SARC: Sequential Prefetching in Adaptive Replacement Cache
1.1 常见问题
(1)、同步预读引发的未命中问题
最简单的顺序预读策略是同步预取,在顺序读轨迹数据块n未命中时会触发将数据块n至n + m带入高速缓存中,其中m被称为顺序预读度,并且是可调参数。考虑使用m = 1的众所周知的一个块预读方案。该方案将连续未命中的次数减少了1/2。概括地说,通过m个数据块的的预读,连续未命中的数量减少了1 /(m + 1)。为了仅通过使用同步预取来消除未命中,就需要变得无限。这是不切实际的,因为提前预取得太多会导致缓存污染,并最终降低性能。
(2)、缓存淘汰引发的未命中问题
预取和缓存管理是相互交织的,不能孤立地加以研究。在实践中,最广泛使用的缓存管理在线策略是LRU,它根据访问的最近性维护一个双链接的轨道列表。在顺序预取的情况下,当磁道被预取或访问时,它们被放置在MRU(最近使用的)末端。并且,对于缓存替换,轨道将从列表的LRU末端被逐出。当系统中存在多组预读时,当前预取组中未访问的轨道将保持在它们在LRU列表中的位置,因此,在某些情况下,可能会靠近LRU列表的末尾,因此可能会发生一些未访问的数据块在被访问之前就被逐出缓存,从而导致顺序丢失。因此,当给顺序预取数据的缓存空间增加时,顺序遗漏并不一定会减少。
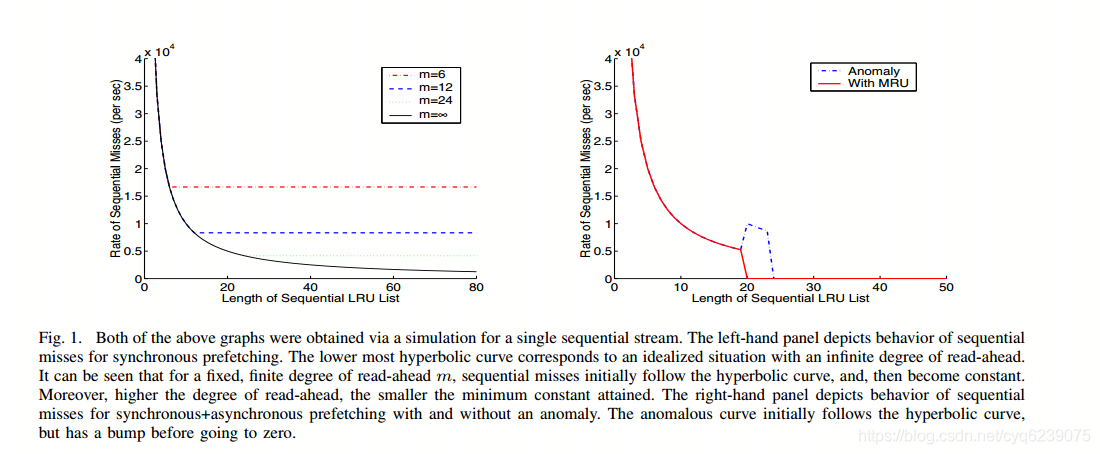
上面的两个图都是通过单个连续流的模拟获得的。 左侧面板描述了用于同步预读的顺序丢失的行为。 最下部的曲线对应于具有无限预读程度的理想情况。可以看出,对于固定的有限度的预读m,顺序未命中率首先遵循曲线,然后变为常数。 此外,预读程度越高,获得的最小常数越小。 右侧面板描述了在有和没有异常的情况下,同步+异步预读的顺序丢失的行为。 异常曲线最初遵循曲线,但在变为零之前有一个凸起
1.2 SARC解决方案
1.2.1 顺序预读
顺序检测的目标是自动发现顺序访问模式。这样的模式不容易发现,因为各种顺序流之间可能存在交错,并且单个流在连续请求之间可能会暂停,即请求之间的等待时间。
SARC方案中识别顺序的基本思想是维护每个跟踪的顺序检测计数器,并使用参数seqthreshold,该参数可以根据需要设置。计数器更新如下。对计数器未初始化的数据块n的命中或未命中,如果数据块n−1在缓存中存在,那么将数据块n的计数器设置为seqthreshold或数据块n-1的计数器值+1这两者中的最小值,如果数据块n−1在缓存中不存在,将数据块n的计数器设置为1。
一旦初始化,磁道的计数器值就不会更改,除非它被淘汰后重新进入缓存。当计数器等于seqThreshold时,该轨迹称为顺序轨迹。如果一个数据块在顺序轨迹上但是未命中,那么我们就认为发生了一个顺序丢失错误。
当达到预读门限seqthreshold后同步预读第一组数据,当访问到预读的一组数据的预设部分时,异步(即在没有顺序丢失的情况下)预读下一组数据,依此类推。通常,异步预读是在异步触发器上完成的,即在预读的磁道组中的特殊数据块。
1.2.2 缓存置换
SARC的缓存置换是一种自适应、自调优、低开销的算法,在顺序和随机数据之间动态地划分缓存空间的数量,以最小化总体漏报率。由于顺序预取页面和随机数据本质上是不同的,因此很自然地将这两种类型的数据分开。如图2所示,我们将在单独的LRU列表中管理每个类:RANDOM和SEQ。我们的目标之一是避免随机页面被较不宝贵的预取页面替换或预读页面在使用之前被过早替换从而引发抖动。
SARC的算法中的一个关键思想是为SEQ列表保持所需的大小(参见图2)。如果淘汰SEQ中的数据块就可以满足所需的大小,则从SEQ的LRU端驱逐磁道;否则,将从RANDOM的LRU端被逐出。SEQ需要的尺寸是不断调整的。

1.2.3 计算SEQ边际效用
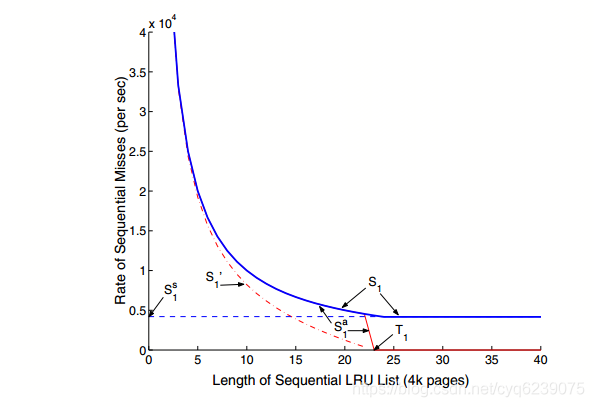
令L以4K页的数量表示列表SEQ的长度。 为了计算SEQ的边际效用,我们检查了顺序缺失的总速率如何响应L中的小变化ΔL而变化,即∆s。通过SEQ的堆栈特性,随着L的增加(分别减小) 减少(分别增加)。 因此,∆s / ∆L始终为负。

我们选择2s / L来近似表示SEQ的边际效用。
1.2.4 计算RANDOM边际效用
RANDOM列表仅包含按需分配的数据。 对于按需申请的数据,LRU是一种堆栈算法。 换句话说,增加(或减少)列表的长度会导致较少(或较大)的未命中数。 令r表示RANDOM中的高速缓存未命中率。为了计算RANDOM的边际效用,我们记录r的变化,即∆r。L的变化∆L。随着L的增加(减少)r减少(增加)。 因此,∆r / ∆L始终为负。边际效用通过该数量的大小来衡量。 与SEQ不同,对于RANDOM列表,可以直接通过实时缓存来估计数量∆r / ∆L。
监视RANDOM列表中bottom部分∆L缓存(见图2),并观察该区域的命中率∆r。如果未将底部的缓存空间ΔL分配给RANDOM,则未命中率r将增加∆r。但是为RANDOM分配更多的缓存空间将从SEQ中夺走相等的数量, 因此需要仔细权衡。 当两个列表的边际效用均等时,可以达到最佳效果。
1.2.5边际效用取值
将RANDOM底部ΔL的大小固定为缓存大小的一小部分恒定值。 该算法的本质是比较的绝对值

如果2s/ L大于∆r / ∆L的大小,则将缓存空间从RANDOM的底部转移到SEQ的底部会更有利,因此我们会增加所需的SEQ大小; 否则,我们将减小所需的SEQ大小。
该公式中∆r和s的时间间隔尚未确定。 时间间隔越小,算法就越具有自适应性,而时间间隔越大,适应性就越平滑且越慢。 我们的算法会根据缓存命中数隐式选择一个时间间隔。具体来说,我们将时间间隔选择为RANDOM列表bottom部分两次连续命中之间的时间差。 在这种情况下,∆r只是一个常数1,我们在相同的时间间隔内测量s。 因此,我们现在需要简单地比较。
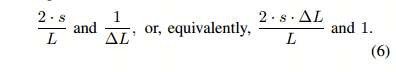
1.2.6 判断是否命中bottom部分
![]()
1.2.7 流程分析


