为什么引入非线性激励函数
如果不用激励函数,在这种情况下你每一层输出都是上层输入的线性函数,很容易验证,无论你有多少层神经网络,输出的都是输入的线性组合。
激活函数是用来加入非线性因素的,因为线性模型的表达能力不够。
以下,同种颜色为同类数据。某些数据是线性可分的,意思是,可以用一条直线将数据分开。比如下图: 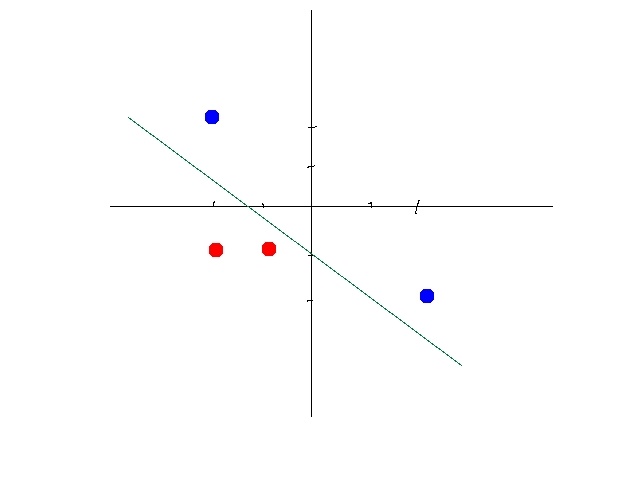
这时候你需要通过一定的机器学习的方法,比如感知机算法(perceptron learning algorithm) 找到一个合适的线性方程。
但是有些数据不是线性可分的。比如如下数据: 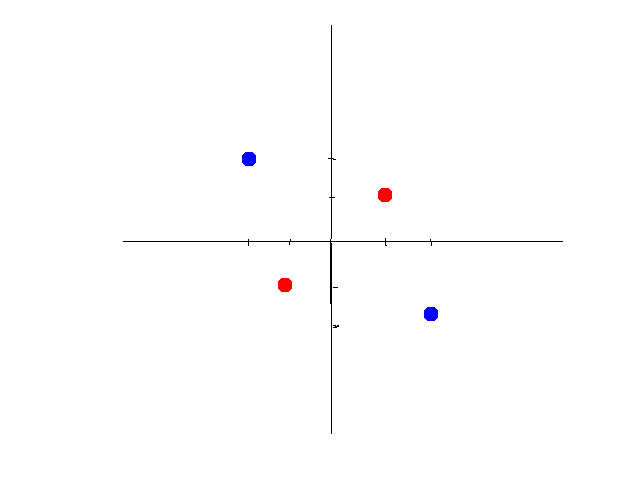
第二组数据你就没有办法画出一条直线来将数据区分开。
这时候有两个办法,第一个办法,是做线性变换(linear transformation),比如讲x,y变成x2,y2 x 2 , y 2,这样可以画出圆形。如图所示: 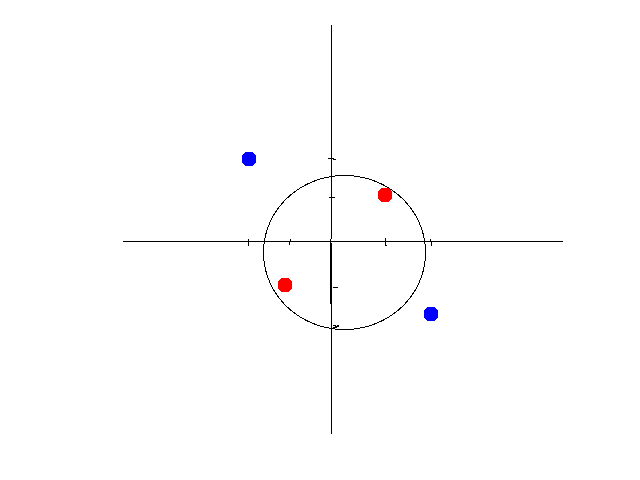
如果将坐标轴从x,y变为以x2,y2 x 2 , y 2为标准,你会发现数据经过变换后是线性可分的了。大致示意图如下: 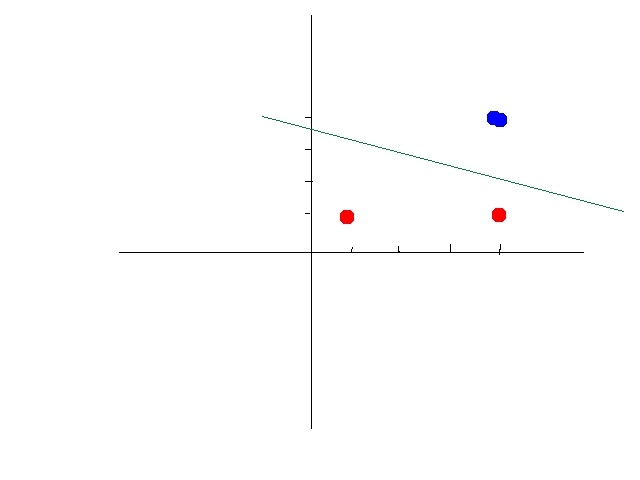
另外一种方法是引入非线性函数。我们来看异或问题(xor problem)。以下是xor真值表 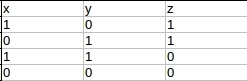
这个真值表不是线性可分的,所以不能使用线性模型,如图所示 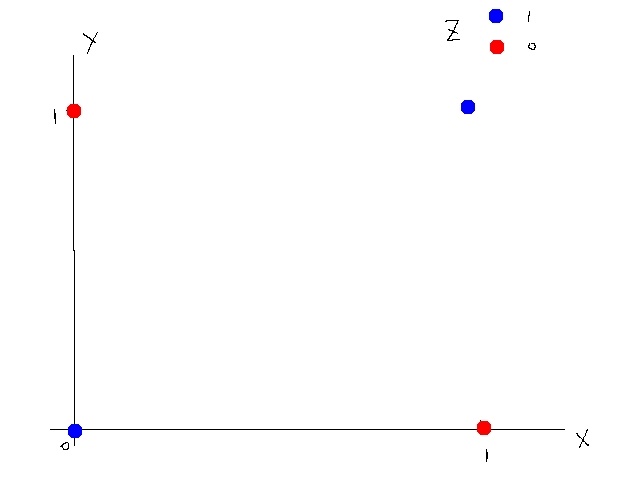
我们可以设计一种神经网络,通过激活函数来使得这组数据线性可分。
激活函数我们选择阀值函数(threshold function),也就是大于某个值输出1(被激活了),小于等于则输出0(没有激活)。这个函数是非线性函数。
神经网络示意图如下: 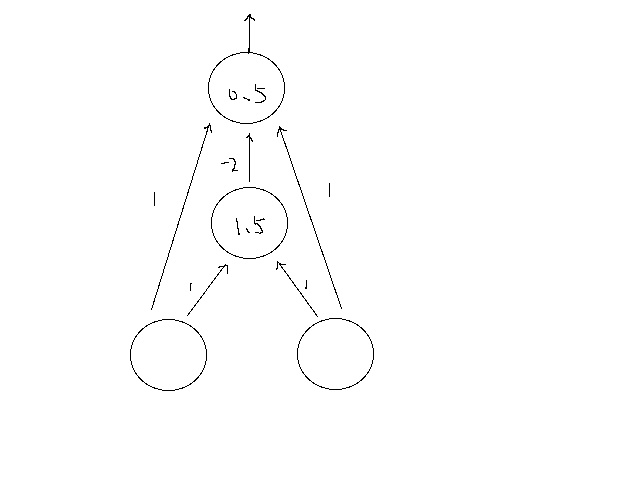
其中直线上的数字为权重。圆圈中的数字为阀值。第二层,如果输入大于1.5则输出1,否则0;第三层,如果输入大于0.5,则输出1,否则0.
我们来一步步算。
第一层到第二层(阀值1.5) 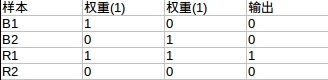
第二层到第三层(阀值0.5) 
可以看到第三层输出就是我们所要的xor的答案。
经过变换后的数据是线性可分的(n维,比如本例中可以用平面),如图所示: 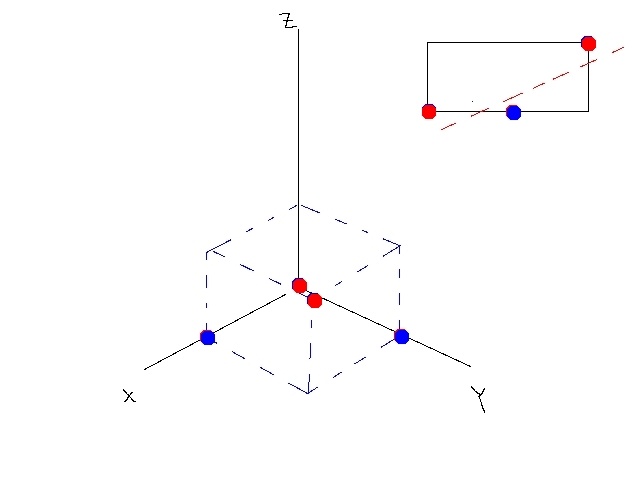
总而言之,激活函数可以引入非线性因素,解决线性模型所不能解决的问题。
- 为什么引入Relu呢
第一,采用sigmoid函数,算激活函数时(指数运算),计算量大。而使用Relu,整个计算节省了很多。
第二,对于深层网络,sigmoid函数反向传播时,很容易出现梯度消失的情况,(sigmoid接近饱和区的时候,变化太缓慢,导数趋于0)从而无法完成深层网络的训练。
第三,Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数之间互相依存的关系,缓解了过拟合的发生。