).flatten
if (libraryPaths.nonEmpty) {
prefixEnv = Some(createLibraryPathPrefix(libraryPaths.mkString(File.pathSeparator),
sparkConf))
}
if (sparkConf.get(AM_JAVA_OPTIONS).isDefined) {
logWarning(s"${AM_JAVA_OPTIONS.key} will not take effect in cluster mode")
}
} else {
// Validate and include yarn am specific java options in yarn-client mode.
sparkConf.get(AM_JAVA_OPTIONS).foreach { opts =>
if (opts.contains("-Dspark")) {
val msg = s"${AM_JAVA_OPTIONS.key} is not allowed to set Spark options (was '$opts')."
throw new SparkException(msg)
}
if (opts.contains("-Xmx")) {
val msg = s"${AM_JAVA_OPTIONS.key} is not allowed to specify max heap memory settings " +
s"(was '$opts'). Use spark.yarn.am.memory instead."
throw new SparkException(msg)
}
javaOpts ++= Utils.splitCommandString(opts)
.map(Utils.substituteAppId(_, appId.toString))
.map(YarnSparkHadoopUtil.escapeForShell)
}
sparkConf.get(AM_LIBRARY_PATH).foreach { paths =>
prefixEnv = Some(createLibraryPathPrefix(paths, sparkConf))
}
}
// For log4j configuration to reference
javaOpts += ("-Dspark.yarn.app.container.log.dir=" + ApplicationConstants.LOG_DIR_EXPANSION_VAR)
val userClass =
if (isClusterMode) {
Seq("--class", YarnSparkHadoopUtil.escapeForShell(args.userClass))
} else {
Nil
}
val userJar =
if (args.userJar != null) {
Seq("--jar", args.userJar)
} else {
Nil
}
val primaryPyFile =
if (isClusterMode && args.primaryPyFile != null) {
Seq("--primary-py-file", new Path(args.primaryPyFile).getName())
} else {
Nil
}
val primaryRFile =
if (args.primaryRFile != null) {
Seq("--primary-r-file", args.primaryRFile)
} else {
Nil
}
val amClass =
if (isClusterMode) {
Utils.classForName("org.apache.spark.deploy.yarn.ApplicationMaster").getName
} else {
Utils.classForName("org.apache.spark.deploy.yarn.ExecutorLauncher").getName
}
if (args.primaryRFile != null &&
(args.primaryRFile.endsWith(".R") || args.primaryRFile.endsWith(".r"))) {
args.userArgs = ArrayBuffer(args.primaryRFile) ++ args.userArgs
}
val userArgs = args.userArgs.flatMap { arg =>
Seq("--arg", YarnSparkHadoopUtil.escapeForShell(arg))
}
val amArgs =
Seq(amClass) ++ userClass ++ userJar ++ primaryPyFile ++ primaryRFile ++ userArgs ++
Seq("--properties-file",
buildPath(Environment.PWD.$$(), LOCALIZED_CONF_DIR, SPARK_CONF_FILE)) ++
Seq("--dist-cache-conf",
buildPath(Environment.PWD.$$(), LOCALIZED_CONF_DIR, DIST_CACHE_CONF_FILE))
// Command for the ApplicationMaster
val commands = prefixEnv ++
Seq(Environment.JAVA_HOME.$$() + "/bin/java", "-server") ++
javaOpts ++ amArgs ++
Seq(
"1>", ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stdout",
"2>", ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stderr")
// TODO: it would be nicer to just make sure there are no null commands here
val printableCommands = commands.map(s => if (s == null) "null" else s).toList
amContainer.setCommands(printableCommands.asJava)
logDebug("===============================================================================")
logDebug("YARN AM launch context:")
logDebug(s" user class: ${Option(args.userClass).getOrElse("N/A")}")
logDebug(" env:")
if (log.isDebugEnabled) {
Utils.redact(sparkConf, launchEnv.toSeq).foreach { case (k, v) =>
logDebug(s" $k -> $v")
}
}
logDebug(" resources:")
localResources.foreach { case (k, v) => logDebug(s" $k -> $v")}
logDebug(" command:")
logDebug(s" ${printableCommands.mkString(" ")}")
logDebug("===============================================================================")
// send the acl settings into YARN to control who has access via YARN interfaces
val securityManager = new SecurityManager(sparkConf)
amContainer.setApplicationACLs(
YarnSparkHadoopUtil.getApplicationAclsForYarn(securityManager).asJava)
setupSecurityToken(amContainer)
amContainer
}我们发现有各种jvm的配置参数javaOpts
Utils.classForName("org.apache.spark.deploy.yarn.ApplicationMaster").getName
如果是集群模式,通过返回获取类ApplicationMaster复制给amClass
Seq(amClass) ++ userClass ++ userJar ++ primaryPyFile ++ primaryRFile ++ userArgs ++
组合封装得到amArgs
最重要的是有一行
Seq(Environment.JAVA_HOME.$$() + "/bin/java", "-server") ++ javaOpts ++ amArgs ++
就是通过java ApplicationMaster,运行其main方法,启动AM进程,也就是说这个启动am的被封装成命令放入容器中
YarnClientImpl#submitApplication->
rmClient.submitApplication(request)
把指令提交给rm,rm让nm执行就会启动ApplicationMaster进程,我们分析ApplicationMaster的伴生对象中的main方法
3.ApplicationMaster#main
def main(args: Array[String]): Unit = {
SignalUtils.registerLogger(log)
val amArgs = new ApplicationMasterArguments(args)
val sparkConf = new SparkConf()
if (amArgs.propertiesFile != null) {
Utils.getPropertiesFromFile(amArgs.propertiesFile).foreach { case (k, v) =>
sparkConf.set(k, v)
}
}
// Set system properties for each config entry. This covers two use cases:
// - The default configuration stored by the SparkHadoopUtil class
// - The user application creating a new SparkConf in cluster mode
//
// Both cases create a new SparkConf object which reads these configs from system properties.
sparkConf.getAll.foreach { case (k, v) =>
sys.props(k) = v
}
val yarnConf = new YarnConfiguration(SparkHadoopUtil.newConfiguration(sparkConf))
master = new ApplicationMaster(amArgs, sparkConf, yarnConf)
val ugi = sparkConf.get(PRINCIPAL) match {
// We only need to log in with the keytab in cluster mode. In client mode, the driver
// handles the user keytab.
case Some(principal) if master.isClusterMode =>
val originalCreds = UserGroupInformation.getCurrentUser().getCredentials()
SparkHadoopUtil.get.loginUserFromKeytab(principal, sparkConf.get(KEYTAB).orNull)
val newUGI = UserGroupInformation.getCurrentUser()
if (master.appAttemptId == null || master.appAttemptId.getAttemptId > 1) {
// Re-obtain delegation tokens if this is not a first attempt, as they might be outdated
// as of now. Add the fresh tokens on top of the original user's credentials (overwrite).
// Set the context class loader so that the token manager has access to jars
// distributed by the user.
Utils.withContextClassLoader(master.userClassLoader) {
val credentialManager = new HadoopDelegationTokenManager(sparkConf, yarnConf, null)
credentialManager.obtainDelegationTokens(originalCreds)
}
}
// Transfer the original user's tokens to the new user, since it may contain needed tokens
// (such as those user to connect to YARN).
newUGI.addCredentials(originalCreds)
newUGI
case _ =>
SparkHadoopUtil.get.createSparkUser()
}
ugi.doAs(new PrivilegedExceptionAction[Unit]() {
override def run(): Unit = System.exit(master.run())
})
}①new ApplicationMasterArguments(args)
一看就是和命令行参数有关的
ApplicationMasterArguments中的parseArgs,仍然是熟悉的解析--class、--jar等参数
②new ApplicationMaster
构建AM,点击去发现如下:
③master.run()
运行am

4.ApplicationMaster#run
final def run(): Int = {
try {
val attemptID = if (isClusterMode) {
// Set the web ui port to be ephemeral for yarn so we don't conflict with
// other spark processes running on the same box
System.setProperty(UI_PORT.key, "0")
// Set the master and deploy mode property to match the requested mode.
System.setProperty("spark.master", "yarn")
System.setProperty(SUBMIT_DEPLOY_MODE.key, "cluster")
// Set this internal configuration if it is running on cluster mode, this
// configuration will be checked in SparkContext to avoid misuse of yarn cluster mode.
System.setProperty("spark.yarn.app.id", appAttemptId.getApplicationId().toString())
Option(appAttemptId.getAttemptId.toString)
} else {
None
}
new CallerContext(
"APPMASTER", sparkConf.get(APP_CALLER_CONTEXT),
Option(appAttemptId.getApplicationId.toString), attemptID).setCurrentContext()
logInfo("ApplicationAttemptId: " + appAttemptId)
// This shutdown hook should run *after* the SparkContext is shut down.
val priority = ShutdownHookManager.SPARK_CONTEXT_SHUTDOWN_PRIORITY - 1
ShutdownHookManager.addShutdownHook(priority) { () =>
val maxAppAttempts = client.getMaxRegAttempts(sparkConf, yarnConf)
val isLastAttempt = appAttemptId.getAttemptId() >= maxAppAttempts
if (!finished) {
// The default state of ApplicationMaster is failed if it is invoked by shut down hook.
// This behavior is different compared to 1.x version.
// If user application is exited ahead of time by calling System.exit(N), here mark
// this application as failed with EXIT_EARLY. For a good shutdown, user shouldn't call
// System.exit(0) to terminate the application.
finish(finalStatus,
ApplicationMaster.EXIT_EARLY,
"Shutdown hook called before final status was reported.")
}
if (!unregistered) {
// we only want to unregister if we don't want the RM to retry
if (finalStatus == FinalApplicationStatus.SUCCEEDED || isLastAttempt) {
unregister(finalStatus, finalMsg)
cleanupStagingDir(new Path(System.getenv("SPARK_YARN_STAGING_DIR")))
}
}
}
if (isClusterMode) {
runDriver()
} else {
runExecutorLauncher()
}
} catch {
case e: Exception =>
// catch everything else if not specifically handled
logError("Uncaught exception: ", e)
finish(FinalApplicationStatus.FAILED,
ApplicationMaster.EXIT_UNCAUGHT_EXCEPTION,
"Uncaught exception: " + StringUtils.stringifyException(e))
} finally {
try {
metricsSystem.foreach { ms =>
ms.report()
ms.stop()
}
} catch {
case e: Exception =>
logWarning("Exception during stopping of the metric system: ", e)
}
}
exitCode
}if (isClusterMode) runDriver()
如果是集群模式就启动Driver端(线程)
runExecutorLauncher()
否则就启动Executor进程
5.ApplicationMaster#runDriver
private def runDriver(): Unit = {
addAmIpFilter(None, System.getenv(ApplicationConstants.APPLICATION_WEB_PROXY_BASE_ENV))
userClassThread = startUserApplication()
// This a bit hacky, but we need to wait until the spark.driver.port property has
// been set by the Thread executing the user class.
logInfo("Waiting for spark context initialization...")
val totalWaitTime = sparkConf.get(AM_MAX_WAIT_TIME)
try {
val sc = ThreadUtils.awaitResult(sparkContextPromise.future,
Duration(totalWaitTime, TimeUnit.MILLISECONDS))
if (sc != null) {
val rpcEnv = sc.env.rpcEnv
val userConf = sc.getConf
val host = userConf.get(DRIVER_HOST_ADDRESS)
val port = userConf.get(DRIVER_PORT)
registerAM(host, port, userConf, sc.ui.map(_.webUrl), appAttemptId)
val driverRef = rpcEnv.setupEndpointRef(
RpcAddress(host, port),
YarnSchedulerBackend.ENDPOINT_NAME)
createAllocator(driverRef, userConf, rpcEnv, appAttemptId, distCacheConf)
} else {
// Sanity check; should never happen in normal operation, since sc should only be null
// if the user app did not create a SparkContext.
throw new IllegalStateException("User did not initialize spark context!")
}
resumeDriver()
userClassThread.join()
} catch {
case e: SparkException if e.getCause().isInstanceOf[TimeoutException] =>
logError(
s"SparkContext did not initialize after waiting for $totalWaitTime ms. " +
"Please check earlier log output for errors. Failing the application.")
finish(FinalApplicationStatus.FAILED,
ApplicationMaster.EXIT_SC_NOT_INITED,
"Timed out waiting for SparkContext.")
} finally {
resumeDriver()
}
}
①startUserApplication()
在一个单独的线程内启动一个包含spark driver的用户类
②ThreadUtils.awaitResult
阻塞当前线程,等待结果sc,sc在创建完SparkContext之后就一定会有的,就是说初始化SparkContext会阻塞创建资源
③registerAM
ApplicationMaster需要申请资源,要与ResourceManager进行交互,所以向rm注册am
④createAllocator
创建分配器
⑤resumeDriver()
用notify通知(表示恢复Driver线程),那么就可以继续往执行我们编写的业务计算逻辑了。因为创建资源会阻塞我们的业务计算执行
6.ApplicationMaster#startUserApplication
private def startUserApplication(): Thread = {
logInfo("Starting the user application in a separate Thread")
var userArgs = args.userArgs
if (args.primaryPyFile != null && args.primaryPyFile.endsWith(".py")) {
// When running pyspark, the app is run using PythonRunner. The second argument is the list
// of files to add to PYTHONPATH, which Client.scala already handles, so it's empty.
userArgs = Seq(args.primaryPyFile, "") ++ userArgs
}
if (args.primaryRFile != null &&
(args.primaryRFile.endsWith(".R") || args.primaryRFile.endsWith(".r"))) {
// TODO(davies): add R dependencies here
}
val mainMethod = userClassLoader.loadClass(args.userClass)
.getMethod("main", classOf[Array[String]])
val userThread = new Thread {
override def run(): Unit = {
try {
if (!Modifier.isStatic(mainMethod.getModifiers)) {
logError(s"Could not find static main method in object ${args.userClass}")
finish(FinalApplicationStatus.FAILED, ApplicationMaster.EXIT_EXCEPTION_USER_CLASS)
} else {
mainMethod.invoke(null, userArgs.toArray)
finish(FinalApplicationStatus.SUCCEEDED, ApplicationMaster.EXIT_SUCCESS)
logDebug("Done running user class")
}
} catch {
case e: InvocationTargetException =>
e.getCause match {
case _: InterruptedException =>
// Reporter thread can interrupt to stop user class
case SparkUserAppException(exitCode) =>
val msg = s"User application exited with status $exitCode"
logError(msg)
finish(FinalApplicationStatus.FAILED, exitCode, msg)
case cause: Throwable =>
logError("User class threw exception: " + cause, cause)
finish(FinalApplicationStatus.FAILED,
ApplicationMaster.EXIT_EXCEPTION_USER_CLASS,
"User class threw exception: " + StringUtils.stringifyException(cause))
}
sparkContextPromise.tryFailure(e.getCause())
} finally {
// Notify the thread waiting for the SparkContext, in case the application did not
// instantiate one. This will do nothing when the user code instantiates a SparkContext
// (with the correct master), or when the user code throws an exception (due to the
// tryFailure above).
sparkContextPromise.trySuccess(null)
}
}
}
userThread.setContextClassLoader(userClassLoader)
userThread.setName("Driver")
userThread.start()
userThread
}①userClassLoader.loadClass(args.userClass) .getMethod
使用类加载器加载userClass,并获取其main方法
②new Thread
创建一个线程
③userThread.setName("Driver") userThread.start()
设置线程名为Driver并启动
④
启动之后就调用run方法
先判断main方法是否是静态的,不是静态报错,是静态就调用。这时候就是执行我们编写的代码里的main方法并执行初始化完成了SparkContext那一步,这时候SparkContext初始化获得了,那么前面提到的阻塞线程就等待成功,可以继续往下走了

总览
这一期涉及到的源码流程图如下: