概述
随机梯度下降,和批量梯度下降原理类似,区别在于求梯度时没有用所有样本的数据,而是仅仅选取一个样本j来求梯度,更新公式为:
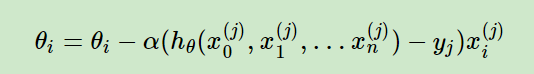
随机梯度下降法由于每次仅仅采用一个样本来迭代,训练速度很快
# -*- coding:utf-8 _*-
# @author: Fu zihao
# @file: pre01.py
import numpy as np
import random
# 学习率
ALPHA = 0.001
# 允许的最大误差
ERROR = 0.01
X1 = np.array([2014, 1600, 2400, 1416, 3000]).reshape(5, 1)
X2 = np.array([3, 3, 3, 2, 4]).reshape(5, 1)
T = np.array([400, 330, 369, 232, 540]).reshape(5, 1)
st0 = 0.5
st1 = 0.5
st2 = 0.5
ST0 = np.array([0.5, 0.5, 0.5, 0.5, 0.5]).reshape(5, 1)
def DT(X1, X2, T, ST0, st1, st2):
dt0 = ST0 + st1 * X1 + st2 * X2 - T
print(dt0, "--------------------")
dt1 = (ST0 + st1 * X1 + st2 * X2 - T) * X1
dt2 = (ST0 + st1 * X1 + st2 * X2 - T) * X2
result = np.hstack((dt0, dt1, dt2))
return result
dt = DT(X1, X2, T, ST0, st1, st2)[0]
dt0 = dt[0]
dt1 = dt[1]
dt2 = dt[2]
print(dt)
while dt0 >= ERROR or dt1 >= ERROR or dt2 >= ERROR:
i = random.randint(0, 4)
st0 = st0 - ALPHA * dt0
st1 = st1 - ALPHA * dt1
st2 = st2 - ALPHA * dt2
ST0N = np.array([st0, st0, st0, st0, st0]).reshape(5, 1)
dt = DT(X1, X2, T, ST0N, st1, st2)[i]
dt0 = dt[0]
dt1 = dt[1]
dt2 = dt[2]
print("-------------------end--------------------")
print(st0, st1, st2)
版权声明:本文为weixin_51062176原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。