实现功能:
python实现比例类指标差异分析-卡方检验。对sex这一列,按照target取值进行分组差异分析。
实现代码:
# 导入需要的库
from warnings import simplefilter
simplefilter(action='ignore', category=FutureWarning)
import pandas as pd
import numpy as np
from scipy.stats import chi2_contingency
# =============读取数据===========
def Read_data(file):
dt = pd.read_csv(file)
dt.columns = ['age', 'sex', 'chest_pain_type', 'resting_blood_pressure', 'cholesterol','fasting_blood_sugar', 'rest_ecg', 'max_heart_rate_achieved','exercise_induced_angina','st_depression', 'st_slope', 'num_major_vessels', 'thalassemia', 'target']
data =dt
return data
# ===========数据清洗==============
def data_clean(data):
# 重复值处理
print('存在' if any(data.duplicated()) else '不存在', '重复观测值')
data.drop_duplicates()
# 缺失值处理
print('不存在' if any(data.isnull()) else '存在', '缺失值')
data.dropna() # 直接删除记录
data.fillna(method='ffill') # 前向填充
data.fillna(method='bfill') # 后向填充
data.fillna(value=2) # 值填充
data.fillna(value={'resting_blood_pressure': data['resting_blood_pressure'].mean()}) # 统计值填充
# 异常值处理
data1 = data['resting_blood_pressure']
# 标准差监测
xmean = data1.mean()
xstd = data1.std()
print('存在' if any(data1 > xmean + 2 * xstd) else '不存在', '上限异常值')
print('存在' if any(data1 < xmean - 2 * xstd) else '不存在', '下限异常值')
# 箱线图监测
q1 = data1.quantile(0.25)
q3 = data1.quantile(0.75)
up = q3 + 1.5 * (q3 - q1)
dw = q1 - 1.5 * (q3 - q1)
print('存在' if any(data1 > up) else '不存在', '上限异常值')
print('存在' if any(data1 < dw) else '不存在', '下限异常值')
print(data)
return data
# ===========卡方检验==============
def sex_chisq(data):
data1=data[['sex','target']]
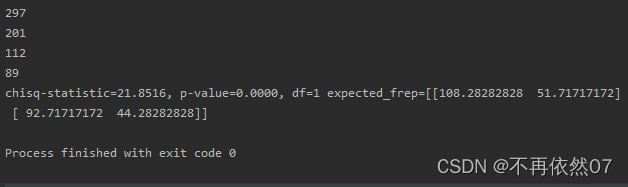
print(len(data1))
print(len(data1[(data1['sex'] == 1)]))
data_sex_Y=data1[(data1['target'] ==1)&(data1['sex'] == 1)]
print(len(data_sex_Y))
data_sex_N=data1[(data1['target'] ==0)&(data1['sex'] == 1)]
print(len(data_sex_N))
kf_data = np.array([[len(data_sex_N), len(data1[(data1['target'] ==0)]) - len(data_sex_N)],
[len(data_sex_Y), len(data1[(data1['target'] ==1)]) - len(data_sex_Y)]])
kf = chi2_contingency(kf_data)
print('chisq-statistic=%.4f, p-value=%.4f, df=%i expected_frep=%s' % kf)
return
#============主函数==============
if __name__=="__main__":
data1=Read_data("F:\数据杂坛\\0504\heartdisease\Heart-Disease-Data-Set-main\\UCI Heart Disease Dataset.csv")
data1=data_clean(data1)
sex_chisq(data1)
实现效果:
喜欢记得点赞,在看,收藏,
关注V订阅号:数据杂坛,获取数据集,完整代码和效果,将持续更新!

版权声明:本文为sinat_41858359原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。