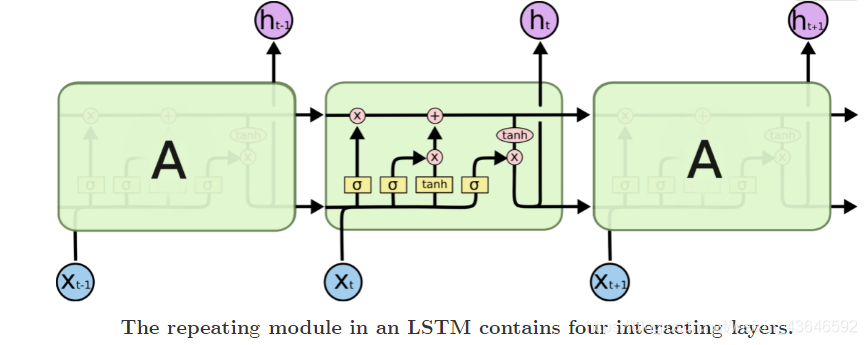
LSTM原理请看这:点击进入
LSTM:
nn.LSTM(input_size,
hidden_size,
num_layers=1,
nonlinearity=tanh,
bias=True,
batch_first=False,
dropout=0,
bidirectional=False)
input_size:表示输入 xt 的特征维度
hidden_size:表示输出的特征维度
num_layers:表示网络的层数
nonlinearity:表示选用的非线性激活函数,默认是 ‘tanh’
bias:表示是否使用偏置,默认使用
batch_first:表示输入数据的形式,默认是 False,就是这样形式,(seq, batch, feature),也就是将序列长度放在第一位,batch 放在第二位
dropout:表示是否在输出层应用 dropout
bidirectional:表示是否使用双向的 LSTM,默认是 False。
import torch
from torch import nn
from torch.nn import functional as F
lstm = nn.LSTM(input_size=10, hidden_size=20, num_layers=2,bidirectional=False)
# 可理解为一个字串长度为5, batch size为3, 字符维度为10的输入
input_tensor = torch.randn(5, 3, 10)
# 两层LSTM的初始H参数,维度[layers, batch, hidden_len]
#在lstm中c和h是不一样的,而RNN中是一样的
h0,c0 = torch.randn(2,3, 20),torch.randn(2,3, 20)
# output_tensor最后一层所有的h输出, hn表示两层最后一个时序的输出, cn表示两层最后一个时刻的状态的输出
output_tensor, (hn,cn) =lstm(input_tensor, (h0,c0))
print(output_tensor.shape, hn.shape,cn.shape)
torch.Size([5, 3, 20]) torch.Size([2, 3, 20]) torch.Size([2, 3, 20])
从上面可以看到输出的h,x,和输入的h,x维度一致。
上面的参数中,num_layers=2相当于有两个rnn cell串联,即一个的输出h作为下一个的输入x。也可单独使用两个nn.LSTMCell实现
而当我们设置成双向LSTM时,即bidirectional=True
lstm = nn.LSTM(input_size=10, hidden_size=20, num_layers=2,bidirectional=True)
h0,c0 = torch.randn(4,3, 20),torch.randn(4,3, 20)
torch.Size([5, 3, 40]) torch.Size([4, 3, 20]) torch.Size([4, 3, 20])
一共5个时刻,可以看到最后一时刻的output维度是[3, 40],因为nn.LSTM模块他在最后会将正向和反向的结果进行拼接concat。而hn中的4是指正反向,还有因为num_layers是两层所以为4。
output_tenso只输出最后一层!!!的所有时刻的状态输出(且正向和反向拼接好了。而hn和cn包含所有层,所有方向的最后时刻的输出。
(?具体输出output、h和c的索引是指哪一层和哪一个方向,可以看这个链接解释:PyTorch 多层双向LSTM输入、输出、隐藏状态、权重、偏置的维度分析)
基于LSTM(多层LSTM、双向LSTM只需修改两个参数即可实现)的英文文本分类:
数据集:英文电影评论(积极、消极)二分类
分词表是我自己修改了nltk路径:
C:\用户\AppData\Roaming\nltk_data\corpora\stopwords里的english文件。
然后你把我的my_english文件放进里面就可以,或者你直接用它的english
数据集链接和my_english分词表都在以下网盘链接:
链接:https://pan.baidu.com/s/1vhh5FmU01KqyjRtxByyxcQ
提取码:bx4k
关于词嵌入是用了nn.embedding(),它的用法请看这:点击进入
import torch
import numpy as np
import pandas as pd
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
import torch.nn.functional as F
读入数据集,数据集为电影评论数据(英文,一个24500条数据),分为积极和消极两类:
df = pd.read_csv('Dataset.csv')
print('一共有{}条数据'.format(len(df)))
df.info()
分词去停用词,我的csv文件里已经处理完保存好了分词结果,可以不运行这一部分:
from nltk.corpus import stopwords
import nltk
def separate_sentence(text):
disease_List = nltk.word_tokenize(text)
#去除停用词
filtered = [w for w in disease_List if(w not in stopwords.words('my_english'))]
#进行词性分析,去掉动词、助词等
Rfiltered =nltk.pos_tag(filtered)
#以列表的形式进行返回,列表元素以(词,词性)元组的形式存在
filter_word = [i[0] for i in Rfiltered]
return " ".join(filter_word)
df['sep_review'] = df['review'].apply(lambda x:separate_sentence(x))
根据需要筛选数据(这里我使用了1000条):
#用xxx条玩玩
use_df = df[:1000]
use_df.head(10)
sentences = list(use_df['sep_review'])
labels = list(use_df['sentiment'])
小于最大长度的补齐:
max_seq_len = max(use_df['sep_review'].apply(lambda x: len(x.split())))
PAD = ' <PAD>' # 未知字,padding符号用来填充长短不一的句子(用啥符号都行,到时在nn.embedding的参数设为padding_idx=word_to_id['<PAD>'])即可
#小于最大长度的补齐
for i in range(len(sentences)):
sen2list = sentences[i].split()
sentence_len = len(sen2list)
if sentence_len<max_seq_len:
sentences[i] += PAD*(max_seq_len-sentence_len)
制作词表(后面用来给单词编号):
num_classes = len(set(labels)) # num_classes=2
word_list = " ".join(sentences).split()
vocab = list(set(word_list))
word2idx = {w: i for i, w in enumerate(vocab)}
vocab_size = len(vocab)
给单词编号(编完号后续还要在embeding层将其转成词向量):
def make_data(sentences, labels):
inputs = []
for sen in sentences:
inputs.append([word2idx[n] for n in sen.split()])
targets = []
for out in labels:
targets.append(out) # To using Torch Softmax Loss function
return inputs, targets
input_batch, target_batch = make_data(sentences, labels)
input_batch, target_batch = torch.LongTensor(input_batch), torch.LongTensor(target_batch)
用Data.TensorDataset(torch.utils.data)对给定的tensor数据(样本和标签),将它们包装成dataset,
然后用Data.DataLoader(torch.utils.data)数据加载器,组合数据集和采样器,并在数据集上提供单进程或多进程迭代器。它可以对我们上面所说的数据集dataset作进一步的设置(比如可以设置打乱,对数据裁剪,设置batch_size等操作,很方便):
from sklearn.model_selection import train_test_split
# 划分训练集,测试集
x_train,x_test,y_train,y_test = train_test_split(input_batch,target_batch,test_size=0.2,random_state = 0)
train_dataset = Data.TensorDataset(torch.tensor(x_train), torch.tensor(y_train))
test_dataset = Data.TensorDataset(torch.tensor(x_test), torch.tensor(y_test))
dataset = Data.TensorDataset(input_batch, target_batch)
batch_size = 16
train_loader = Data.DataLoader(
dataset=train_dataset, # 数据,封装进Data.TensorDataset()类的数据
batch_size=batch_size, # 每块的大小
shuffle=True, # 要不要打乱数据 (打乱比较好)
num_workers=2, # 多进程(multiprocess)来读数据
)
test_loader = Data.DataLoader(
dataset=test_dataset, # 数据,封装进Data.TensorDataset()类的数据
batch_size=batch_size, # 每块的大小
shuffle=True, # 要不要打乱数据 (打乱比较好)
num_workers=2, # 多进程(multiprocess)来读数据
)
搭建网络:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device,'能用')
class LSTM(nn.Module):
def __init__(self,vocab_size, embedding_dim, hidden_size, num_classes, num_layers,bidirectional):
super(LSTM, self).__init__()
self.vocab_size = vocab_size
self.embedding_dim = embedding_dim
self.hidden_size = hidden_size
self.num_classes = num_classes
self.num_layers = num_layers
self.bidirectional = bidirectional
self.embedding = nn.Embedding(self.vocab_size, embedding_dim, padding_idx=word2idx['<PAD>'])
self.lstm = nn.LSTM(input_size=self.embedding_dim, hidden_size=self.hidden_size,batch_first=True,num_layers=self.num_layers,bidirectional=self.bidirectional)
if self.bidirectional:
self.fc = nn.Linear(hidden_size*2, num_classes)
else:
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
batch_size, seq_len = x.shape
#初始化一个h0,也即c0,在RNN中一个Cell输出的ht和Ct是相同的,而LSTM的一个cell输出的ht和Ct是不同的
#维度[layers, batch, hidden_len]
if self.bidirectional:
h0 = torch.randn(self.num_layers*2, batch_size, self.hidden_size).to(device)
c0 = torch.randn(self.num_layers*2, batch_size, self.hidden_size).to(device)
else:
h0 = torch.randn(self.num_layers, batch_size, self.hidden_size).to(device)
c0 = torch.randn(self.num_layers, batch_size, self.hidden_size).to(device)
x = self.embedding(x)
out,(_,_)= self.lstm(x, (h0,c0))
output = self.fc(out[:,-1,:]).squeeze(0) #因为有max_seq_len个时态,所以取最后一个时态即-1层
return output
实例化网络:
要实现多层LSTM只需修改参数:num_layers。要实现双向LSTM只需修改参数:bidirectional=True。
model = LSTM(vocab_size=vocab_size,embedding_dim=300,hidden_size=20,num_classes=2,num_layers=2,bidirectional=True).to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
模型训练过程:
model.train()
for epoch in range(1):
for batch_x, batch_y in train_loader:
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
pred = model(batch_x)
loss = criterion(pred, batch_y) #batch_y类标签就好,不用one-hot形式
if (epoch + 1) % 10 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()
模型测试过程:这里只测试准确率
test_acc_list = []
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
pred = output.max(1, keepdim=True)[1] # 找到概率最大的下标
correct += pred.eq(target.view_as(pred)).sum().item()
# test_loss /= len(test_loader.dataset)
# test_loss_list.append(test_loss)
test_acc_list.append(100. * correct / len(test_loader.dataset))
print('Accuracy: {}/{} ({:.0f}%)\n'.format(correct, len(test_loader.dataset),100. * correct / len(test_loader.dataset)))