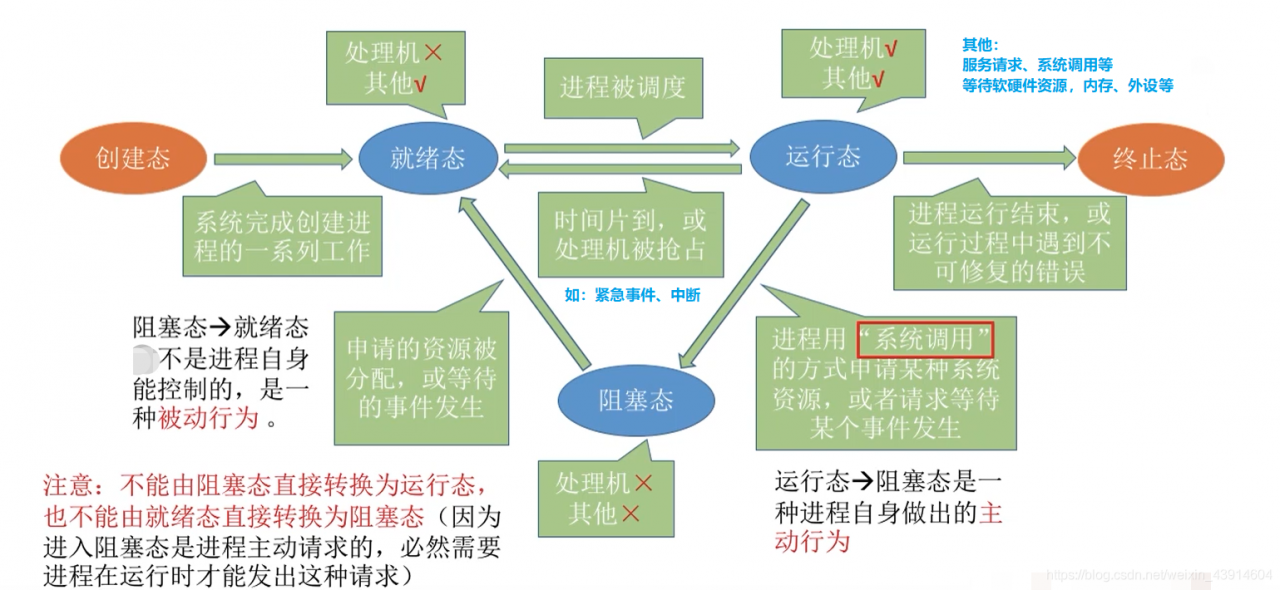
操作系统中运行到就绪有几种转换方式?
运行->就绪态:时间片使用完或者处理机被抢占但是进程还没有结束
就绪->运行态:进程被调度进入执行态
写代码的时候应该如何避免死锁?
将系统中所有的资源设置标志位,排序,规定所有的进程申请资源以一定的顺序来操作,避免死锁
a给b端发fin包,b端在没有收到的时候,b给a也发了一个fin包会怎样
当两端同时收到fin包的时候,会同时断开连接,进入closed状态
HTTP的请求头,请求行,请求体分别存放什么数据结构?
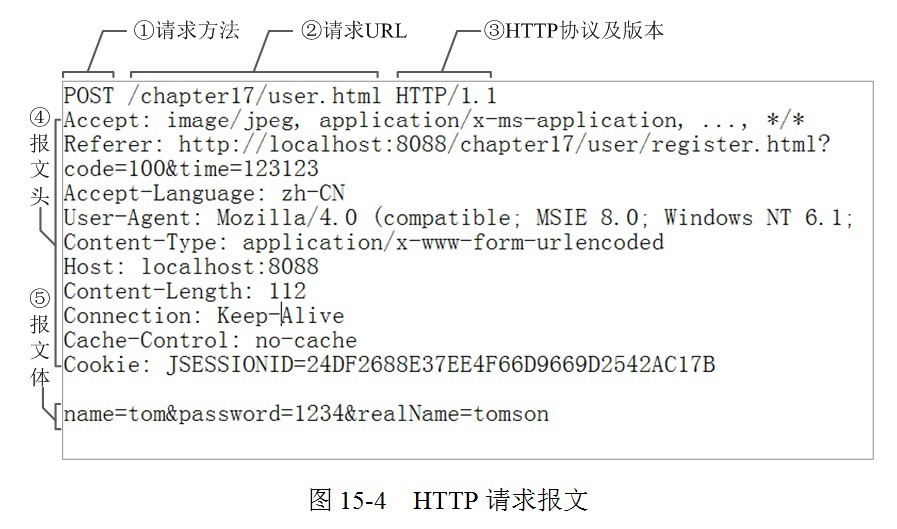
请求行:方法字段,URL字段和HTTP协议版本字段构成,用空格分割
请求头:由关键字/值对组成,每行一对,关键字和值用冒号分割典型的请求头有:
- User-Agent:产生请求的浏览器类型
- Accept:客户端可以识别的内容类型列表
- Host:请求的主机名,允许多个域名同处于一个主机
- Cookie等
- content-Type报文体的格式
报文体: GET请求没有正文信息,Post请求有多种数据格式可以是默认的键值对格式,可以是Json,可以是multipart/form-data,可以是text/xml
为什么复合索引要遵循最左前缀原则?
多列索引是先按照第一列进行排序,然后在第一列排好序的基础上再对第二列进行排序,如果没有第一列,直接访问第一列,第二列肯定是无需的;
比方说(name,age,code),b+树会优先比较name来确定下一步搜索的方向,如果name相同再比较age和code,最后得到检索的数据
什么场景使用阻塞IO,什么场景使用非阻塞IO?
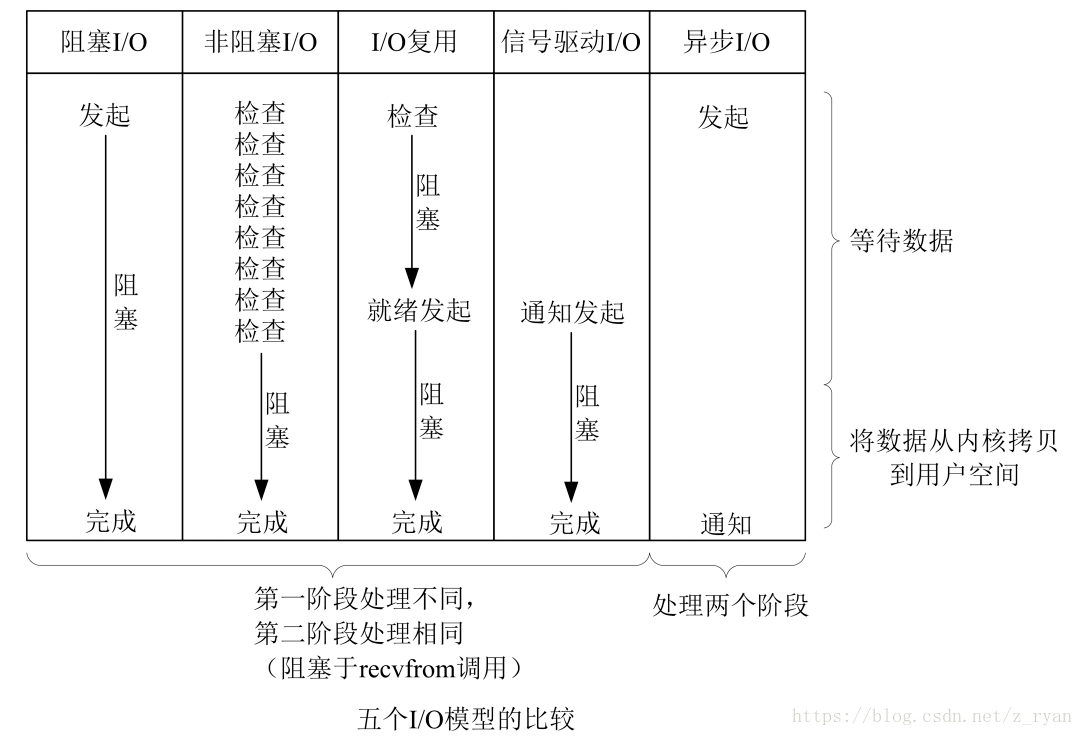
IO:即数据的读取或者写入操作,通常用户进程中的一个完整IO分为两阶段:用户进程->内核空间,内核空间->设备空间(网络,磁盘等),IO有内存IO,网络IO和磁盘IO三种,通常我们说的是后两者;五种IO模型包括阻塞IO,非阻塞IO,信号驱动IO,IO多路复用,异步IO(效率由低到高)
以下图中recvform是阻塞套接字
阻塞IO:进程发起IO系统调用之后,进程被阻塞,转到内核空间处理,整个IO处理完毕之后,返回进程,操作成功则进程获取到数据(一个人去钓鱼,在鱼竿前一直等,不做其他事,直到鱼上钩,才结束等的动作)
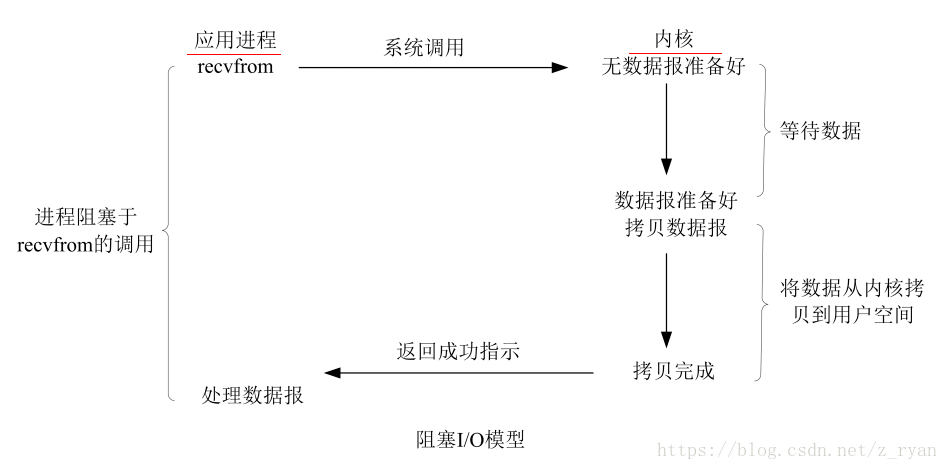
- 进程阻塞挂起不消耗cpu资源,及时响应每个操作
- 实现难度低,开发应用容易
- 适合并发量小的网络应用开发
- 不适合并发大的应用,因为一个请求IO会阻塞进程,所以得为每个请求分配一个处理进程以及及时响应,系统开销大
非阻塞IO:进程发起IO系统调用后,如果内核缓冲区没有数据,需要到IO设备中读取,返回一个错误进程不会被阻塞,进程发起IO系统调用之后,如果内核有数据,内核就会直接把数据返回进程(一个人在河边钓鱼,但是他一边看书,玩手机,每隔一个固定时间检查有没有鱼上钩,当检查到有鱼上钩的时候,停下手上的事情,把鱼钓上来)
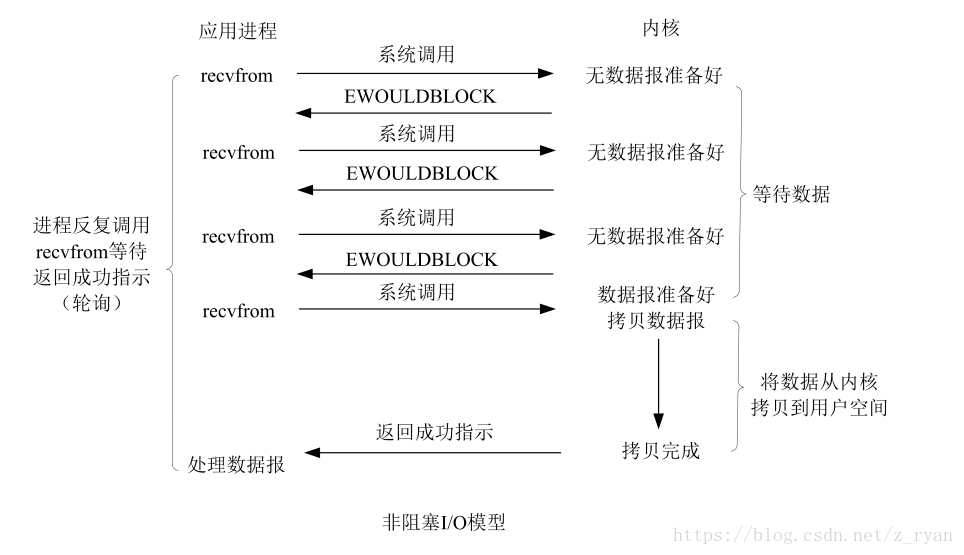
- 进程轮询(重复)调用,不停的查看是否有资源可读,消耗cpu资源
- 实现难度低,开发应用相对阻塞IO模式较难
- 适用于并发量小,且不需要及时响应的网络应用开发
- 典型应用:socket
IO复用模型:不再由应用程序自己监视连接,而是内核替应用程序监视文件描述符,好处在于单个进程就可以处理多个网络连接的IO;进程调用select,整个进程会被阻塞,同时内核会监视所有select负责的socket,当任何一个socket的数据准备好了,select就会返回,此时用户进程再调用read,将数据从内核拷贝到用户进程(钓鱼佬不讲武德,用很多根鱼竿来钓鱼)
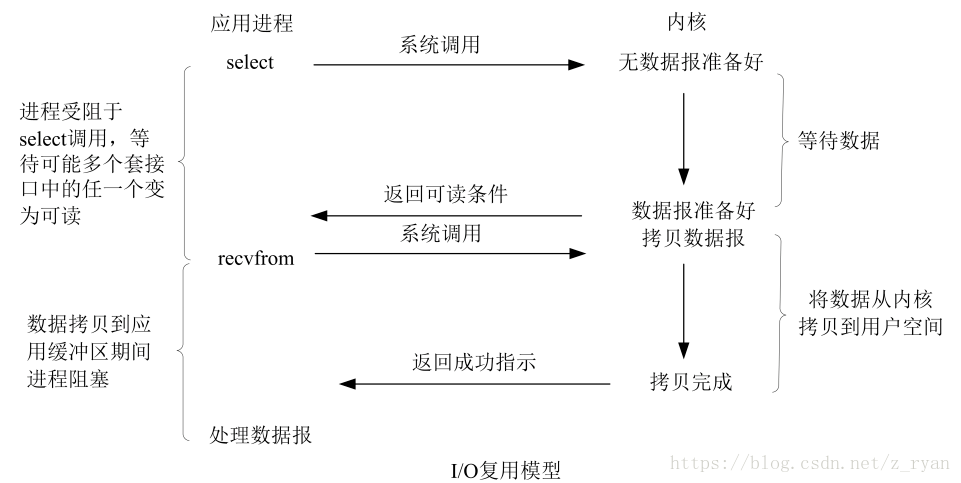
- 专一进程解决多个进程IO的阻塞问题,性能好,适用于高并发服务应用开发,一个进程(线程)能响应多个请求
- 由于使用了select和recvform两个系统调用,所以当连接数并不多的情况下,反而效果还没有多线程+非阻塞/阻塞IO的性能好,可能延迟还大
- 典型应用:select,poll,epoll,java NIO
- 应用场景:服务器需要同时处理多个处于连接/监听状态的套接字,需要同时处理多个端口或者多种服务,同时处理用户输入和网络连接,同时处理UDP请求和TCP请求
select:注册IO,阻塞扫描,监听的IO最大连接数不能多余FD_SIZE
poll:原理类似于select,没有数量限制,但是IO数量大扫描性能线性下降
epoll:时间驱动不阻塞,mmap实现内核与用户空间的消息传递,数量很大
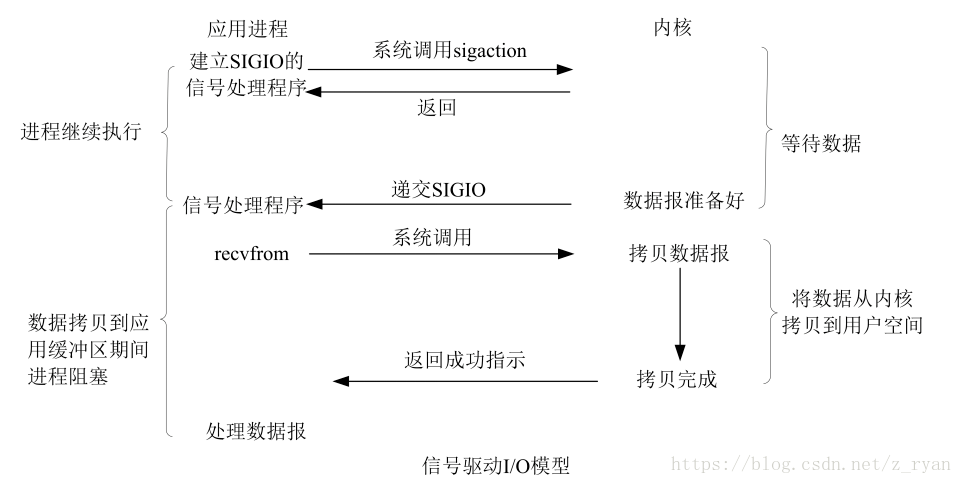
信号驱动IO: 应用进程告诉内核,数据准备好的时候给我发信号,对该信号进行捕捉,并且调用我的信号处理函数来处理信号(钓鱼佬给鱼竿挂上一个铃铛,有鱼上钩的时候,铃铛就会响,此时把鱼钓上来)
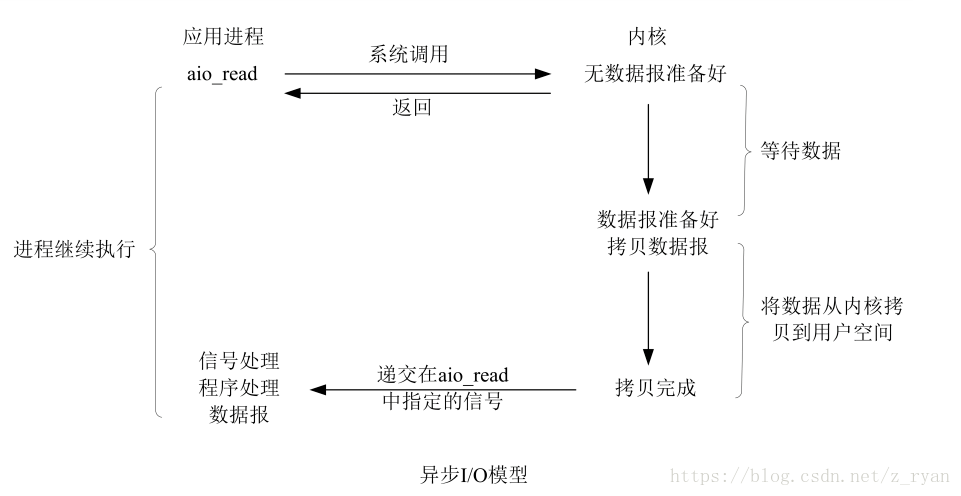
异步IO:以上四种IO都是同步的,只有异步IO是异步的,用户进程进行aio_read系统调用之后,就可以去处理其他的逻辑了,无论数据是否准备好了,都会返回给用户进程,不会对进程造成阻塞,等数据都准备好了,内核直接复制数据到进程空间,然后从内核向进程发送通知,此时数据已经在用户空间了,可以对数据进行处理了(一个人喜欢吃鱼,于是它雇了一个厨师去帮他钓鱼,鱼钓上来了之后,厨师把鱼直接喂到他嘴里)
五种IO模型的比较
什么是CA证书?客户端如何确定ca证书可信
数字证书颁发机构(简称CA)是值得信赖的第三方实体颁发数字证书机构并管理为最终用户数据加密的公共密钥和证书。CA的责任是确保公司或用户收到有效的身份认证是唯一证书。
什么时候使用进程什么时候使用线程?
当频繁销毁和创建的时候当然使用线程,耗时操作使用线程提高应用app的响应
并行操作只能使用进程
需要稳定和安全的操作时使用进程,需要速度的时候,选择线程更好
Java怎么启用一个进程?
一个JVM进程对应一个java程序,在jvm的内部程序的多任务是通过线程来实现的,当使用过java命令启动一个java应用程序就会启动一个JVM进程
//法一
Runtime rt = Runtime.getRuntime();
Process process = rt.exec("java com.test.process.MyClass");
//法二
ProcessBuilder pb = new ProcessBuilder(myXXcommand,myXXobject);
Process p = pb.start();mq的结构?消费组?
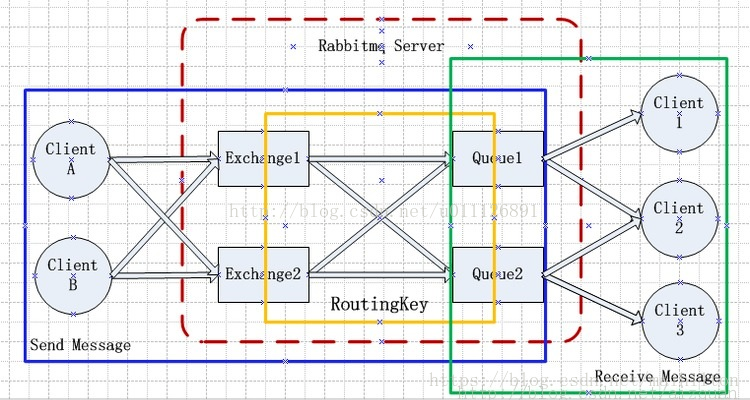
- Broker:它提供一种传输服务,它的角色就是维护一条从生产者到消费者的路线,保证数据能按照指定的方式进行传输,
- Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列。
- Queue:消息的载体,每个消息都会被投到一个或多个队列。
- Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来.
- Routing Key:路由关键字,exchange根据这个关键字进行消息投递。
- vhost:虚拟主机,一个broker里可以有多个vhost,用作不同用户的权限分离。
- Producer:消息生产者,就是投递消息的程序.
- Consumer:消息消费者,就是接受消息的程序.
- Channel:消息通道,在客户端的每个连接里,可建立多个channel.
消费组组是kafka提供的可扩展具有容错性的消费者机制
- 一个消费者只能有一个消费组,一个消费组可能有多个消费者。当消息发送到主题后,主题只会把消息发送给订阅它的消费组内的一个消费者。
- 每个消费者只能消费所分配到的分区中的消息。换言之,每一个分区只能被一个消费组中的一个消费者消费。
- 如果所有的消费者都属于同一个消费组,那么消息就会被均衡的投递给每一个消费者,也就是一个消费组内每条消息只会被一个消费者处理,这就相当于点对点模式。
- 如果所有的消费者都不属于一个消费组,那么消息就会投递给订阅该主题的每个消费组中的一个消费者,这就相当于发布/订阅模式。
什么时候需要自定义类加载器
- 加密:java代码很容易被反编译,如果你需要把自己的代码进行加密,可以先将编译后的代码用某种算法加密,然后实现自己的类加载器,负责把加密后的代码还原
- 从非标准来源加载代码:你的部分字节码是放在数据库中,甚至是网上的,就可以自己写个类加载器,从指定来源加载类
现在有一个函数,有p的概率生成1,1-p的概率生成0,怎么使用这个函数,让他以相同的概率生成1和0?怎么推广到1-n?
调用两次,有四个结果00,01,10,11其中01和10概率相等,可以用这两种结果代表0和1,设这个函数为random()表示说功能是平均输出0和1
public int rand(int n){
StringBuilder stringBuilder = new StringBuilder();
while(true){
//拿到当前数的二进制位的最高位数,向上取整
int bits=(int)Math.ceil((Math.log(n)/Math.log(2)));
int v=0;
for(int i=0;i<bits;i++){
//对每一位进行0,1的概率运算
if(random()==1){
v|=(1<<i);
}
}
//当结果小于n的时候才输出
if(v<n){
return v;
}
}
}SQL题
查询姓孟老师的个数
select count(教师号)
from teacher
where 教师姓名 like '孟%';查询课程编号为0002的总成绩
select sum(成绩)
from score
where 课程号 = '0002';查询选了课程的学生人数
select count(distinct 学号) as 学生人数
from score;查询各科成绩的最高和最低分
select 课程号,max(成绩) as 最高分,min(成绩) as 最低分
from score
group by 课程号;查询每门课程被多少人选修
select 课程号, count(学号)
from score
group by 课程号;查询男生女生的人数
select 性别,count(*)
from student
group by 性别;查询平均成绩大于60分学生的学号和平均成绩
select 学号, avg(成绩)
from score
group by 学号
having avg(成绩)>60;查询至少选修了两门课的学生姓名
*/
select 学号, count(课程号) as 选修课程数目
from score
group by 学号
having count(课程号)>=2;topK问题:查询各科成绩前两名的记录
select *
from score
where 课程号 = '0001'
order by 成绩 desc
limit 2;更新一张表的一些行,如果字段是c,将其改成d这个sql怎么写
UPDATE t1 SET NAME='小吴' WHERE NAME ="王五";统计一个字段的具体值,并且增加过滤条件与排序条件
SELECT COUNT(grade) FROM t1 GROUP BY NAME
HAVING COUNT(grade)>2 ORDER BY COUNT(grade); 总成绩前十的sql怎么写?
SELECT NAME,SUM(grade) FROM t1
GROUP BY NAME ORDER BY SUM(grade) DESC LIMIT 3; 联合查询,查询所有学生的学号、姓名、选课数、总成绩
select a.学号,a.姓名,count(b.课程号) as 选课数,sum(b.成绩) as 总成绩
from student as a left join score as b
on a.学号 = b.学号
group by a.学号;查询平均成绩大于85的所有学生的学号、姓名和平均成绩
select a.学号,a.姓名, avg(b.成绩) as 平均成绩
from student as a left join score as b
on a.学号 = b.学号
group by a.学号
having avg(b.成绩)>85;场景题
如果一个外卖配送单子要发布,现在有200个骑手都想要这一单,如何保证只有一个骑手接到单子?
单机情况,采用volatile关键字修饰该订单,并且使用cas操作
多机情况采用redission分布式锁对整个过程进行加锁
如何把一个文件快速下发到100w个服务器?
采用p2p网络形式,比如树状形式,网状形式,单个节点既可以从其他节点接收服务又可以向其他节点提供服务
可能存在的两个问题:
- 如果树上某一个节点坏掉了,那么这个节点往下的所有服务器会宕机
- 如果树中的某条路径,传递时间太长,使得传递效率退化
改进:100w台服务器相当于有100w个节点的连通图,我们可以在图中生成多颗不同的生成树,在进行数据下发的时候,同时按照多颗不同的树去传递数据,这样就可以避免中间某个节点宕机,影响到后续的节点
10亿个数,找最大的10个
单机单核足够大的内存:维护一个小顶堆,每次都与顶堆最小的数进行比较,如果后续元素比容器内最小数字大,删掉容器内最小的元素,并且将该元素插入容器
单机多核足够大的内存:内存中使用hash将数据划分成多个part,每个part交给一个线程处理,逻辑与单机的时候类似,最后一个线程将结果归并,并且让每个线程自己去获取下一个part继续处理,这样可以避免效率高的线程没事做的情况
有几台机器存储着几亿淘宝搜索日志,你只有一台2G的电脑,怎么搜索出热度最高的10个
可以拆分成n多个文件:以首字母分,不同的首字母放在不同文件,长度过长的继续按照次首字母进行拆分,这样一来,每个文件的每个数据长度相同,首位字母也相同,能保证数据被独立分成了n个文件,且各个文件中不存在关键词的交集
对于每个文件,使用hash或者Trie树(前缀树)进行词频统计,并且使用大根堆,获取词频最多的10个词,依次处理每个文件
10万个数从小到大输出?
多路归并排序算法,在N个数中取M个数排序之后方法放到内存,然后多路归并算法进行合并
在2.5亿个整数中找出不重复的数,内存不足以容纳所有数字
位操作,采用bitmap方法来对每一个数据进行标记,0代表存在,1代表不存在
两个线程交替打印不使用锁?
static volatile int num=1;
static volatile boolean flag=true;
public static void main(String[] args) {
new Thread(()->{
while(num<=100){
if(flag){
System.out.println(Thread.currentThread().getName() + ":" + num);
num++;
flag=false;
}
}
},"A").start();
new Thread(()->{
while(num<=100){
if(!flag){
System.out.println(Thread.currentThread().getName() + ":" + num);
num++;
flag=true;
}
}
},"B").start();
}如何定位大对象的位置?
Jmap命令是一个可以输出所有内存中对象的工具,其命令格式为jmap [option] pid
- -dump:live,formate=b,file=<filename>选项中 live指的是或者的对象,file指的是文件名,生成堆转储快照dump文件
- -heap 打印堆总结
- -finalizerinfo:打印等待回收对象的信息
- -histo[:live]打印堆的对象统计,包括对象数,内存,大小等
有哪几种常用的线程池?
线程池:

阻塞队列:
- ArrayBlockingQueue:规定大小的BlockingQueue,其构造必须指定大小。其所含的对象是FIFO顺序排序的。
- LinkedBlockingQueue:大小不固定的BlockingQueue,若其构造时指定大小,生成的BlockingQueue有大小限制,不指定大小,其大小有Integer.MAX_VALUE来决定。其所含的对象是FIFO顺序排序的。
- PriorityBlockingQueue:类似于LinkedBlockingQueue,但是其所含对象的排序不是FIFO,而是依据对象的自然顺序或者构造函数的Comparator决定。
- DelayWorkQueue:队列中的元素必须实现Delayed接口,在创建元素的时候指定多久才能从队列中获取当前元素
- SynchronousQueue:特殊的BlockingQueue,对其的操作必须是放和取交替完成。
生产中应该使用ThreadPoolExecutor和BlockingQueue连用来创建线程池
Thread.Start是立即启动吗?
调用了start方法之后,线程的状态从new变成了ready状态,而不是running,线程要等待cpu的调度,start方法的被调用顺序不能决定线程的执行顺序
如果有1000万左右的数据进行查询,使用B+树需要经过几次IO
对于一个普通的二叉树,如果有100w的数据,大概的时间复杂度为log2N=100w,N=20的时候获取到节点,也就是I/O福再度最大为O(20)
对于InnoDB引擎的B+树来说,它的数据页大小是16kb,假设主键索引类型为bigint为8字节,指针在innodb中为6字节,一共14字节,一个节点大概可以容纳下16*1024/14=1170个下级指针,假设一条数据大小为1k,那么一个叶子节点可以存储16条数据,对于10000000万的数据来说, 需要625000个叶子节点来存储,对于一个三层的b+树(包括根节点),可以拥有1170*1170=1368900个叶子节点,其中一层是根节点位于常驻内存中,那么只需要2次IO操作就能访问到叶子节点了