参考:
- 写的很详细的博客,很多来自于此:https://www.caiyifan.cn/p/d6990d10.html
- https://kubernetes.io/zh/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/
- https://blog.csdn.net/qq_39382182/article/details/121915330
- https://blog.lanweihong.com/posts/56314/
公网云服务器搭建k8s不是一件很好玩的事,会遇到各种麻烦,个人建议如果有条件直接在内网组建即可
一、集群配置与建立
注意:选择的Master节点必须>2核CPU
| master | Node1 | Node2 | |
|---|---|---|---|
| IP(公网) | 211.159.224.96 | 124.223.56.208 | 47.103.203.133 |
| IP(私有) | 10.0.16.15 | 10.0.16.14 | 172.17.59.2 |
| 系统 | Ubuntu20.04 | Ubuntu18.04 | Ubuntu20.04 |
三台云服务器搭建k8s v1.23.0版本,下面具体的操作会在括号中表明是哪些主机需要的操作
二、核心问题
屏蔽云服务器公网/内网IP问题:
现在的云服务器的公网IP是不会直接配置在服务器的网卡上的,网卡上的是内网IP,而多个服务器的内网IP一定不会在同一个网段,所以配置公网服务器之间的K8S集群最大的问题就在于此,可以总结为:
- master主机
kubeadm init时用内网IP还是公网IP? - flannel插件:pod不互通,其实这个问题可能就是第一个问题没处理好造成的
这些问题有不同的解决方案,网上给出了很多,我也尝试了很多,但是也有很多失败,下面的部分(三~)只写了成功部署的方法,其他的解决方法会在最后部分给出链接与相关信息。
因为也是接触k8s没多久,很多问题我也不明所以然(可能知道解决方法),所以我的目标是先部署没问题,原理学习完毕后再回来看这些问题。
三、前置工作
2.2 创建虚拟网卡(每个主机)
我们直接使用服务器公网IP启动K8S集群,但是直接是不行的,服务器上没有这个IP的网卡,所以我们需要在对应网卡上创建一个对应公网IP的虚拟网卡:
持久化创建一个虚拟网卡,防止重启失效
sudo vim /etc/network/interfaces
添加以下内容:
auto eth0:1
iface eth0:1 inet static
address <主网IP>
netmask 255.255.255.0
# 重启网卡
/etc/init.d/networking restart # 没有就安装 apt install ifupdown ifupdown2 netscript-2.4
如果有问题,查阅:https://www.cxyzjd.com/article/White_Idiot/82934338
2.3 安装前的设置(每个主机)
# 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
ufw disable # ubuntu
# 关闭selinux
sed -i 's/enforcing/disabled/' /etc/selinux/config # 永久
setenforce 0 # 临时
# 关闭swap
swapoff -a # 临时
sed -ri 's/.*swap.*/#&/' /etc/fstab # 永久
# 根据规划设置主机名
hostnamectl set-hostname <hostname>
# 在master添加hosts (换成自己的IP)
cat >> /etc/hosts << EOF
<公网IP1> master
<公网IP2> node1
<公网IP3> node2
EOF
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
br_netfilter
EOF
# 将桥接的IPv4流量传递到iptables的链
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system # 生效
# 时间同步
yum install ntpdate -y
ntpdate time.windows.com
2.4 安装安装包(每个主机)
安装包的下载可能需要配置不同linux包管理工具的国内源,这个自行百度即可解决
docker自行下载,唯一要注意的是:选择的CRI容器进行时的cgroups管理器必须是
systemd,否则会提示失败,官网详细介绍:https://kubernetes.io/zh/docs/tasks/administer-cluster/kubeadm/configure-cgroup-driver/官方推荐kubelet使用systemd驱动,那么我们修改docker的驱动, 修改
/etc/docker/daemon.json文件:{ "exec-opts": ["native.cgroupdriver=systemd"] }# 重启docker\kubelet systemctl restart docker systemctl restart kubelet
下载k8s安装工具(版本看自己):
ubuntu:
apt-get install -y kubectl=1.23.0-00 kubeadm=1.23.0-00 kubelet=1.23.0-00 apt-mark hold kubelet kubeadm kubectl # 锁定版本 systemctl enable kubelet # 开机启动
2.5 开启云服务器端口(每个主机)
很重要的一步,如果开启的不好会导致服务无法访问
控制面/Master
| 协议 | 方向 | 端口范围 | 目的 | 使用者 |
|---|---|---|---|---|
| TCP | 入站 | 6443 | Kubernetes API server | 所有 |
| TCP | 入站 | 2379-2380 | etcd server client API | kube-apiserver, etcd |
| TCP | 入站 | 10250 | Kubelet API | 自身, 控制面 |
| TCP | 入站 | 10259 | kube-scheduler | 自身 |
| TCP | 入站 | 10257 | kube-controller-manager | 自身 |
尽管 etcd 的端口也列举在控制面的部分,但你也可以在外部自己托管 etcd 集群或者自定义端口。
工作节点
| 协议 | 方向 | 端口范围 | 目的 | 使用者 |
|---|---|---|---|---|
| TCP | 入站 | 10250 | Kubelet API | 自身, 控制面 |
| TCP | 入站 | 30000-32767 | NodePort Services | 所有 |
NodePort Services是pod服务的默认端口范围。这里如果希望Master的IP也可以访问Pod服务,那么也可以给Master主机开放这些端口(建议)
所有节点
Flannel网络组件构建Pod之间的通信时需要的配置
| 协议 | 方向 | 端口范围 | 作用 | 使用者 |
|---|---|---|---|---|
| UDP | 入站 | 8472 | vxlan Overlay 网络通信 | Overlay 网络 |
2.6 修改启动参数(每个主机)
修改systemd管理的kubectl, 添加 kubelet的启动参数--node-ip=公网IP, 每个主机都要添加并指定对应的公网ip, 添加了这一步才能使用公网 ip来注册进集群
sudo vi /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
添加--node-ip=<公网IP>
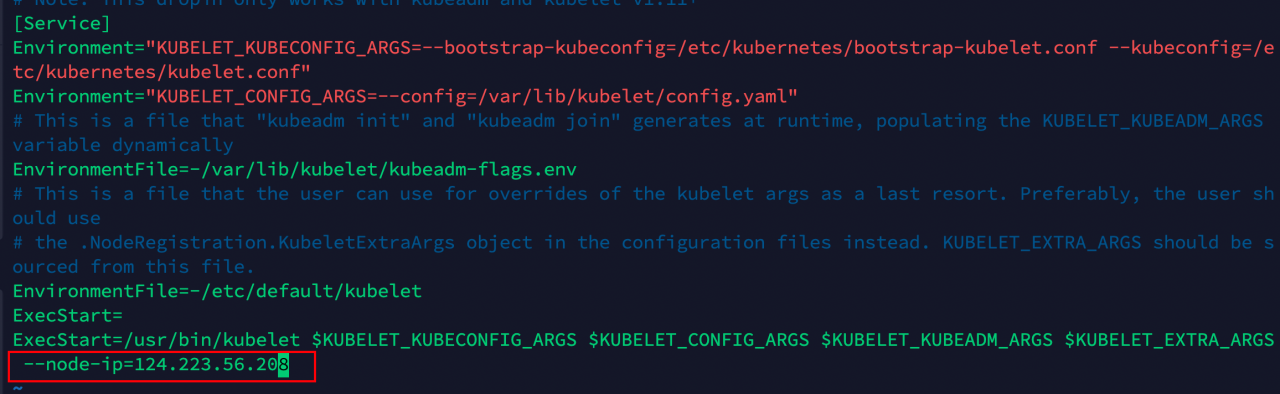
重启服务:systemctl daemon-reload
参数官方解释如下:(设置节点IP,使用默认IP,我们期望使用公网IP)
--node-ip string IP address (or comma-separated dual-stack IP addr
esses) of the node. If unset, kubelet will use the node's default IPv4 address, if any, or its default IPv6 address if it has no IPv4 addresses. You can pass '::' to make it prefer the default IPv6 address rather than the default IPv4 address.
四、搭建启动
1. master初始化(master)
sudo kubeadm init \
--apiserver-advertise-address=211.159.224.96 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.23.0 \
--control-plane-endpoint=211.159.224.96 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16
--v=5
初始化成功后会给出提示,执行以下操作让Master主机上所有用户可以使用kubectl命令
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
并且还给出了其他节点加入集群的命令:
kubeadm join 211.159.224.96 --token esce21.q6hetwm8si29qxwn \
--discovery-token-ca-cert-hash sha256:00603a05805807501d7181c3d60b478788408cfe6cedefedb1f97569708be9c5
如果过期了可以重新获取:
kubeadm token create --print-join-command
2. 集群的重置(出错了再执行此步骤)
如果安装失败想重新安装需要卸载集群
删除之前的环境(每个节点):
sudo kubeadm reset
rm -rf /root/.kube/
sudo rm -rf /etc/kubernetes/
sudo rm -rf /var/lib/kubelet/
sudo rm -rf /var/lib/dockershim
sudo rm -rf /var/run/kubernetes
sudo rm -rf /var/lib/cni
sudo rm -rf /var/lib/etcd
sudo rm -rf /etc/cni/net.d
# apt-get --purge remove kubectl kubelet kubeadm 安装包可以不卸载
注意,即使这样也没有删除掉k8s对本机网卡iptables转发的配置,完全的删除还需要执行:
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
ipvsadm -C
ipvsadm --clear
执行ifconfig会发现还有一些虚拟veth、cni、flannel等设备都可以通过ip link delete xxx删除掉
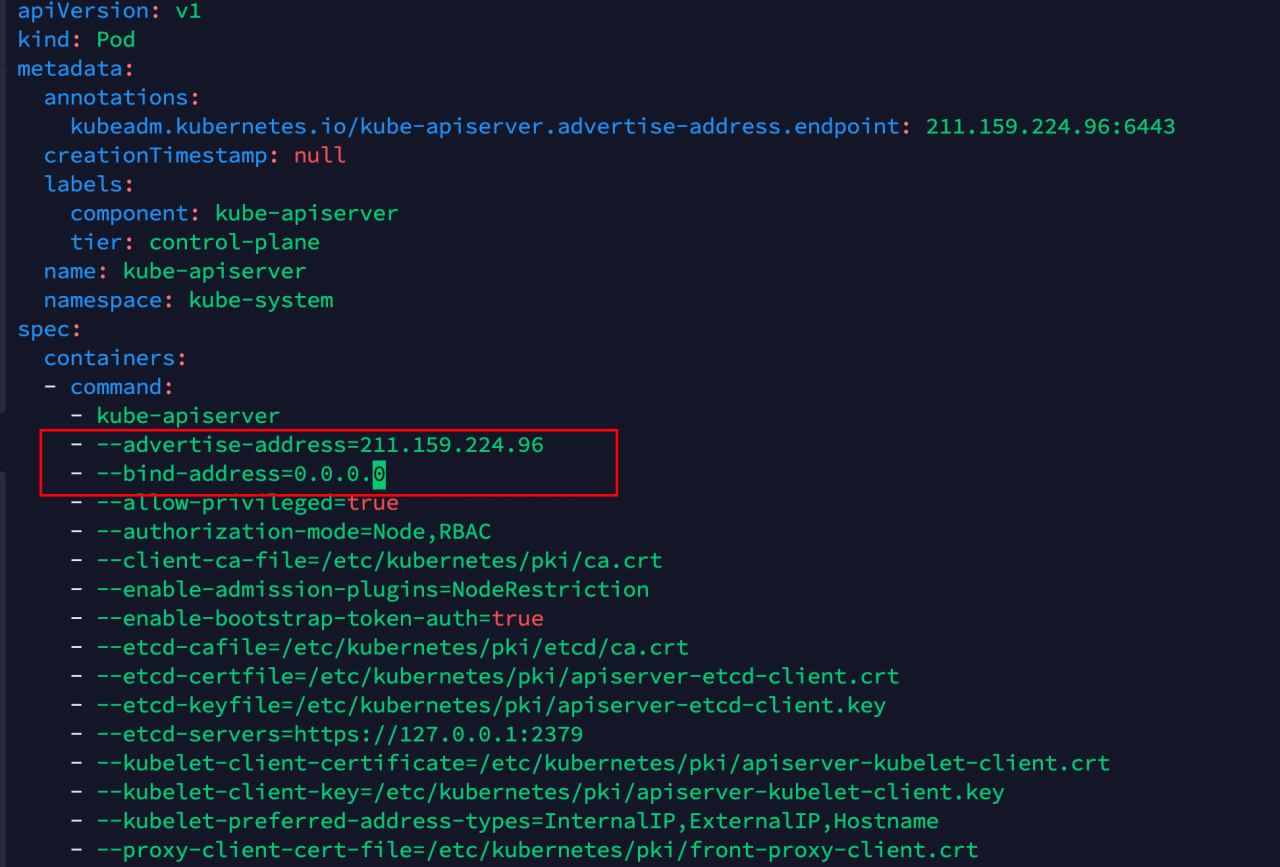
3. 修改kube-apiserver参数(Master)
在 master 节点,kube-apiserver 添加--bind-address=0.0.0.0和修改--advertise-addres=<公网IP>
sudo vi /etc/kubernetes/manifests/kube-apiserver.yaml
4. work node加入(work node)
在每个work node上执行一下上面的join指令即可:
kubeadm join 211.159.224.96 --token esce21.q6hetwm8si29qxwn \
--discovery-token-ca-cert-hash sha256:00603a05805807501d7181c3d60b478788408cfe6cedefedb1f97569708be9c5
5. 安装CNI网络插件(Master)
使用flannel, 在master节点执行
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
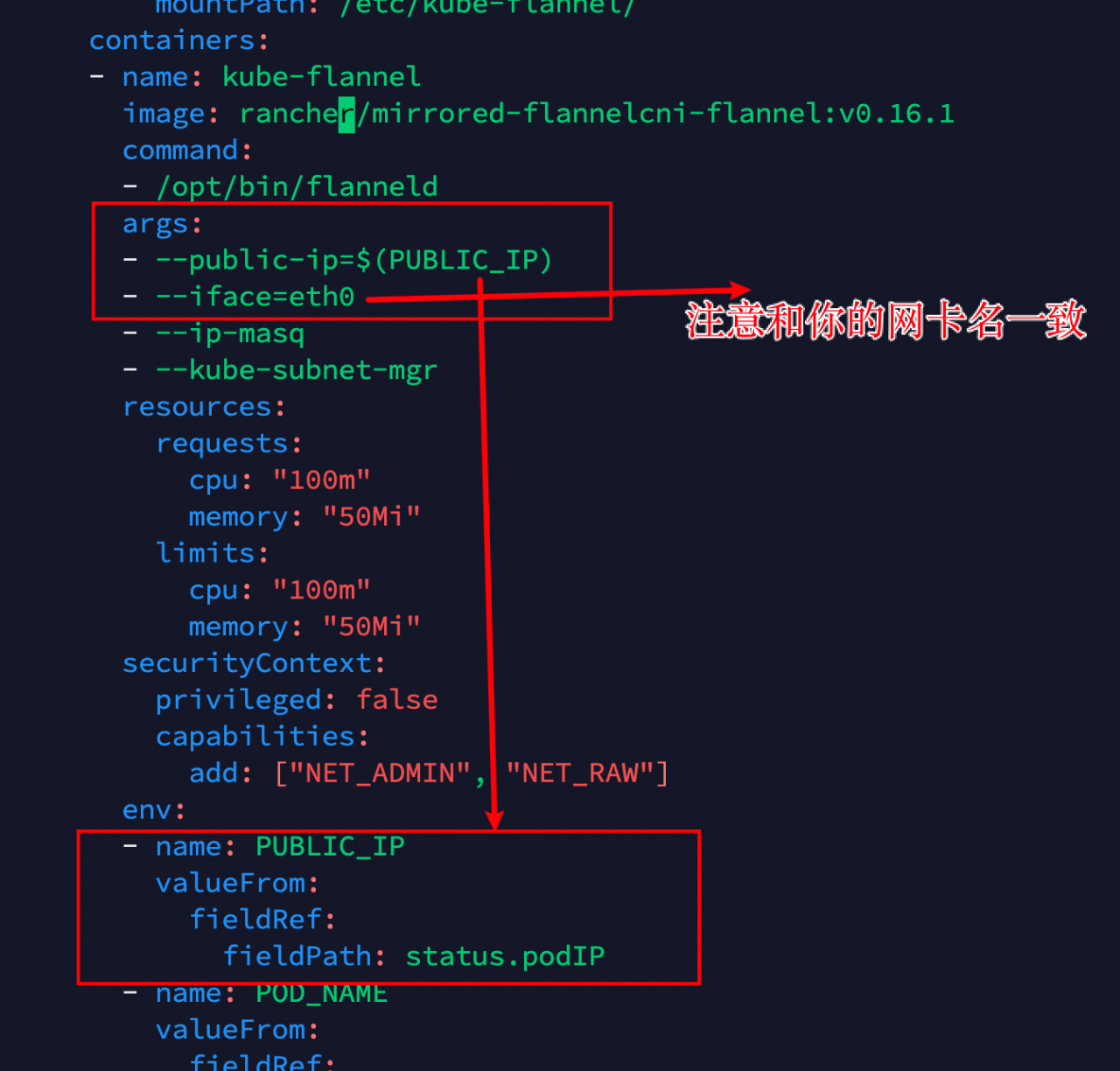
修改 yaml 配置文件,添加两处地方:
vi kube-flannel.yml
containers:
- name: kube-flannel
image: rancher/mirrored-flannelcni-flannel:v0.16.1
command:
- /opt/bin/flanneld
args:
- --public-ip=$(PUBLIC_IP)
- --iface=eth0
- --ip-masq
- --kube-subnet-mgr
env:
- name: PUBLIC_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
安装插件:
kubectl apply -f kube-flannel.yml
6. 检查状态(Master)
检查集群状态: kubectl get nodes

检查系统Pods状态:
watch -n 1 kubectl get pod -n kube-system -o wide

五、测试
master 节点执行下面命令来部署 nginx
kubectl create deploy my-nginx --image=nginx
kubectl expose deploy my-nginx --port=80 --type=NodePort
查看 nginx 部署的 pod 信息,可以看到 Pod ip,以及部署在哪一个节点上
kubectl get pods -o wide
每一台机子都ping一下Pod的IP,看看是否能Ping通,如果不行,先执行sudo iptables -P FORWARD ACCEPT, 如果还是不行, 那么检查主机的UDP端口8472是否开启

测试NodePort:
kubectl get svc -o wide

用每个主机的公网IP + 这里的端口号,看看是否都可以访问Nginx服务,如果都可以那么集群就ok了,如果不行就检查端口是否开放(特别是Master)
六、其他公网组建k8s的解决方案
1. 内网IP+iptables转发
使用内网IP与Iptables转发链:https://zhuanlan.zhihu.com/p/410371256
使用此方法出现的Bug:
1. 其他服务器内网IP与主机内网docker网桥网段冲突
注意查看其他公网服务器的内网IP是否会和Master本机的其他内网服务IP冲突,我就是和docker0网桥的Ip冲突,导致即使配置了Iptables转发还是不能ping通
因为阿里云轻量服务器内网不可修改(云服务器可以改),所以选择了修改docker的默认网桥docker0,修改docker0 IP: (https://www.jianshu.com/p/69fc2d9656e7)
修改文件 /etc/docker/daemon.json添加内容 “bip”: “ip/netmask” [ 切勿与宿主机同网段 ]
[root@iZ2ze278r1bks3c1m6jdznZ ~]# cat /etc/docker/daemon.json
{
"bip":"192.168.100.1/24"
}
重启docker服务器
[root@iZ2ze278r1bks3c1m6jdznZ ~]# systemctl restart docker
2. 使用公网IP配置init启动导致 Initial timeout of 40s passed.
问题描述:
master init启动卡在:
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[kubelet-check] Initial timeout of 40s passed.
原因:
因为阿里云主机网络是VPC,公网IP只能在控制台上看到,在系统里面看到的是内部网卡的IP,阿里云采用NAT方式将公网IP映射到ECS的位于私网的网卡上,所以在网卡上看不到公网IP,使用 ifconfig 查看到的也是私有网卡的IP,导致 etcd 无法启动。
解决:
使用iptables转发(见上方)
或者(来自https://zhuanlan.zhihu.com/p/410371256)
另启一个命令行窗口修改初始化生成的 etcd.yaml 中的配置成示例图一样,进程会自动重试并初始化成功。
vim /etc/kubernetes/manifests/etcd.yaml

3. kubelet与docker驱动不同启动失败
问题描述:
kubelet启动失败,
journalctl -xeu kubelet查看错误信息:failed to run Kubelet: misconfiguration: kubelet cgroup driver: \"systemd\" is different from docker cgroup driver: \"cgroupfs\""原因:
kubelet与docker的cgroups驱动程序不同
解决:
官方推荐kubelet使用systemd驱动,那么我们修改docker的驱动, 修改
/etc/docker/daemon.json文件:{ "exec-opts": ["native.cgroupdriver=systemd"] }# 重启docker\kubelet systemctl restart docker systemctl restart kubelet
4. kubelet找不到配置文件
kubelet启动报错:
问题描述:failed to load Kubelet config file /var/lib/kubelet/ config.yaml, error failed to read kubelet config file "/var
原因与解决:新版本需要先kubeadmin init生成对应的配置文件,kubelet才会正常