1、es简介
2、es优缺点
3、es使用
4、es可以解决的问题
5、es举例
6、es执行结果截图
7、es数据增量方案
8、使用es搜索
一、es简介
es是一个是一个实时的分布式搜索和分析引擎。它可以帮助你用前所未有的速度去处理大规模数据。
它可以用于全文搜索,结构化搜索以及分析,当然你也可以将这三者进行组合。
es是一个建立在全文搜索引擎 Apache Lucene™ 基础上的搜索引擎,可以说Lucene是当今最先进,最高效的全功能开源搜索引擎框架。
es使用Lucene作为内部引擎,但是在使用它做全文搜索时,只需要使用统一开发好的API即可,而不需要了解其背后复杂的Lucene的运行原理。
es除了做全索引外,还可以做如下工作:
分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
实时分析的分布式搜索引擎。
可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
以上功能可以通过你喜欢的编程语言或客户端与es的restful api进行通讯。
二、概念说了半天了,说下优缺点吧
优点:
1、es是分布式的,不需要其它组件,分发是实时由es主节点内部自动完成的。
2、处理多组用户,而不需特殊配置。
3、es擦用gateway的概念,(gateway:网关是网络连接设备的重要组成部分,它不仅具有路由的功能,而且能在两个不同的协议集之间进行转换,从而使不同的网络之间进行互联。例如:一个Netware局域网通过网关可以访问IBM的SNA网络,这样使用IPX协议的PC就可和SNA网络上的IBM主机进行通信。)是得备份更简单。
4、es节点发生故障时,可以进行自动分配其它节点替代。
缺点:
1、文档太少,不易维护。
2、目前觉得,建索引的速度不够快,期待有更好的方法。
三、es使用(包括创建和搜索以及关闭)
es的获取和关闭方法:
package com.elasticsearch.config;
import static org.elasticsearch.common.xcontent.XContentFactory.jsonBuilder;
import java.util.ArrayList;
import java.util.List;
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.ImmutableSettings;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.common.xcontent.XContentBuilder;
/**
* 初始化连接es服务端,这里相当于dao层..
*
* @author:jackkang
*
* 2013-1-12 下午11:27:37
*/
public class InitES {
static Log log = LogFactory.getLog(InitES.class);
/**
* 静态,单例...
*/
private static TransportClient client;
public static TransportClient initESClient() {
try {
if (client == null) {
// 配置你的es,现在这里只配置了集群的名,默认是elasticsearch,跟服务器的相同
Settings settings = ImmutableSettings
.settingsBuilder()
.put("cluster.name", "elasticsearch")
.put("discovery.type", "zen")//发现集群方式
.put("discovery.zen.minimum_master_nodes", 2)//最少有2个master存在
.put("discovery.zen.ping_timeout", "200ms")//集群ping时间,太小可能会因为网络通信而导致不能发现集群
.put("discovery.initial_state_timeout", "500ms")
.put("gateway.type", "local")//(fs, none, local)
.put("index.number_of_shards", 1)
.put("action.auto_create_index", false)//配置是否自动创建索引
.put("cluster.routing.schedule", "50ms")//发现新节点时间
.build();
// 从属性文件中获取搜索服务器相对域地址
String transportAddresses = Config.getProperty(
"transportAddresses", "");
// 集群地址配置
List<InetSocketTransportAddress> list = new ArrayList<InetSocketTransportAddress>();
if (StringUtils.isNotEmpty(transportAddresses)) {
String[] strArr = transportAddresses.split(",");
for (String str : strArr) {
String[] addressAndPort = str.split(":");
String address = addressAndPort[0];
int port = Integer.valueOf(addressAndPort[1]);
InetSocketTransportAddress inetSocketTransportAddress = new InetSocketTransportAddress(
address, port);
list.add(inetSocketTransportAddress);
}
}
// 这里可以同时连接集群的服务器,可以多个,并且连接服务是可访问的
InetSocketTransportAddress addressList[] = (InetSocketTransportAddress[]) list
.toArray(new InetSocketTransportAddress[list.size()]);
// Object addressList[]=(Object [])list.toArray();
client = new TransportClient(settings)
.addTransportAddresses(addressList);
// 这里可以同时连接集群的服务器,可以多个,并且连接服务是可访问的 192.168.1.102
// client = new TransportClient(settings).addTransportAddresses(
// new InetSocketTransportAddress("192.168.1.103", 9300));
//
// Client client = new TransportClient()
// .addTransportAddress(new
// InetSocketTransportAddress("192.168.0.149", 9300))
// .addTransportAddress(new
// InetSocketTransportAddress("192.168.0.162", 9300));
// 改变shards数目:
/*client.admin().indices().prepareUpdateSettings("test")
.setSettings(ImmutableSettings.settingsBuilder().put("index.number_of_replicas", 2)).execute().actionGet();*/
}
} catch (Exception e) {
// if (log.isDebugEnabled()) {
// log.debug("方法AppCommentAction-deleteAppComment,参数信息:commentid" );
// }
log.error("获取客户端对象异常:" + e.getMessage());
}
return client;
}
public static void closeESClient() {
if (client != null) {
client.close();
}
}
}
搜索:
package com.elasticsearch.action;
import java.io.UnsupportedEncodingException;
import java.net.MalformedURLException;
import java.util.ArrayList;
import java.util.Calendar;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.regex.Pattern;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import com.elasticsearch.config.ElasticsearchUtil;
import com.elasticsearch.pojo.Pager;
import com.opensymphony.xwork2.ActionSupport;
public class SearchAction extends ActionSupport {
private static final long serialVersionUID = 1L;
/** 关键字 **/
private String wd;
/** 消耗时间 **/
private double spendTime;
/** 查询结果集对象 **/
private List<Map<String, Object>> pageList = new ArrayList<Map<String, Object>>();
/** 分页对象 **/
private Pager pager;
/** 总记录数 使用静态变量的方式缓存 **/
private Long total;
private SearchResponse response;
/**
* 条件检索action
*
* @throws MalformedURLException
* @throws SolrServerException
* @throws UnsupportedEncodingException
**/
public String search() throws MalformedURLException,
UnsupportedEncodingException {
/** 检索开始时间 **/
long startTime = System.currentTimeMillis();
/** 获取页面封装好的分页对象 **/
if (pager == null) {
pager = new Pager();
pager.setMaxPageItems(10);
}
wd = new String(wd.getBytes("ISO-8859-1"), "UTF-8"); // 解决乱码
pager.setDefaultMaxPageItems(1);
/**高亮字段**/
String[] highFields=new String[]{"content","title"};
response = ElasticsearchUtil.searcher("medcl", "news",
pager.getOffset(), pager.getMaxPageItems(), wd,highFields);
/** 总记录数 **/
total = response.getHits().totalHits();
System.out.println("命中总数:" + total);
SearchHits searchHits = response.getHits();
SearchHit[] hits = searchHits.getHits();
for (int i = 0; i < hits.length; i++) {
Map<String, Object> map = new HashMap<String, Object>();
SearchHit hit = hits[i];
String id=hit.getId();
String content = ElasticsearchUtil.getHighlightFields(hit,"content");
String title = ElasticsearchUtil.getHighlightFields(hit,"title");
map.put("id", hit.getSource().get("id"));
map.put("content", content);
map.put("title", title);
map.put("create_time", hit.getSource().get("create_time"));
map.put("links", hit.getSource().get("link"));
pageList.add(map);
}
/** 检索完成时间 **/
long endTime = System.currentTimeMillis();
/** 检索花费时间 **/
//spendTime = (double) (endTime - startTime) / 1000;
Calendar c = Calendar.getInstance();
c.setTimeInMillis(endTime - startTime);
spendTime = c.get(Calendar.MILLISECOND);
return SUCCESS;
}
public static String Html2Text(String inputString) {
String htmlStr = inputString; // 含html标签的字符串
String textStr = "";
java.util.regex.Pattern p_script;
java.util.regex.Matcher m_script;
java.util.regex.Pattern p_style;
java.util.regex.Matcher m_style;
java.util.regex.Pattern p_html;
java.util.regex.Matcher m_html;
try {
String regEx_script = "<[\\s]*?script[^>]*?>[\\s\\S]*?<[\\s]*?\\/[\\s]*?script[\\s]*?>"; // 定义script的正则表达式{或<script[^>]*?>[\\s\\S]*?<\\/script>
// }
String regEx_style = "<[\\s]*?style[^>]*?>[\\s\\S]*?<[\\s]*?\\/[\\s]*?style[\\s]*?>"; // 定义style的正则表达式{或<style[^>]*?>[\\s\\S]*?<\\/style>
// }
String regEx_html = "<[^>]+>"; // 定义HTML标签的正则表达式
p_script = Pattern.compile(regEx_script, Pattern.CASE_INSENSITIVE);
m_script = p_script.matcher(htmlStr);
htmlStr = m_script.replaceAll(""); // 过滤script标签
p_style = Pattern.compile(regEx_style, Pattern.CASE_INSENSITIVE);
m_style = p_style.matcher(htmlStr);
htmlStr = m_style.replaceAll(""); // 过滤style标签
p_html = Pattern.compile(regEx_html, Pattern.CASE_INSENSITIVE);
m_html = p_html.matcher(htmlStr);
htmlStr = m_html.replaceAll(""); // 过滤html标签
textStr = htmlStr;
} catch (Exception e) {
System.err.println("Html2Text: " + e.getMessage());
}
return textStr;// 返回文本字符串
}
public String getWd() {
return wd;
}
public void setWd(String wd) {
this.wd = wd;
}
public double getSpendTime() {
return spendTime;
}
public void setSpendTime(double spendTime) {
this.spendTime = spendTime;
}
public List<Map<String, Object>> getPageList() {
return pageList;
}
public void setPageList(List<Map<String, Object>> pageList) {
this.pageList = pageList;
}
public Pager getPager() {
return pager;
}
public void setPager(Pager pager) {
this.pager = pager;
}
public Long getTotal() {
return total;
}
public void setTotal(Long total) {
this.total = total;
}
}
四、可以决绝基金的问题
随着基金系统的逐渐完善,数据量的增加,使用es可以缓解检索数据给数据库带来的压力。
比如,基金中报销的病例列表,报销记录,消费记录等
五、es举例
es使用java链接,创建mapping,保存数据
demo的javabean
package com.elasticsearch;
import com.google.common.collect.Lists;
import com.util.date.Joda_Time;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.XContentFactory;
import java.io.IOException;
import java.util.Date;
import java.util.List;
/**
* javabean
*/
public class User {
private String name;
private String home;//家乡
private double height;//身高
private int age;
private Date birthday;
public User() {
}
public User(String name, String home, double height, int age, Date birthday) {
this.name = name;
this.home = home;
this.height = height;
this.age = age;
this.birthday = birthday;
}
/**
* 随机生成一个用户信息
*
* @return
*/
public static User getOneRandomUser() {
return new User("葫芦" + (int) (Math.random() * 1000) + "娃", "山西省太原市" + (int) (Math.random() * 1000) + "街道", (Math.random() * 1000), (int) (Math.random() * 100), new Date(System.currentTimeMillis() - (long) (Math.random() * 100000)));
}
/**
* 随机生成num个用户信息
*
* @param num 生成数量
* @return
*/
public static List<User> getRandomUsers(int num) {
List<User> users = Lists.newArrayList();
if (num < 0) num = 10;
for (int i = 0; i < num; i++) {
users.add(new User("葫芦" + (int) (Math.random() * 1000) + "娃", "山西省太原市" + (int) (Math.random() * 1000) + "街道", (Math.random() * 1000), (int) (Math.random() * 100), new Date(System.currentTimeMillis() - (long) (Math.random() * 100000))));
}
return users;
}
/**
* 封装对象的Json信息
*
* @param user
* @return
* @throws IOException
*/
public static XContentBuilder getXContentBuilder(User user) throws IOException {
return XContentFactory.jsonBuilder()
.startObject()
.field("name", user.getName())//该字段在上面的方法中mapping定义了,所以该字段就有了自定义的属性,比如 age等
.field("home", user.getHome())
.field("height", user.getHeight())
.field("age", user.getAge())
.field("birthday", user.getBirthday())
.field("state", "默认属性,mapping中没有定义")//该字段在上面方法中的mapping中没有定义,所以该字段的属性使用es默认的.
.endObject();
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getHome() {
return home;
}
public void setHome(String home) {
this.home = home;
}
public double getHeight() {
return height;
}
public void setHeight(double height) {
this.height = height;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Date getBirthday() {
return birthday;
}
public void setBirthday(Date birthday) {
this.birthday = birthday;
}
}
2、java与es交互demo
package com.framework_technology.elasticsearch;
import org.elasticsearch.action.admin.indices.alias.IndicesAliasesRequestBuilder;
import org.elasticsearch.action.admin.indices.alias.exists.AliasesExistRequestBuilder;
import org.elasticsearch.action.admin.indices.alias.exists.AliasesExistResponse;
import org.elasticsearch.action.admin.indices.create.CreateIndexRequestBuilder;
import org.elasticsearch.action.admin.indices.create.CreateIndexResponse;
import org.elasticsearch.action.admin.indices.stats.IndexStats;
import org.elasticsearch.action.bulk.BulkRequestBuilder;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.XContentFactory;
import java.io.IOException;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* mapping创建
* 添加记录到es
*/
public class Es_BuildIndex {
/**
* 索引的mapping
* <p>
* 预定义一个索引的mapping,使用mapping的好处是可以个性的设置某个字段等的属性
* Es_Setting.INDEX_DEMO_01类似于数据库
* mapping 类似于预设某个表的字段类型
* <p>
* Mapping,就是对索引库中索引的字段名及其数据类型进行定义,类似于关系数据库中表建立时要定义字段名及其数据类型那样,
* 不过es的 mapping比数据库灵活很多,它可以动态添加字段。
* 一般不需要要指定mapping都可以,因为es会自动根据数据格式定义它的类型,
* 如果你需要对某 些字段添加特殊属性(如:定义使用其它分词器、是否分词、是否存储等),就必须手动添加mapping。
* 有两种添加mapping的方法,一种是定义在配 置文件中,一种是运行时手动提交mapping,两种选一种就行了。
*
* @throws Exception Exception
*/
protected static void buildIndexMapping() throws Exception {
Map<String, Object> settings = new HashMap<>();
settings.put("number_of_shards", 4);//分片数量
settings.put("number_of_replicas", 0);//复制数量
settings.put("refresh_interval", "10s");//刷新时间
//在本例中主要得注意,ttl及timestamp如何用java ,这些字段的具体含义,请去到es官网查看
CreateIndexRequestBuilder cib = Es_Utils.client.admin().indices().prepareCreate(Es_Utils.LOGSTASH_YYYY_MM_DD);
cib.setSettings(settings);
XContentBuilder mapping = XContentFactory.jsonBuilder()
.startObject()
.startObject("we3r")//
.startObject("_ttl")//有了这个设置,就等于在这个给索引的记录增加了失效时间,
//ttl的使用地方如在分布式下,web系统用户登录状态的维护.
.field("enabled", true)//默认的false的
.field("default", "5m")//默认的失效时间,d/h/m/s 即天/小时/分钟/秒
.field("store", "yes")
.field("index", "not_analyzed")
.endObject()
.startObject("_timestamp")//这个字段为时间戳字段.即你添加一条索引记录后,自动给该记录增加个时间字段(记录的创建时间),搜索中可以直接搜索该字段.
.field("enabled", true)
.field("store", "no")
.field("index", "not_analyzed")
.endObject()
//properties下定义的name等等就是属于我们需要的自定义字段了,相当于数据库中的表字段 ,此处相当于创建数据库表
.startObject("properties")
.startObject("@timestamp").field("type", "long").endObject()
.startObject("name").field("type", "string").field("store", "yes").endObject()
.startObject("home").field("type", "string").field("index", "not_analyzed").endObject()
.startObject("now_home").field("type", "string").field("index", "not_analyzed").endObject()
.startObject("height").field("type", "double").endObject()
.startObject("age").field("type", "integer").endObject()
.startObject("birthday").field("type", "date").field("format", "YYYY-MM-dd").endObject()
.startObject("isRealMen").field("type", "boolean").endObject()
.startObject("location").field("lat", "double").field("lon", "double").endObject()
.endObject()
.endObject()
.endObject();
cib.addMapping(Es_Utils.LOGSTASH_YYYY_MM_DD_MAPPING, mapping);
cib.execute().actionGet();
}
/**
* 给 []index 创建别名
* 重载方法可以按照过滤器或者Query 作为一个别名
*
* @param aliases aliases别名
* @param indices 多个 index
* @return 是否完成
*/
protected static boolean createAliases(String aliases, String... indices) {
IndicesAliasesRequestBuilder builder = Es_Utils.client.admin().indices().prepareAliases();
return builder.addAlias(indices, aliases).execute().isDone();
}
/**
* 查询此别名是否存在
*
* @param aliases aliases
* @return 是否存在
*/
protected static boolean aliasesExist(String... aliases) {
AliasesExistRequestBuilder builder =
Es_Utils.client.admin().indices().prepareAliasesExist(aliases);
AliasesExistResponse response = builder.execute().actionGet();
return response.isExists();
}
/**
* 添加记录到es
* <p>
* 增加索引记录
*
* @param user 添加的记录
* @throws Exception Exception
*/
protected static void buildIndex(User user) throws Exception {
// INDEX_DEMO_01_MAPPING为上个方法中定义的索引,prindextype为类型.jk8231为id,以此可以代替memchche来进行数据的缓存
IndexResponse response = Es_Utils.client.prepareIndex(Es_Utils.LOGSTASH_YYYY_MM_DD, Es_Utils.LOGSTASH_YYYY_MM_DD_MAPPING)
.setSource(
User.getXContentBuilder(user)
)
.setTTL(8000)//这样就等于单独设定了该条记录的失效时间,单位是毫秒,必须在mapping中打开_ttl的设置开关
.execute()
.actionGet();
}
/**
* 批量添加记录到索引
*
* @param userList 批量添加数据
* @throws java.io.IOException IOException
*/
protected static void buildBulkIndex(List<User> userList) throws IOException {
BulkRequestBuilder bulkRequest = Es_Utils.client.prepareBulk();
// either use Es_Setting.client#prepare, or use Requests# to directly build index/delete requests
for (User user : userList) {
//通过add批量添加
bulkRequest.add(Es_Utils.client.prepareIndex(Es_Utils.LOGSTASH_YYYY_MM_DD, Es_Utils.LOGSTASH_YYYY_MM_DD_MAPPING)
.setSource(
User.getXContentBuilder(user)
)
);
}
BulkResponse bulkResponse = bulkRequest.execute().actionGet();
//如果失败
if (bulkResponse.hasFailures()) {
// process failures by iterating through each bulk response item
System.out.println("buildFailureMessage:" + bulkResponse.buildFailureMessage());
}
}
}
数据查看、
通过第三方工具查看
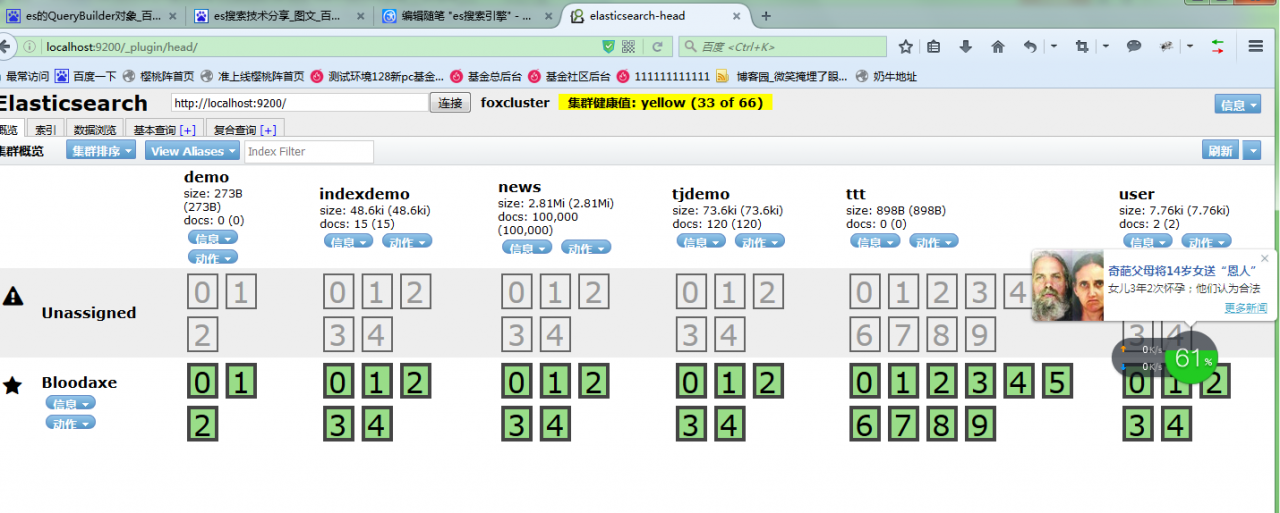
六、执行时间

七、es数据增量方案
1、定时任务轮训,bulk方式操作
批量添加操作:(可以把以前的数据导进来)
/**
* 批量添加记录到索引
*
* @param userList 批量添加数据
* @throws java.io.IOException IOException
*/
protected static void buildBulkIndex(List<User> userList) throws IOException {
BulkRequestBuilder bulkRequest = InitES.buildClient().prepareBulk();
// either use Es_Setting.client#prepare, or use Requests# to directly build index/delete requests
for (User user : userList) {
//通过add批量添加
bulkRequest.add(InitES.buildClient().prepareIndex(LOGSTASH_YYYY_MM_DD, LOGSTASH_YYYY_MM_DD_MAPPING)
.setSource(
User.getXContentBuilder(user)
)
);
}
BulkResponse bulkResponse = bulkRequest.execute().actionGet();
//如果失败
if (bulkResponse.hasFailures()) {
// process failures by iterating through each bulk response item
System.out.println("buildFailureMessage:" + bulkResponse.buildFailureMessage());
}
}
2、用队列做数据同步,异步的方式,生产一条,放在队列里去消费一条。
增量使用队列,当新增一条记录时往es中添加一条记录
protected static void buildIndex(User user) throws Exception {
// INDEX_DEMO_01_MAPPING为上个方法中定义的索引,prindextype为类型.jk8231为id,以此可以代替memchche来进行数据的缓存
IndexResponse response = InitES.buildClient().prepareIndex(LOGSTASH_YYYY_MM_DD, LOGSTASH_YYYY_MM_DD_MAPPING)
.setSource(
User.getXContentBuilder(user)
)
.setTTL(8000)//这样就等于单独设定了该条记录的失效时间,单位是毫秒,必须在mapping中打开_ttl的设置开关
.execute()
.actionGet();
}
es中的QueryBuilders的termQuery查询,
1. 若value为汉字,则大部分情况下,只能为一个汉字;
2. 若value为英文,则是一个单词;
queryString支持多个中文查询
TYPE:
{"mappings":{"carecustomerlog_type_all":{"properties":{"applyrate":{"type":"double"},"careAccountId":{"type":"long"},"careCustomId":{"type":"string","index":"not_analyzed"},"careaccountid":{"type":"long"},"cdate":{"type":"long"},"content":{"type":"string","index":"not_analyzed"},"customerid":{"type":"string","index":"not_analyzed"},"customername":{"type":"string","index":"not_analyzed"},"id":{"type":"long"},"orderid":{"type":"string","index":"not_analyzed"},"preapplyrate":{"type":"long"},"type":{"type":"long"},"watenum":{"type":"string","index":"not_analyzed"}}},"careCustomerLogByCustomerId":{"properties":{"customerid":{"type":"string","index":"not_analyzed"}}}}}
转载于:https://www.cnblogs.com/ywzq/p/5598326.html