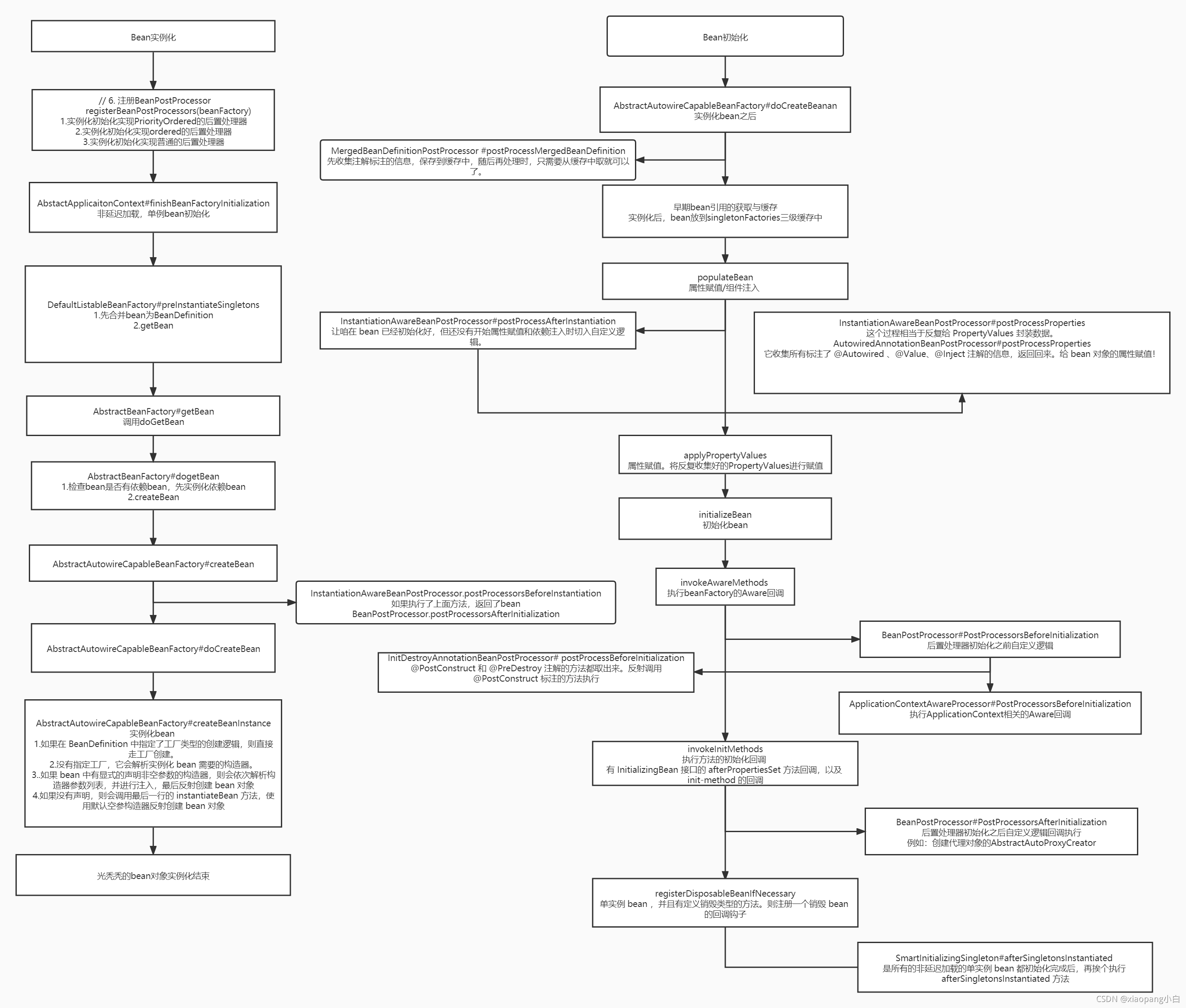
bean实例化研究了createBeanInstance方法。
接下来看bean的初始化。
主要点如下:
1.bean 的属性赋值 & 组件依赖注入
2.bean 的初始化方法回调
3.重要的 BeanPostProcessor 功能解析
doCreateBean
protected Object doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) throws BeanCreationException {
BeanWrapper instanceWrapper = null;
if (mbd.isSingleton()) {
instanceWrapper = (BeanWrapper)this.factoryBeanInstanceCache.remove(beanName);
}
if (instanceWrapper == null) {
instanceWrapper = this.createBeanInstance(beanName, mbd, args);
}
Object bean = instanceWrapper.getWrappedInstance();
Class<?> beanType = instanceWrapper.getWrappedClass();
if (beanType != NullBean.class) {
mbd.resolvedTargetType = beanType;
}
synchronized(mbd.postProcessingLock) {
if (!mbd.postProcessed) {
try {
this.applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
} catch (Throwable var17) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Post-processing of merged bean definition failed", var17);
}
mbd.postProcessed = true;
}
}
boolean earlySingletonExposure = mbd.isSingleton() && this.allowCircularReferences && this.isSingletonCurrentlyInCreation(beanName);
if (earlySingletonExposure) {
if (this.logger.isTraceEnabled()) {
this.logger.trace("Eagerly caching bean '" + beanName + "' to allow for resolving potential circular references");
}
this.addSingletonFactory(beanName, () -> {
return this.getEarlyBeanReference(beanName, mbd, bean);
});
}
Object exposedObject = bean;
try {
this.populateBean(beanName, mbd, instanceWrapper);
exposedObject = this.initializeBean(beanName, exposedObject, mbd);
} catch (Throwable var18) {
if (var18 instanceof BeanCreationException && beanName.equals(((BeanCreationException)var18).getBeanName())) {
throw (BeanCreationException)var18;
}
throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Initialization of bean failed", var18);
}
if (earlySingletonExposure) {
Object earlySingletonReference = this.getSingleton(beanName, false);
if (earlySingletonReference != null) {
if (exposedObject == bean) {
exposedObject = earlySingletonReference;
} else if (!this.allowRawInjectionDespiteWrapping && this.hasDependentBean(beanName)) {
String[] dependentBeans = this.getDependentBeans(beanName);
Set<String> actualDependentBeans = new LinkedHashSet(dependentBeans.length);
String[] var12 = dependentBeans;
int var13 = dependentBeans.length;
for(int var14 = 0; var14 < var13; ++var14) {
String dependentBean = var12[var14];
if (!this.removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) {
actualDependentBeans.add(dependentBean);
}
}
if (!actualDependentBeans.isEmpty()) {
throw new BeanCurrentlyInCreationException(beanName, "Bean with name '" + beanName + "' has been injected into other beans [" + StringUtils.collectionToCommaDelimitedString(actualDependentBeans) + "] in its raw version as part of a circular reference, but has eventually been wrapped. This means that said other beans do not use the final version of the bean. This is often the result of over-eager type matching - consider using 'getBeanNamesForType' with the 'allowEagerInit' flag turned off, for example.");
}
}
}
}
try {
this.registerDisposableBeanIfNecessary(beanName, bean, mbd);
return exposedObject;
} catch (BeanDefinitionValidationException var16) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Invalid destruction signature", var16);
}
}
MergedBeanDefinitionPostProcessor
// …
// Allow post-processors to modify the merged bean definition.
synchronized (mbd.postProcessingLock) {
if (!mbd.postProcessed) {
try {
applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
}
// catch …
mbd.postProcessed = true;
}
}
// …
这个阶段它会回调所有的 MergedBeanDefinitionPostProcessor 。
这里面有几个关键的MergedBeanDefinitionPostProcessor 后置处理器的实现。
InitDestroyAnnotationBeanPostProcessor
它是处理初始化和销毁**注解**的后置处理器。
public void postProcessMergedBeanDefinition(RootBeanDefinition beanDefinition, Class<?> beanType, String beanName) {
LifecycleMetadata metadata = findLifecycleMetadata(beanType);
metadata.checkConfigMembers(beanDefinition);
}
findLifecycleMetadata 方法是查找 bean 的生命周期元信息:
private LifecycleMetadata findLifecycleMetadata(Class<?> clazz) {
if (this.lifecycleMetadataCache == null) {
// Happens after deserialization, during destruction...
return buildLifecycleMetadata(clazz);
}
// 构建缓存 ......
return metadata;
}
用缓存机制,把 bean 的初始化和销毁注解信息都保存到 lifecycleMetadataCache 里了。缓存的对象如下:
目标类信息,初始化方法集合,销毁方法集合。
private class LifecycleMetadata {
private final Class<?> targetClass;
private final Collection<InitDestroyAnnotationBeanPostProcessor.LifecycleElement> initMethods;
private final Collection<InitDestroyAnnotationBeanPostProcessor.LifecycleElement> destroyMethods;
进入buildLifecycleMetadata 方法
private LifecycleMetadata buildLifecycleMetadata(final Class<?> clazz) {
if (!AnnotationUtils.isCandidateClass(clazz, Arrays.asList(this.initAnnotationType, this.destroyAnnotationType))) {
return this.emptyLifecycleMetadata;
}
List<LifecycleElement> initMethods = new ArrayList<>();
List<LifecycleElement> destroyMethods = new ArrayList<>();
Class<?> targetClass = clazz;
do {
final List<LifecycleElement> currInitMethods = new ArrayList<>();
final List<LifecycleElement> currDestroyMethods = new ArrayList<>();
// 反射所有的public方法
ReflectionUtils.doWithLocalMethods(targetClass, method -> {
// 寻找所有被初始化注解标注的方法
if (this.initAnnotationType != null && method.isAnnotationPresent(this.initAnnotationType)) {
LifecycleElement element = new LifecycleElement(method);
currInitMethods.add(element);
}
// 寻找所有被销毁注解标注的方法
if (this.destroyAnnotationType != null && method.isAnnotationPresent(this.destroyAnnotationType)) {
currDestroyMethods.add(new LifecycleElement(method));
}
});
initMethods.addAll(0, currInitMethods);
destroyMethods.addAll(currDestroyMethods);
targetClass = targetClass.getSuperclass();
} // 依次向上寻找父类
while (targetClass != null && targetClass != Object.class);
return (initMethods.isEmpty() && destroyMethods.isEmpty() ? this.emptyLifecycleMetadata :
new LifecycleMetadata(clazz, initMethods, destroyMethods));
}
它会寻找这个 bean 所属的 Class 中是否有包含初始化注解和销毁注解的方法。初始化注解、销毁注解在子类 CommonAnnotationBeanPostProcessor 中有指定:
setInitAnnotationType(PostConstruct.class);
setDestroyAnnotationType(PreDestroy.class);
InitDestroyAnnotationBeanPostProcessor 就是收集标注了 @PostConstruct 和 @PreDestroy 注解的后置处理器。
CommonAnnotationBeanPostProcessor
CommonAnnotationBeanPostProcessor是InitDestroyAnnotationBeanPostProcessor 的子类。
public void postProcessMergedBeanDefinition(RootBeanDefinition beanDefinition, Class<?> beanType, String beanName) {
// 调用InitDestroyAnnotationBeanPostProcessor
super.postProcessMergedBeanDefinition(beanDefinition, beanType, beanName);
// 收集注入相关的信息
InjectionMetadata metadata = findResourceMetadata(beanName, beanType, null);
metadata.checkConfigMembers(beanDefinition);
}
了调用父类 InitDestroyAnnotationBeanPostProcessor 的收集动作之外,它在这里还要收集有关注入的注解信息。与上面的 findLifecycleMetadata 方法类似。
do {
final List<InjectionMetadata.InjectedElement> currElements = new ArrayList<>();
ReflectionUtils.doWithLocalFields(targetClass, field -> {
if (webServiceRefClass != null && field.isAnnotationPresent(webServiceRefClass)) {
if (Modifier.isStatic(field.getModifiers())) {
throw new IllegalStateException("@WebServiceRef annotation is not supported on static fields");
}
currElements.add(new WebServiceRefElement(field, field, null));
}
else if (ejbClass != null && field.isAnnotationPresent(ejbClass)) {
if (Modifier.isStatic(field.getModifiers())) {
throw new IllegalStateException("@EJB annotation is not supported on static fields");
}
currElements.add(new EjbRefElement(field, field, null));
}
else if (field.isAnnotationPresent(Resource.class)) {
if (Modifier.isStatic(field.getModifiers())) {
throw new IllegalStateException("@Resource annotation is not supported on static fields");
}
if (!this.ignoredResourceTypes.contains(field.getType().getName())) {
currElements.add(new ResourceElement(field, field, null));
}
}
});
它还能支持 JAVA EE 规范中的 @WebServiceRef 、@EJB 、@Resource 注解,并封装对应的注解信息。
AutowiredAnnotationBeanPostProcessor
它应该是收集自动注入的注解信息的。底层的原理与前两者的逻辑设计一模一样。,这里重点说一下它支持的注解。
public AutowiredAnnotationBeanPostProcessor() {
this.autowiredAnnotationTypes.add(Autowired.class);
this.autowiredAnnotationTypes.add(Value.class);
try {
this.autowiredAnnotationTypes.add((Class<? extends Annotation>)
ClassUtils.forName("javax.inject.Inject", AutowiredAnnotationBeanPostProcessor.class.getClassLoader()));
}
AutowiredAnnotationBeanPostProcessor 在构造方法中,就已经指定好它默认支持 @Autowired 注解、@Value 注解,如果 classpath 下有来自 JSR 330 的 @Inject 注解,也会一并支持。
注解后置处理器小结
从这几个后置处理器中,我们就可以发现,可以支持 bean 中标注的注解的后置处理器,它们的处理方式都是先收集注解标注的信息,保存到缓存中,随后再处理时,只需要从缓存中取就可以了。
早期bean对象引用的获取与缓存
// ......
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
// logger ......
// 处理循环依赖的问题
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
// ......
//DefaultSingletonBeanRegistry#addSingletonFactory
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized(this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
this.singletonFactories.put(beanName, singletonFactory);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}
这里有一个获取早期 bean 对象引用的动作,这一步是为了解决 bean 之间的循环依赖问题。
目前,bean 被实例化出来之后还没有进行属性赋值和组件的依赖注入。但此时的 bean 对象已经实实在在的存在了。如果在此期间,有另外的 bean 又需要创建它时,就不应该再创建同样的一个 bean 对象,而是直接拿到该引用即可,这个设计就是为了解决 bean 之间的循环依赖而用。
populateBean - 属性赋值+依赖注入
接下来的两步是挨着的:
// ......
// Initialize the bean instance.
Object exposedObject = bean;
try {
populateBean(beanName, mbd, instanceWrapper);
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
// ......
populateBean
检查bean&准备
protected void populateBean(String beanName, RootBeanDefinition mbd, @Nullable BeanWrapper bw) {
if (bw == null) {
if (mbd.hasPropertyValues()) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Cannot apply property values to null instance");
}
else {
// Skip property population phase for null instance.
return;
}
}
// ......
这个地方仅仅是为了检查 BeanWrapper 中是否存在而已
InstantiationAwareBeanPostProcessor
// ......
// Give any InstantiationAwareBeanPostProcessors the opportunity to modify the
// state of the bean before properties are set. This can be used, for example,
// to support styles of field injection.
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
if (!ibp.postProcessAfterInstantiation(bw.getWrappedInstance(), beanName)) {
return;
}
}
}
}
// ......
合着 postProcessAfterInstantiation 方法也是干预 bean 的属性等东西的呀。而且有一个小细节注意一下,postProcessAfterInstantiation 方法返回的是 boolean 类型,当 postProcessAfterInstantiation 返回 false 时,会直接 return 出去,不再执行下面的属性赋值 + 组件依赖注入的逻辑!
那这个回调有什么可以利用的吗?
当 bean 的创建来到这个位置的时候,此时 bean 的状态如何?还是所有属性都为空吧,而且还都没有执行任何初始化的逻辑吧。所以这个回调的位置,就是让咱在 bean 已经初始化好,但还没有开始属性赋值和依赖注入时切入自定义逻辑。
自动注入支持
// ......
PropertyValues pvs = (mbd.hasPropertyValues() ? mbd.getPropertyValues() : null);
// 解析出当前bean支持的自动注入模式
int resolvedAutowireMode = mbd.getResolvedAutowireMode();
if (resolvedAutowireMode == AUTOWIRE_BY_NAME || resolvedAutowireMode == AUTOWIRE_BY_TYPE) {
MutablePropertyValues newPvs = new MutablePropertyValues(pvs);
// Add property values based on autowire by name if applicable.
if (resolvedAutowireMode == AUTOWIRE_BY_NAME) {
autowireByName(beanName, mbd, bw, newPvs);
}
// Add property values based on autowire by type if applicable.
if (resolvedAutowireMode == AUTOWIRE_BY_TYPE) {
autowireByType(beanName, mbd, bw, newPvs);
}
pvs = newPvs;
}
// ......
这一部分的逻辑是支撑 “自动注入模式” 功能的。
在上面先把当前正在创建的 bean 的自动注入模式解析出来,之后根据自动注入模式,执行对应的逻辑。我们看看byName的逻辑实现:
protected void autowireByName(
String beanName, AbstractBeanDefinition mbd, BeanWrapper bw, MutablePropertyValues pvs) {
String[] propertyNames = unsatisfiedNonSimpleProperties(mbd, bw);
for (String propertyName : propertyNames) {
// 存在bean,就获取出来,添加依赖关系
if (containsBean(propertyName)) {
Object bean = getBean(propertyName);
pvs.add(propertyName, bean);
registerDependentBean(propertyName, beanName);
}
}
}
逻辑是相当的简单吧!就仅仅是查出来,添加上依赖关系,就完事了。
另外留意一点!在这段代码执行完毕后,有 pvs = newPvs; 的步骤,它将这个过程中需要组件依赖注入的信息也都封装进了 PropertyValues 中了,所以此时 pvs 中就应该有一开始封装的信息,以及通过自动注入封装好的依赖信息。
又回调InstantiationAwareBeanPostProcessor
// ......
boolean hasInstAwareBpps = hasInstantiationAwareBeanPostProcessors();
boolean needsDepCheck = (mbd.getDependencyCheck() != AbstractBeanDefinition.DEPENDENCY_CHECK_NONE);
PropertyDescriptor[] filteredPds = null;
if (hasInstAwareBpps) {
if (pvs == null) {
pvs = mbd.getPropertyValues();
}
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
// 【核心】回调postProcessProperties
PropertyValues pvsToUse = ibp.postProcessProperties(pvs, bw.getWrappedInstance(), beanName);
if (pvsToUse == null) {
if (filteredPds == null) {
filteredPds = filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching);
}
pvsToUse = ibp.postProcessPropertyValues(pvs, filteredPds, bw.getWrappedInstance(), beanName);
if (pvsToUse == null) {
return;
}
}
pvs = pvsToUse;
}
}
}
// ......
这一段源码又在取那些 InstantiationAwareBeanPostProcessor 了,不过注意这次回调的方法是 postProcessProperties 和 postProcessPropertyValues 方法了( postProcessPropertyValues 方法在 SpringFramework 5.1 之后被废弃了)。
注意 postProcessProperties 方法会传入 PropertyValues ,也会返回 PropertyValues ,所以这个过程相当于反复给 PropertyValues 封装数据。
这个时机的回调是属性赋值和组件依赖注入的核心时机,所以我们需要关注这里面一个非常重要的后置处理器:AutowiredAnnotationBeanPostProcessor 。
AutowiredAnnotationBeanPostProcessor#postProcessProperties
public PropertyValues postProcessProperties(PropertyValues pvs, Object bean, String beanName) {
InjectionMetadata metadata = findAutowiringMetadata(beanName, bean.getClass(), pvs);
try {
metadata.inject(bean, beanName, pvs);
} // catch ......
return pvs;
}
它收集所有标注了 @Autowired 、@Value、@Inject 注解的信息,返回回来。不过这里不只是收集了,它要真正的给 bean 对象的属性赋值!
之前的问题:
在 BeanFactoryPostProcessor 或者 BeanDefinitionRegistryPostProcessor 中无法直接使用 @Autowired 直接注入 SpringFramework 中的内部组件(如 Environment )?
当 BeanDefinitionRegistryPostProcessor 在初始化的阶段,还不存在 BeanPostProcessor 呢,所以那些用于支持依赖注入的后置处理器( AutowiredAnnotationBeanPostProcessor )还没有被初始化,自然也就没办法支持注入了。正确的做法是借助 Aware 接口的回调注入。
metadata.inject
public void inject(Object target, @Nullable String beanName, @Nullable PropertyValues pvs) throws Throwable {
Collection<InjectedElement> checkedElements = this.checkedElements;
// 收集所有要注入的信息
Collection<InjectedElement> elementsToIterate =
(checkedElements != null ? checkedElements : this.injectedElements);
if (!elementsToIterate.isEmpty()) {
// 迭代,依次注入
for (InjectedElement element : elementsToIterate) {
// logger ......
element.inject(target, beanName, pvs);
}
}
}
整体逻辑还是非常简单的哈,给一个 bean 进行注入,就相当于给这个 bean 中需要注入的元素依次注入。
protected void inject(Object target, @Nullable String requestingBeanName, @Nullable PropertyValues pvs)
throws Throwable {
if (this.isField) {
// 反射注入字段
Field field = (Field) this.member;
ReflectionUtils.makeAccessible(field);
field.set(target, getResourceToInject(target, requestingBeanName));
}
else {
if (checkPropertySkipping(pvs)) {
return;
}
try {
// 反射调用setter方法
Method method = (Method) this.member;
ReflectionUtils.makeAccessible(method);
method.invoke(target, getResourceToInject(target, requestingBeanName));
} // catch ......
}
}
属性赋值
// ......
if (needsDepCheck) {
if (filteredPds == null) {
filteredPds = filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching);
}
checkDependencies(beanName, mbd, filteredPds, pvs);
}
if (pvs != null) {
// 将PropertyValues应用给bean
applyPropertyValues(beanName, mbd, bw, pvs);
}
}
核心动作就只有 applyPropertyValues :
这个 applyPropertyValues 方法的作用,就是把前面准备好的 PropertyValues 对象封装的内容,应用到当前正在创建的 bean 实例上。
预检查和准备
protected void applyPropertyValues(String beanName, BeanDefinition mbd, BeanWrapper bw, PropertyValues pvs) {
if (pvs.isEmpty()) {
return;
}
if (System.getSecurityManager() != null && bw instanceof BeanWrapperImpl) {
((BeanWrapperImpl) bw).setSecurityContext(getAccessControlContext());
}
MutablePropertyValues mpvs = null;
List<PropertyValue> original;
// ......
这段很简单啦,如果直接没有要应用的 bean 属性,则直接返回就好,否则它就要准备处理 PropertyValues 了。
重复解析的提前返回
if (pvs instanceof MutablePropertyValues) {
mpvs = (MutablePropertyValues) pvs;
// 判断PropertyValues是否已经解析过了
if (mpvs.isConverted()) {
try {
bw.setPropertyValues(mpvs);
return;
} // catch ......
}
original = mpvs.getPropertyValueList();
}
else {
original = Arrays.asList(pvs.getPropertyValues());
}
// ......
if (mpvs.isConverted()) 的动作很明显是检查 PropertyValues 是否已经解析过了,如果已经解析过,则直接应用就行,不需要重复解析。
初始化BeanDefinitionValueResolver
// ......
TypeConverter converter = getCustomTypeConverter();
if (converter == null) {
converter = bw;
}
BeanDefinitionValueResolver valueResolver = new BeanDefinitionValueResolver(this, beanName, mbd, converter);
// ......
BeanDefinitionValueResolver 很重要。BeanDefinitionValueResolver 的初始化需要传入一个 TypeConverter ,而这个 TypeConverter 是 SpringFramework 中内部用于类型转换的核心 API 。
简单的来说,使用 TypeConverter 可以将一个 String 类型的数据,转换为特定的所需要的类型的数据。
BeanDefinitionValueResolver 就利用 TypeConverter,完成对 bean 实例中需要注入的属性值进行解析,并适配为 bean 属性所需要的类型(如 String → int ,依赖 bean 的名称转为实际 bean 的引用)。
类型转换
// ......
// Create a deep copy, resolving any references for values.
List<PropertyValue> deepCopy = new ArrayList<>(original.size());
boolean resolveNecessary = false;
// 迭代逐个解析PropertyValue
for (PropertyValue pv : original) {
// 已经解析过的直接添加
if (pv.isConverted()) {
deepCopy.add(pv);
}
else {
String propertyName = pv.getName();
// 此处取出的值是未经过转换的原始value
Object originalValue = pv.getValue();
// 此处是 5.2 的一个扩展,如果编程式使用BeanDefinitionBuilder添加自动注入的属性时,
// 会使用类似于自动注入支持的方式处理该属性
if (originalValue == AutowiredPropertyMarker.INSTANCE) {
Method writeMethod = bw.getPropertyDescriptor(propertyName).getWriteMethod();
if (writeMethod == null) {
throw new IllegalArgumentException("Autowire marker for property without write method: " + pv);
}
originalValue = new DependencyDescriptor(new MethodParameter(writeMethod, 0), true);
}
// 根据originalValue的类型,解析出bean依赖的属性值
// 此处如果是bean的名称,则最终解析出来的是真正的bean对象
Object resolvedValue = valueResolver.resolveValueIfNecessary(pv, originalValue);
Object convertedValue = resolvedValue;
boolean convertible = bw.isWritableProperty(propertyName) &&
!PropertyAccessorUtils.isNestedOrIndexedProperty(propertyName);
if (convertible) {
convertedValue = convertForProperty(resolvedValue, propertyName, bw, converter);
}
// 此处要对解析前和解析后的数据进行对比
// 如果解析之前与解析之后的值完全一致,则代表不需要解析,或已经解析过了,直接保存
if (resolvedValue == originalValue) {
if (convertible) {
pv.setConvertedValue(convertedValue);
}
deepCopy.add(pv);
}
// 如果String类型转为其他类型(除了集合或数组),则认为它也不需要再解析了
else if (convertible && originalValue instanceof TypedStringValue &&
!((TypedStringValue) originalValue).isDynamic() &&
!(convertedValue instanceof Collection || ObjectUtils.isArray(convertedValue))) {
pv.setConvertedValue(convertedValue);
deepCopy.add(pv);
}
// 否则,该字段认定为每次都需要重新解析
else {
resolveNecessary = true;
deepCopy.add(new PropertyValue(pv, convertedValue));
}
}
}
// 如果所有字段都解析完毕,则当前PropertyValues可以标记为已经解析完成,后续不需要重复解析
if (mpvs != null && !resolveNecessary) {
mpvs.setConverted();
}
// ......
PropertyValues应用到bean
// ......
// Set our (possibly massaged) deep copy.
try {
bw.setPropertyValues(new MutablePropertyValues(deepCopy));
}
catch (BeansException ex) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Error setting property values", ex);
}
}
最后一个步骤,这里要把 PropertyValues 中的属性值全部应用到 bean 对象中了。
这一部分来回调的源码比较多,最终的落地在 :org.springframework.beans.AbstractNestablePropertyAccessor.PropertyHandler#setValue 中,它的其中一个实现类 FieldPropertyHandler 的方法实现如下:
public void setValue(@Nullable Object value) throws Exception {
try {
ReflectionUtils.makeAccessible(this.field);
this.field.set(getWrappedInstance(), value);
}
// catch ......
}

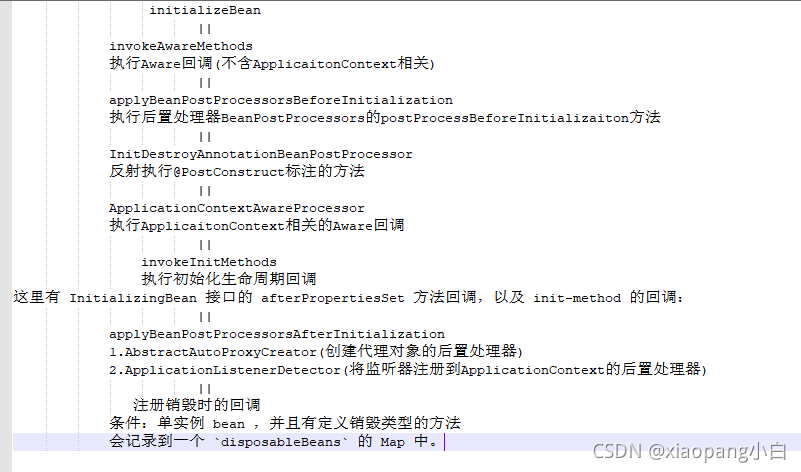
initializeBean
当 bean 的创建过程走到 initializeBean 方法时,此时 bean 中的属性都是齐全的了,但生命周期的回调都还没有回调,接下来我们研究这个部分。
四个步骤:
1.执行Aware回调
2.执行BeanPostProcessor的前置回调
3.执行生命周期回调
4.执行BeanPostProcessor的后置回调
protected Object initializeBean(String beanName, Object bean, @Nullable RootBeanDefinition mbd) {
if (System.getSecurityManager() != null) {
// ......
}
else {
// 1.4.1 执行Aware回调
invokeAwareMethods(beanName, bean);
}
Object wrappedBean = bean;
// 1.4.2 执行BeanPostProcessor的前置回调
if (mbd == null || !mbd.isSynthetic()) {
wrappedBean = applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
}
try {
// 1.4.3 执行生命周期回调
invokeInitMethods(beanName, wrappedBean, mbd);
}
// catch ......
// 1.4.4 执行BeanPostProcessor的后置回调
if (mbd == null || !mbd.isSynthetic()) {
wrappedBean = applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);
}
return wrappedBean;
}
invokeAwareMethods - 执行Aware回调
invokeAwareMethods(beanName, bean); 这个方法中的定义相当简单,只是判断接口的定义,以及强转后的接口方法调用而已,非常容易理解:
private void invokeAwareMethods(String beanName, Object bean) {
if (bean instanceof Aware) {
// 如果bean实现了BeanNameAware,则强转后调用setBeanName方法注入bean的名称
if (bean instanceof BeanNameAware) {
((BeanNameAware) bean).setBeanName(beanName);
}
// 如果bean实现了BeanClassLoaderAware,则强转后调用setBeanClassLoader方法注入当前的ClassLoader
if (bean instanceof BeanClassLoaderAware) {
ClassLoader bcl = getBeanClassLoader();
if (bcl != null) {
((BeanClassLoaderAware) bean).setBeanClassLoader(bcl);
}
}
// 如果bean实现了BeanFactoryAware,则强转后调用setBeanFactory方法注入BeanFactory
if (bean instanceof BeanFactoryAware) {
((BeanFactoryAware) bean).setBeanFactory(AbstractAutowireCapableBeanFactory.this);
}
}
}
不过这里面有一个问题:
有关 ApplicationContext 部分的处理,怎么一个也没有咧?
接着下面处理。
applyBeanPostProcessorsBeforeInitialization
public Object applyBeanPostProcessorsBeforeInitialization(Object existingBean, String beanName)
throws BeansException {
Object result = existingBean;
for (BeanPostProcessor processor : getBeanPostProcessors()) {
Object current = processor.postProcessBeforeInitialization(result, beanName);
// 此处做了一个分支控制:如果处理完的结果返回null,则认为停止BeanPostProcessor的处理,返回bean对象
if (current == null) {
return result;
}
result = current;
}
return result;
}
它会依次执行容器中所有 BeanPostProcessor 的 postProcessBeforeInitialization 方法。不过这里有一个分支控制处理:如果处理完的结果返回 null ,则不再执行后面剩余的 BeanPostProcessor ,直接返回上一个 BeanPostProcessor 处理之后的 bean 对象返回。由此我们可以在此处针对自己项目中某些特定的 bean 搞一些特殊的拦截的处理。
InitDestroyAnnotationBeanPostProcessor
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
LifecycleMetadata metadata = findLifecycleMetadata(bean.getClass());
try {
metadata.invokeInitMethods(bean, beanName);
}
// catch ......
return bean;
}
@PostConstruct 和 @PreDestroy 注解的方法都取出来,所以这里就相当于回调 @PostConstruct 标注的方法了!
public void invokeInitMethods(Object target, String beanName) throws Throwable {
Collection<LifecycleElement> checkedInitMethods = this.checkedInitMethods;
Collection<LifecycleElement> initMethodsToIterate =
(checkedInitMethods != null ? checkedInitMethods : this.initMethods);
if (!initMethodsToIterate.isEmpty()) {
for (LifecycleElement element : initMethodsToIterate) {
// logger ......
element.invoke(target);
}
}
}
public void invoke(Object target) throws Throwable {
ReflectionUtils.makeAccessible(this.method);
this.method.invoke(target, (Object[]) null);
}
反射调用@PostConstruct 标注的方法执行。
ApplicationContextAwareProcessor
执行ApplicationContext相关的Aware回调。
由此我们可以先得出一个结论:BeanFactory 的注入时机比 ApplicationContext 早。
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
if (!(bean instanceof EnvironmentAware || bean instanceof EmbeddedValueResolverAware ||
bean instanceof ResourceLoaderAware || bean instanceof ApplicationEventPublisherAware ||
bean instanceof MessageSourceAware || bean instanceof ApplicationContextAware)){
return bean;
}
// ......
else {
invokeAwareInterfaces(bean);
}
return bean;
}
invokeInitMethods - 执行初始化生命周期回调
这里有 InitializingBean 接口的 afterPropertiesSet 方法回调,以及 init-method 的回调:
protected void invokeInitMethods(String beanName, Object bean, @Nullable RootBeanDefinition mbd)
throws Throwable {
boolean isInitializingBean = (bean instanceof InitializingBean);
if (isInitializingBean && (mbd == null || !mbd.isExternallyManagedInitMethod("afterPropertiesSet"))) {
// ......
else {
// 回调InitializingBean的afterPropertiesSet方法
((InitializingBean) bean).afterPropertiesSet();
}
}
if (mbd != null && bean.getClass() != NullBean.class) {
String initMethodName = mbd.getInitMethodName();
if (StringUtils.hasLength(initMethodName) &&
!(isInitializingBean && "afterPropertiesSet".equals(initMethodName)) &&
!mbd.isExternallyManagedInitMethod(initMethodName)) {
// 回调init-method方法(同样是反射调用)
invokeCustomInitMethod(beanName, bean, mbd);
}
}
}
applyBeanPostProcessorsAfterInitialization
执行BeanPostProcessors的PostProcessorsAfterInitialization方法。
public Object applyBeanPostProcessorsAfterInitialization(Object existingBean, String beanName)
throws BeansException {
Object result = existingBean;
for (BeanPostProcessor processor : getBeanPostProcessors()) {
Object current = processor.postProcessAfterInitialization(result, beanName);
if (current == null) {
return result;
}
result = current;
}
return result;
}
以下为几个重要的后置处理器:
AbstractAutoProxyCreator
public Object postProcessAfterInitialization(@Nullable Object bean, String beanName) {
if (bean != null) {
Object cacheKey = getCacheKey(bean.getClass(), beanName);
if (this.earlyProxyReferences.remove(cacheKey) != bean) {
// 创建代理对象
return wrapIfNecessary(bean, beanName, cacheKey);
}
}
return bean;
}
这就是之前我们在学习 BeanPostProcessor 中一直提到的创建代理的核心处理器了,它也是 AOP 创建代理对象的核心实现。
ApplicationListenerDetector
public Object postProcessAfterInitialization(Object bean, String beanName) {
if (bean instanceof ApplicationListener) {
Boolean flag = this.singletonNames.get(beanName);
if (Boolean.TRUE.equals(flag)) {
this.applicationContext.addApplicationListener((ApplicationListener<?>) bean);
}
// 异常分支处理 ......
}
return bean;
}
它用来关联所有的监听器引用。同样的,监听器在创建的时候,也需要 ApplicationListenerDetector 把这些监听器挂进 ApplicationContext 中,这样这些监听器才可以被事件广播器使用。
注册销毁时的回调
如果一个 bean 定义的 class 有实现 DisposableBean 接口,或者声明了 @PreDestroy 注解,或者声明了 destroy-method 方法,则会在 doCreateBean 方法的最后一步,注册一个销毁 bean 的回调钩子:
// doCreateBean 最后 ......
// Register bean as disposable.
try {
registerDisposableBeanIfNecessary(beanName, bean, mbd);
}
// catch ......
return exposedObject;
}
进入 registerDisposableBeanIfNecessary 方法:
protected void registerDisposableBeanIfNecessary(String beanName, Object bean, RootBeanDefinition mbd) {
AccessControlContext acc = (System.getSecurityManager() != null ? getAccessControlContext() : null);
// 不是原型bean,且有定义销毁类型的方法
if (!mbd.isPrototype() && requiresDestruction(bean, mbd)) {
if (mbd.isSingleton()) {
registerDisposableBean(beanName,
new DisposableBeanAdapter(bean, beanName, mbd, getBeanPostProcessors(), acc));
}
// 处理特殊的scope ......
}
}
通常情况下可以记录销毁 bean 的回调钩子的原则是:单实例 bean ,并且有定义销毁类型的方法。
对于这些定义了销毁类型的方法的 bean ,会记录到一个 disposableBeans 的 Map 中:
private final Map<String, Object> disposableBeans = new LinkedHashMap<>();
public void registerDisposableBean(String beanName, DisposableBean bean) {
synchronized (this.disposableBeans) {
this.disposableBeans.put(beanName, bean);
}
}
到这里,doCreateBean 方法全部执行完毕,一个 bean 已经被成功的创建出来了。
SmartInitializingSingleton
else {
// 普通的初始化,就是getBean方法
getBean(beanName);
}
}
}
// 初始化的最后阶段 ......
}
这个初始化的最后阶段,是在 SpringFramework 4.1 之后才有的,而支撑这个阶段的核心接口是 SmartInitializingSingleton 。
else {
getBean(beanName);
}
}
}
// Trigger post-initialization callback for all applicable beans...
for (String beanName : beanNames) {
Object singletonInstance = getSingleton(beanName);
if (singletonInstance instanceof SmartInitializingSingleton) {
SmartInitializingSingleton smartSingleton = (SmartInitializingSingleton) singletonInstance;
// ......
else {
smartSingleton.afterSingletonsInstantiated();
}
}
}
}
SmartInitializingSingleton 的回调时机,是所有的非延迟加载的单实例 bean 都初始化完成后,再挨个执行 afterSingletonsInstantiated 方法,调用的方式非常简单,逐个判断就完事了。
Lifecycle的回调
在 ApplicationContext 的 refresh 方法最后,初始化完成所有非延迟加载的单实例 bean 之后,会执行 finishRefresh 方法:
protected void finishRefresh() {
// Clear context-level resource caches (such as ASM metadata from scanning).
// 清除上下文级别的资源缓存
clearResourceCaches();
// Initialize lifecycle processor for this context.
// 为当前ApplicationContext初始化一个生命周期处理器
initLifecycleProcessor();
// Propagate refresh to lifecycle processor first.
// 将refresh的动作传播到生命周期处理器
getLifecycleProcessor().onRefresh();
// Publish the final event.
// 广播事件
publishEvent(new ContextRefreshedEvent(this));
// Participate in LiveBeansView MBean, if active.
LiveBeansView.registerApplicationContext(this);
}
这里面的处理逻辑还是很有序的,首先把该读取的一些资源缓存都清除掉,然后它初始化了一个生命周期处理器,随后调用它的 onRefresh 方法,接下来广播 ContextRefreshedEvent 事件。而回调 Lifecycle 接口的动作,就发生在这个生命周期处理器中。
initLifecycleProcessor
protected void initLifecycleProcessor() {
ConfigurableListableBeanFactory beanFactory = getBeanFactory();
if (beanFactory.containsLocalBean(LIFECYCLE_PROCESSOR_BEAN_NAME)) {
this.lifecycleProcessor =
beanFactory.getBean(LIFECYCLE_PROCESSOR_BEAN_NAME, LifecycleProcessor.class);
// logger ......
}
else {
DefaultLifecycleProcessor defaultProcessor = new DefaultLifecycleProcessor();
defaultProcessor.setBeanFactory(beanFactory);
this.lifecycleProcessor = defaultProcessor;
beanFactory.registerSingleton(LIFECYCLE_PROCESSOR_BEAN_NAME, this.lifecycleProcessor);
// logger ......
}
}
无论 BeanFactory 中有没有 LifecycleProcessor ,它都会保证最终容器中会有,注意它的实现类是 DefaultLifecycleProcessor ,我们下面会进入它的内部实现。
onRefresh
public void onRefresh() {
startBeans(true);
this.running = true;
}
DefaultLifecycleProcessor 的 onRefresh 方法非常简单,就是启动 bean 。继续往下进到源码中:
private void startBeans(boolean autoStartupOnly) {
Map<String, Lifecycle> lifecycleBeans = getLifecycleBeans();
Map<Integer, LifecycleGroup> phases = new HashMap<>();
lifecycleBeans.forEach((beanName, bean) -> {
// 注意此处,如果autoStartupOnly为true,则不会执行
if (!autoStartupOnly || (bean instanceof SmartLifecycle && ((SmartLifecycle) bean).isAutoStartup())) {
int phase = getPhase(bean);
LifecycleGroup group = phases.get(phase);
if (group == null) {
group = new LifecycleGroup(phase, this.timeoutPerShutdownPhase, lifecycleBeans, autoStartupOnly);
phases.put(phase, group);
}
group.add(beanName, bean);
}
});
if (!phases.isEmpty()) {
List<Integer> keys = new ArrayList<>(phases.keySet());
Collections.sort(keys);
for (Integer key : keys) {
// 依次调用Lifecycle的start方法
phases.get(key).start();
}
}
}
这里面就是一个一个调用 Lifecycle 的 start 方法的位置了,但请小伙伴们注意一点:由于 onRefresh 方法中调用的 startBeans(true); 传入的参数是 true ,lifecycleBeans.forEach 部分不会执行,所以在该阶段不会回调 Lifecycle 的 start 方法!
ApplicationContext#start
那这些 Lifecycle 的 start 方法什么时候才能被调用呢?
我们回到测试代码中:
ctx.refresh();
System.out.println("================IOC容器刷新完毕==================");
ctx.start();
// ---------AbstractApplicationContext----------
public void start() {
getLifecycleProcessor().start();
publishEvent(new ContextStartedEvent(this));
}
// ---------DefaultLifecycleProcessor-----------
public void start() {
startBeans(false);
this.running = true;
}
startBeans
private void startBeans(boolean autoStartupOnly) {
Map<String, Lifecycle> lifecycleBeans = getLifecycleBeans();
Map<Integer, LifecycleGroup> phases = new HashMap<>();
lifecycleBeans.forEach((beanName, bean) -> {
if (!autoStartupOnly || (bean instanceof SmartLifecycle && ((SmartLifecycle) bean).isAutoStartup())) {
// 此处的phase可类比Order
int phase = getPhase(bean);
LifecycleGroup group = phases.get(phase);
if (group == null) {
// 不同的phase分到不同的group中
group = new LifecycleGroup(phase, this.timeoutPerShutdownPhase, lifecycleBeans, autoStartupOnly);
phases.put(phase, group);
}
group.add(beanName, bean);
}
});
// ......
我们把 startBeans 方法分为两部分来看:
前半段的操作很明显是一个分组的动作。这里面的 phase 可以类比为 Order ,LifecycleGroup 可以简单的理解为 List<Lifecycle> 。所以这个过程很明显,就是将所有的 Lifecycle 按照不同的 phase 分组而已。
start
// ......
if (!phases.isEmpty()) {
List<Integer> keys = new ArrayList<>(phases.keySet());
Collections.sort(keys);
for (Integer key : keys) {
//
phases.get(key).start();
}
}
}
分组之后,它会根据不同的 phase 排序后依次执行,而执行的 start 方法看上去比较复杂,最终还是调用 Lifecycle 的 start 方法:
public void start() {
if (this.members.isEmpty()) {
return;
}
// logger ......
Collections.sort(this.members);
for (LifecycleGroupMember member : this.members) {
doStart(this.lifecycleBeans, member.name, this.autoStartupOnly);
}
}
private void doStart(Map<String, ? extends Lifecycle> lifecycleBeans, String beanName, boolean autoStartupOnly) {
Lifecycle bean = lifecycleBeans.remove(beanName);
if (bean != null && bean != this) {
String[] dependenciesForBean = getBeanFactory().getDependenciesForBean(beanName);
for (String dependency : dependenciesForBean) {
doStart(lifecycleBeans, dependency, autoStartupOnly);
}
if (!bean.isRunning() &&
(!autoStartupOnly || !(bean instanceof SmartLifecycle) || ((SmartLifecycle) bean).isAutoStartup())) {
// logger ......
try {
// 【调用实现了Lifecycle接口的bean】
bean.start();
}
// catch ......
}
}
}
等所有 Lifecycle 都执行完毕,一个 bean 的完整初始化生命周期也就结束了。
总结:
bean 对象创建完成后,会进行属性赋值、组件依赖注入,以及初始化阶段的方法回调。
在 populateBean 属性赋值阶段,会事先收集好 bean 中标注了依赖注入的注解( @Autowired 、@Value 、@Resource 、@Inject ),之后会借助后置处理器,回调 postProcessProperties 方法实现依赖注入。
属性赋值和依赖注入之后,会回调执行 bean 的初始化方法,以及后置处理器的逻辑:1.首先会执行 Aware 相关的回调注入,
2.之后执行后置处理器的前置回调,在后置处理器的前置方法中,会回调 bean 中标注了 @PostConstruct 注解的方法,所有的后置处理器前置回调后,会执行 InitializingBean 的 afterPropertiesSet 方法。
3.随后是 init-method 指定的方法,等这些 bean 的初始化方法都回调完毕后。
4.最后执行后置处理器的后置回调。
全部的 bean 初始化结束后,ApplicationContext 的 start 方法触发时,会触发实现了 Lifecycle 接口的 bean 的 start 方法。