谷粒商城–elasticsearch–高级篇笔记一
1.elasticsearch是什么?
Elasticsearch 是位于 Elastic Stack 核心的分布式搜索和分析引擎。Logstash 和 Beats 有助于收集、聚合和丰富您的数据并将其存储在 Elasticsearch 中。Kibana 使您能够以交互方式探索、可视化和共享对数据的洞察,并管理和监控堆栈。Elasticsearch 是索引、搜索和分析发生的地方。
Elasticsearch 为所有类型的数据提供近乎实时的搜索和分析。无论您拥有结构化或非结构化文本、数值数据还是地理空间数据,Elasticsearch 都可以以支持快速搜索的方式高效地存储和索引它。您可以超越简单的数据检索和聚合信息来发现数据中的趋势和模式。随着您的数据和查询量的增长,Elasticsearch 的分布式特性使您的部署能够随之无缝增长。
虽然并非所有问题都是搜索问题,但 Elasticsearch 提供了在各种用例中处理数据的速度和灵活性:
- 向应用或网站添加搜索框
- 存储和分析日志、指标和安全事件数据
- 使用机器学习实时自动建模数据的行为
- 使用 Elasticsearch 作为存储引擎自动化业务工作流
- 使用 Elasticsearch 作为地理信息系统 (GIS) 管理、集成和分析空间信息
- 使用 Elasticsearch 作为生物信息学研究工具存储和处理遗传数据
我们不断对人们使用搜索的新颖方式感到惊讶。但是,无论您的用例是否与其中之一类似,或者您正在使用 Elasticsearch 来解决新问题,您在 Elasticsearch 中处理数据、文档和索引的方式都是相同的。
2.简介
全文搜索属于最常见的需求, 开源的 Elasticsearch 是目前全文搜索引擎的首选。它可以快速地储存、 搜索和分析海量数据。 维基百科、 Stack Overflow、 Github 都采用它Elastic 的底层是开源库 Lucene。 但是, 你没法直接用 Lucene, 必须自己写代码去调用它的
接口。 Elastic 是 Lucene 的封装, 提供了 REST API 的操作接口, 开箱即用。
REST API: 天然的跨平台。
官方文档
3.基本概念
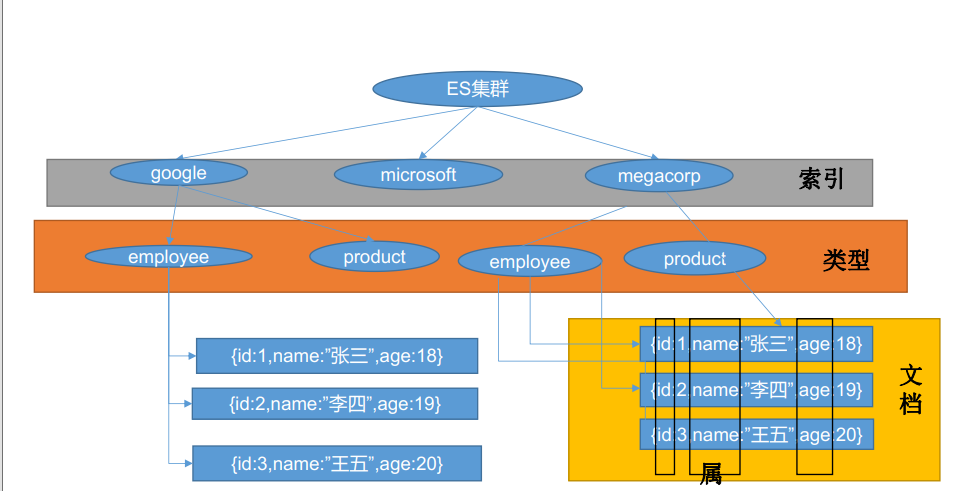
3.1 Index(索引)
- 动词,相当于MySQL中的insert.
- 名词,相当于MySQL中的Database.
3.2 Type (类型)
3.2.1 概念
在Index(索引)中,可以定义一个或多个类型,每种类型的数据放一起.
类似于MySQL中数据库中可以定义一个或多个表(Table);
3.2.2 ElasticSearch7-去掉type概念
Elasticsearch 7. X URL中的type参数为可选。比如,索引一个文档不再要求提供文档类型。
Elasticsearch 8.X 不再支持URL中的type参数。
原因
关系型数据库中两个数据表示是独立的,即使他们里面有相同名称的列也不影响使用,但ES中不是这样的。elasticsearch是基于Lucene开发的搜索引擎,而ES中不同type下名称相同的filed最终在Lucene中的处理方式是一样的。
- 两个不同type下的两个user_name,在ES同一个索引下其实被认为是同一个filed,你必须在两个不同的type中定义相同的filed映射。否则,不同type中的相同字段名称就会在处理中出现冲突的情况,导致Lucene处理效率下降。
- 去掉type就是为了提高ES处理数据的效率。
3.2.3 Elasticsearch 版本升级问题(升级到8)
解决:将索引从多类型迁移到单类型,每种类型文档一个独立索引
3.3 Document(文档)
保存到某个索引(Index)下,某种类型(Type)的一个数据(Document),文档是JSON格式的
一个Document就像是MySQL中某个表的一条记录.
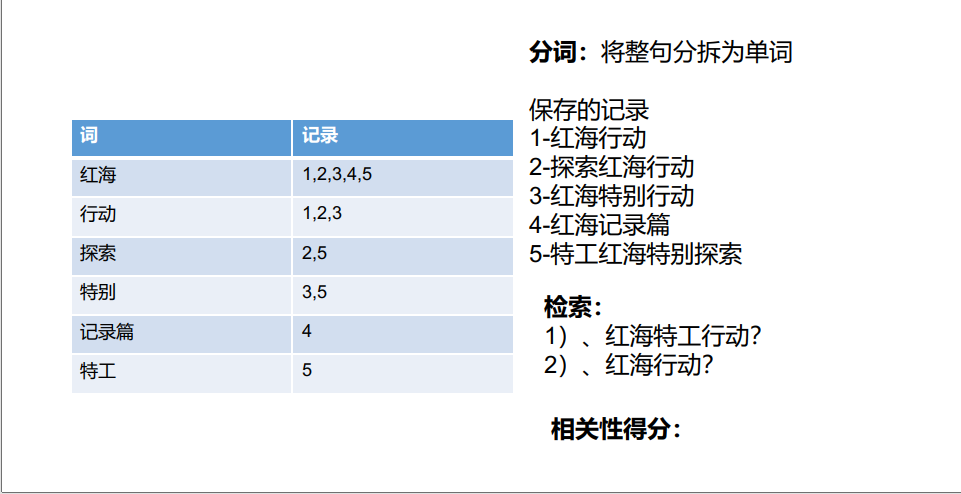
3.4 倒排索引
倒排索引:由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。
索引存储示例
将整句拆分为单词,将单词的值与索引存储起来,就可以根据单词查询索引位置,然后根据检索条件的相关性得分进行排序
4.Docker 安装ES 与 kibana
4.1下载镜像文件
elasticsearch与kibana版本是同步的
docker pull elasticsearch:7.4.2 #存储和检索数据
docker pull kibana:7.4.2 #可视化检索数据
4.2 创建实例
4.2.1创建ElasticSearch实例
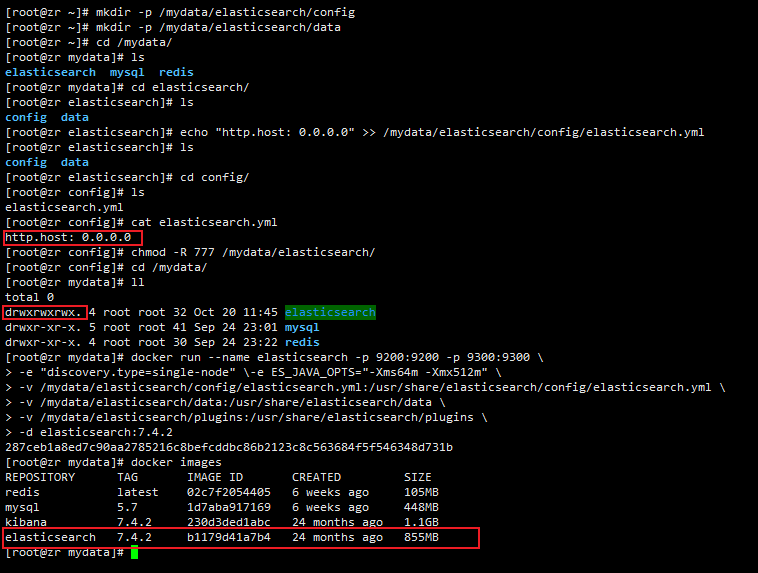
#先将es的数据与配置与需要映射的文件夹创建好
mkdir -p /mydata/elasticsearch/config
mkdir -p /mydata/elasticsearch/data
#配置es地址
echo "http.host: 0.0.0.0" >> /mydata/elasticsearch/config/elasticsearch.yml
#保证权限
chmod -R 777 /mydata/elasticsearch/
#创建并启动实例
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \-e ES_JAVA_OPTS="-Xms64m -Xmx512m" \
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
**特别注意:
-e ES_JAVA_OPTS="-Xms64m -Xmx256m" \ 测试环境下, 设置 ES 的初始内存和最大内存, 否则导
致过大启动不了 ES **
4.2.2关于ElasticSearch的9200和9300端口区别
9200作为Http协议,主要用于外部通讯
9300作为Tcp协议,jar之间就是通过tcp协议通讯 .ES集群之间是通过9300进行通讯
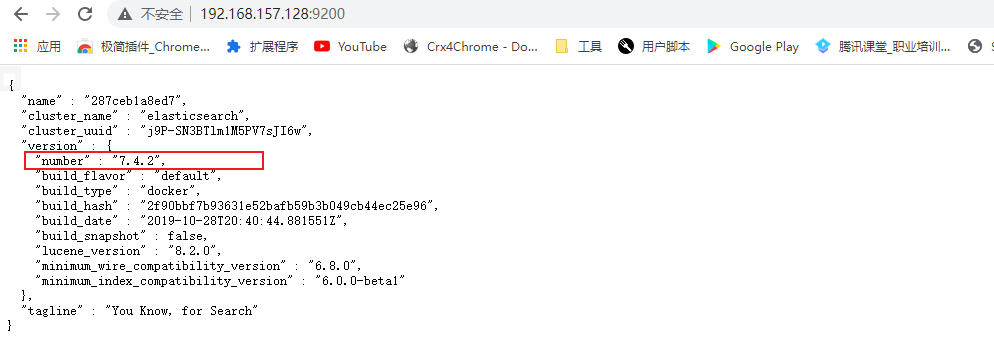
测试是否创建成功
192.168.157.128:9200 虚拟机地址+9200
4.2.3创建Kibana实例
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://192.168.157.128:9200 -p 5601:5601 \
-d kibana:7.4.2
测试是否创建成功
192.168.157.128:5601
4.3设置es与Kibana在docker启动时启动
#设置es在docker开启的时候启动
docker update elasticsearch --restart=always
#设置Kibana在docker开启的时候启动
docker update kibana --restart=always
重启docker发现es与Kibana仍然可以使用
5.初步检索
5.1_cat
- GET /_cat/nodes: 查看所有节点

- GET /_cat/health: 查看 es 健康状况

- GET /_cat/master: 查看主节点
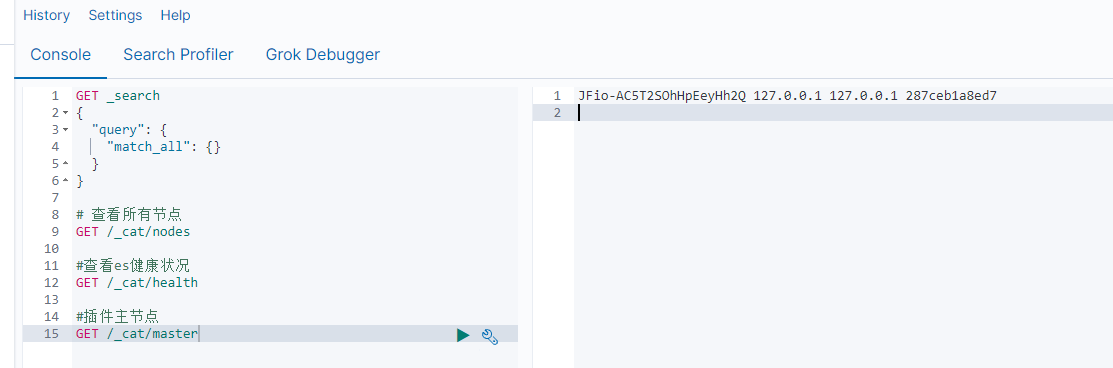
- GET /_cat/indices: 查看所有索引 show databases;
5.2索引(保存)一个文档
5.2.1 PUT方法(必须带id)
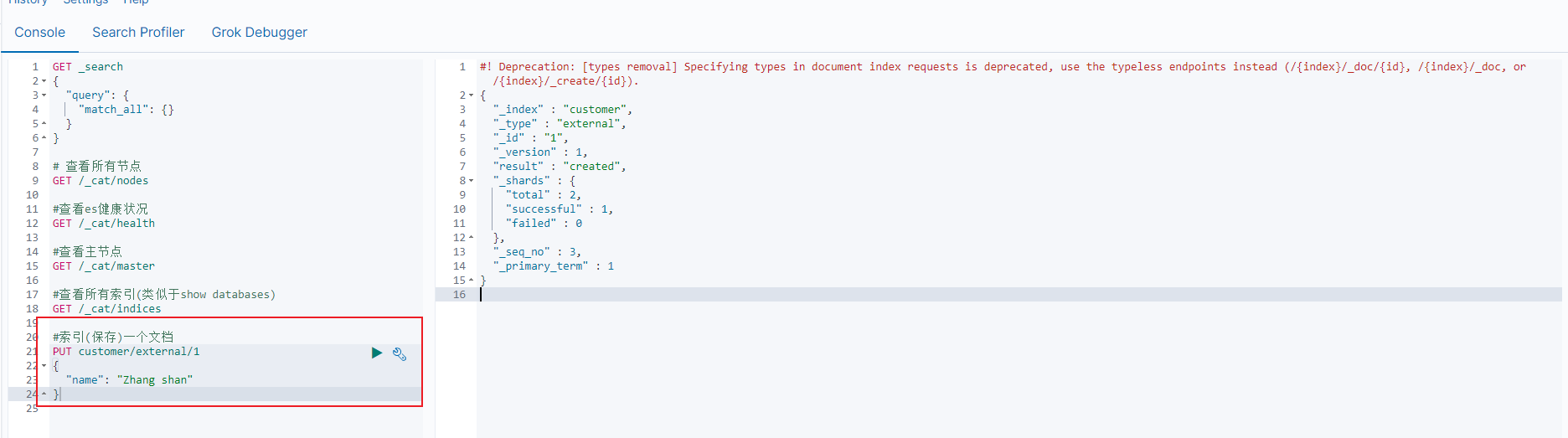
保存一个数据, 保存在哪个索引的哪个类型下, 指定用哪个唯一标识
#在 customer 索引下的 external 类型下保存 1 号数据
PUT customer/external/1
{
"name": "Zhang shan"
}
5.2.2POST方法(可以不带id)
#索引(保存)一个文档 (POST)
GET customer/external/2
{
"name":"Li Si"
}
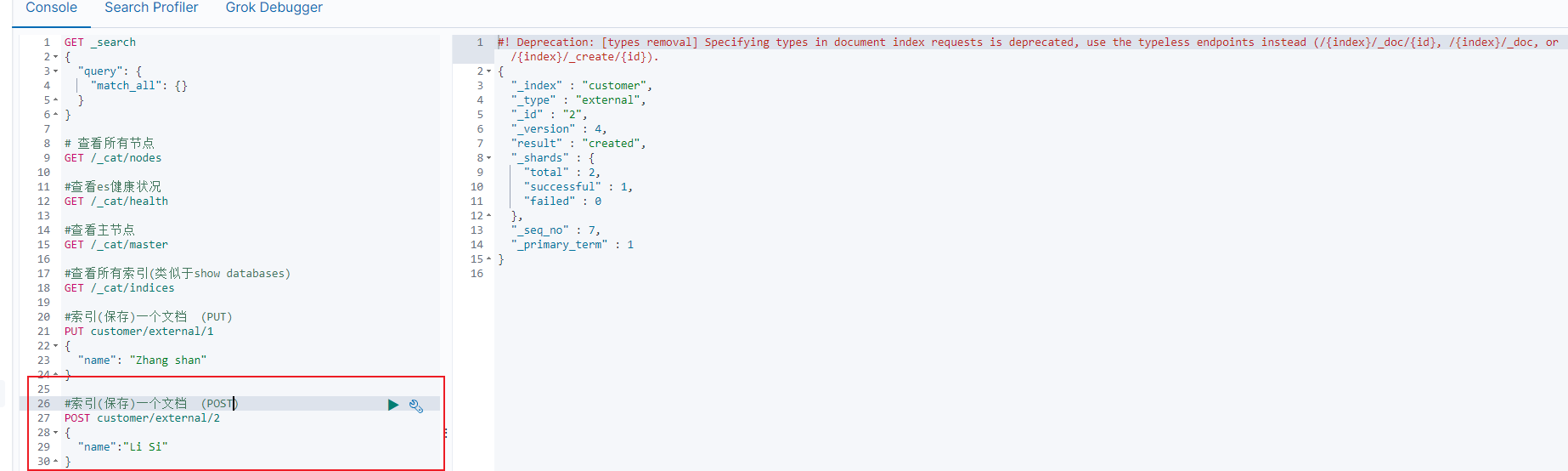
5.2.3使用GET方法与使用PUT方法索引(保存)文档的区别
个人理解:
PUT与POST都可以新增与修改文档
PUT与POST修改文档都是指定id再索引一次
POST新增可以不带id(自动生成),也可以自定义id
PUT新增只能自定义id,不能自动生成(PUT本就是设定用来修改的)
PUT 和 POST 都可以对文档进行新增,修改
POST 新增。 如果不指定 id, 会自动生成 id。 指定 id 就会修改这个数据, 并新增版本号.
- POST新增带id:如5.2.2
- POST新增不带id :id自动生成
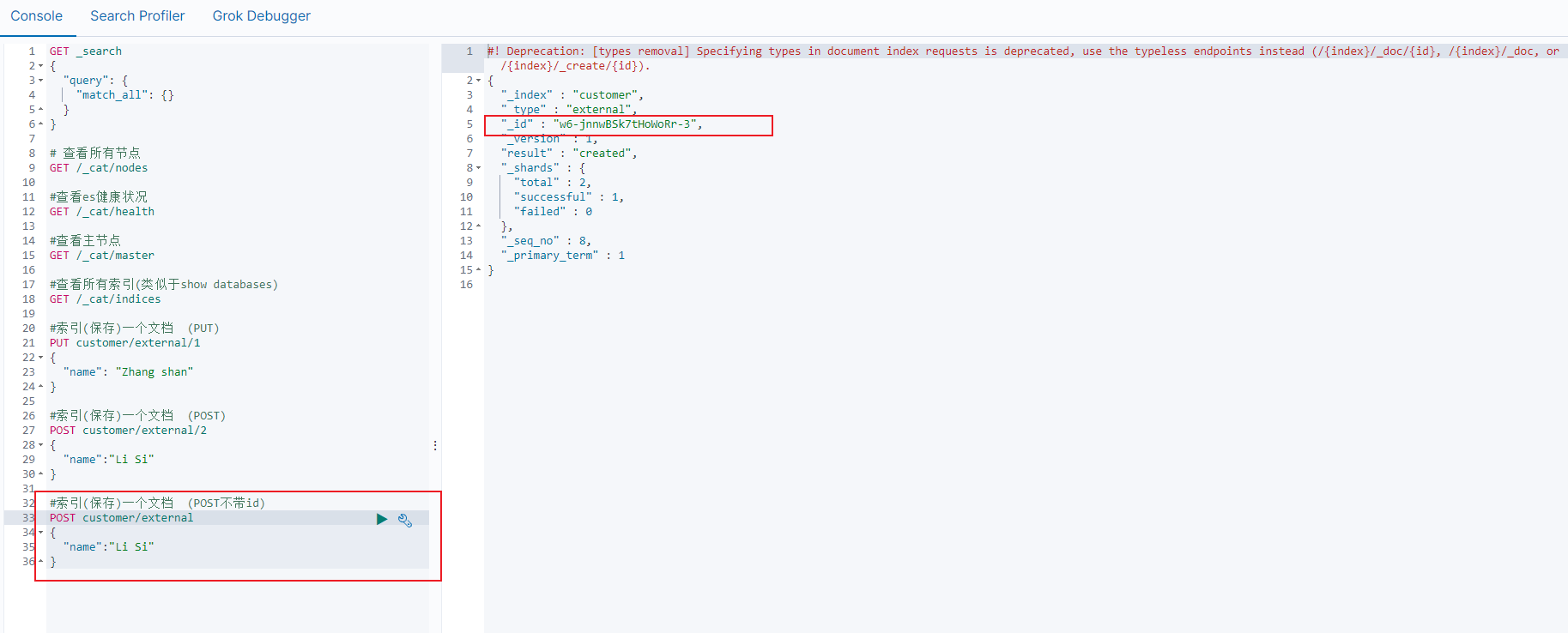
- POST 修改
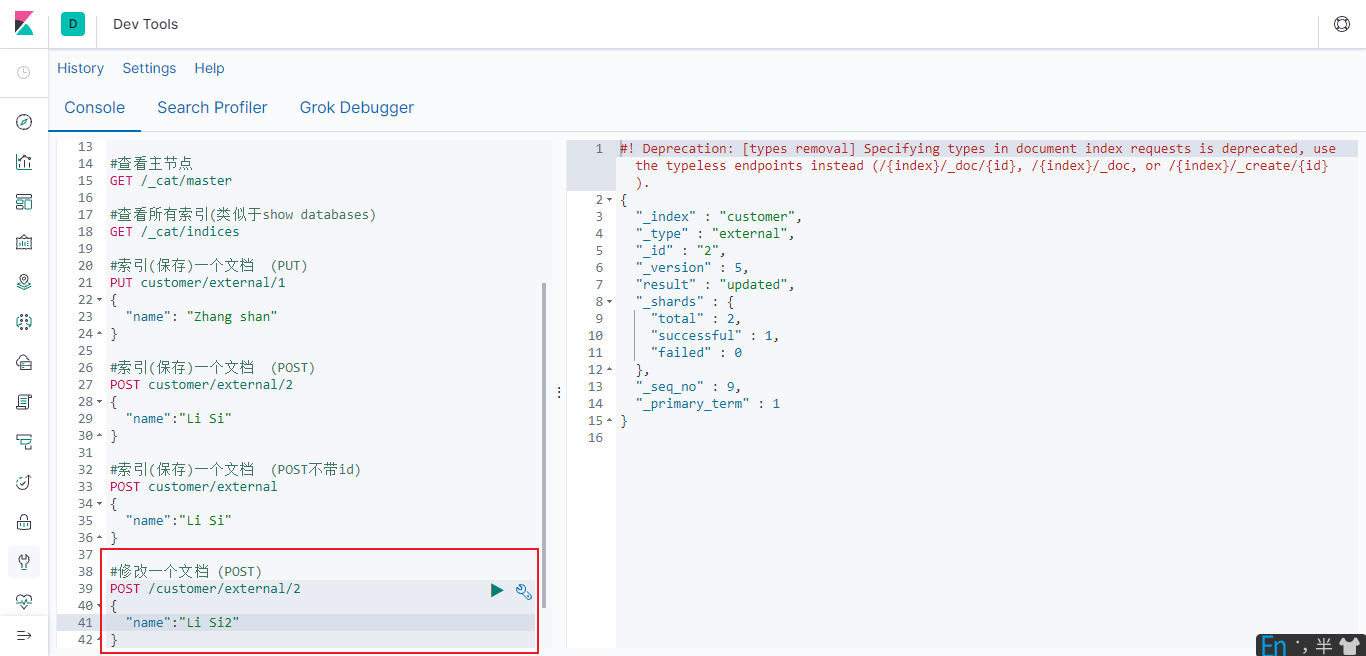
PUT 可以新增可以修改。PUT 必须指定 id; 由于 PUT 需要指定 id, 我们一般都用来做修改 操作, 不指定 id 会报错。
- PUT新增必须带id,不带id会报错
5.3查询指定id文档
#查询文档指定id
GET /customer/external/1
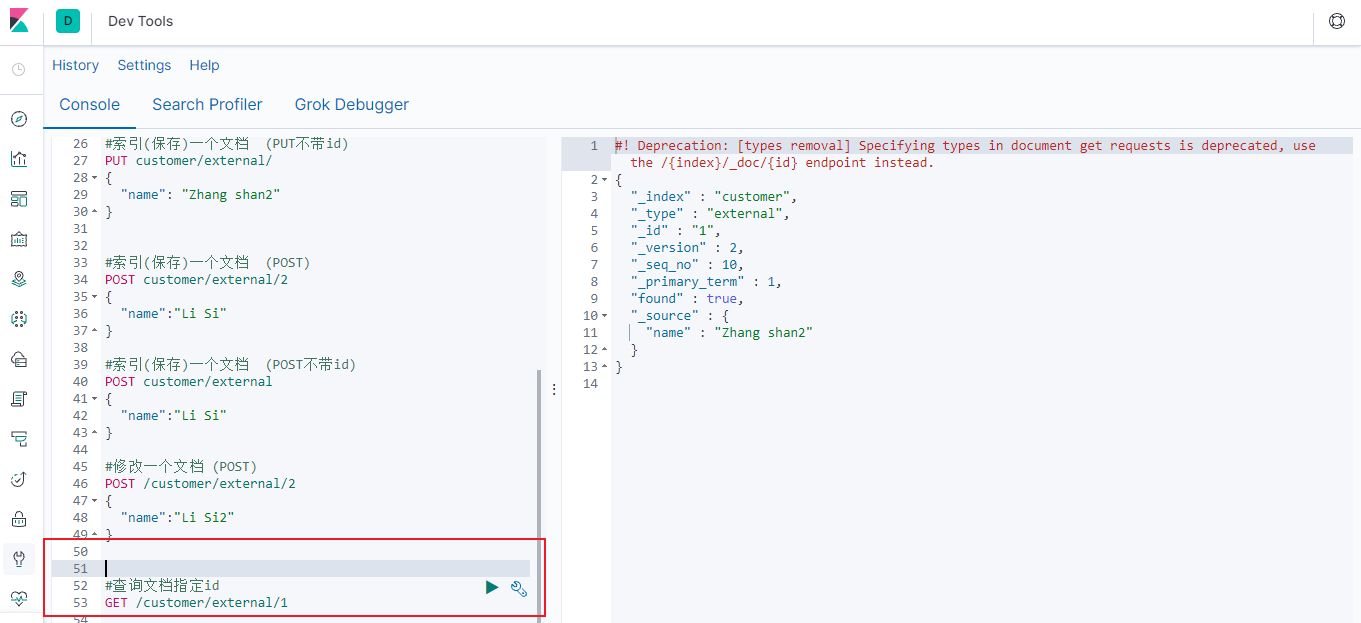
#查询结果
{
"_index" : "customer", //在哪个索引
"_type" : "external", //在哪个类型
"_id" : "1", //记录 id
"_version" : 2, //版本号
"_seq_no" : 10, //并发控制字段, 每次更新就会+1, 用来做乐观锁
"_primary_term" : 1, //同上, 主分片重新分配, 如重启, 就会变化
"found" : true,
"_source" : { //真正的内容
"name" : "Zhang shan2"
}
}
5.4更新文档
5.4.1 POST更新方式一
POST customer/external/1/_update
{
"doc": {
"name": "John Doew"
}
}
5.4.2 POST更新方式二
#之前就是这种写法
POST customer/external/1
{
"name": "John Doe2"
}
5.4.3 PUT更新
PUT customer/external/1
{
"name": "John Doe3"
}
5.4.3 更新同时增加属性
#更新同时增加属性
POST customer/external/1/_update
{
"doc": {
"name": "Jane Doe",
"age": 20
}
}
5.4.4 三种更新方式的特点
POST方式一与方式二的区别是否带update
- 带_update的POST更新:会对比源文档数据, 如果相同不会有什么操作, 文档 version 不增加
(会对比源文档数据, 如果相同不会有什么操作, 文档 version 不增加)
- 不带_update的POST:总会将数据重新保存并增加 version 版本
POST使用场景
对于大并发更新, 不带 update;
对于大并发查询偶尔更新, 带 update; 对比更新, 重新计算分配规则。
- PUT 操作总会将数据重新保存并增加 version 版本;
5.5删除指定id文档&索引
5.5.1删除指定id文档
#删除文档
DELETE customer/external/1
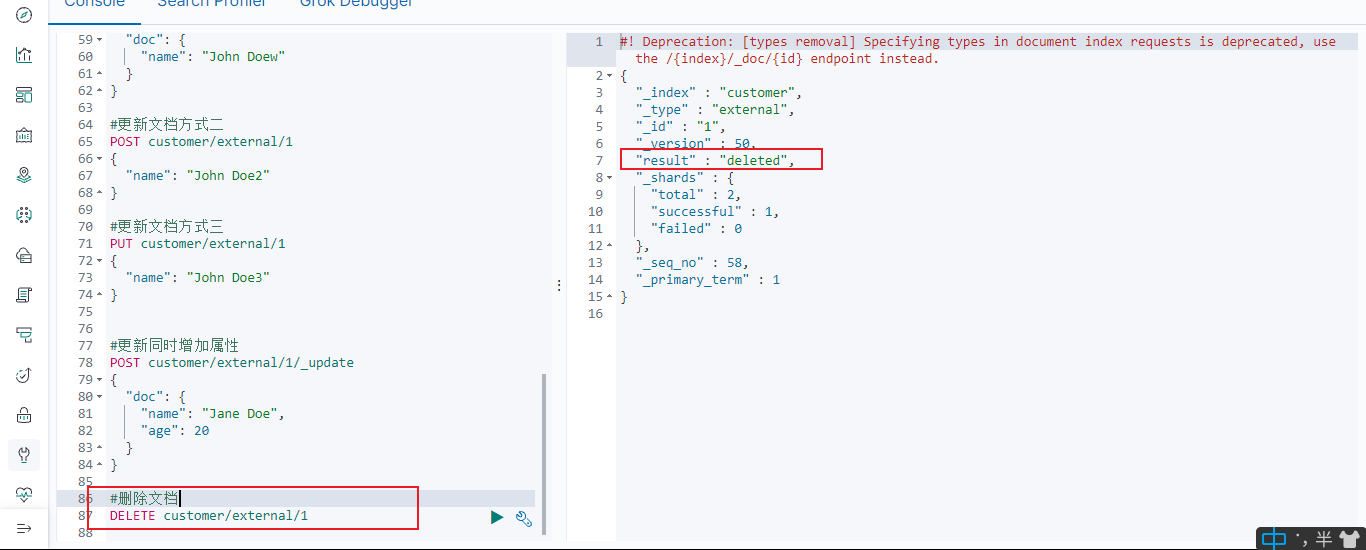
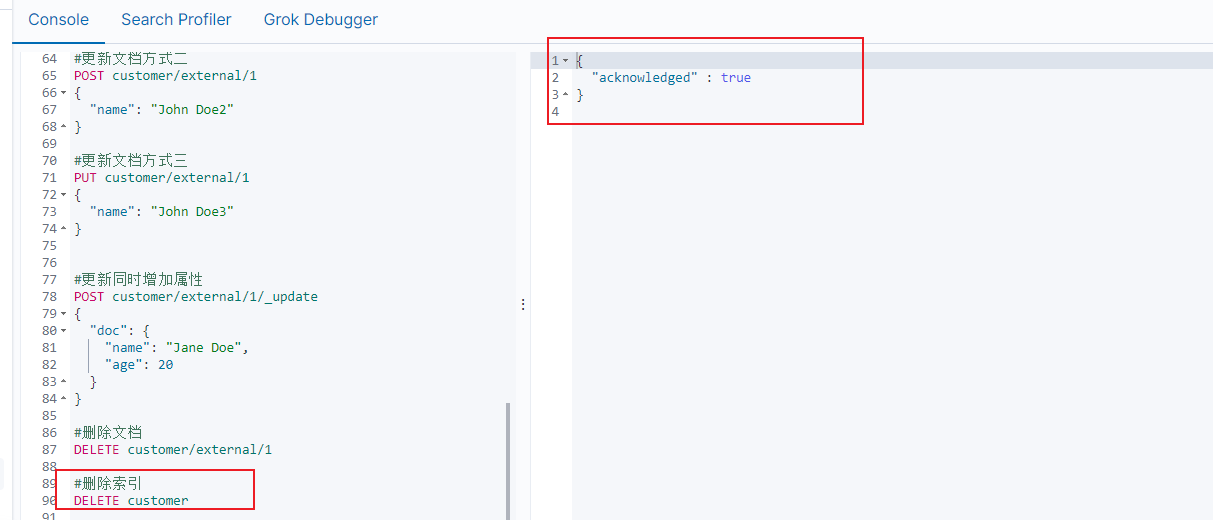
5.5.2删除索引
#删除索引
DELETE customer
5.6 bulk 批量 API
在单个 API 调用中执行多个索引或删除操作。这减少了开销并且可以大大提高索引速度。
5.6.1 语法格式
{ action: { metadata }} //action: 操作; metadata:对哪一个数据进行操作
{ request body } //操作的内容
{ action: { metadata }}
{ request body }
两个一组
#批量操作
POST customer/external/_bulk //对customer索引下的external类型进行批量操作
{"index":{"_id":"1"}} //索引(添加)一个文档,指定id=1
{"name": "John Doe" } //id=1的属性值
{"index":{"_id":"2"}} //索引(添加)一个文档,指定id=2
{"name": "Jane Doe" } //id=2属性值
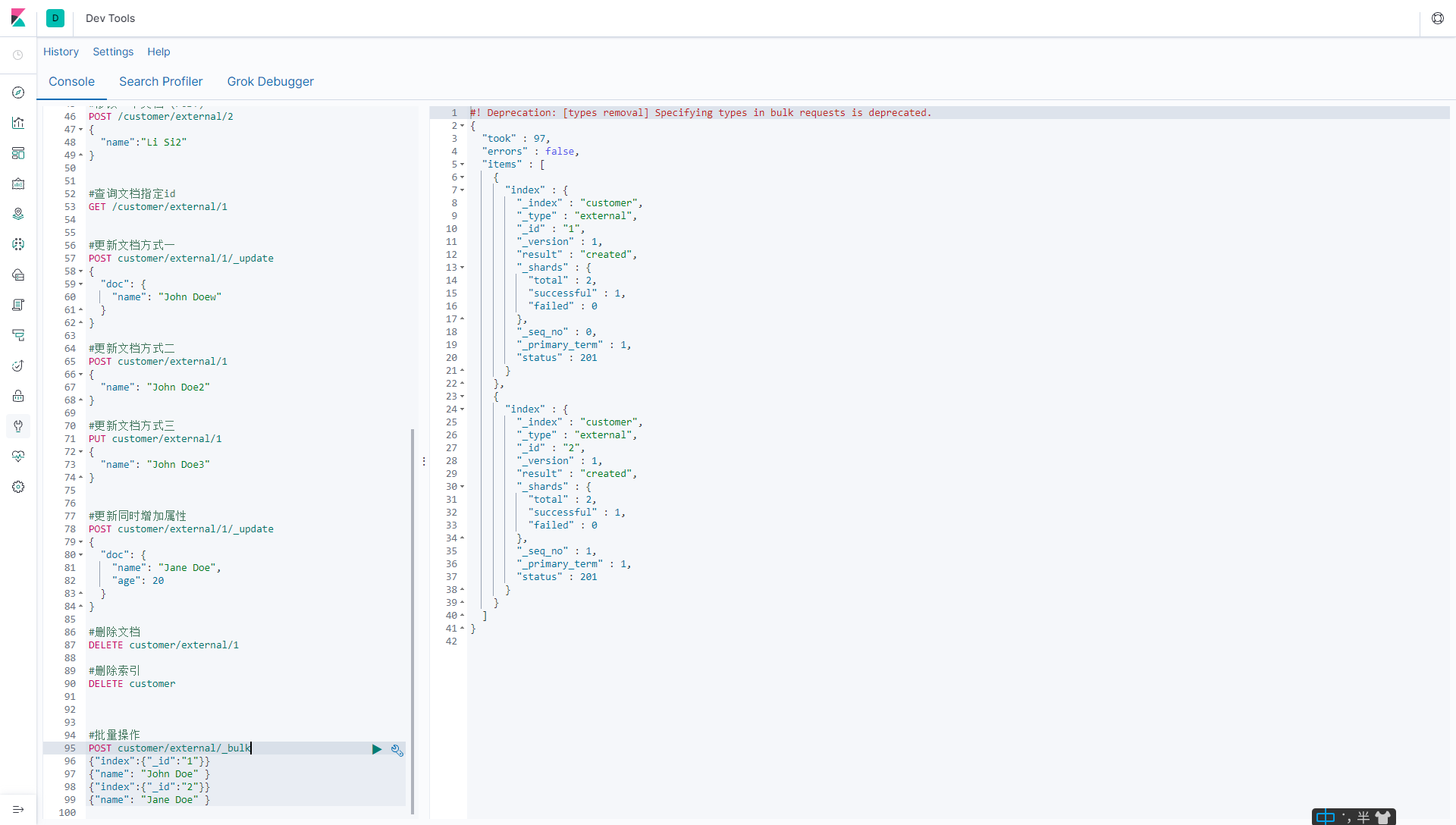
5.6.2 复杂实例
POST /_bulk
{ "delete": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "create": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "title": "My first blog post" }
{ "index": { "_index": "website", "_type": "blog" }}
{ "title": "My second blog post" }
{ "update": { "_index": "website", "_type": "blog", "_id": "123"}}
{ "doc" : {"title" : "My updated blog post"} }
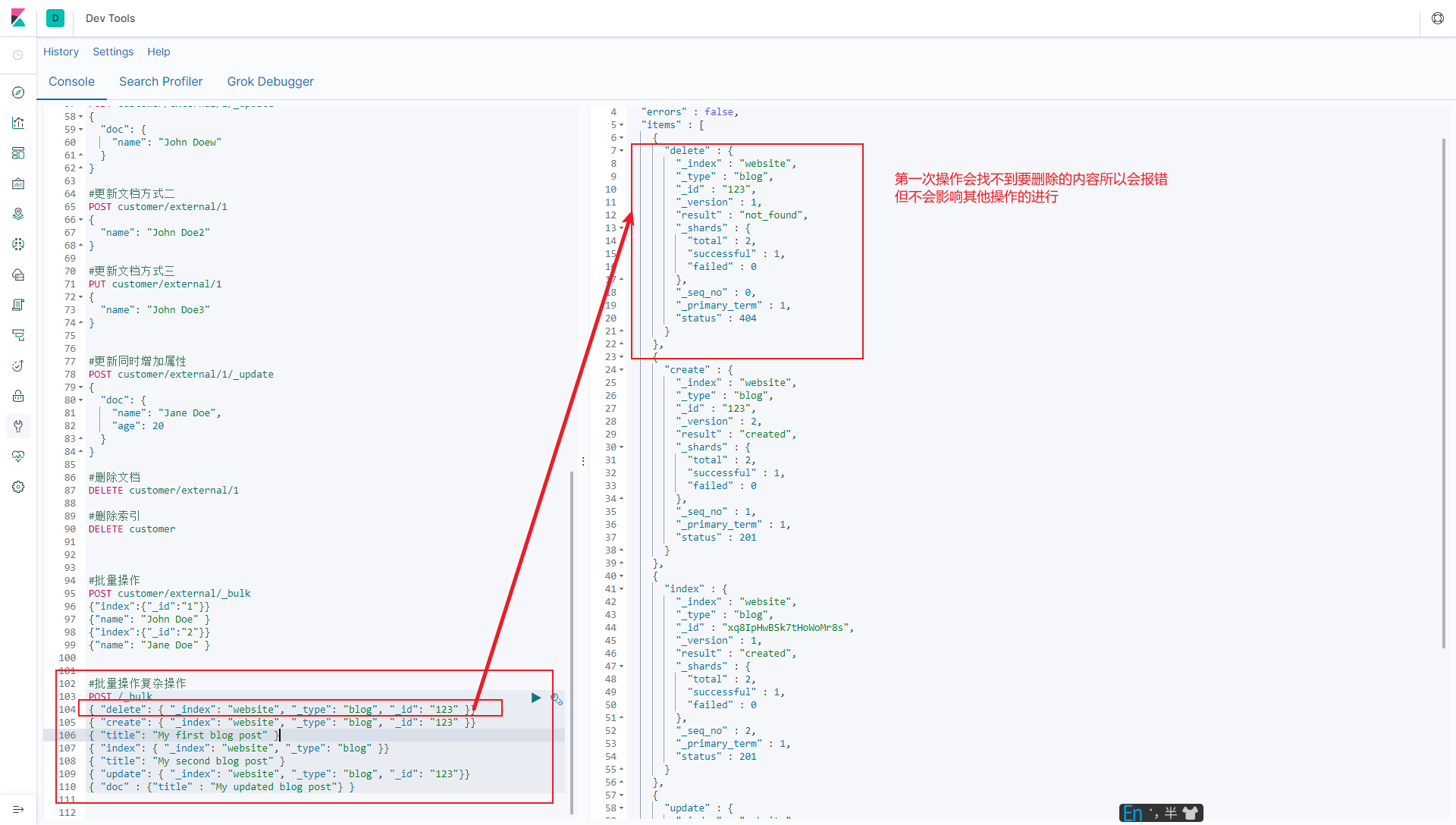
bulk API 以此按顺序执行所有的 action(动作) 。 如果一个单个的动作因任何原因而失败,它将继续处理它后面剩余的动作。 当 bulk API 返回时, 它将提供每个动作的状态(与发送的顺序相同) , 所以您可以检查是否一个指定的动作是不是失败了。
5.6.3 样本测试数据
原测试数据地址已经挂了
新测试数据地址:https://gitee.com/zhourui815/gulimall/blob/master/doc/es%E6%B5%8B%E8%AF%95%E6%95%B0%E6%8D%AE.json
POST bank/account/_bulk
测试数据
6.进阶检索
6.1 SearchAPI
ES 支持两种基本方式检索 :
- 一个是通过使用 REST request URI 发送搜索参数(uri+检索参数)
- 另一个是通过使用 REST request body 来发送它们(uri+请求体)
6.1.1检索信息
**一切检索从_search 开始 **
#检索 bank 下所有信息, 包括 type 和 docs
GET bank/_search
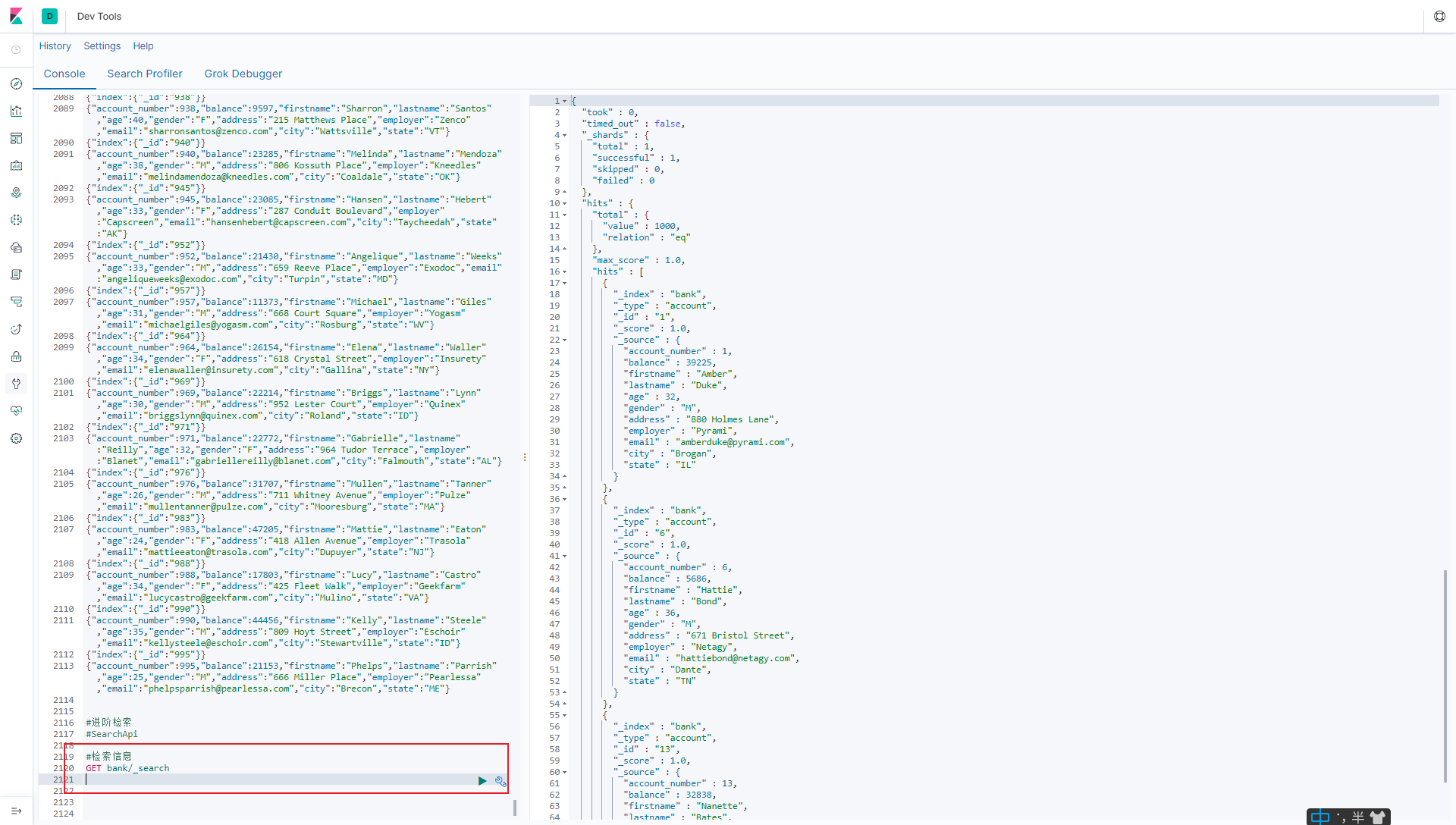
6.1.1.1请求参数方式检索
#请求参数方式检索
q=* 代表要查询的字段类似于select *
sort=account_number:asc 代表按照account_number字段排序,升序
GET bank/_search?q=*&sort=account_number:asc
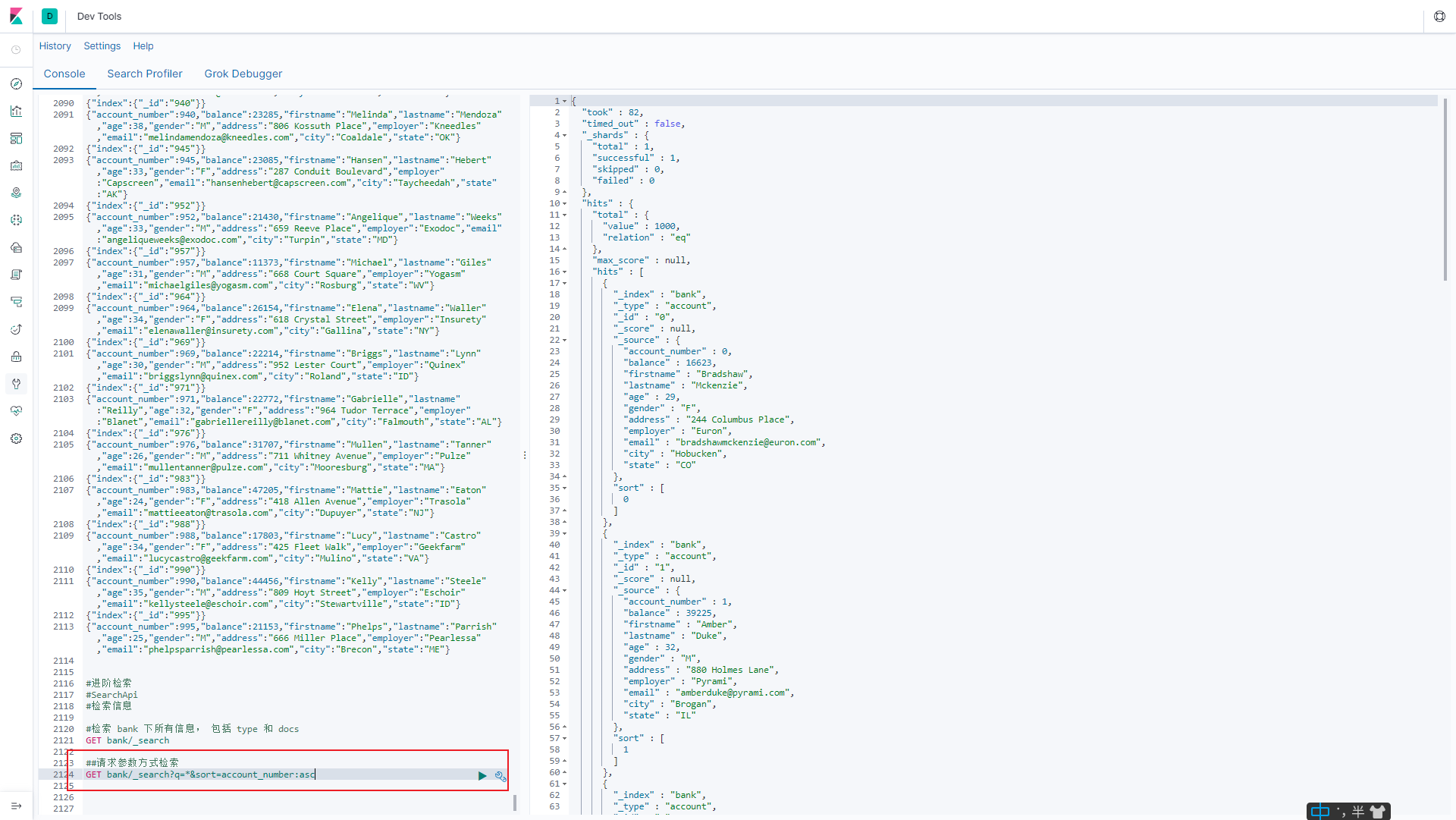
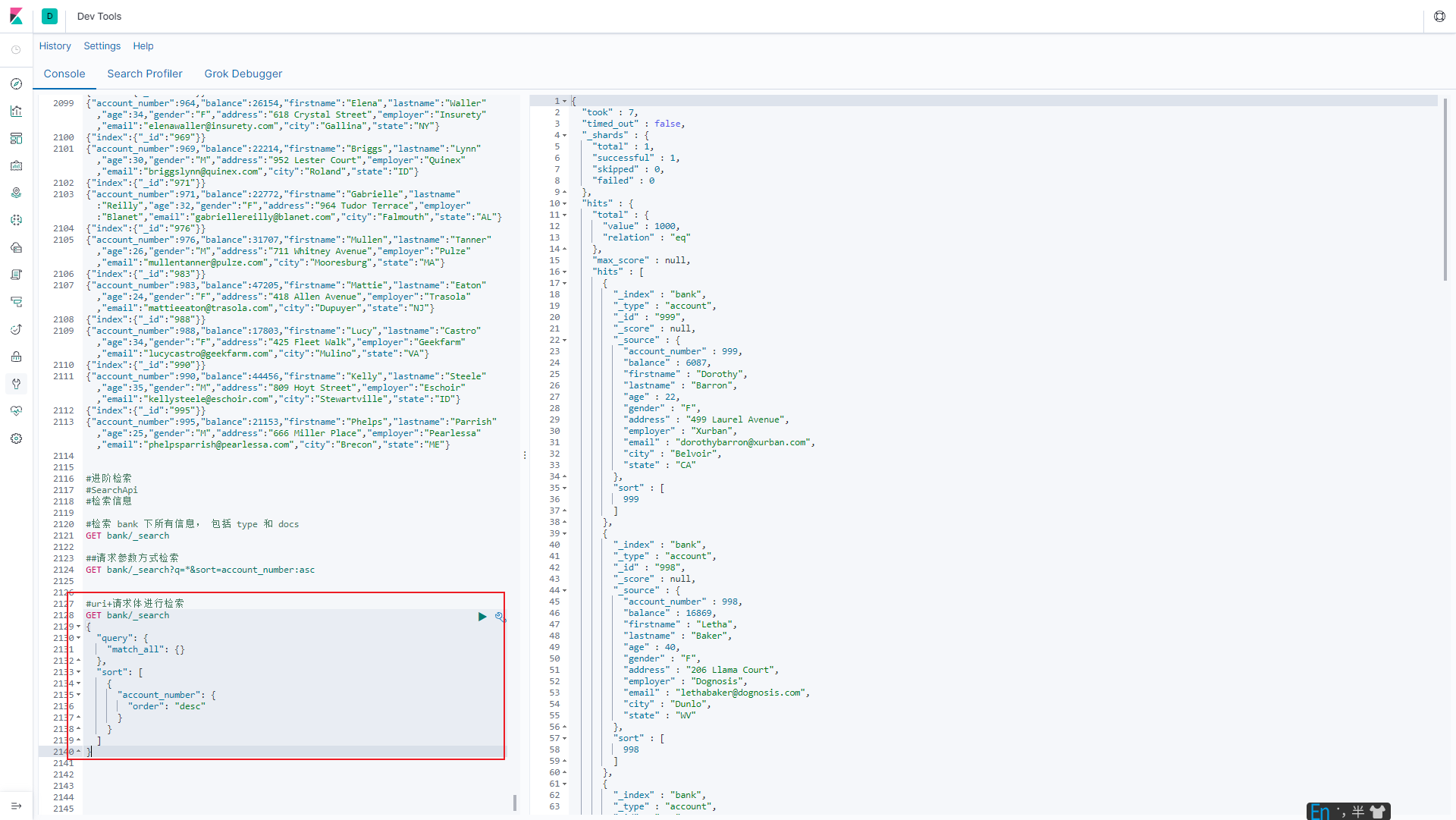
6.1.1.2 uri+请求体进行检索
#uri+请求体进行检索
GET bank/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"account_number": {
"order": "desc"
}
}
]
}
6.2 Query DSL
Elasticsearch 提供了一个可以执行查询的 Json 风格的 DSL( domain-specific language 领域特定语言) 。 这个被称为 Query DSL。 该查询语言非常全面, 并且刚开始的时候感觉有点复杂,真正学好它的方法是从一些基础的示例开始的。
6.2.1 基本语法格式
6.2.1.1 查询结构
#一个查询语句 的典型结构
{
QUERY_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE,...
}
}
#如果是针对某个字段, 那么它的结构如下:
{
QUERY_NAME: {
FIELD_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE,...
}
}
}
6.2.1.2查询示例
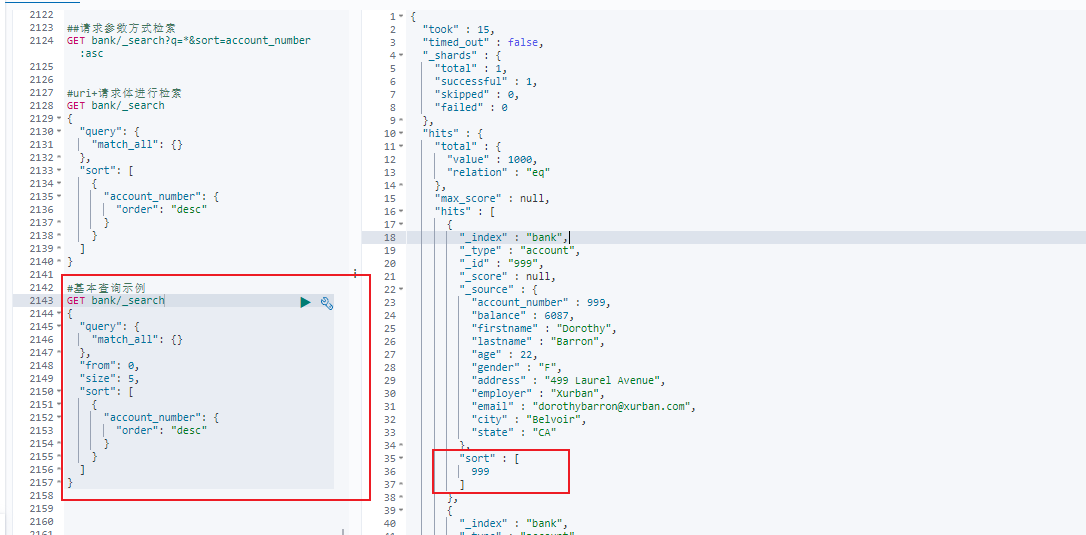
查询back索引并按照account_number字段降序排序,分页大小为5
#基本查询示例
GET bank/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 5,
"sort": [
{
"account_number": {
"order": "desc"
}
}
]
}
- query 定义如何查询,
- match_all 查询类型【代表查询所有的所有】 , es 中可以在 query 中组合非常多的查 询类型完成复杂查询
- 除了 query 参数之外, 我们也可以传递其它的参数以改变查询结果。 如 sort, size
- from+size 限定, 完成分页功能
- sort 排序, 多字段排序, 会在前序字段相等时后续字段内部排序, 否则以前序为准
6.2.2 match匹配
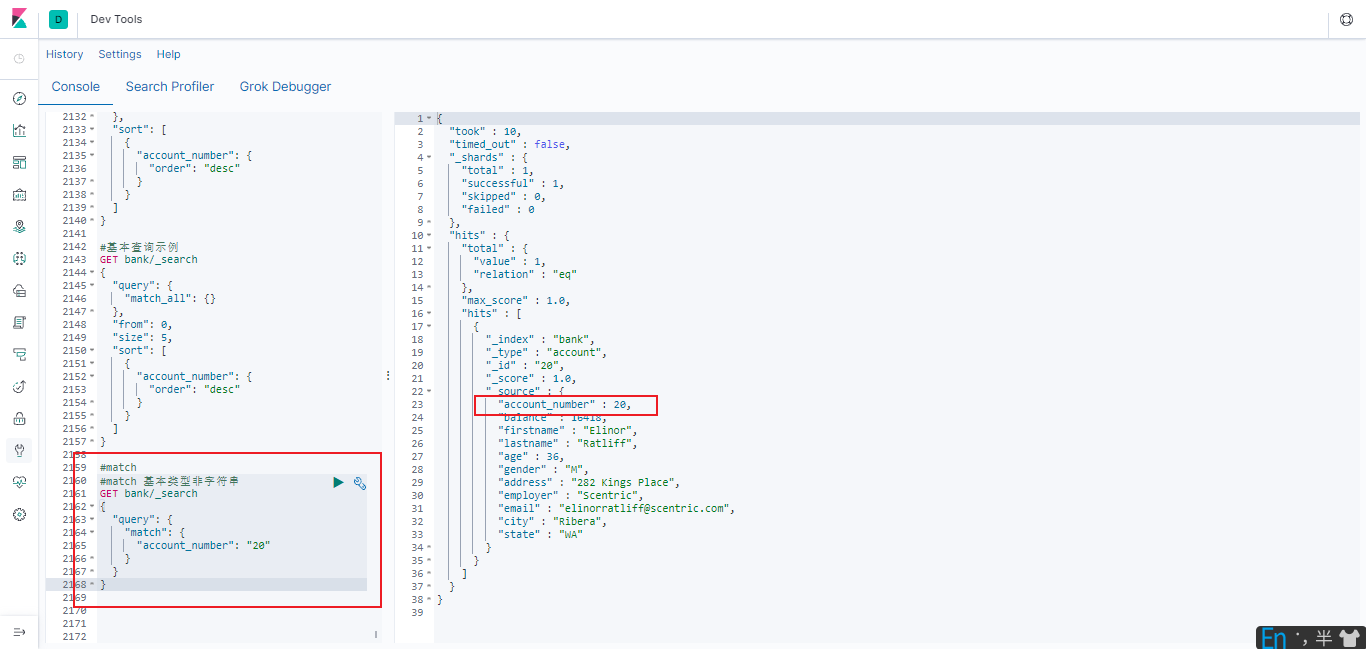
#match 基本类型(非字符串类型),精确匹配
GET bank/_search
{
"query": {
"match": {
"account_number": "20"
}
}
}
match 返回 account_number=20 的
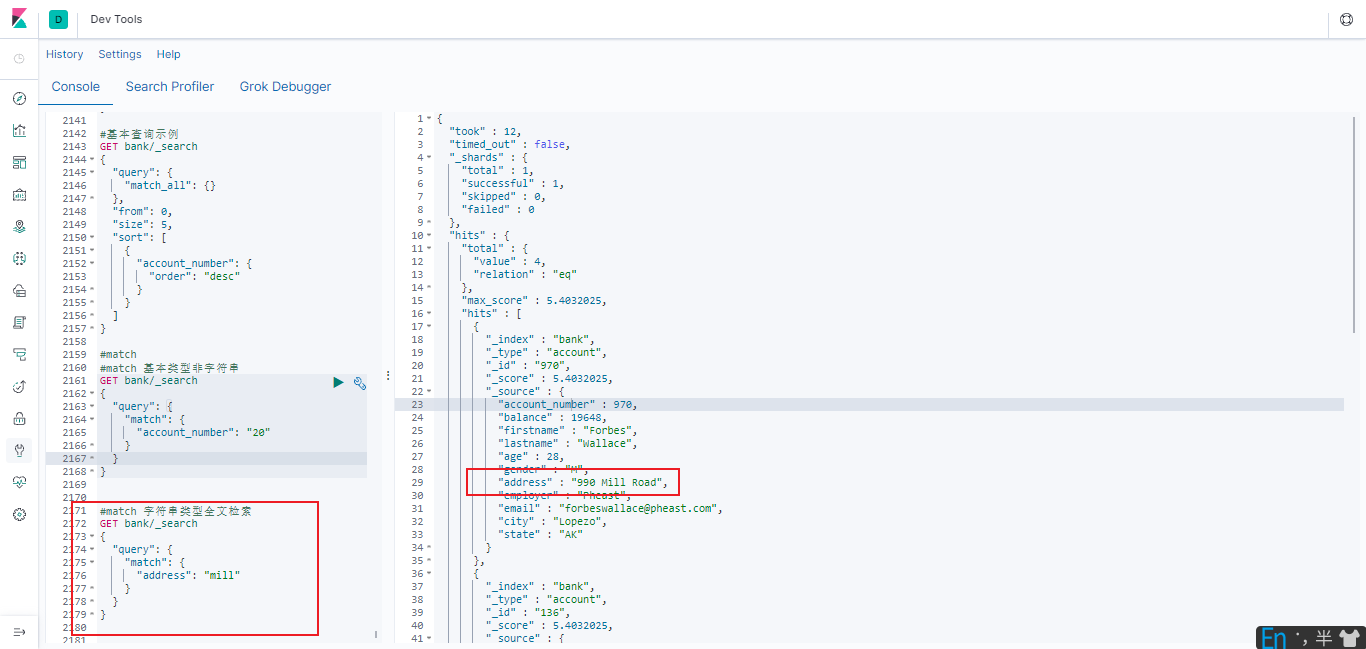
#match 字符串类型,全文检索
GET bank/_search
{
"query": {
"match": {
"address": "mill"
}
}
}
最终查询出 address 中包含 mill 单词的所有记录 match 当搜索字符串类型的时候, 会进行全文检索, 并且每条记录有相关性得分。
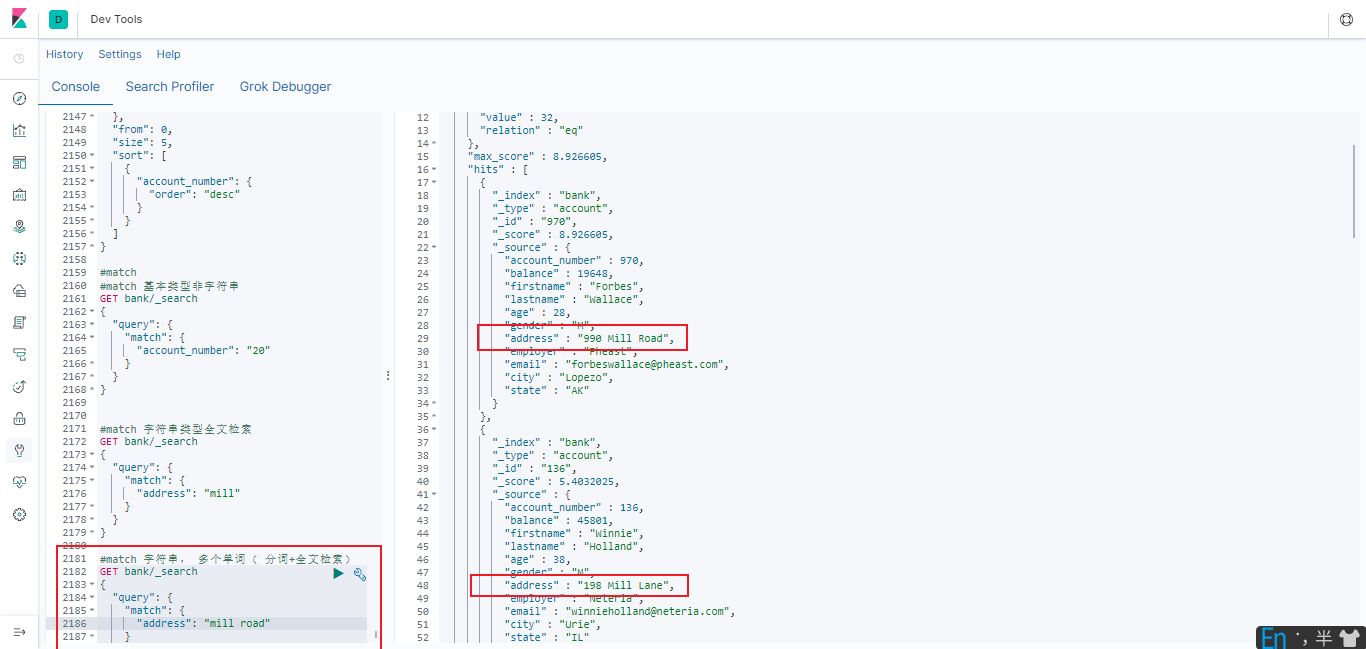
#match 字符串, 多个单词( 分词+全文检索)
GET bank/_search
{
"query": {
"match": {
"address": "mill road"
}
}
}
最终查询出 address 中包含 mill 或者 road 或者 mill road 的所有记录, 并给出相关性得分
6.2.3 match_phrase 短语匹配
**短语匹配:将需要匹配的值当成一个整体单词( 不分词) 进行检索 **
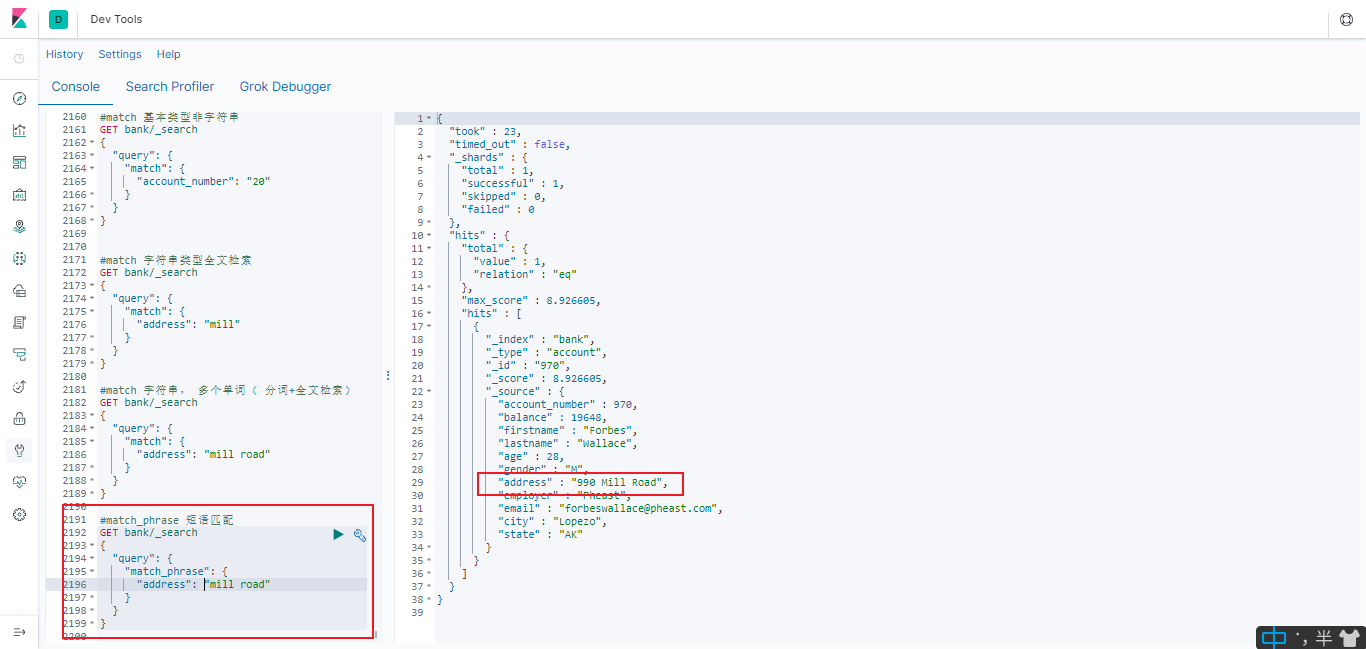
#match_phrase 短语匹配
GET bank/_search
{
"query": {
"match_phrase": {
"address": "mill road"
}
}
}
查出 address 中包含 mill road 的所有记录, 并给出相关性得分
6.2.4 multi_match 多字段匹配
#multi_match 多字段匹配
GET bank/_search
{
"query": {
"multi_match": {
"query": "mill",
"fields": ["address","state"]
}
}
}
查询 state 或者 address 包含 mill

6.2.5 bool 复合查询
bool 用来做复合查询:
复合语句可以合并 任何 其它查询语句, 包括复合语句, 了解这一点是很重要的。 这就意味着, 复合语句之间可以互相嵌套, 可以表达非常复杂的逻辑。
6.2.5.1 must
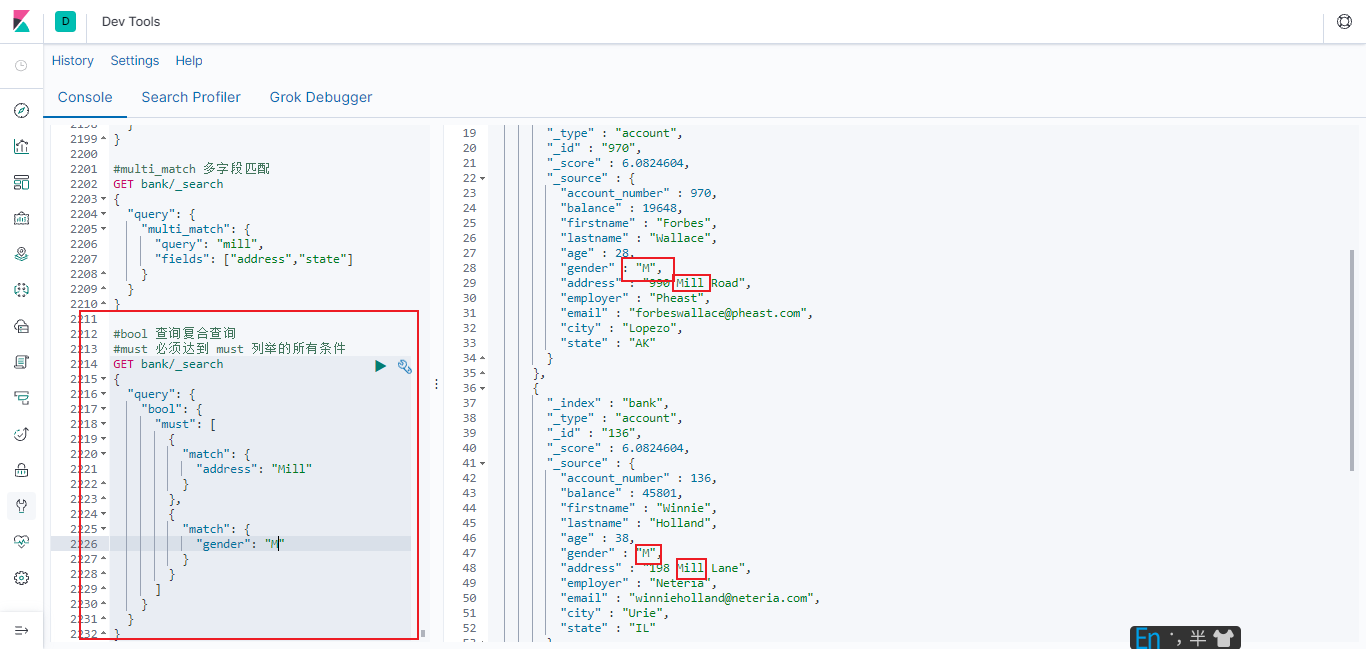
必须达到 must 列举的所有条件
#must 必须达到 must 列举的所有条件
GET bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"address": "Mill"
}
},
{
"match": {
"gender": "M"
}
}
]
}
}
}
6.2.5.2 should
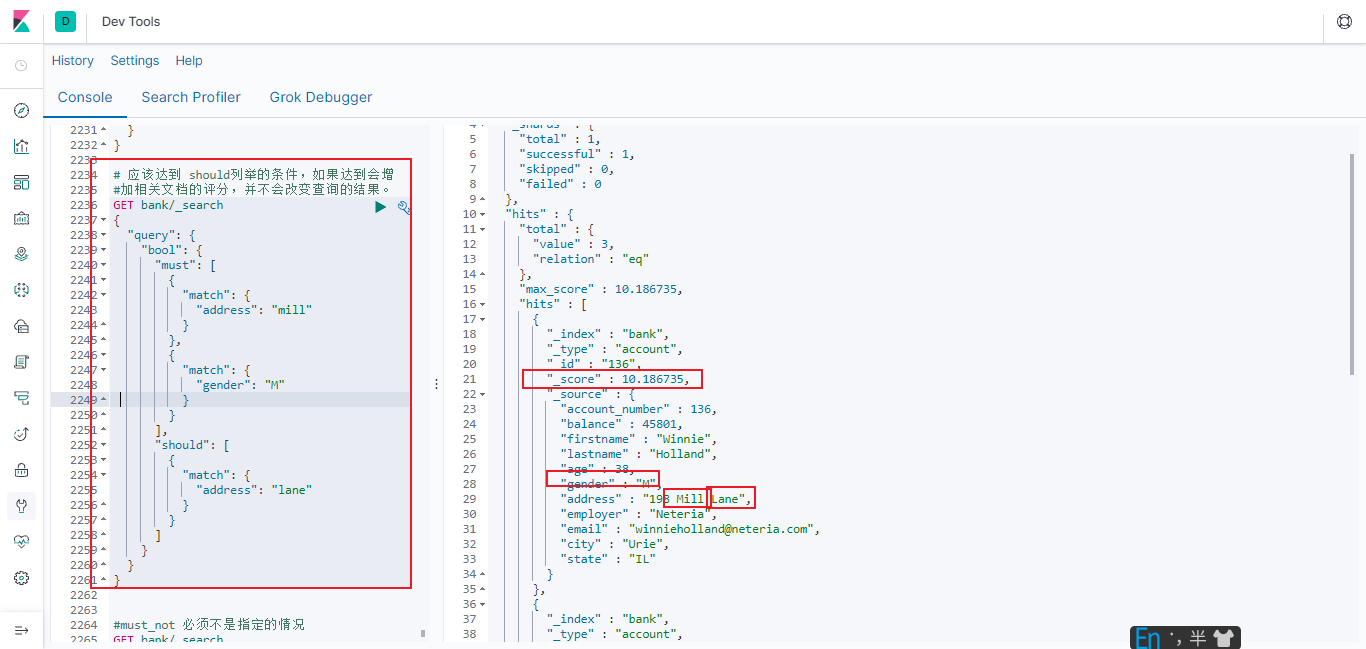
应该达到 should 列举的条件, 如果达到会增加相关文档的评分, 并不会改变查询的结果。 如果 query 中只有 should 且只有一种匹配规则, 那么 should 的条件就会被作为默认匹配条件而去改变查询结果
# 应该达到 should列举的条件,如果达到会增
#加相关文档的评分,并不会改变查询的结果。
GET bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"address": "mill"
}
},
{
"match": {
"gender": "M"
}
}
],
"should": [
{
"match": {
"address": "lane"
}
}
]
}
}
}
6.2.5.3 must_not
必须不是指定的情况
#must_not 必须不是指定的情况
GET bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"address": "mill"
}
},
{
"match": {
"gender": "M"
}
}
],
"should": [
{
"match": {
"address": "lane"
}
}
],
"must_not": [
{"match": {
"FIELD": "TEXT"
}}
]
}
}
}
6.2.5.2中查询的"email" : “winnieholland@neteria.com”,的记录不见了
address 包含 mill, 并且 gender 是 M, 如果 address 里面有 lane 最好不过, 但是 email 必 须不包含 baluba.com

6.2.5.4 filter 结果过滤
并不是所有的查询都需要产生分数, 特别是那些仅用于 “filtering”(过滤) 的文档。 **为了不计算分数 **Elasticsearch 会自动检查场景并且优化查询的执行。
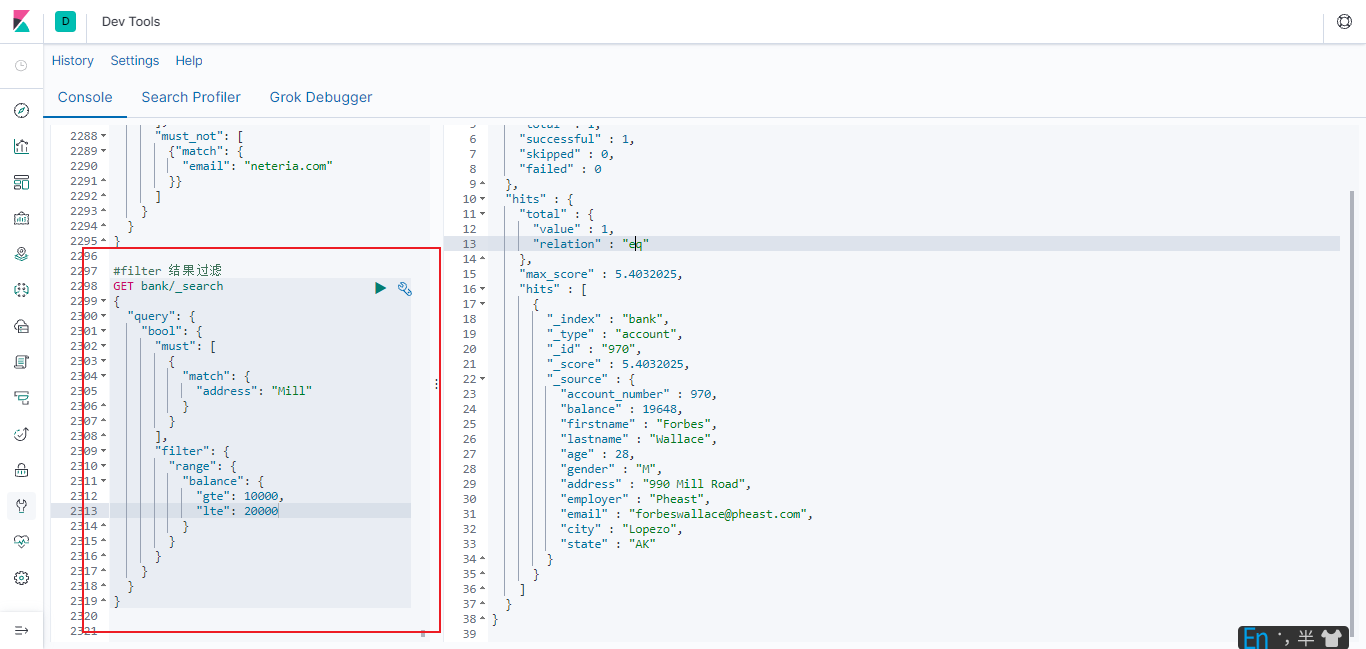
6.2.5.4 总结
| 事件 | 描述 |
|---|---|
| must | 子句(查询)必须出现在匹配的文档中,并将有助于得分。 |
| filter | 子句(查询))必须出现在匹配的文档中。然而不像 must此查询的分数将被忽略。 |
| should | 子句(查询)应出现在匹配文档中。在布尔查询中不包含must或fiter子句,一个或多个should子句必须有相匹配的文件。匹配 should条件的最小数目可通过设置minimum_should_match参数。 |
| must_not | 子句(查询)不能出现在匹配的文档中。 |
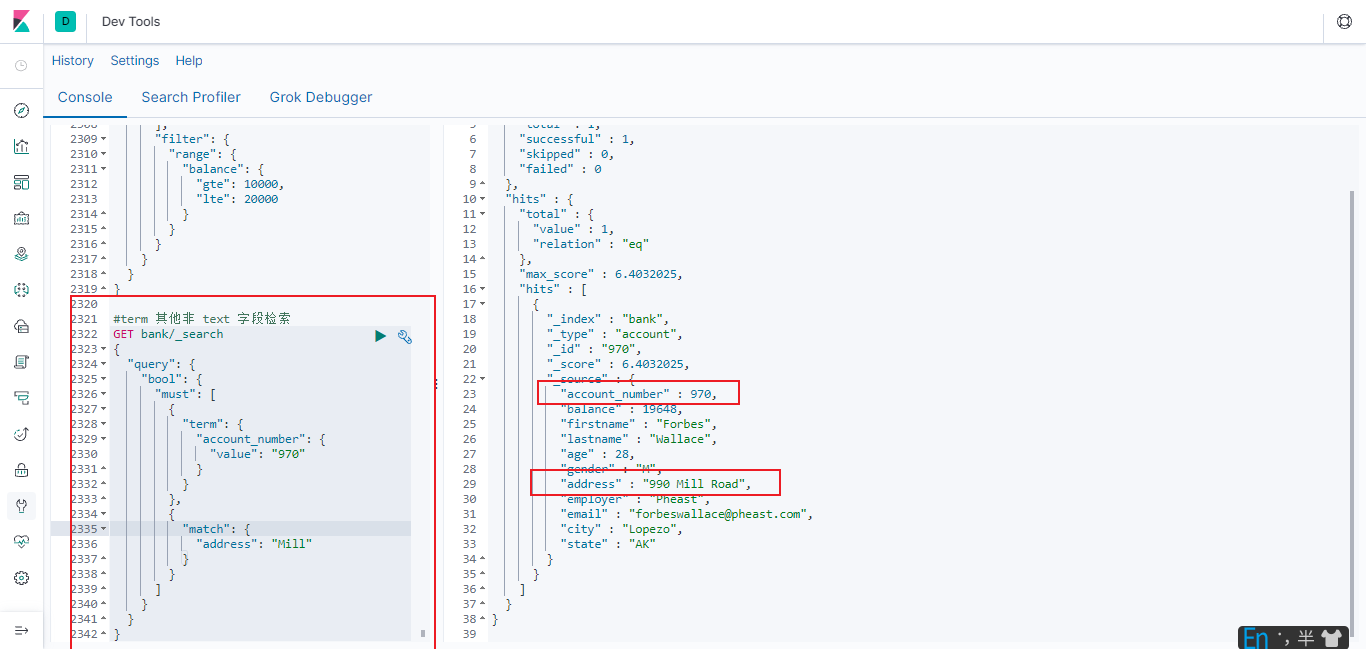
6.2.6 term 非 text 字段检索
和 match 一样。 匹配某个属性的值。 全文检索字段用 match, 其他非 text 字段匹配用 term。
#term 其他非 text 字段检索
GET bank/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"account_number": {
"value": "970"
}
}
},
{
"match": {
"address": "Mill"
}
}
]
}
}
}
6.2.7 aggregations 聚合检索
聚合提供了从数据中分组和提取数据的能力。 最简单的聚合方法大致等于 SQL GROUP BY 和 SQL 聚合函数。 在 Elasticsearch 中, 您有执行搜索返回 hits( 命中结果) , 并且同时返回聚合结果, 把一个响应中的所有 hits( 命中结果) 分隔开的能力。 这是非常强大且有效的,您可以执行查询和多个聚合, 并且在一次使用中得到各自的( 任何一个的) 返回结果, 使用一次简洁和简化的 API 来避免网络往返。
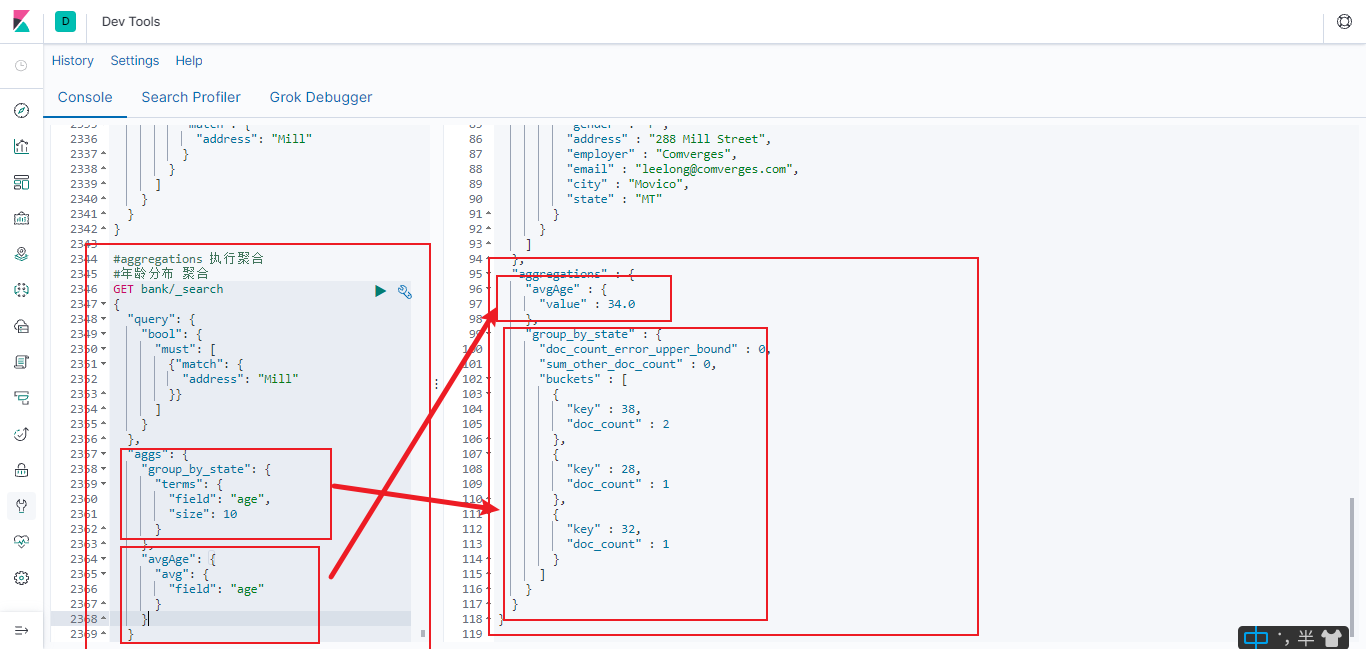
6.2.7.1 年龄分布 并求出年龄的平均值
搜索 address 中包含 mill 的所有人的年龄分布以及平均年龄, 但不显示这些人的详情
#aggregations 执行聚合
#年龄分布及平均值 聚合
GET bank/_search
{
"query": {
"bool": {
"must": [
{"match": {
"address": "Mill"
}}
]
}
},
"aggs": {
"group_by_state": {
"terms": {
"field": "age",
"size": 10
}
},
"avgAge": {
"avg": {
"field": "age"
}
}
}
}
size: 0 不显示搜索数据
aggs: 执行聚合。 聚合语法如下
“aggs”: {
“aggs_name 这次聚合的名字, 方便展示在结果集中”: {
"AGG_TYPE 聚合的类型(
avg,term,terms) ": {} }
},
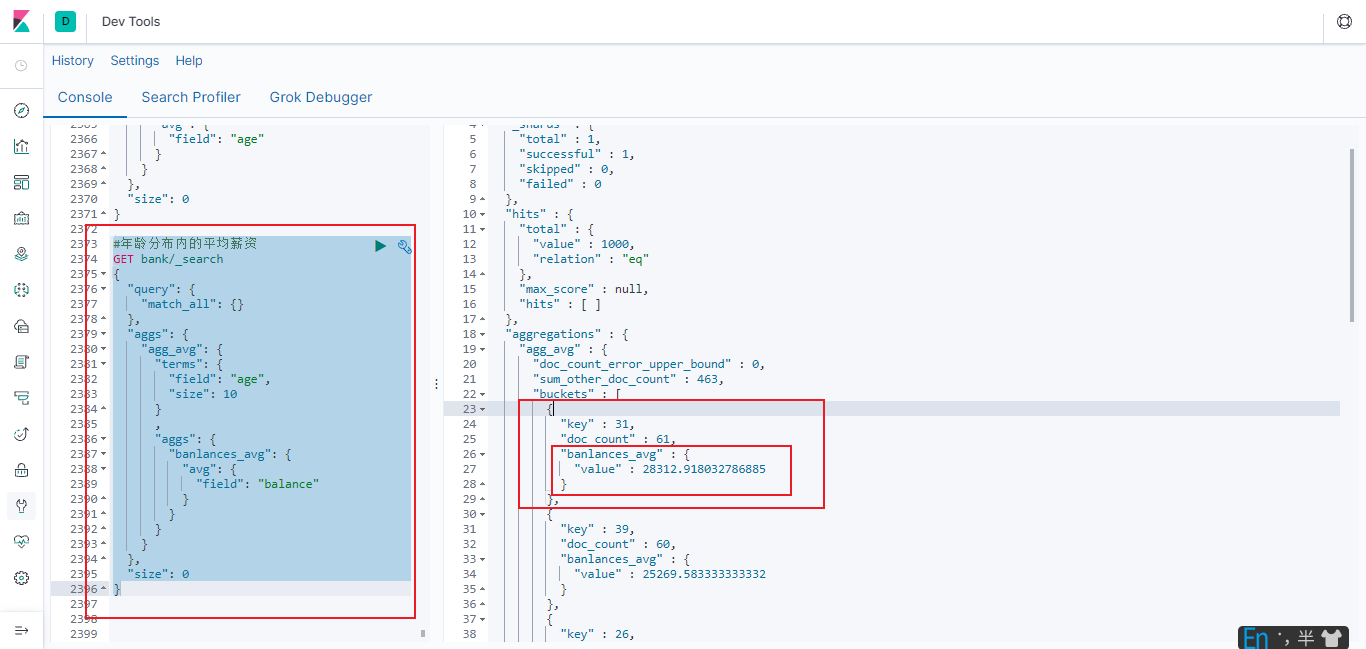
6.2.7.2 求出年龄分布,并在每个年龄求平均薪资
#年龄分布内的平均薪资
GET bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"agg_avg": {
"terms": {
"field": "age",
"size": 10
}
,
"aggs": {
"banlances_avg": {
"avg": {
"field": "balance"
}
}
}
}
},
"size": 0
}
注意与6.2.7.1区分,6.2.7.1是分为两个聚合
此示例是在一次聚合的基础上再次聚合
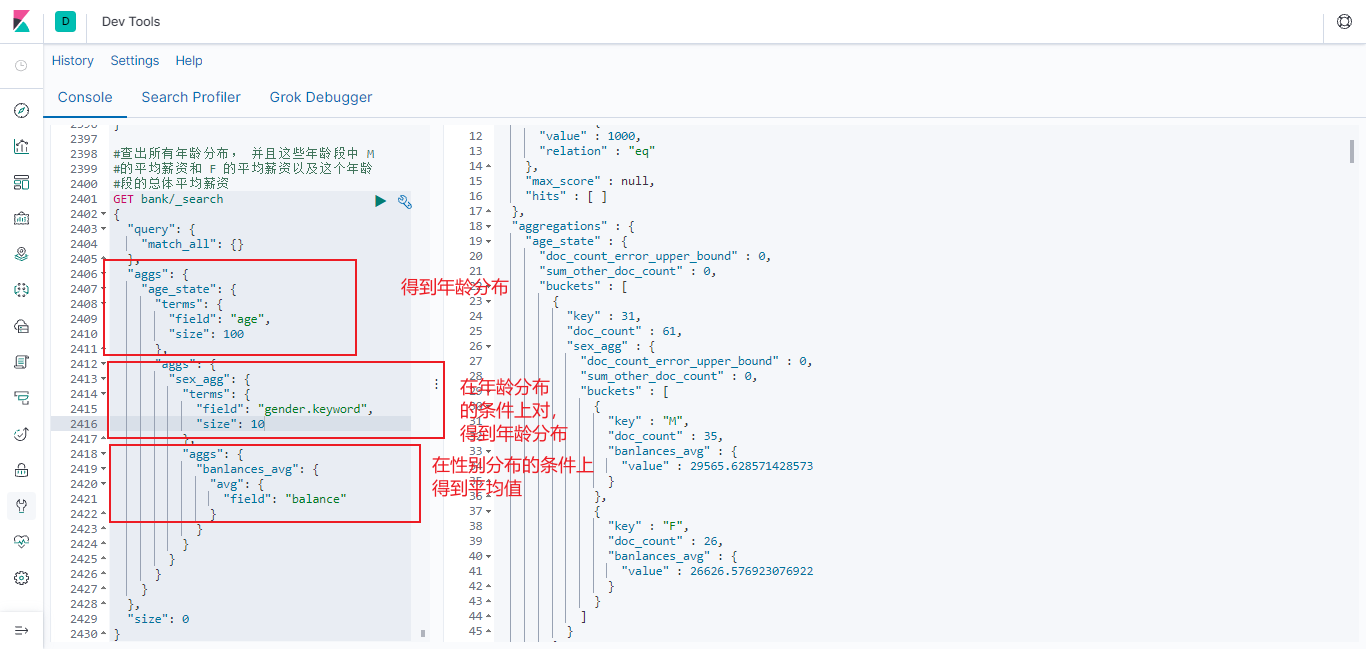
6.2.7.3 年龄分布,性别分布的基础上求平均值
查出所有年龄分布, 并且这些年龄段中 M 的平均薪资和 F 的平均薪资以及这个年龄段的总体平均薪资
#查出所有年龄分布, 并且这些年龄段中 M
#的平均薪资和 F 的平均薪资以及这个年龄
#段的总体平均薪资
GET bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"age_state": {
"terms": {
"field": "age",
"size": 100
},
"aggs": {
"sex_agg": {
"terms": {
"field": "gender.keyword",
"size": 10
},
"aggs": {
"banlances_avg": {
"avg": {
"field": "balance"
}
}
}
}
}
}
},
"size": 0
}
6.3 Mapping
6.3.1 字段类型


6.3.2 映射
Mapping(映射)
Mapping 是用来定义一个文档( document) , 以及它所包含的属性( field) 是如何存储和
索引的。 比如, 使用 mapping 来定义:
- 哪些字符串属性应该被看做全文本属性(full text fields) 。
- 哪些属性包含数字, 日期或者地理位置。
- 文档中的所有属性是否都能被索引(_all 配置) 。
- 日期的格式。
- 自定义映射规则来执行动态添加属性。
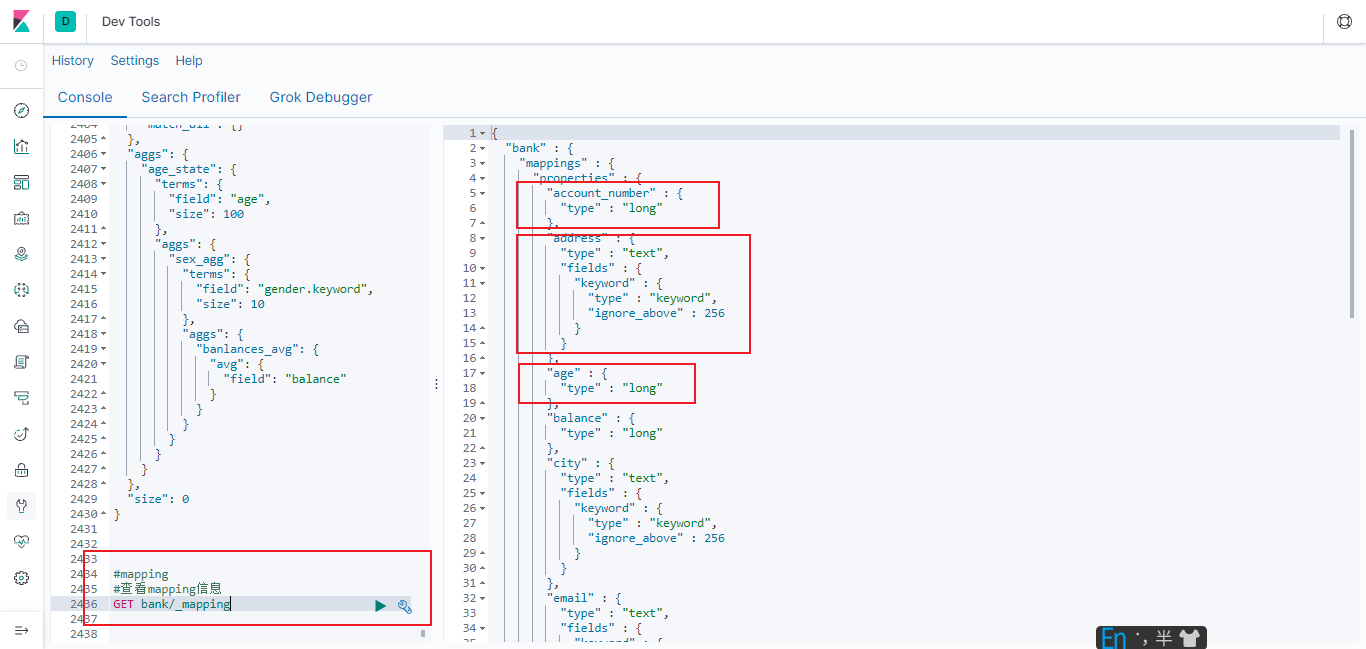
6.3.2.1 查看mapping信息
#查看mapping信息
GET bank/_mapping
我们在创建索引是没有指定类型,为什么会查询出来呢?
答:es会根据数据自动猜测的映射类型
6.3.3 新版本改变
Es7 及以上移除了 type 的概念。
关系型数据库中两个数据表示是独立的, 即使他们里面有相同名称的列也不影响使用,但 ES 中不是这样的。 elasticsearch 是基于 Lucene 开发的搜索引擎, 而 ES 中不同 type下名称相同的 filed 最终在 Lucene 中的处理方式是一样的。
两个不同 type 下的两个 user_name, 在 ES 同一个索引下其实被认为是同一个 filed,你必须在两个不同的 type 中定义相同的 filed 映射。 否则, 不同 type 中的相同字段名称就会在处理中出现冲突的情况, 导致 Lucene 处理效率下降。
去掉 type 就是为了提高 ES 处理数据的效率。
Elasticsearch 7.x
URL 中的 type 参数为可选。 比如, 索引一个文档不再要求提供文档类型。
Elasticsearch 8.x
不再支持 URL 中的 type 参数。
解决:
1) 、 将索引从多类型迁移到单类型, 每种类型文档一个独立索引
2) 、 将已存在的索引下的类型数据, 全部迁移到指定位置即可。 详见数据迁移
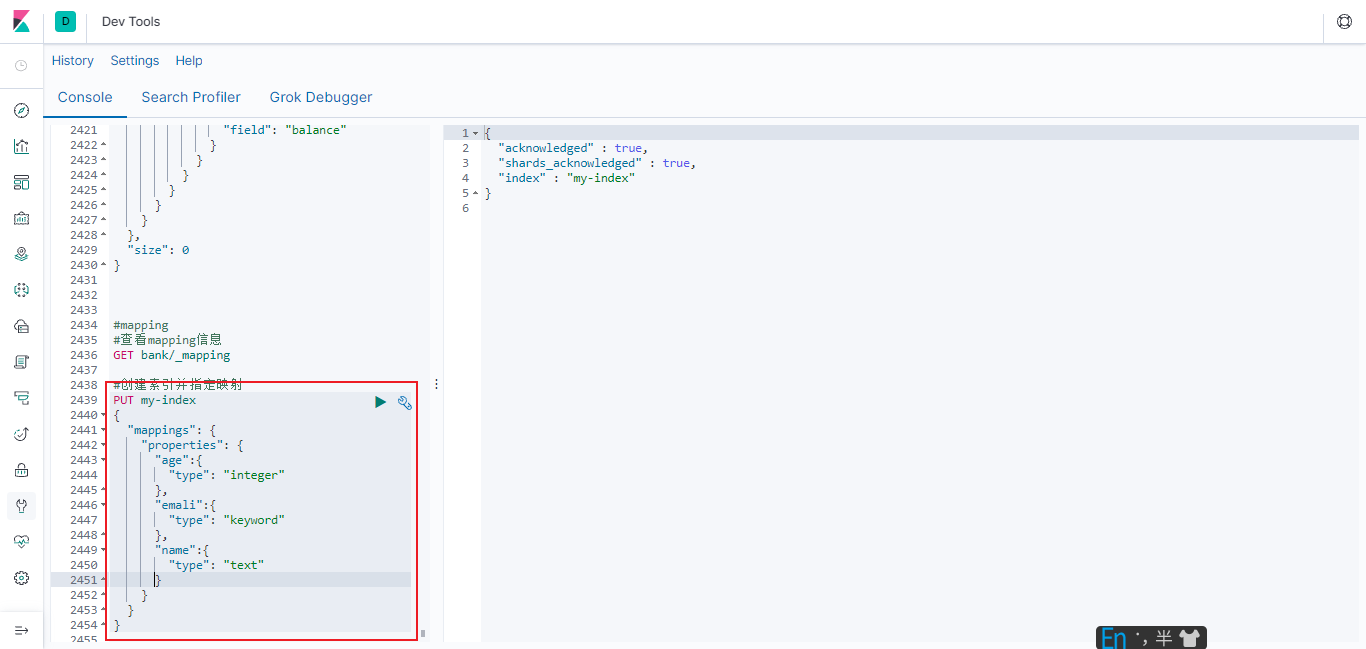
6.3.3.1 创建映射
#创建索引并指定映射
PUT my-index
{
"mappings": {
"properties": {
"age":{
"type": "integer"
},
"emali":{
"type": "keyword"
},
"name":{
"type": "text"
}
}
}
}
6.3.3.2 添加新的字段映射
#添加新的字段映射
PUT my-index/_mapping
{
"properties": {
"employee-id": {
"type": "text",
"index": false
}
}
}

6.3.3.3 更新映射
对于已经存在的映射字段, 我们不能更新。 更新必须创建新的索引进行数据迁移
6.3.3.4 数据迁移
6.3.3.4.1查询出想要修改的映射类型
GET bank/_mapping
#创建一个新的索引
将一下的属性复制出来
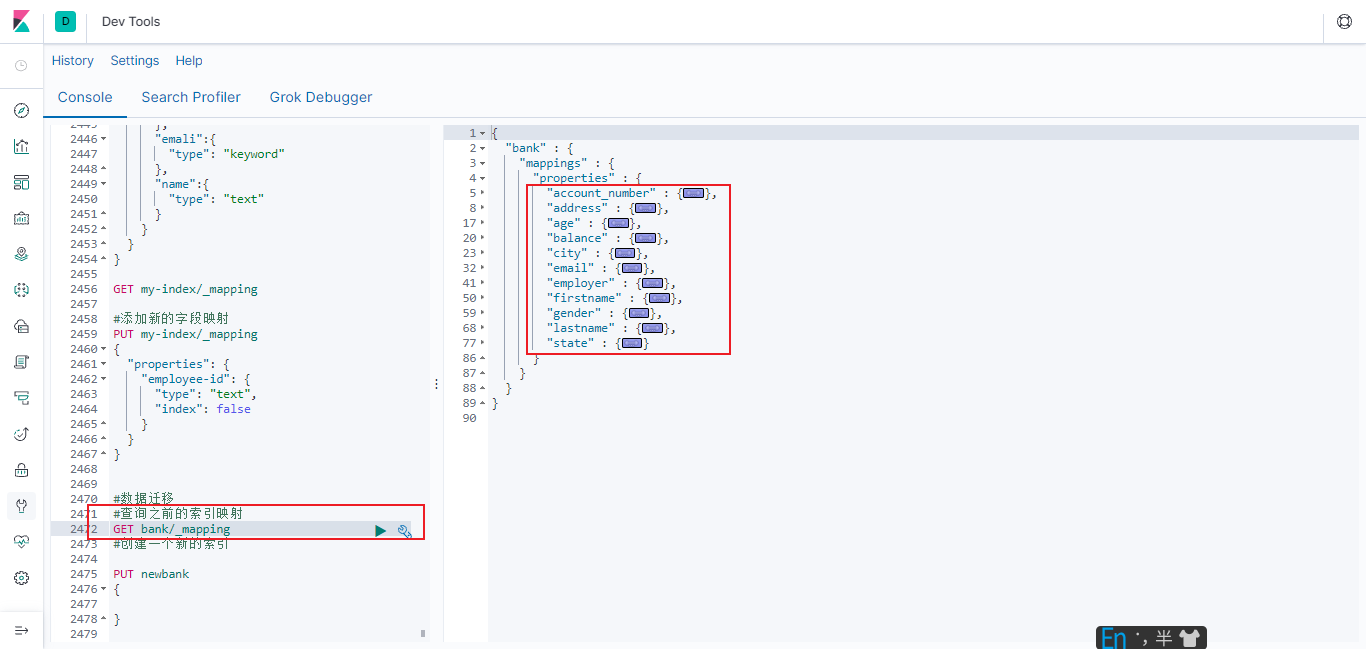
6.3.3.4.2 新增一个新的索引
将6.3.3.4.1中复制的属性粘贴至属性中,先不要执行
#创建一个新的索引 PUT newbank { "properties": { "account_number" : { "type" : "long" }, "address" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "age" : { "type" : "long" }, "balance" : { "type" : "long" }, "city" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "email" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "employer" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "firstname" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "gender" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "lastname" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "state" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } } } }
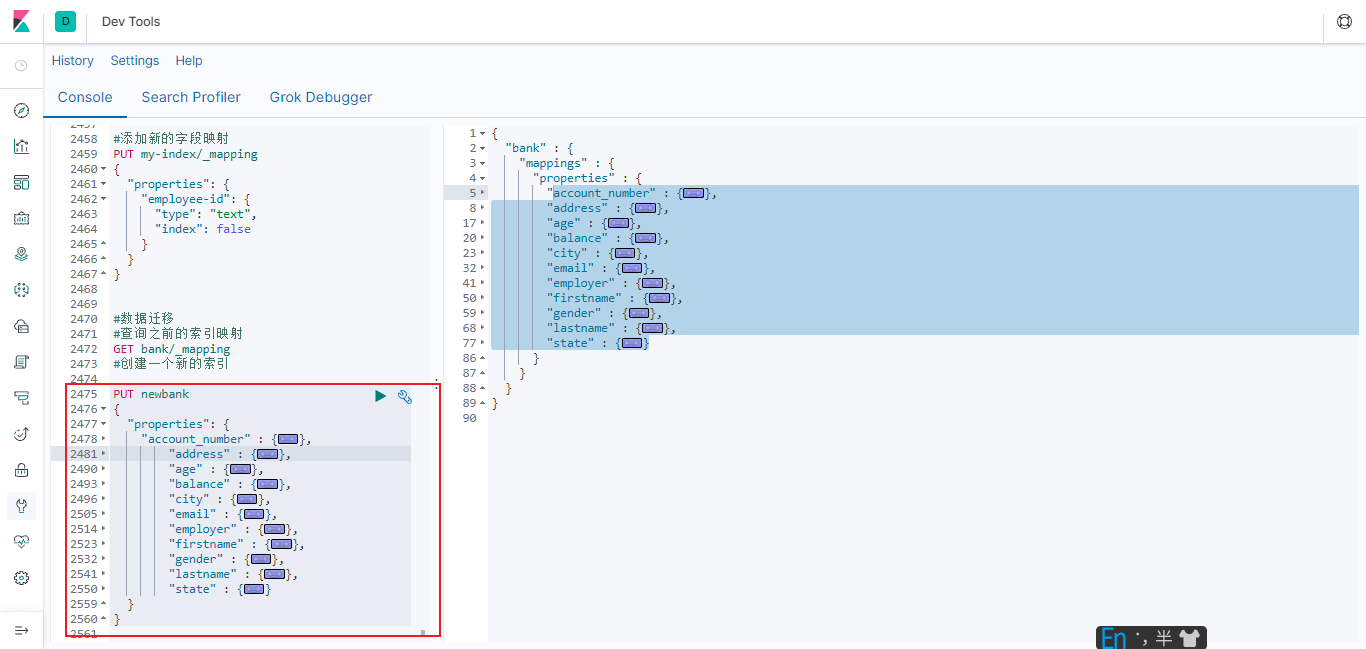
- 将各个字段的映射类型按照自己的需求修改 保存
#创建一个新的索引
PUT /newbank
{
"mappings": {
"properties": {
"account_number": {
"type": "long"
},
"address": {
"type": "text"
},
"age": {
"type": "integer"
},
"balance": {
"type": "long"
},
"city": {
"type": "keyword"
},
"email": {
"type": "keyword"
},
"employer": {
"type": "keyword"
},
"firstname": {
"type": "text"
},
"gender": {
"type": "keyword"
},
"lastname": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"state": {
"type": "keyword"
}
}
}
}
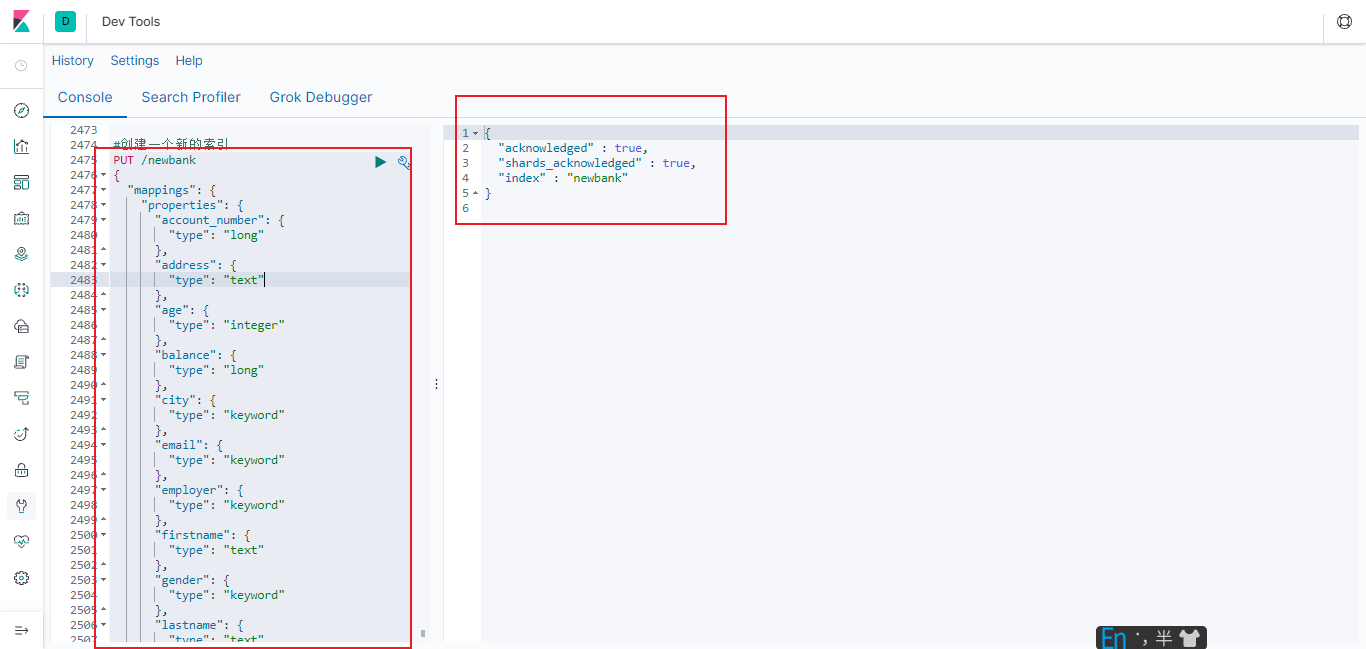
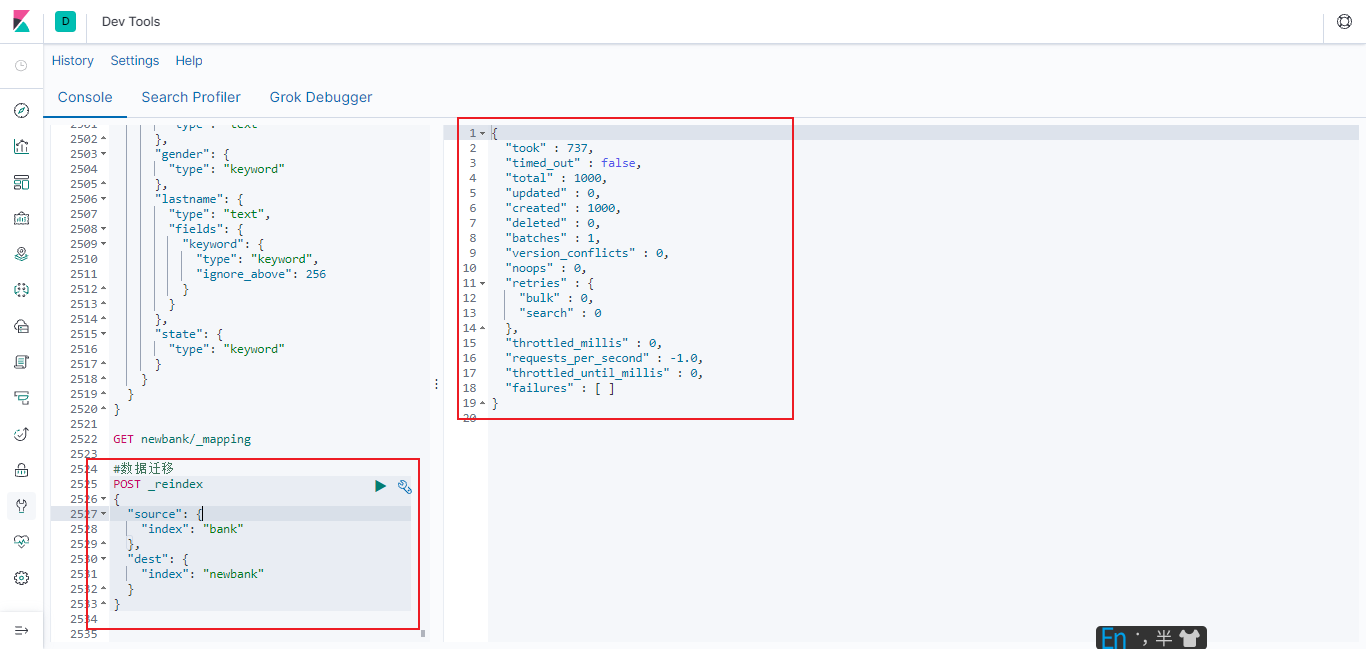
6.3.3.4.3 数据迁移
先创建出 newbank 的正确映射。 然后使用如下方式进行数据迁移
固定语法
POST _reindex
{
“source”: {
“index”: “twitter”
},
“dest”: {
“index”: “new_twitter”
}
}
将 旧索引的 type 下的数据进行迁移
#数据迁移
POST _reindex
{
"source": {
"index": "bank"
},
"dest": {
"index": "newbank"
}
}
迁移成功
6.4 分词
一个 tokenizer( 分词器) 接收一个字符流, 将之分割为独立的 tokens( 词元, 通常是独立的单词) , 然后输出 tokens 流。
例如, whitespace tokenizer 遇到空白字符时分割文本。 它会将文本 “Quick brown fox!” 分割为 [Quick, brown, fox!]。
该 tokenizer(分词器) 还负责记录各个 term(词条) 的顺序或 position 位置(用于 phrase 短语和 word proximity 词近邻查询) , 以及 term(词条) 所代表的原始 word(单词) 的 start(起始) 和 end(结束) 的 character offsets(字符偏移量) (用于高亮显示搜索的内容) 。
Elasticsearch 提供了很多内置的分词器, 可以用来构建 custom analyzers(自定义分词器) 。
6.4.1安装ik分词器
没安装ik分词器之前的效果
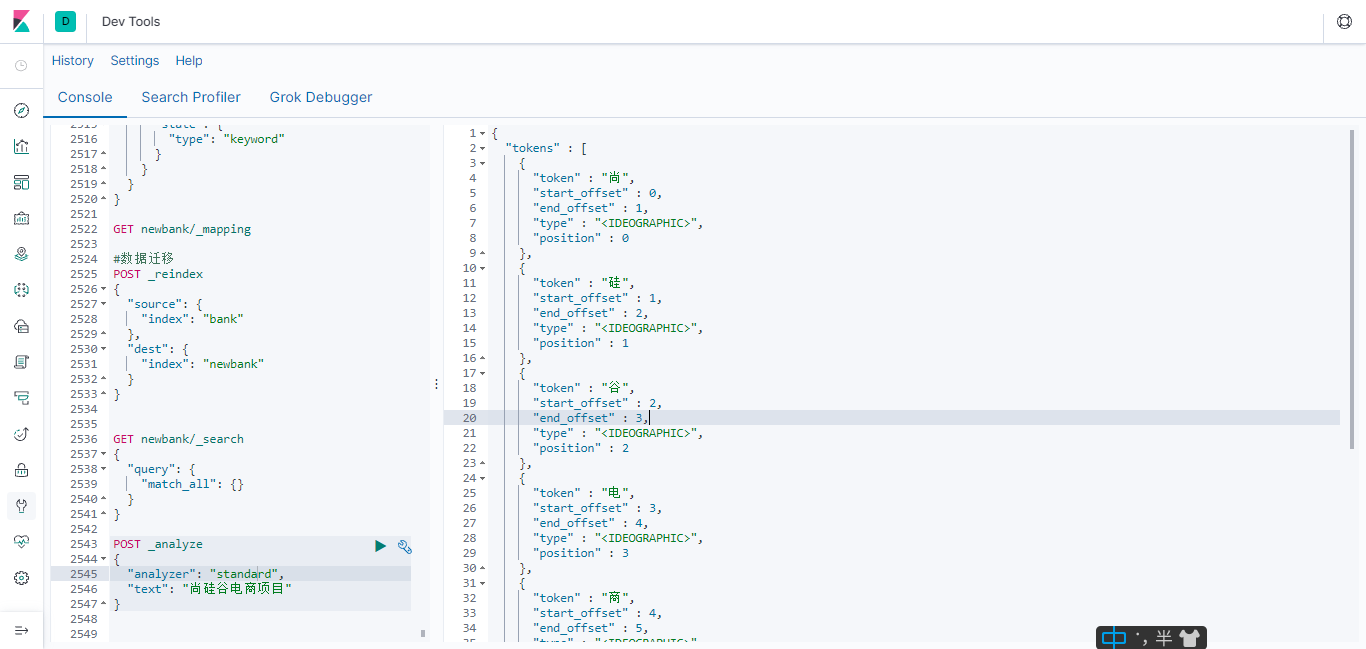
**注意: 不能用默认 elasticsearch-plugin install xxx.zip 进行自动安装 **
https://github.com/medcl/elasticsearch-analysis-ik/releases?after=v6.4.2 对应 es 版本安装 (此处选用的7.4.2版本)
- 由于之前映射了plugins目录,所以在/mydata/elasticsearch/plugins/下载elasticsearch-analysis-ik-7.4.2.zip
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.2/elasticsearch-analysis-ik-7.4.2.zip
- 解压下载的文件
unzip elasticsearch-analysis-ik-7.4.2.zip
- 删除zip文件
rm –rf *.zip
- 将elasticsearch文件夹下的所有文件 移动至ik目录下(自建目录)
mv elasticsearch/ ik
- 确认是否安装好了分词器
#进入容器内部
docker exec -it 容器 id /bin/bash
#即可列出系统的分词器
cd ../bin
elasticsearch plugin list
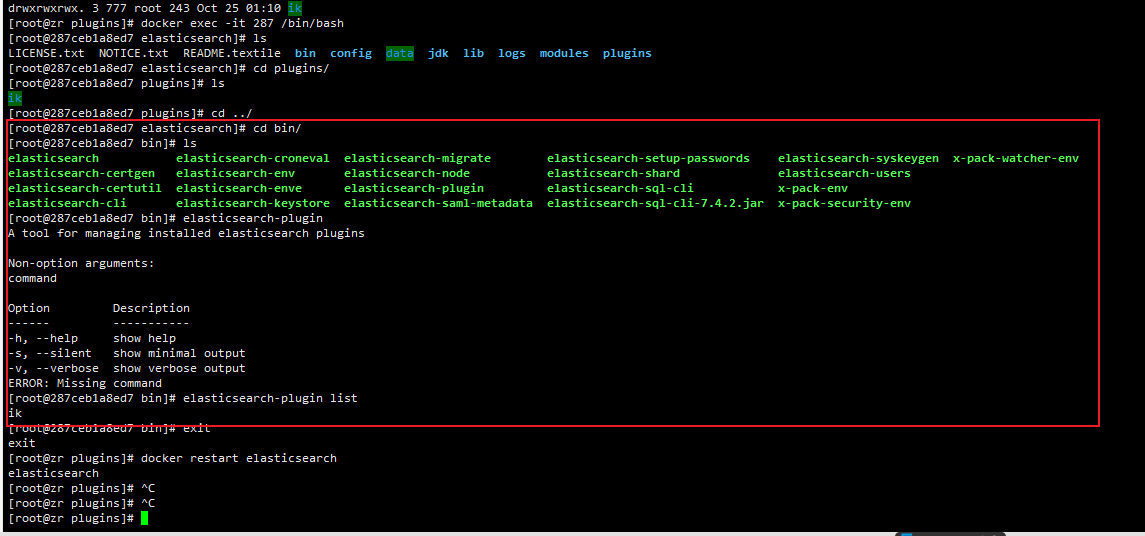
- 发现ik后重启容器
docker restart elasticsearch
6.4.2 测试分词器
6.4.2.1使用默认分词器
#使用默认分词器
POST _analyze
{
"text": "我是中国人"
}
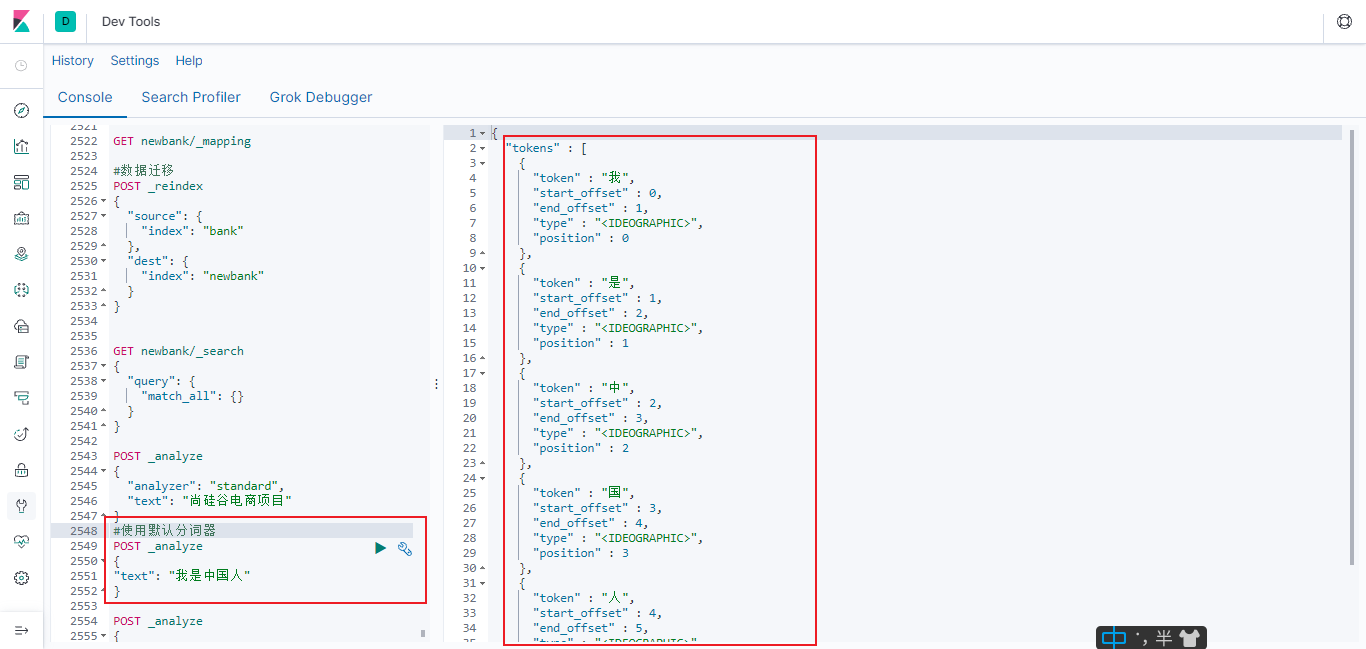
6.4.2.2 使用ik_smart 分词器
POST _analyze
{
"analyzer": "ik_smart",
"text": "我是中国人"
}
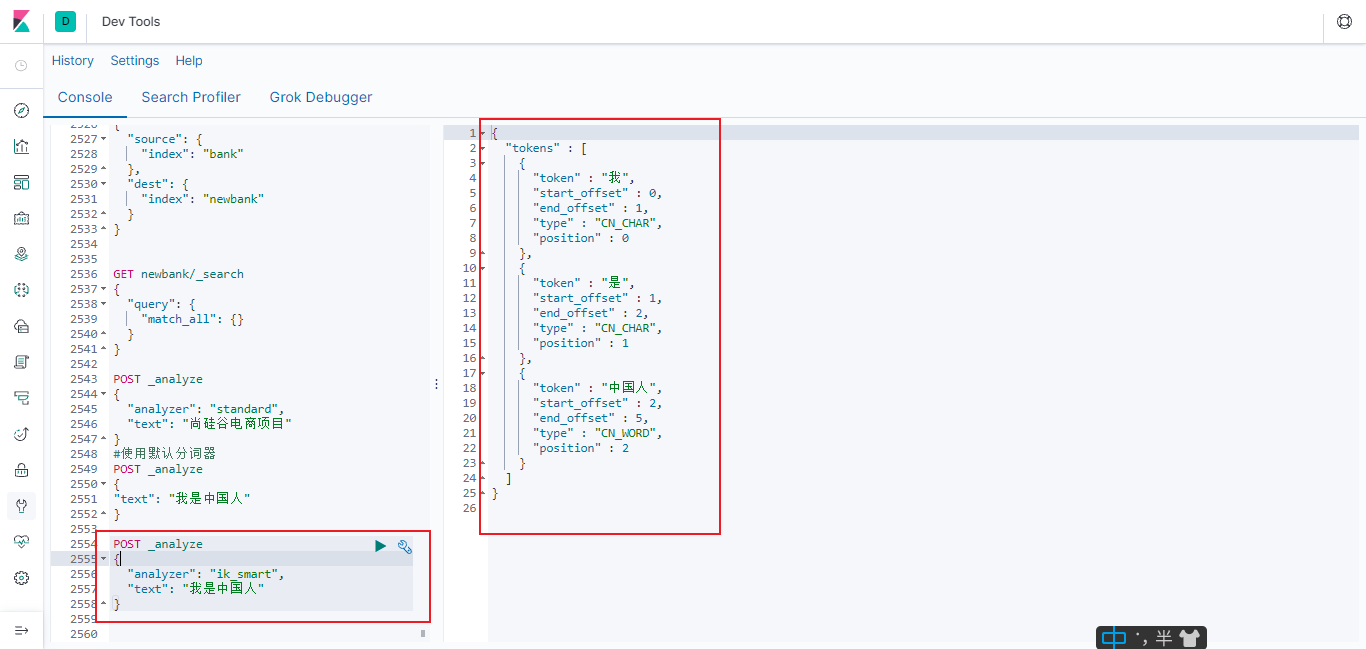
6.4.2.3 使用ik_max_word 分词器
#使用ik_max_word 分词器
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
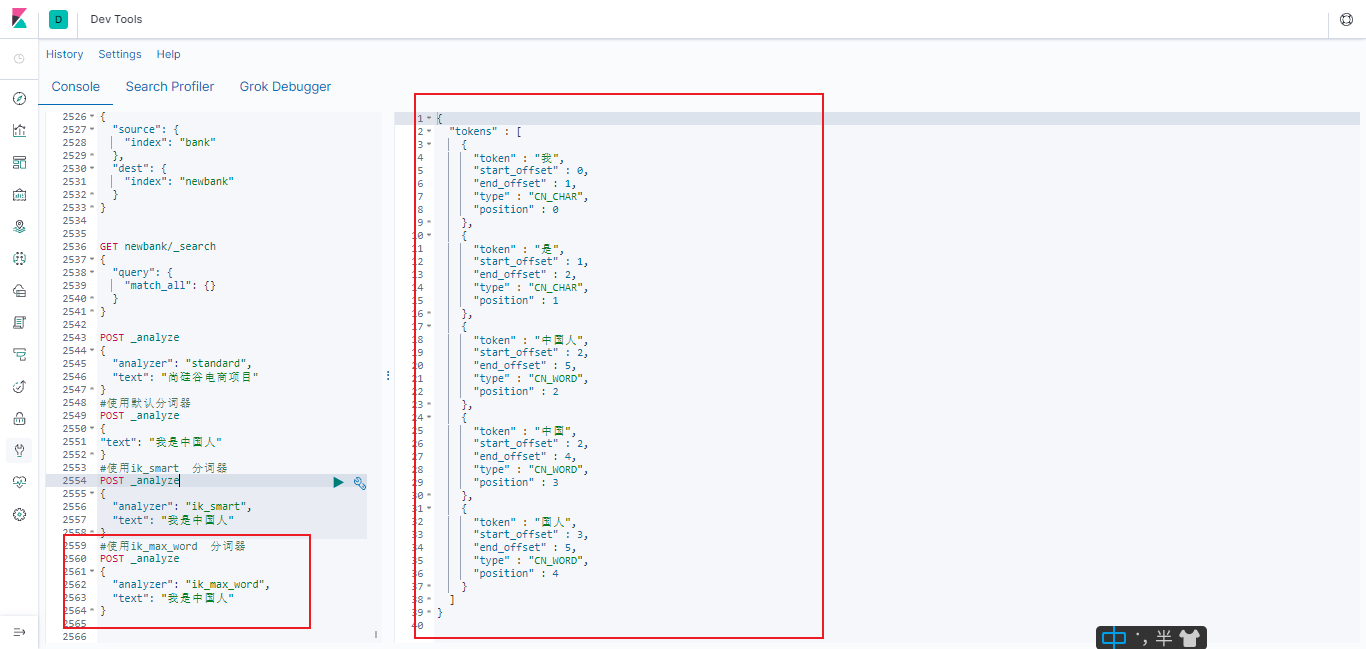
6.4.2.4总结
能够看出不同的分词器, 分词有明显的区别, 所以以后定义一个索引不能再使用默认的 mapping 了, 要手工建立 mapping, 因为要选择分词器。
6.4.4.自定义词库
6.4.4.1 未自定义词库
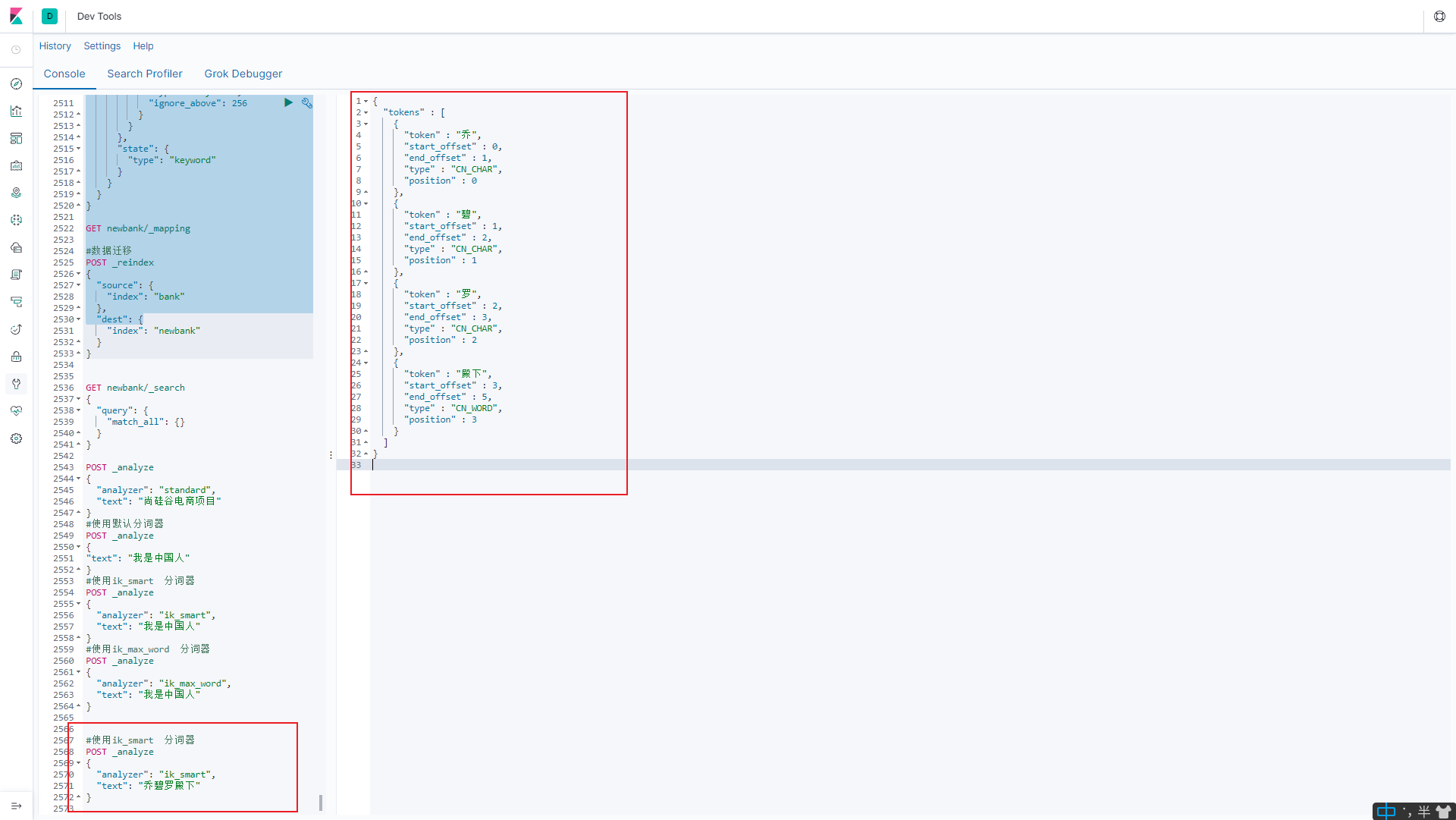
6.4.4.2 自定义词库测试
6.4.4.2.1 创建词库
在搭建好nginx的基础上,搭建nginx在8.x章节
cd /mydata/nginx/html/
#创建自定义词库
vim fenci.txt
添加新词

6.4.4.2.1 自定义词库
修改分词器的配置文件
vim /mydata/elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml
指定自定义词库地址
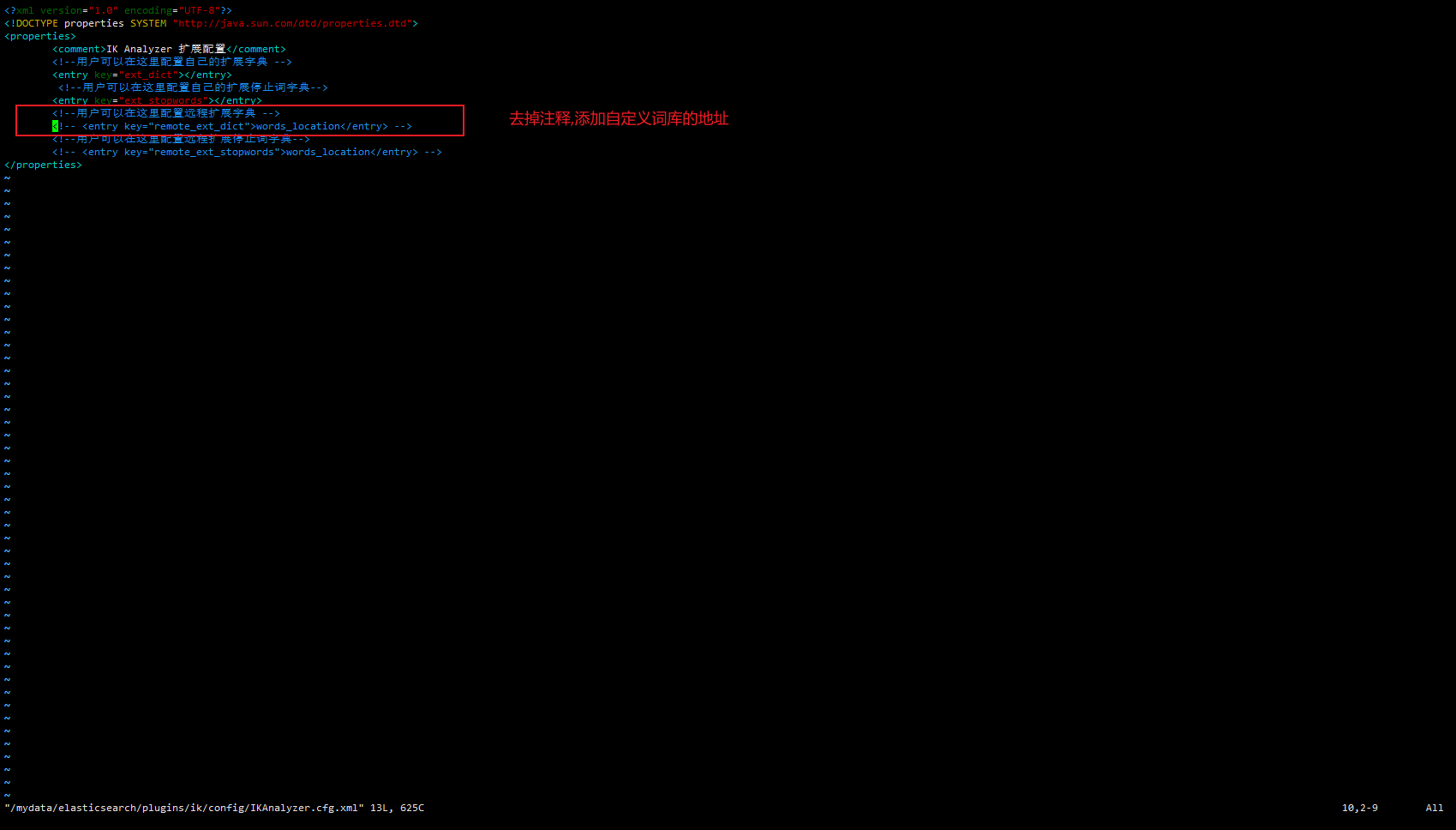

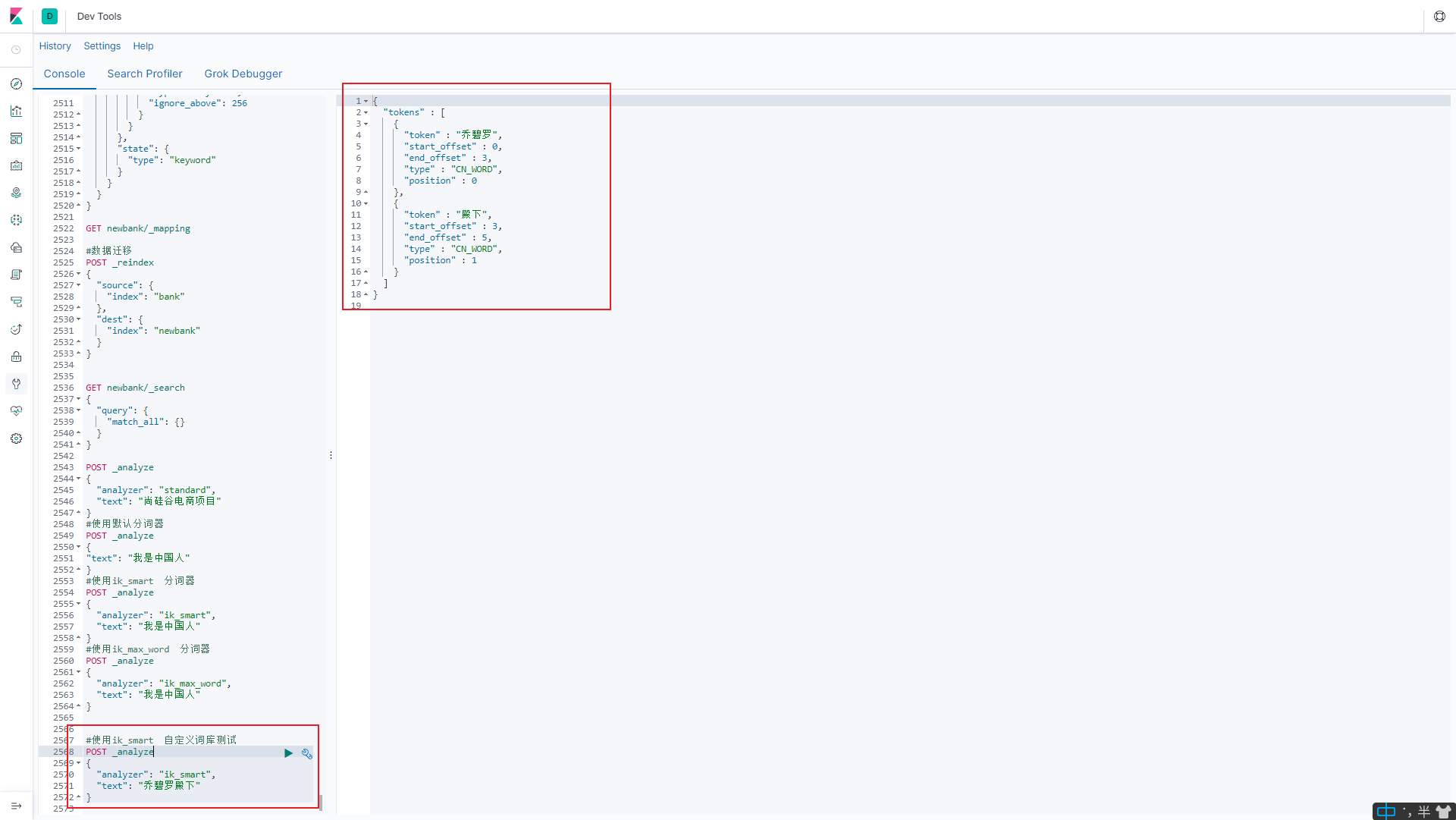
重启es
docker restart elasticsearch
测试结果
7.Elasticsearch-Rest-Client
7.1 为什么选择Elasticsearch-Rest-Client
9300: TCP
- spring-data-elasticsearch:transport-api.jar;
- springboot 版本不同, transport-api.jar 不同, 不能适配 es 版本
- 7.x 已经不建议使用, 8 以后就要废弃
9200: HTTP
- JestClient: 非官方, 更新慢
- RestTemplate: 模拟发 HTTP 请求, ES 很多操作需要自己封装, 麻烦
- HttpClient: 同上
- Elasticsearch-Rest-Client: 官方 RestClient, 封装了 ES 操作, API 层次分明, 上手简单
最终选择 Elasticsearch-Rest-Client(elasticsearch-rest-high-level-client)
为什么选择用高阶?
低阶与高阶的区别就像是jdbc与mybatis的区别
7.2 SpringBoot整合
7.2.1 新增模块gulimall-search
启动类
package site.zhourui.gilimall.search;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
@EnableDiscoveryClient
@SpringBootApplication(exclude = DataSourceAutoConfiguration.class)
public class GulimallSearchApplication {
public static void main(String[] args) {
SpringApplication.run(GulimallSearchApplication.class, args);
}
}
pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.1.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>site.zhourui.gulimall</groupId>
<artifactId>gulimall-search</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>gulimall-search</name>
<description>ElasticSearch检索服务</description>
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.4.2</elasticsearch.version>
<spring-cloud.version>Hoxton.SR9</spring-cloud.version>
</properties>
<dependencies>
<dependency>
<groupId>com.zhourui.gulimall</groupId>
<artifactId>gulimall-common</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.4.2</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
<version>2.2.0.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
7.2.2 新增配置类
gulimall-search/src/main/java/site/zhourui/gilimall/search/config/GulimallElasticSearchConfig.java
package site.zhourui.gilimall.search.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author zr
* @date 2021/10/25 14:27
*/
@Configuration
public class GulimallElasticSearchConfig {
//全局通用设置项,单实例singleton,构建授权请求头,异步等信息
public static final RequestOptions COMMON_OPTIONS;
static {
RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();
// builder.addHeader("Authorization","Bearer"+TOKEN);
// builder.setHttpAsyncResponseConsumerFactory(
// new HttpAsyncResponseConsumerFactory.HeapBufferedResponseConsumerFactory(30*1024*1024*1024));
COMMON_OPTIONS = builder.build();
}
@Bean
public RestHighLevelClient esRestClient() {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("192.168.157.128", 9200, "http")));
return client;
}
}
7.2.3 测试
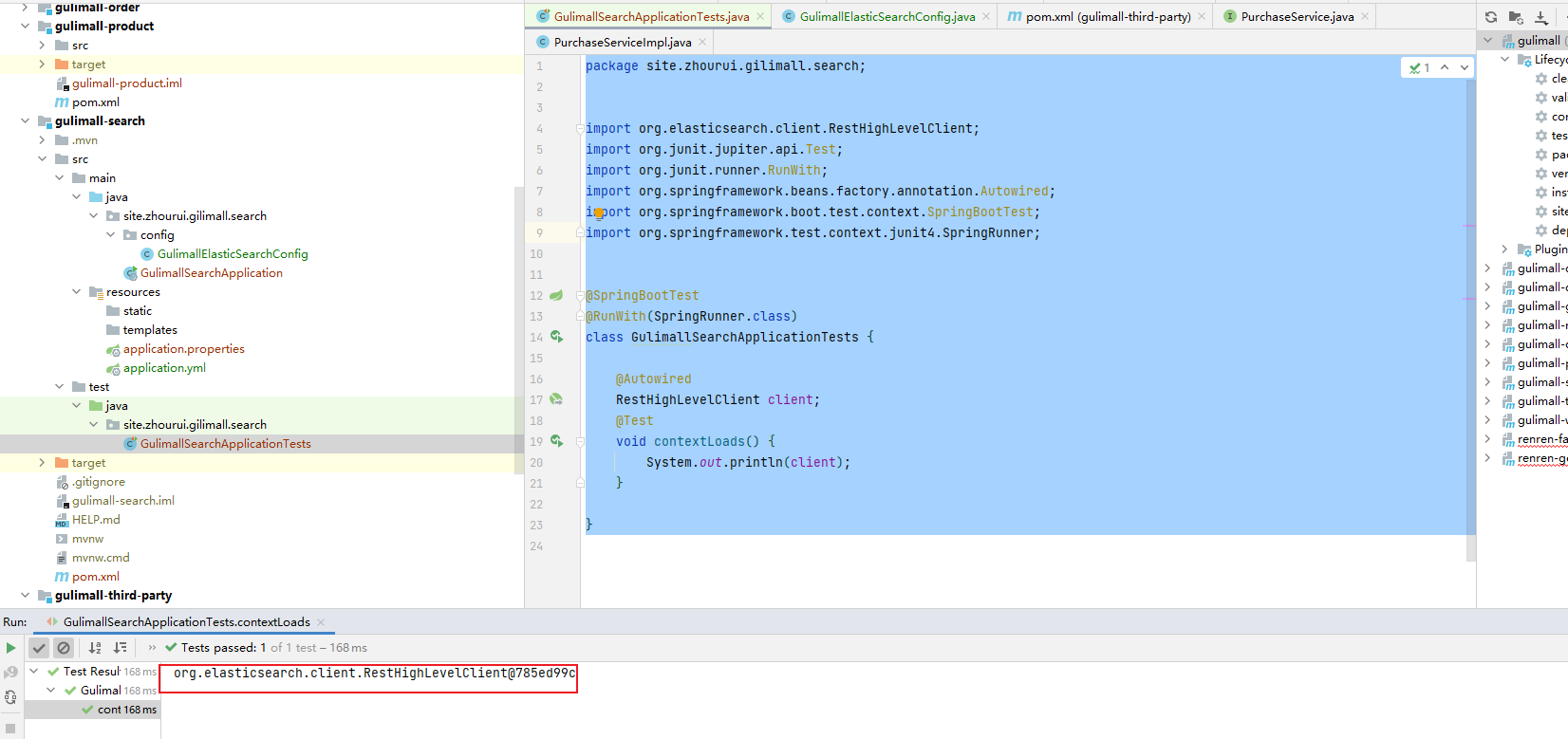
gulimall-search/src/test/java/site/zhourui/gilimall/search/GulimallSearchApplicationTests.java
package site.zhourui.gilimall.search;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.jupiter.api.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
@SpringBootTest
@RunWith(SpringRunner.class)
class GulimallSearchApplicationTests {
@Autowired
RestHighLevelClient client;
@Test
void contextLoads() {
System.out.println(client);
}
}
测试结果
7.3 使用
7.3.1 索引(新增) 数据
gulimall-search/src/test/java/site/zhourui/gilimall/search/GulimallSearchApplicationTests.java
package site.zhourui.gilimall.search;
import com.alibaba.fastjson.JSON;
import lombok.Data;
import org.apache.catalina.User;
import org.apache.ibatis.ognl.JavaSource;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import site.zhourui.gilimall.search.config.GulimallElasticSearchConfig;
import java.io.IOException;
@SpringBootTest
@RunWith(SpringRunner.class)
class GulimallSearchApplicationTests {
@Autowired
RestHighLevelClient client;
/**
* 测试索引到es
*/
@Test
void index() throws IOException {
IndexRequest request = new IndexRequest("users");//索引名
request.id("1");//文档id
User user = new User();
user.setUserName("张三");
user.setAge(18);
user.setGender("男");
String jsonString = JSON.toJSONString(user);
request.source(jsonString,XContentType.JSON);//要保存的内容
//执行操作
IndexResponse index = client.index(request, GulimallElasticSearchConfig.COMMON_OPTIONS);
//提取有用的响应数据
System.out.println(index);
}
@Data
class User{
private String userName;
private Integer age;
private String gender;
}
@Test
void contextLoads() {
System.out.println(client);
}
}
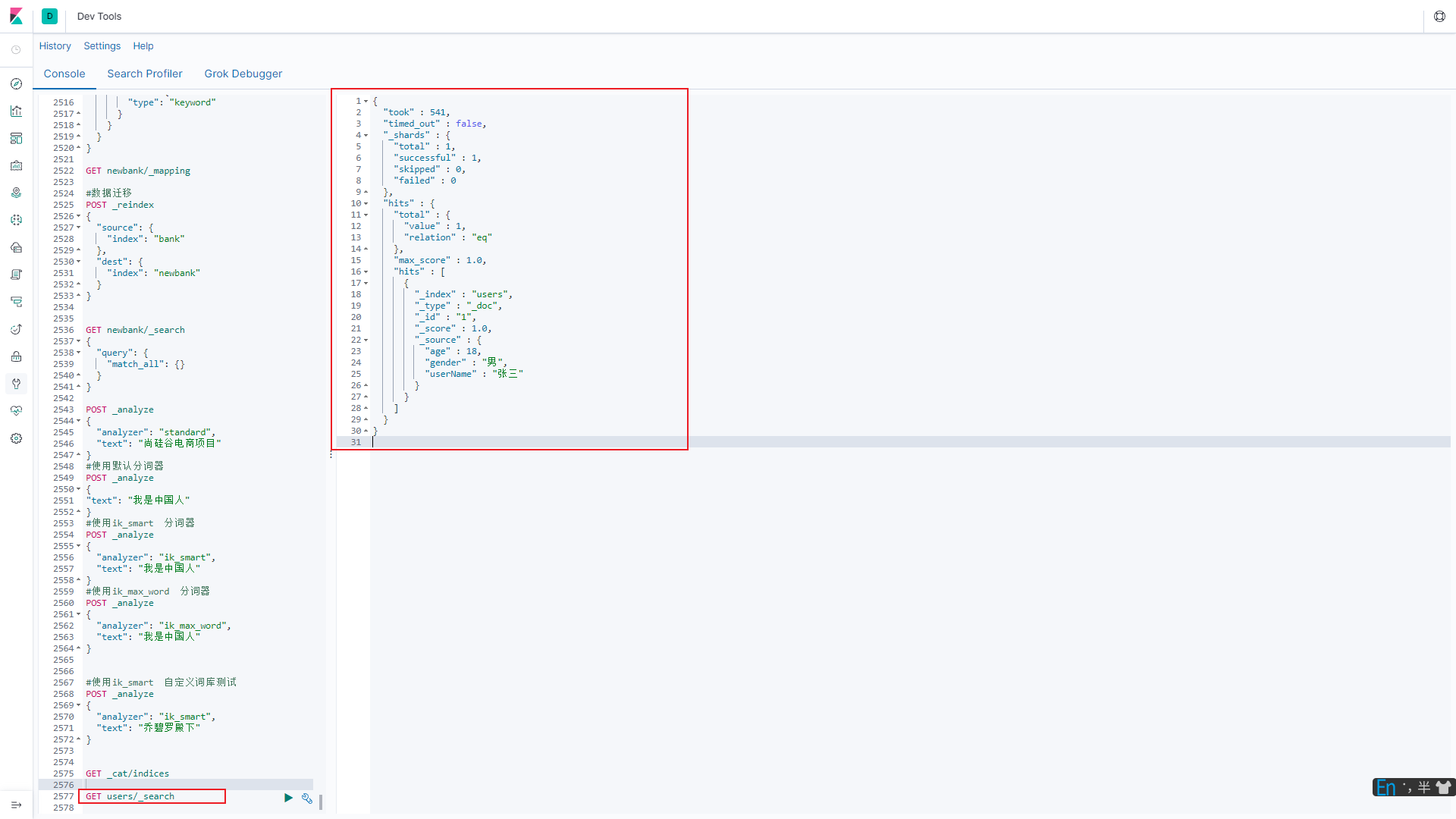
成功索引
7.3.2 获取数据
/**
* 测试查询es
* @throws IOException
*/
@Test
void search() throws IOException {
//创建索引请求
SearchRequest searchRequest = new SearchRequest();
//指定索引
searchRequest.indices("bank");
//指定DSL,检索条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("address","mill"));
//构造检索条件
// searchSourceBuilder.query();
// searchSourceBuilder.from();
// searchSourceBuilder.size();
// searchSourceBuilder.aggregation();
searchRequest.source(searchSourceBuilder);
//执行检索
SearchResponse searchResponse = client.search(searchRequest, GulimallElasticSearchConfig.COMMON_OPTIONS);
//分析结果 searchResponse
System.out.println(searchResponse);
}
searchResponse查询结果
与
#match 字符串类型全文检索 GET bank/_search { "query": { "match": { "address": "mill" } } }查询出的结果一致
{
"took": 15,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 5.4032025,
"hits": [{
"_index": "bank",
"_type": "account",
"_id": "970",
"_score": 5.4032025,
"_source": {
"account_number": 970,
"balance": 19648,
"firstname": "Forbes",
"lastname": "Wallace",
"age": 28,
"gender": "M",
"address": "990 Mill Road",
"employer": "Pheast",
"email": "forbeswallace@pheast.com",
"city": "Lopezo",
"state": "AK"
}
}, {
"_index": "bank",
"_type": "account",
"_id": "136",
"_score": 5.4032025,
"_source": {
"account_number": 136,
"balance": 45801,
"firstname": "Winnie",
"lastname": "Holland",
"age": 38,
"gender": "M",
"address": "198 Mill Lane",
"employer": "Neteria",
"email": "winnieholland@neteria.com",
"city": "Urie",
"state": "IL"
}
}, {
"_index": "bank",
"_type": "account",
"_id": "345",
"_score": 5.4032025,
"_source": {
"account_number": 345,
"balance": 9812,
"firstname": "Parker",
"lastname": "Hines",
"age": 38,
"gender": "M",
"address": "715 Mill Avenue",
"employer": "Baluba",
"email": "parkerhines@baluba.com",
"city": "Blackgum",
"state": "KY"
}
}, {
"_index": "bank",
"_type": "account",
"_id": "472",
"_score": 5.4032025,
"_source": {
"account_number": 472,
"balance": 25571,
"firstname": "Lee",
"lastname": "Long",
"age": 32,
"gender": "F",
"address": "288 Mill Street",
"employer": "Comverges",
"email": "leelong@comverges.com",
"city": "Movico",
"state": "MT"
}
}]
}
}
7.3.3 聚合查询
7.3.3.1 年龄分布
/**
* 测试聚合查询es
* @throws IOException
*/
@Test
void aggSearch1() throws IOException {
//创建索引请求
SearchRequest searchRequest = new SearchRequest();
//指定索引
searchRequest.indices("bank");
//指定DSL,检索条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("address","mill"));
//聚合条件
TermsAggregationBuilder ageAgg = AggregationBuilders.terms("ageAgg").field("age").size(10);
//在检索条件中增加聚合条件
searchSourceBuilder.aggregation(ageAgg);
//构造检索条件
// searchSourceBuilder.query();
// searchSourceBuilder.from();
// searchSourceBuilder.size();
// searchSourceBuilder.aggregation();
searchRequest.source(searchSourceBuilder);
//执行检索
SearchResponse searchResponse = client.search(searchRequest, GulimallElasticSearchConfig.COMMON_OPTIONS);
//分析结果 searchResponse
System.out.println(searchResponse);
}
查询结果
与
#aggregations 执行聚合 #年龄分布及平均值 聚合 GET bank/_search { "query": { "bool": { "must": [ {"match": { "address": "Mill" }} ] } }, "aggs": { "group_by_state": { "terms": { "field": "age", "size": 10 } } }, "size": 0 }查询出的结果一致
{
"took": 19,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 5.4032025,
"hits": [{
"_index": "bank",
"_type": "account",
"_id": "970",
"_score": 5.4032025,
"_source": {
"account_number": 970,
"balance": 19648,
"firstname": "Forbes",
"lastname": "Wallace",
"age": 28,
"gender": "M",
"address": "990 Mill Road",
"employer": "Pheast",
"email": "forbeswallace@pheast.com",
"city": "Lopezo",
"state": "AK"
}
}, {
"_index": "bank",
"_type": "account",
"_id": "136",
"_score": 5.4032025,
"_source": {
"account_number": 136,
"balance": 45801,
"firstname": "Winnie",
"lastname": "Holland",
"age": 38,
"gender": "M",
"address": "198 Mill Lane",
"employer": "Neteria",
"email": "winnieholland@neteria.com",
"city": "Urie",
"state": "IL"
}
}, {
"_index": "bank",
"_type": "account",
"_id": "345",
"_score": 5.4032025,
"_source": {
"account_number": 345,
"balance": 9812,
"firstname": "Parker",
"lastname": "Hines",
"age": 38,
"gender": "M",
"address": "715 Mill Avenue",
"employer": "Baluba",
"email": "parkerhines@baluba.com",
"city": "Blackgum",
"state": "KY"
}
}, {
"_index": "bank",
"_type": "account",
"_id": "472",
"_score": 5.4032025,
"_source": {
"account_number": 472,
"balance": 25571,
"firstname": "Lee",
"lastname": "Long",
"age": 32,
"gender": "F",
"address": "288 Mill Street",
"employer": "Comverges",
"email": "leelong@comverges.com",
"city": "Movico",
"state": "MT"
}
}]
},
"aggregations": {
"lterms#ageAgg": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [{
"key": 38,
"doc_count": 2
}, {
"key": 28,
"doc_count": 1
}, {
"key": 32,
"doc_count": 1
}]
}
}
}
7.3.4获取查询结果(转为对象)
具体结果在下面那个hits里

利用json生成javabean,并使用lombok
/**
* Auto-generated: 2021-10-25 16:57:49
*
* @author bejson.com (i@bejson.com)
* @website http://www.bejson.com/java2pojo/
*/
@Data
@ToString
public static class Accout {
private int account_number;
private int balance;
private String firstname;
private String lastname;
private int age;
private String gender;
private String address;
private String employer;
private String email;
private String city;
private String state;
}
/**
* 测试聚合查询es
* @throws IOException
*/
@Test
void aggSearch1() throws IOException {
//创建索引请求
SearchRequest searchRequest = new SearchRequest();
//指定索引
searchRequest.indices("bank");
//指定DSL,检索条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("address","mill"));
//聚合条件
TermsAggregationBuilder ageAgg = AggregationBuilders.terms("ageAgg").field("age").size(10);
//在检索条件中增加聚合条件
searchSourceBuilder.aggregation(ageAgg);
//构造检索条件
// searchSourceBuilder.query();
// searchSourceBuilder.from();
// searchSourceBuilder.size();
// searchSourceBuilder.aggregation();
searchRequest.source(searchSourceBuilder);
//执行检索
SearchResponse searchResponse = client.search(searchRequest, GulimallElasticSearchConfig.COMMON_OPTIONS);
//分析结果 searchResponse
System.out.println(searchResponse);
//获取所有查询结果
SearchHits hits = searchResponse.getHits();
SearchHit[] searchHits = hits.getHits();
for (SearchHit searchHit : searchHits) {
// searchHit.getId();
// searchHit.getIndex();
// searchHit.getType();
//转为json字符串
String sourceAsString = searchHit.getSourceAsString();
Accout accout = JSON.parseObject(sourceAsString, Accout.class);
System.out.println(accout);
}
}
查询结果

8.安装nginx
8.1 随便启动一个 nginx 实例, 只是为了复制出配置
#创建一个空文件夹
cd /mydata/
mkdir nginx
#启用nginx实例
#没有nginx镜像会自动下载并启动
docker run -p 80:80 --name nginx -d nginx:1.10
8.2 将容器内的配置文件拷贝到当前目录
#当前目录为mydata
docker container cp nginx:/etc/nginx .
8.3修改文件名称
#修改文件名
mv nginx conf
#新建一个nginx文件夹
mkdir nginx
#将config文件夹复制到nginx下
mv conf nginx/
8.4 删除原容器:
#停止原容器
docker stop nginx
#删除原容器
docker rm 容器id
8.5 创建新的nginx
docker run -p 80:80 --name nginx \
-v /mydata/nginx/html:/usr/share/nginx/html \
-v /mydata/nginx/logs:/var/log/nginx \
-v /mydata/nginx/conf:/etc/nginx \
-d nginx:1.10
访问:192.168.157.128虚拟机地址
搭建成功了,只是没有访问文件

新建一个hello word文件
vim index.html


测试通过
