一、循环优化
- Pipeline:流水线操作
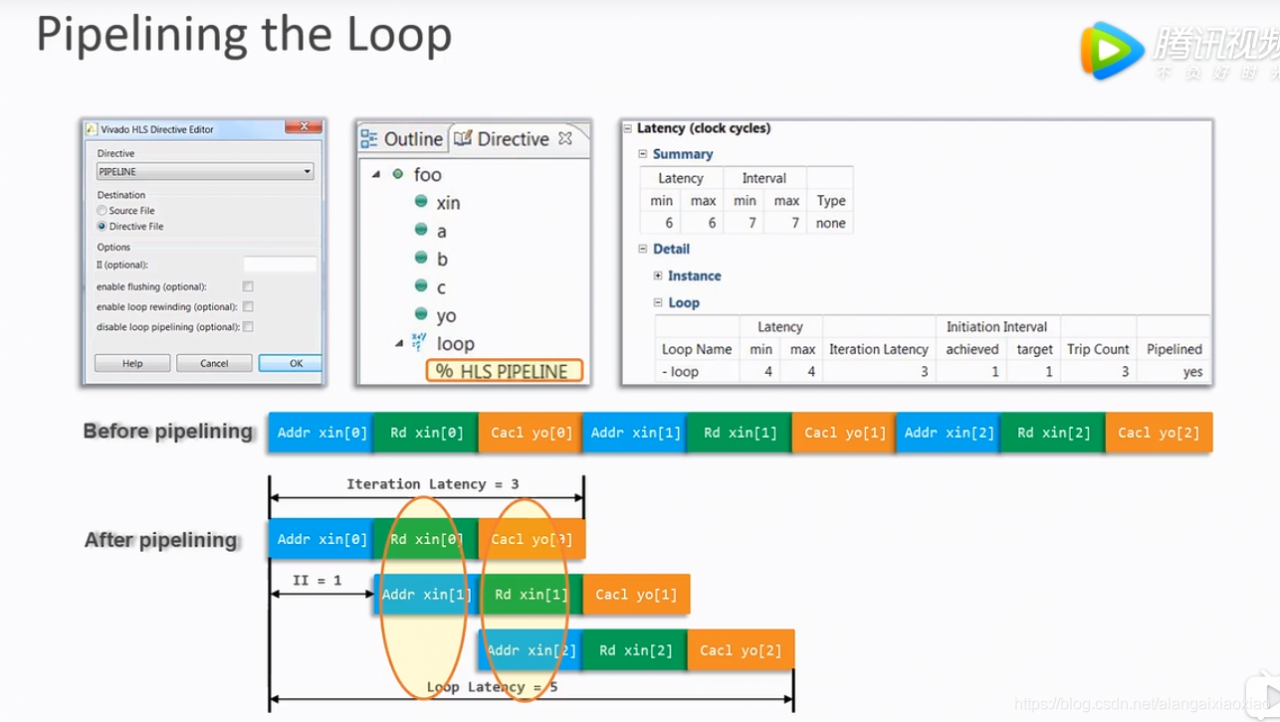
iteration latency:每次循环迭代所需要的时钟周期数
Initiation Interval(II):两次迭代之间的时钟间隔;
2.Unroll:循环展开
每一个循环都时分复用同一个电路,循环展开相当于把该电路进行逻辑复制。
指令:#pragma HLS unroll factor = 2
如果没有指明优化factor=N,则表示该循环完全展开。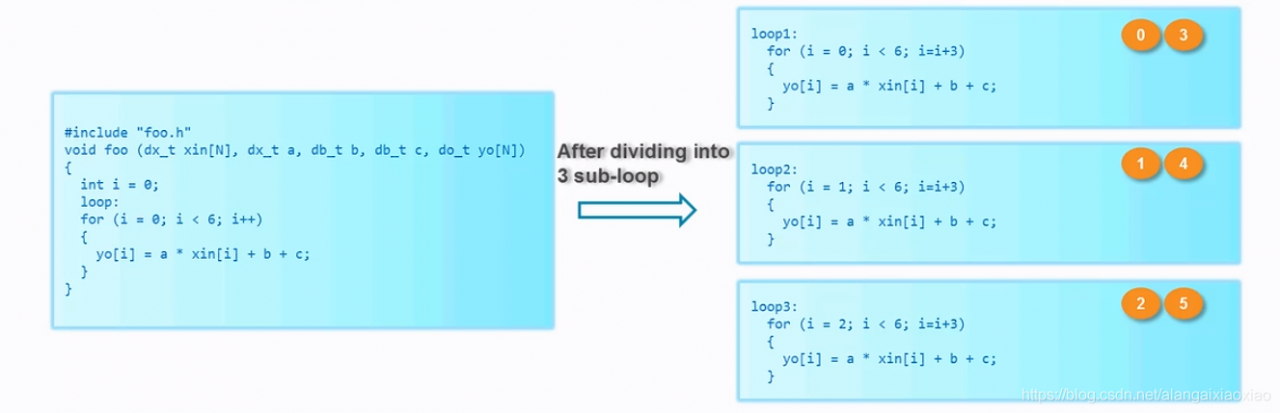
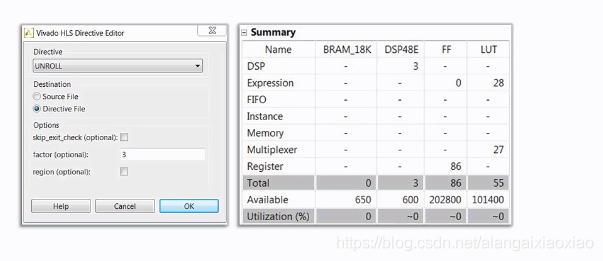
factor表示把该循环体的逻辑资源复制了几份;
2. 循环变量
讲循环变量i设置为int(32位)或者是ap_int<4>(4位),整个的资源不受任何影响,在综合编译时,HLS考虑的是i的最大值,根据最大值进行相应的资源规划。
二、数组分割 ARRAY_PARTITION
Block:整体的分
cyclic:交叉的分
complete:数组分为单独的元素进行操作
当分开多元数组的时候,dimension选项用于具体数组分成的维度。
三、工程中经常用到的优化策略
3.1 ARRAY_PARTITION
int a[n];
#pragma HLS ARRAY_PARTITION variable=a complete dim=1
将数组完全分块,即在硬件中实现为多个register,而不实现为block ram;
即使是多维数组,在完全分块时,dim = 1;
3.2 UNROLL
指令:#pragma HLS unroll factor = 2
如果没有指明优化factor=N,则表示该循环完全展开。
for(t1 = 0;t1 < Tn;t1++)
{
#pragma HLS UNROLL
a[i] = b[i] + c;
}
在硬件中,相当于逻辑电路复制;
3.3 PIPELINE
指令:#pragma HLS PIPELINE
两次的循环可以公用时钟周期,不需要等到这次循环完成了,再进行下一次的循环迭代。
Initiation Interval(II):两次迭代之间的时钟间隔;
iteration latency:每次循环迭代所需要的时钟周期数
#pragma HLS PIPELINE II=1
默认II= 1
3.4 DEPENDENCE
#pragma HLS DEPENDENCE variable=output_buffer inter false
Inter:(迭代间相关)指定dependency是存在于同一个循环的不同的迭代之中
如果进行这个指令指明false,则HLS会将循环进行并行化处理。
Intra:(迭代内相关)指定dependence是在一个循环迭代之中。例如一个数组会在iteration的开始和结束被access
当intradependencies被指明为false时,HLS就会将loop中间的operation进行自由的移动。
当在同一个循环中,同一个变量(不同偏移的数组变量)存在读写情况时,当读和写操作在前一个读和写操作之后被执行,则认为是具有dependencies,例如:
for(tm = 0;tm < Tm;tm++){
tmp_add_result = output_buffer[tm][tr][tc];//line 8
......
output_buffer[tm][tr][tc] = tmp_add_result + tmp_add12;//line 9
}
此时,编译器认为line 8和line 9的output_buffer[tm][tr][tc]具有依赖关系。如果loop之间有dependencies,则pipeline就不能进行。HLS DEPENDENCE可以为output_buffer提供额为的信息,指明依赖关系不成立。可以进行如下优化:
#pragma HLS PIPELINE
for(tm = 0;tm < Tm;tm++){
#pragma HLS DEPENDENCE variable=output_buffer inter false
tmp_add_result = output_buffer[tm][tr][tc];//line 8
......
output_buffer[tm][tr][tc] = tmp_add_result + tmp_add12;//line 9
}