使用工具:Python3.6版本
Python官网:https://www.python.org/
目录
Scrapy的安装
pip install Scrapy。在此之前需要先安装几个包:wheel、lxml以及twisted
cmd执行语句需要进入到对应的python根目录的Scripts文件夹下D:\hailong\Python3.6\Scripts
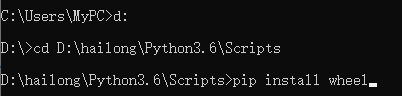
然后依次运行如下语句:
(1) pip install wheel
(2) pip install lxml
(3) pip install twisted
(4) 最后 pip install scrapy
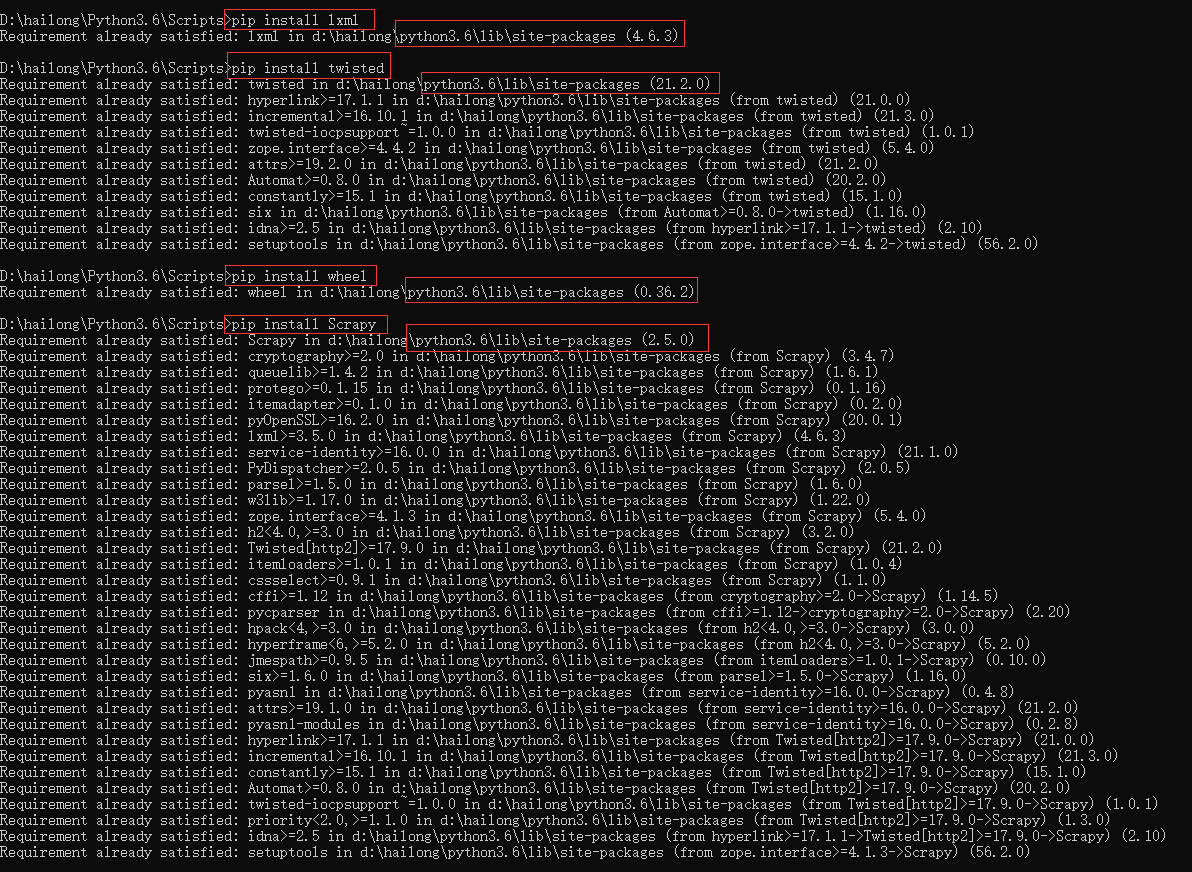
安装好的wheel、lxml、twisted、scrapy包都在此路径下D:\hailong\Python3.6\Lib\site-packages
(5) 验证Scrapy框架是否安装成功:
打开python,输入import scrapy和scrapy.version_info可以查看scrapy的版本信息

Scrapy爬取数据步骤
一、创建工程:
创建一个文件夹,任意命名,然后打开cmd进入该目录。
输入命令:Scrapy startproject movie

此时可以看到该目录下多了一个叫movie的文件夹

而movie文件夹下还有一个叫movie的文件夹
二、创建爬虫程序
用cd movie指令进入movie目录,输入命令:
Scrapy genspider meiju meijutt.tv
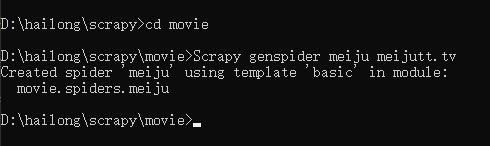
该命令创建了一个叫meiju的爬虫
这时查看spiders目录可以看到多了一个meiju.py,就是我们刚创建的爬虫。
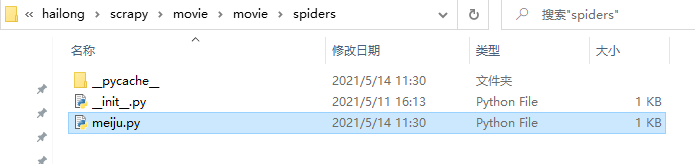
三、编辑爬虫
用代码编辑器打开meiju.py,进行如下编辑:
import scrapy
from movie.items import MovieItem
class MeijuSpider(scrapy.Spider):#继承这个类
name = 'meiju'#名字
allowed_domains = ['meijutt.tv']#域名
start_urls = ['https://www.meijutt.tv/new100.html']#要补充完整
# headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36'}
def parse(self, response):
print(888888888)#测试用
movies = response.xpath('//ul[@class="top-list fn-clear"]/li')#意思是选中所有的属性class值为"top-list fn-clear"的ul下的li标签内容
print(movies)#测试用
for each_movie in movies:
item = MovieItem()
item['name'] = each_movie.xpath('./h5/a/@title').extract()[0]
# .表示选取当前节点,也就是对每一项li,其下的h5下的a标签中title的属性值
yield item #一种特殊的循环
四、设置item模板
如图所示,在items.py中输入代码:
import scrapy
class MovieItem(scrapy.Item):
name = scrapy.Field()
五、设置配置文件
如图所示,在settings.py中输入代码:
ITEM_PIPELINES = {'movie.pipelines.MoviePipeline':100}
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 1
六、设置数据处理脚本
如图所示,在pipelines.py中输入代码:
from itemadapter import ItemAdapter
class MoviePipeline:
def process_item(self, item, spider):
return item
七、运行爬虫
运行之前建议检查各行缩进,尤其是:之后的缩进,因为python对语法的缩进非常严格。
运行cmd,进入到爬虫根目录,也就是D:\hailong\scrapy\newmovie\movie下(带scrapy.cfg文件的文件夹下)

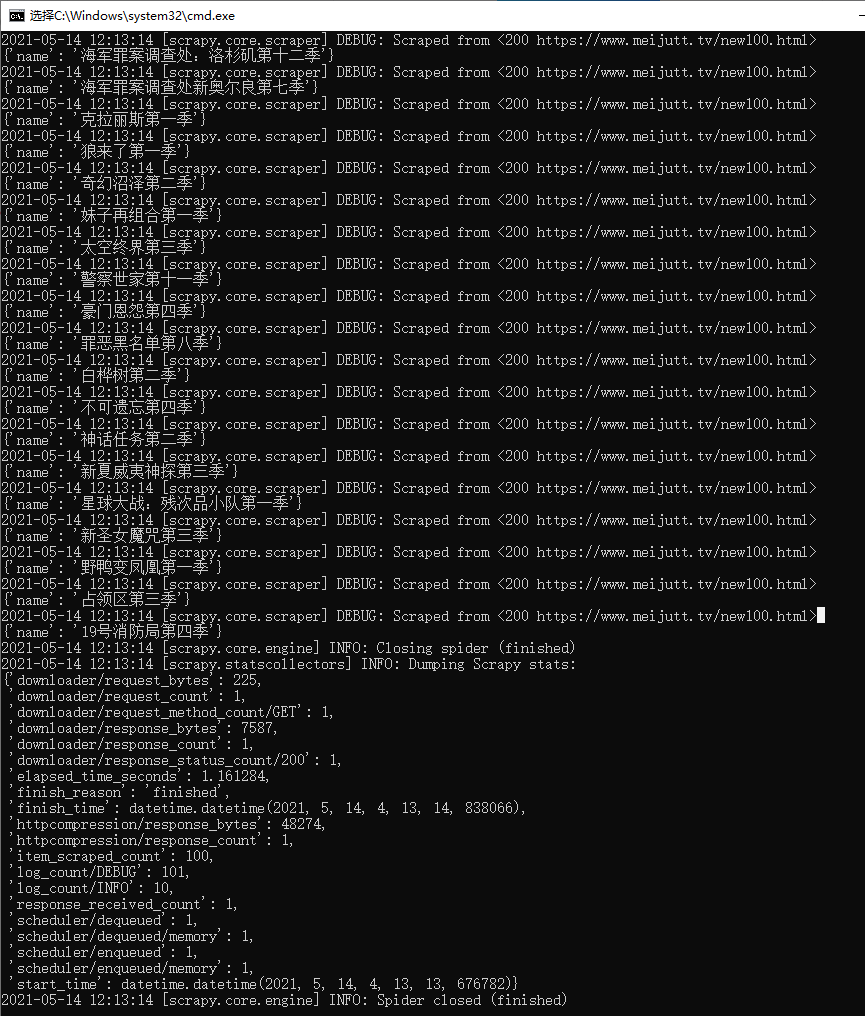
执行命令:Scrapy crawl meiju
然后发现未能获取到信息,问题报错信息解决来源:https://ask.csdn.net/questions/7428925?spm=1001.2014.3001.5501
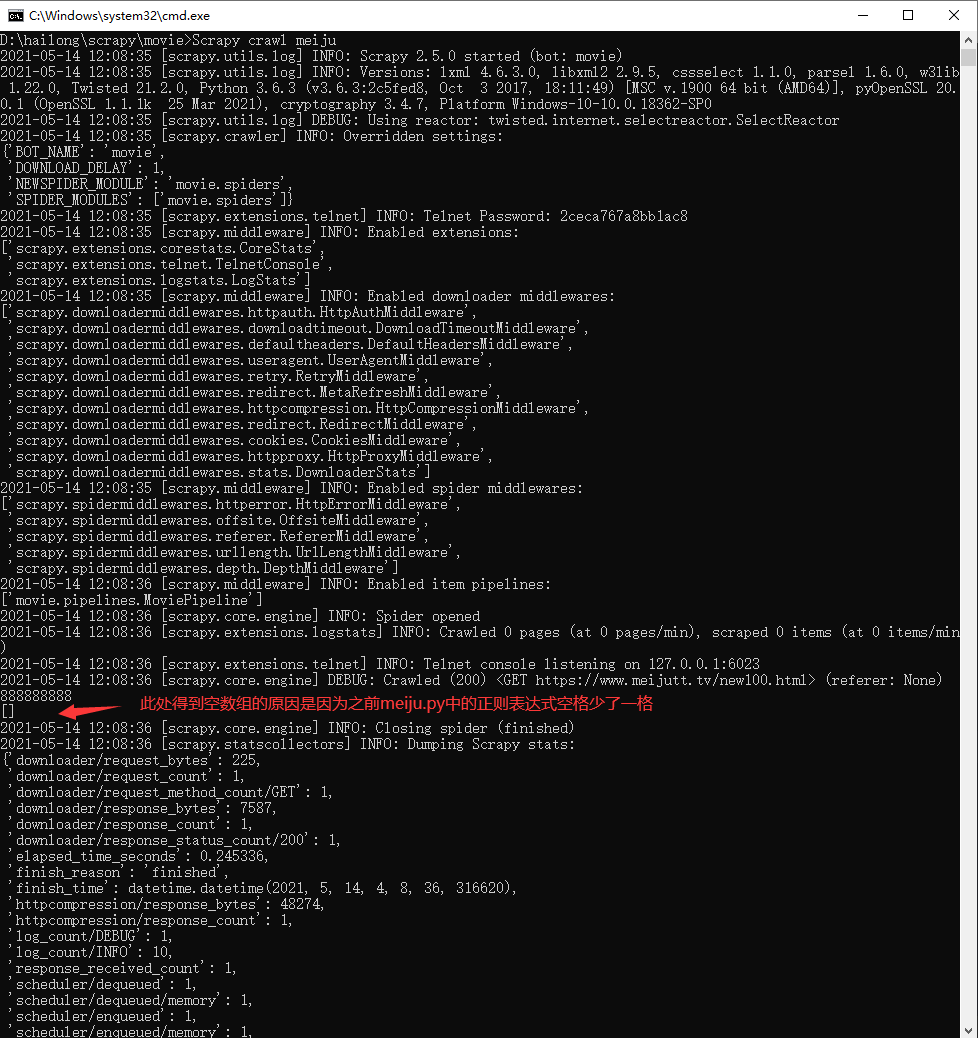
修改之后再执行Scrapy crawl meiju,发现有获取到信息