LinkNet
《LinkNet:Exploiting Encoder Representations for Efficient Semantic Segmentation》
作者:Abhishek Chaurasia,etc;
单位:普渡大学
发表会议及时间:IEEE 2017
https://arxiv.org/abs/1707.03718
一 论文导读
二 论文精读
三 代码实现
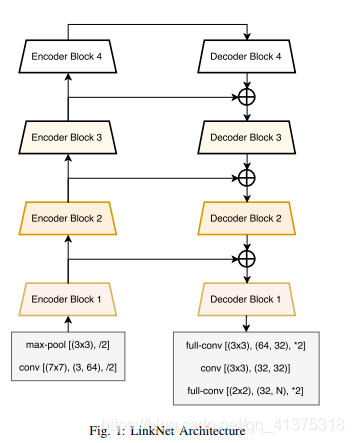
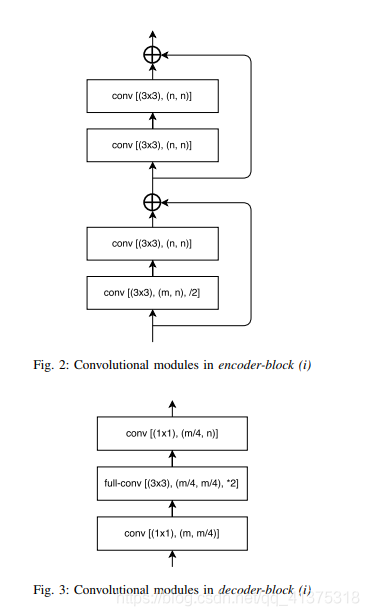
import torch.nn as nn
from torchvision import models
import torch
class BasicBlock(nn.Module):
def __init__(self, in_planes, out_planes, stride=1, padding=0, bias=False):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_planes, out_planes, 3, stride, padding, bias=bias)
self.bn1 = nn.BatchNorm2d(out_planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(out_planes, out_planes, 3, 1, padding, bias=bias)
self.bn2 = nn.BatchNorm2d(out_planes)
self.downsample = None
if stride > 1:
self.downsample = nn.Sequential(nn.Conv2d(in_planes, out_planes, 3, stride, bias=False),
nn.BatchNorm2d(out_planes),)
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class Encoder(nn.Module):
def __init__(self, in_planes, out_planes, stride=1, padding=0, bias=False):
super(Encoder, self).__init__()
self.block1 = BasicBlock(in_planes, out_planes, stride, padding, bias)
self.block2 = BasicBlock(out_planes, out_planes, 1, padding, bias)
def forward(self, x):
x = self.block1(x)
x = self.block2(x)
return x
class Decoder(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, output_padding=0, bias=False):
# TODO bias=True
super(Decoder, self).__init__()
self.conv1 = nn.Sequential(nn.Conv2d(in_planes, in_planes//4, 1, 1, 0, bias=bias),
nn.BatchNorm2d(in_planes//4),
nn.ReLU(inplace=True),)
self.tp_conv = nn.Sequential(nn.ConvTranspose2d(in_planes//4, in_planes//4, kernel_size, stride, padding, output_padding, bias=bias),
nn.BatchNorm2d(in_planes//4),
nn.ReLU(inplace=True),)
self.conv2 = nn.Sequential(nn.Conv2d(in_planes//4, out_planes, 1, 1, 0, bias=bias),
nn.BatchNorm2d(out_planes),
nn.ReLU(inplace=True),)
def forward(self, x):
x = self.conv1(x)
x = self.tp_conv(x)
x = self.conv2(x)
return x
class linknet(nn.Module):
def __init__(self, n_classes=12):
super(linknet, self).__init__()
base = models.resnet18(pretrained=False)
self.in_block = nn.Sequential(
base.conv1,
base.bn1,
base.relu,
base.maxpool
)
self.encoder1 = base.layer1
self.encoder2 = base.layer2
self.encoder3 = base.layer3
self.encoder4 = base.layer4
self.decoder1 = Decoder(64, 64, 3, 1, 1, 0)
self.decoder2 = Decoder(128, 64, 3, 2, 1, 1)
self.decoder3 = Decoder(256, 128, 3, 2, 1, 1)
self.decoder4 = Decoder(512, 256, 3, 2, 1, 1)
# Classifier
self.tp_conv1 = nn.Sequential(nn.ConvTranspose2d(64, 32, 3, 2, 1, 1),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),)
self.conv2 = nn.Sequential(nn.Conv2d(32, 32, 3, 1, 1),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),)
self.tp_conv2 = nn.ConvTranspose2d(32, n_classes, 2, 2, 0)
def forward(self, x):
# Initial block
print('x:', x.size())
x = self.in_block(x);print('x:', x.size())
# Encoder blocks
e1 = self.encoder1(x);print('e1:', e1.size())
e2 = self.encoder2(e1);print('e2:', e2.size())
e3 = self.encoder3(e2);print('e3:', e3.size())
e4 = self.encoder4(e3);print('e4:', e4.size())
# Decoder blocks
d4 = e3 + self.decoder4(e4);print('d4:', d4.size())
d3 = e2 + self.decoder3(d4);print('d3:', d3.size())
d2 = e1 + self.decoder2(d3);print('d2:', d2.size())
d1 = x + self.decoder1(d2);print('d1:', d1.size())
# Classifier
y = self.tp_conv1(d1);print('y:', y.size())
y = self.conv2(y);print('y:', y.size())
y = self.tp_conv2(y);print('y:', y.size())
return y
# 随机生成输入数据
inputs = torch.randn((1, 3, 512, 512))
# 定义网络
net = linknet(n_classes=8)
# 前向传播
out = net(inputs)
# 打印输出大小
print('-----'*5)
print(out.size())
print('-----'*5)

四 问题思索
版权声明:本文为qq_41375318原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。