目录
一、Hadoop简介
1、 Hadoop框架与模块
二、Hadoop工作模式
1、Hadoop部署(单机部署)
2、伪分布式
3、完全分布式
4、扩容DN节点
三、资源管理器YARN
一、Hadoop简介
1、Hadoop框架与模块
Hadoop名字不是一个缩写,是Hadoop之父Doug Cutting儿子毛绒玩具象命名的。
Hadoop起源于Google的三大论文:
GFS:Google的分布式文件系统Google File System
MapReduce:Google的MapReduce开源分布式并行计算框架
BigTable:一个大型的分布式数据库
演变关系:
GFS—->HDFS
Google MapReduce—->Hadoop MapReduce
Google MapReduce—->Hadoop MapReduce
hadoop主流版本:
Apache基金会hadoop
Cloudera版本(Cloudera’s Distribution Including Apache Hadoop,简称“CDH”)
Hortonworks版本(Hortonworks Data Platform,简称“HDP”)
Hadoop框架包括以下四个模块:
Hadoop Common: 这些是其他Hadoop模块所需的Java库和实用程序。这些库提供文件系统和操作系统级抽象,并包含启动Hadoop所需的Java文件和脚本。
Hadoop YARN: 这是一个用于作业调度和集群资源管理的框架。
Hadoop Distributed File System (HDFS): 分布式文件系统,提供对应用程序数据的高吞吐量访问。
Hadoop MapReduce:这是基于YARN的用于并行处理大数据集的系统。
其中最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,MapReduce为海量的数据提供了计算。
hadoop应用场景:
在线旅游、移动数据、电子商务、能源开采与节能、基础架构管理、图像处理、诈骗检测、IT安全、医疗保健等等
二、Hadoop工作模式
Apache Hadoophttp://hadoop.apache.org/
1、hadoop部署
真实主机创建1台新的虚拟机 server13(namenode) 内存为2G
真实主机下载hadoop官方套件,需要jdk环境,发送给server13
创建hadoop用户,并为hadoop设置用户密码 ,切换到这一普通用户运行,不建议使用超级用户身份
useradd hadoop
由于是在创建好的hadoop下进行操作 需要修改文件权限 修改文件用户和所属组为hadoop
使用源码安装(不用rpm包安装) 并创建软连接
进入/home/hadoop/hadoop/etc/hadoop目录下,编辑hadoop-env.sh脚本文件 
配置环境变量 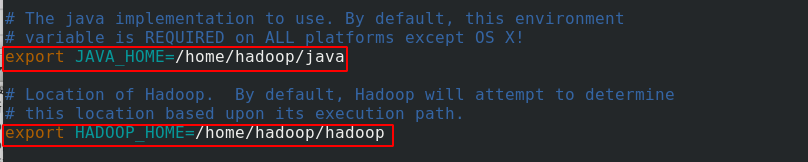
复制/etc/hadoop/*.xml至创建的input目录中
![]()
配置在非分布式模式下作为jar运行,查找并显示匹配正则表达式的内容。 将输出写入到 output目录,output目录会自动创建
查看output目录被创建 查看其里边的内容 
2、伪分布式
伪分布式就是假分布式,假就假在只有一台机器而不是多台机器来完成一个任务,但是模拟了分布式的这个过程,所以伪分布式下Hadoop也就是虽然在一个机器上配置了hadoop的所有节点,但伪分布式完成了所有分布式所必须的事件。伪分布式Hadoop和单机版最大区别就在于需要配置HDFS。
编辑core-site.xml文件,指定hdfs的NN的ip,由于是伪分布式,所以主从都在一起,填写本机9000端口 

编辑hdfs-site.xml文件,以伪分布式模式在单节点上运行,每个 Hadoop 守护进程作为单独的 Java 进程运行。副本数设置为1![]()

查看workers,是自己![]()
hadoop用户生成密钥
复制密钥给localhost并测试免密登录 
初始化文件系统
初始化完成后,数据都存放在/tmp目录下
启动NN和DN

jps显示当前开启的java进程,使用此命令需要将jps命令添加到环境变量
编辑.bash_profile添加java环境变量![]()

source激活环境变量,使用jps命令,可以看到启动的进程
查看正在运行的java进程

删除output目录 重新运行 以单词数统计input目录内容将结果输出到output

运行失败报错 input路径不存在
浏览器访问server1的9870端口进入hadoop页面9870是hadoop默认的监听端口,9000是Namenode和Datanode的连接端口 
当前的伪分布模式活着就一个节点
hadoop分布式文件系统默认信息会初始化在/tmp/下
server13输入bin/hdfs dfsadmin -report通过命令行查看文件系统 
文件系统信息如图
创建用户主目录,注意用户要一致,查看上传目录没有文件,上传input目录
通过浏览器图形化界面界面查看文件系统

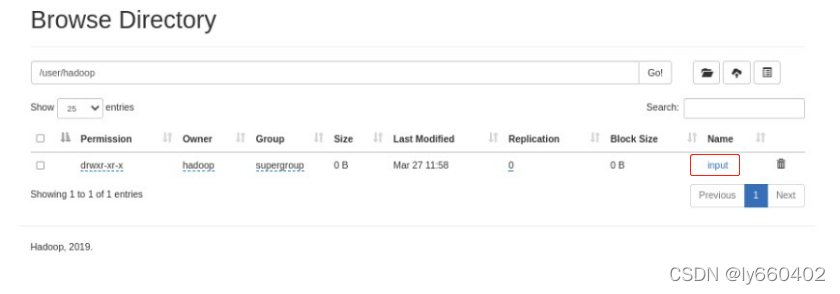

删除input目录 用bin命令进行统计,input不是本地的 它的数据已经上传至分布式文件系统,以单词数统计input目录内容将结果输出到output

本地已经删除了output目录,再查看还是可以看到该目录及其内容,因为已经上传到了分布式中 


在hadoop页面中可以看到该目录
点击进入output目录,查看其包含的内容 
本地在分布式中下载output目录,然后切换到该目录查看其内容,正常 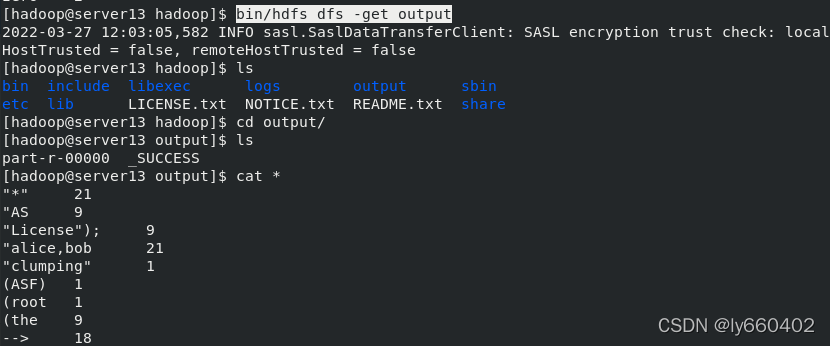
3、完全分布式
完全分布式部署需要将DN和NN分开,NameNode-master只保留源数据,不存储数据 删除掉output目录
停止伪分布部署 
真机重新在开启两台新的虚拟机 server11(datanode) server12(datanode) 内存最少为2G
hadoop要求所有节点NN和DN的配置一样 所有节点需要同步
所有的数据都在/home/hadoop/目录下 只需要使用nfs-utils套件来完成同步
server13安装nfs-utils文件系统
启动服务并设置开机自启 编辑/etc/exports 共享/home/hadoop目录,赋予读写权限,匿名用户uid和gid与master节点的hadoop用户一致 
exportfs -rv刷新 
server11和server12安装nfs文件系统 实现数据同步
添加hadoop用户 生产环境中所有集群部署需要时间同步
server11挂载nfs中server1分享的/home/hadoop目录到本地的/home/hadoop目录,然后切换到hadoop用户
server12节点同样的操作

server13测试与server11和server12的ssh免密连接,成功连接
使用nfs文件系统,挂载目录下的数据都是同步的。数据同步后 已自动设置好免密
进入到 /etc/hadoop目录下 编辑core-site.xml文件
定义master 可以设定ip地址 也可以设定主机名称
编辑hdfs-site.xml,将副本数量改为2 ![]()

再编辑workers,指定server11和server12是数据节点 (DN)
清理/tmp/目录 重新进行初始化

初始化完成后,数据都存放在/tmp。启动NN和DN
使用jps查看java进程,可以看到server13作为NN节点运行 secondnode表示当master的NN down掉后由它来接管
 这时通过免密 启动server11 12 的DN节点
这时通过免密 启动server11 12 的DN节点
server11 12jps查看java进程,可以看到作为DN节点在运行
![]()


![]()

浏览器访问hadoop图形化页面,点击查看DN节点信息,可以看到server2和server3正常显示
重新格式化文件系统,之前数据都被清除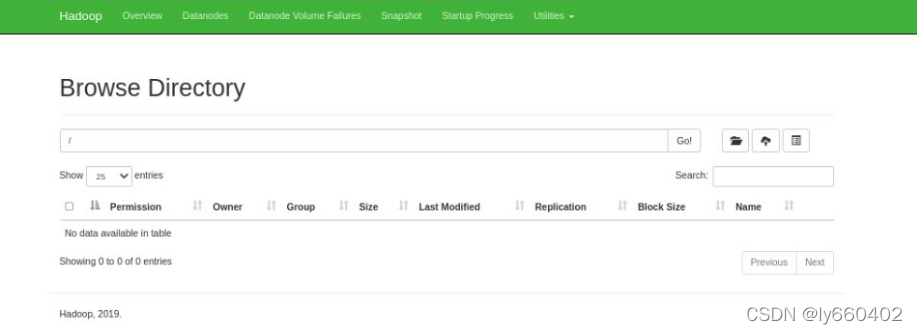
![]()
server13在dfs创建虚拟目录/user/hadoop 
浏览器查看创建成功

在创建input目录,将input目录上传至文件系统
图形化的方式点击进入input目录,可以正常查看目录内容


再次以单词数统计input目录内容将结果输出到output

![]()

图形化查看 进入output目录,内容正常显示
默认不允许使用图形化的方式上传 只能使用命令行的方式
4、扩容DN节点
在添加一台虚拟机 server14作为DN
安装nfs-utils
添加hadoop用户并挂载 


添加worker节点
server14返回到/hadoop/目录,运行DN节点进程 启动成功后jps查看DN节点正在运行
现在hadoop页面上可以看到server4加入到工作节点
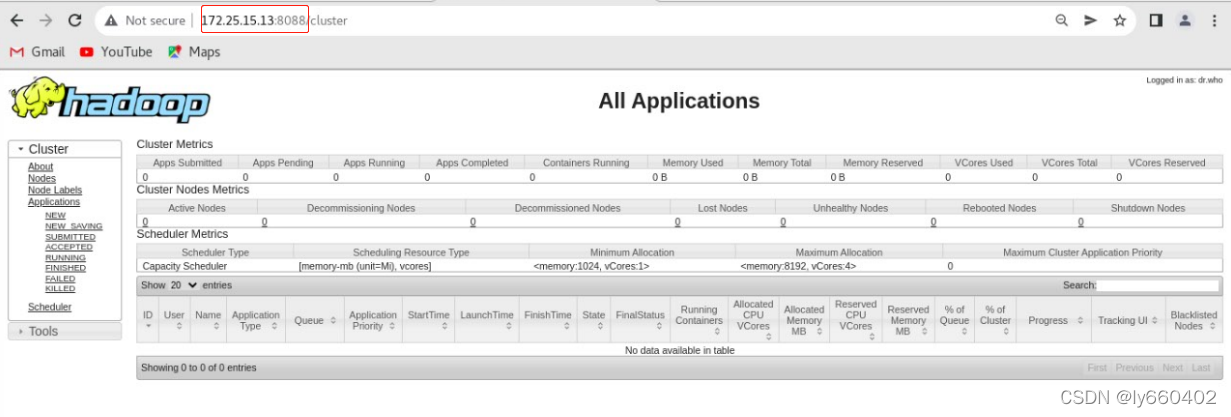
三、资源管理器YARN
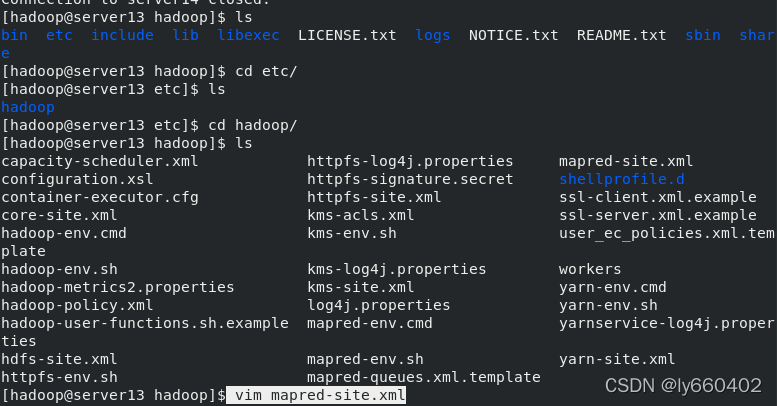
编辑etc/hadoop/mapred-site.xml文件,添加mapreduce模块,$HADOOP_MAPERD_HOME变量稍后会在环境变量中定义

编辑hadoop-env.sh环境变量文件,定义HADOOP_MAPERD_HOME变量![]()

编辑-site.xml文件,添加nodemanager模块 yarn![]() https://so.csdn.net/so/search?q=yarn&spm=1001.2101.3001.7020
https://so.csdn.net/so/search?q=yarn&spm=1001.2101.3001.7020![]()

server13开启yarn,jps查看java进程,可以看到ResourceManager运行


在所有的worker启动NM节点管理器


浏览器访问server1的8088端口可以查看资源管理页面