1.添加索引
示例代码1:
from elasticsearch import Elasticsearch
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
doc = {
"mappings": {
"properties": {
"grade": {
"type": "long"
},
"id": {
"type": "long"
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"sex": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"subject": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
# 创建索引
res = es.index(index="test_index", id=1, document=doc)
print(res)
print(res['result'])
# 创建索引
res2 = es.index(index='test_index2', document=doc)
print(res2)
运行结果:

示例代码2:
from elasticsearch import Elasticsearch
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
doc = {
"mappings": {
"properties": {
"grade": {
"type": "long"
},
"id": {
"type": "long"
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"sex": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"subject": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
# 创建索引
res = es.index(index="test_index", id=1, document=doc)
print(res)
print(res['result'])
print("*" * 100)
# 创建索引
res2 = es.index(index='test_index2', document=doc)
print(res2)
print(res2['result'])
print("*" * 100)
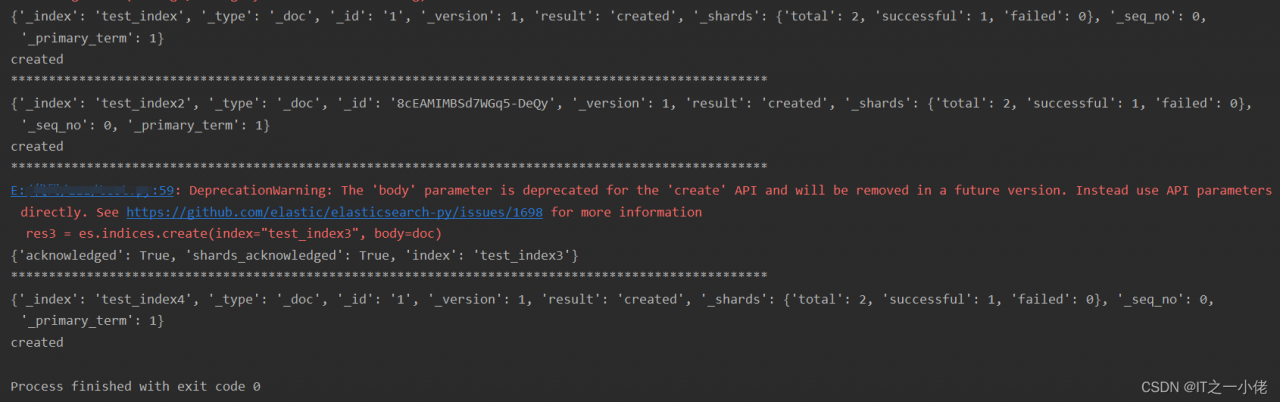
# 创建索引 res3运行两次会报错
res3 = es.indices.create(index="test_index3", body=doc)
print(res3)
# print(res3['result']) # 注意:此行运行会报错
print("*" * 100)
# 创建索引 res4多次执行会报错
res4 = es.create(index='test_index4', id=1, document=doc)
print(res4)
print(res4['result'])
运行结果:
示例代码3:
from elasticsearch import Elasticsearch
from datetime import datetime
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
doc = {
'author': 'dgw',
'text': 'Elasticsearch: cool. bonsai cool.',
'timestamp': datetime.now(),
}
res = es.index(index="test_index", id=1, document=doc)
print(res)
print(res['result'])
运行结果:

2.查询索引
示例代码:
from elasticsearch import Elasticsearch
from datetime import datetime
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
doc = {
'author': 'dgw',
'text': 'Elasticsearch: cool. bonsai cool.',
'timestamp': datetime.now(),
}
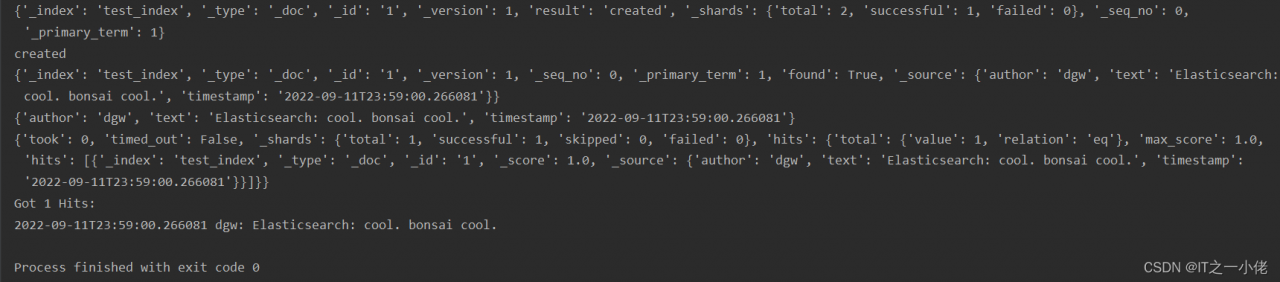
# 创建索引
res = es.index(index="test_index", id=1, document=doc)
print(res)
print(res['result'])
# 查询数据
res2 = es.get(index="test_index", id=1)
print(res2)
print(res2['_source'])
es.indices.refresh(index="test_index")
query = {
"match_all": {}
}
res3 = es.search(index='test_index', query=query)
print(res3)
print("Got %d Hits:" % res3['hits']['total']['value'])
for hit in res3['hits']['hits']:
print("%(timestamp)s %(author)s: %(text)s" % hit["_source"])
运行结果:
3.删除索引
示例代码:
from elasticsearch import Elasticsearch
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
# 判断索引是否存在,存在则删除索引
if es.indices.exists(index="test_index"):
print('test_index索引存在,即将删除')
es.indices.delete(index="test_index")
else:
print('test_index索引不存在!')
运行结果:

4.判断索引是否存在
为防止在创建索引的时候出现重复,产生错误,在创建之前最好判断一下索引是否存在。
示例代码:
from elasticsearch import Elasticsearch
es = Elasticsearch(hosts='http://47.93.5.86:9200')
# print(es)
doc = {
"mappings": {
"properties": {
"grade": {
"type": "long"
},
"id": {
"type": "long"
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"sex": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"subject": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
# 创建索引
res = es.index(index="test_index", id=1, document=doc)
print(res)
print(res['result'])
# 判断索引是否存在
es_exist = es.exists(index="test_index", id=2)
print(es_exist)
# 判断索引是否存在
es_exist = es.indices.exists(index='test_index')
print(es_exist)
运行结果:

5.添加数据
示例代码:
from elasticsearch import Elasticsearch
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
doc = {
'mappings': {
'properties': {
'name': {
'type': 'text'
},
'id': {
'type': 'integer'
},
}
}
}
# 判断索引是否存在,存在则删除索引
if es.indices.exists(index="test_index"):
print('test_index索引存在,即将删除')
es.indices.delete(index="test_index")
else:
print('索引不存在!可以创建')
# 创建索引
res = es.indices.create(index="test_index", body=doc)
print(res)
print("*" * 100)
# 添加数据
es.index(index="test_index", id='1', document={"name": "北京张三", "id": 1})
es.index(index="test_index", id='2', document={"name": "河北李四", "id": 2})
# 查询数据
res = es.get(index="test_index", id=1)
print(res)
运行结果:

6.查询数据
示例代码:
from elasticsearch import Elasticsearch
import time
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
doc = {
'mappings': {
'properties': {
'name': {
'type': 'text'
},
'id': {
'type': 'integer'
},
}
}
}
# 判断索引是否存在,存在则删除索引
if es.indices.exists(index="test_index"):
print('test_index索引存在,即将删除')
es.indices.delete(index="test_index")
else:
print('索引不存在!可以创建')
# 创建索引
res = es.indices.create(index="test_index", body=doc)
print(res)
print("*" * 100)
# 添加数据
es.index(index="test_index", id='1', document={"name": "北京张三", "id": 1})
es.index(index="test_index", id='2', document={"name": "河北李四", "id": 2})
es.index(index="test_index", id='3', document={"name": "北京王五", "id": 3})
time.sleep(1) # 如果不加时间停顿的话,下面查询的结果为空,上面添加数据需要时间
# 查询数据
# 使用get查询数据
res = es.get(index="test_index", id=1)
print(res)
print("*" * 100)
# 使用search查询数据
query1 = {
"query": {
"match_all": {}
},
"from": 0,
"size": 10
}
res2 = es.search(index="test_index", body=query1)
print(res2)
print("*" * 100)
# 精确查找term
query2 = {
"query": {
"term": {
"name": {
"value": "北"
}
}
}
}
res2 = es.search(index="test_index", body=query2)
print(res2)
print("*" * 100)
# 精确查找terms
query3 = {
"query": {
"terms": {
"name": [
"张",
"李"
]
}
}
}
res3 = es.search(index="test_index", body=query3)
print(res3)
print("*" * 100)
# 模糊查找match
query4 = {
"query": {
"match": {
"name": "京"
}
}
}
res = es.search(index="test_index", body=query4)
print(res)
print("*" * 100)
# 查询id和name包含
query5 = {
"query": {
"multi_match": {
"query": "张三",
"fields": ["name"]
}
}
}
res = es.search(index="test_index", body=query5)
print(res)
print("*" * 100)
# 搜索出id为1或者2的所有数据
query6 = {
"query": {
"ids": {
"type": "_doc",
"values": ["1", "2"]
}
}
}
res = es.search(index="test_index", body=query6)
print(res)
print("*" * 100)
运行结果:
test_index索引存在,即将删除
{'acknowledged': True, 'shards_acknowledged': True, 'index': 'test_index'}
****************************************************************************************************
{'_index': 'test_index', '_type': '_doc', '_id': '1', '_version': 1, '_seq_no': 0, '_primary_term': 1, 'found': True, '_source': {'name': '北京张三', 'id': 1}}
****************************************************************************************************
{'took': 0, 'timed_out': False, '_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0}, 'hits': {'total': {'value': 3, 'relation': 'eq'}, 'max_score': 1.0, 'hits': [{'_index': 'test_index', '_type': '_doc', '_id': '1', '_score': 1.0, '_source': {'name': '北京张三', 'id': 1}}, {'_index': 'test_index', '_type': '_doc', '_id': '2', '_score': 1.0, '_source': {'name': '河北李四', 'id': 2}}, {'_index': 'test_index', '_type': '_doc', '_id': '3', '_score': 1.0, '_source': {'name': '北京王五', 'id': 3}}]}}
****************************************************************************************************
{'took': 0, 'timed_out': False, '_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0}, 'hits': {'total': {'value': 3, 'relation': 'eq'}, 'max_score': 0.13353139, 'hits': [{'_index': 'test_index', '_type': '_doc', '_id': '1', '_score': 0.13353139, '_source': {'name': '北京张三', 'id': 1}}, {'_index': 'test_index', '_type': '_doc', '_id': '2', '_score': 0.13353139, '_source': {'name': '河北李四', 'id': 2}}, {'_index': 'test_index', '_type': '_doc', '_id': '3', '_score': 0.13353139, '_source': {'name': '北京王五', 'id': 3}}]}}
****************************************************************************************************
{'took': 0, 'timed_out': False, '_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0}, 'hits': {'total': {'value': 2, 'relation': 'eq'}, 'max_score': 1.0, 'hits': [{'_index': 'test_index', '_type': '_doc', '_id': '1', '_score': 1.0, '_source': {'name': '北京张三', 'id': 1}}, {'_index': 'test_index', '_type': '_doc', '_id': '2', '_score': 1.0, '_source': {'name': '河北李四', 'id': 2}}]}}
****************************************************************************************************
{'took': 0, 'timed_out': False, '_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0}, 'hits': {'total': {'value': 2, 'relation': 'eq'}, 'max_score': 0.4700036, 'hits': [{'_index': 'test_index', '_type': '_doc', '_id': '1', '_score': 0.4700036, '_source': {'name': '北京张三', 'id': 1}}, {'_index': 'test_index', '_type': '_doc', '_id': '3', '_score': 0.4700036, '_source': {'name': '北京王五', 'id': 3}}]}}
****************************************************************************************************
{'took': 0, 'timed_out': False, '_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0}, 'hits': {'total': {'value': 1, 'relation': 'eq'}, 'max_score': 1.9616582, 'hits': [{'_index': 'test_index', '_type': '_doc', '_id': '1', '_score': 1.9616582, '_source': {'name': '北京张三', 'id': 1}}]}}
****************************************************************************************************
{'took': 0, 'timed_out': False, '_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0}, 'hits': {'total': {'value': 2, 'relation': 'eq'}, 'max_score': 1.0, 'hits': [{'_index': 'test_index', '_type': '_doc', '_id': '1', '_score': 1.0, '_source': {'name': '北京张三', 'id': 1}}, {'_index': 'test_index', '_type': '_doc', '_id': '2', '_score': 1.0, '_source': {'name': '河北李四', 'id': 2}}]}}
****************************************************************************************************7.复合查询数据
示例代码:
from elasticsearch import Elasticsearch
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
query = {
"query": {
"bool": {
"must": [
{
"term": {
"name": {
"value": "张"
}
}
},
{
"term": {
"id": {
"value": "1"
}
}
}
]
}
}
}
res = es.search(index="test_index", body=query)
print(res)
运行结果:

8.切片查询数据
示例代码:
from elasticsearch import Elasticsearch
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
query = {
"query": {
"match_all": {}
},
"from": 0,
"size": 2
}
res = es.search(index="test_index", body=query)
print(res)
运行结果:

9.范围查询数据
示例代码:
from elasticsearch import Elasticsearch
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
query = {
"query": {
"range": {
"id": {
"gte": 1,
"lte": 2
}
}
}
}
res = es.search(index="test_index", body=query)
print(res)
运行结果:

10.前缀查询数据
示例代码:
from elasticsearch import Elasticsearch
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
# 查询前缀为“张”的数据。注意:这个要看分词后的前缀
query = {
"query": {
"prefix": {
"name": {
"value": "张"
}
}
}
}
res = es.search(index="test_index", body=query)
print(res)
运行结果:

11.通配符查询
示例代码:
from elasticsearch import Elasticsearch
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
# 查询前缀为“张”的数据。注意:这个要看分词后的前缀
query = {
"query": {
"wildcard": {
"name": {
"value": "三"
}
}
}
}
res = es.search(index="test_index", body=query)
print(res)
运行结果:

12.查询数据排序
示例代码:
from elasticsearch import Elasticsearch
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
# 查询前缀为“张”的数据。注意:这个要看分词后的前缀
query = {
"query": {
"match_all": {}
},
"sort": [
{
"id": {
"order": "desc" # asc升序,desc降序
}
}
]
}
res = es.search(index="test_index", body=query)
print(res)
运行结果:

版权声明:本文为weixin_44799217原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。