文章目录
总流程
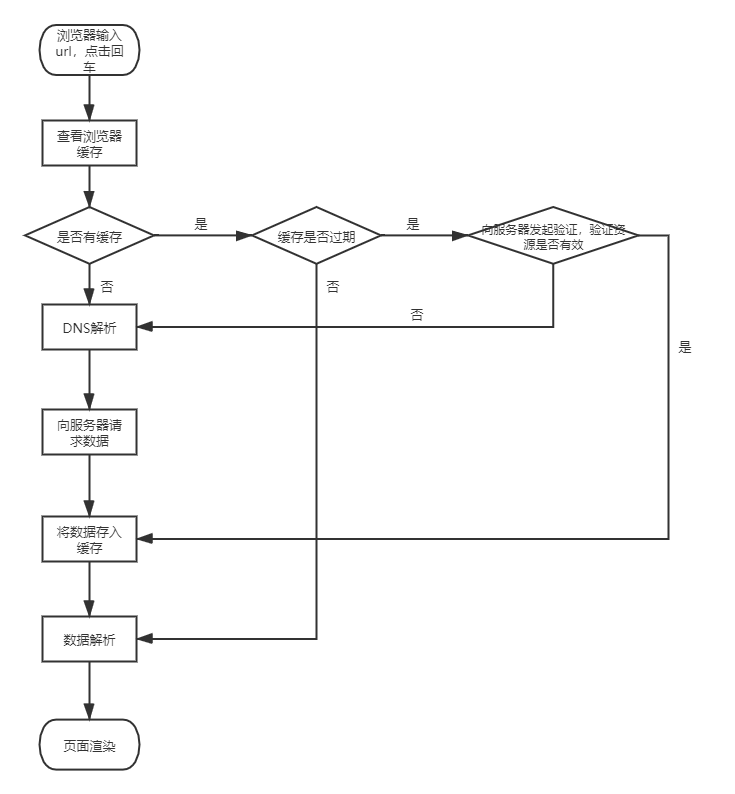
浏览器输入url之后,首先,会从浏览器缓存中查看缓存中是否存在请求的数据,如果存在并且未过期,则触发强缓存,如果存在但是已过期,则触发协商缓存;如果不存在则向服务器发送请求;DNS解析域名成ip地址,浏览器使用ip地址向服务器发送请求,浏览器接收数据,将数据存入缓存当中,解析数据,渲染页面。
浏览器缓存
资源缓存的位置
浏览器的缓存位置分为:memory cache(内存) 和 disk cache(磁盘)
区别:
| memory cache | disk cache | |
|---|---|---|
| 相同点 | 只能存储一些派生类资源文件 | 只能存储一些派生类资源文件 |
| 不同点 | 退出进程时数据会被清除 | 退出进程时数据不会被清除 |
| 存储资源 | 一般脚本、字体、图片会存在内存当中 | 一般非脚本会存在磁盘当中,如css等 |
三级缓存原理
先去内存看,如果有,直接加载
如果内存没有,择取硬盘获取,如果有直接加载
如果硬盘也没有,那么就进行网络请求
加载到的资源缓存到硬盘和内存
比如:访问图片-> 200 -> 退出浏览器
再进来-> 200(from disk cache) -> 刷新 -> 200(from memory cache)
浏览器缓存的分类
- 强缓存
- 协商缓存
浏览器向服务器请求资源时,首先判断是否命中强缓存,再判断是否命中协商缓存
强缓存
浏览器在加载资源是,会现根据本地缓存资源的header中的信息判断是否命中强缓存,如果命中则直接使用浏览器缓存中的资源。
这里 header 中的信息指的是 expires 和 cache-control。
Expires
该字段是 http1.0 时的规范,它的值为一个绝对时间的 GMT 格式的时间字符串,比如 Expires:Mon,18 Oct 2066 23:59:59 GMT。这个时间代表着这个资源的失效时间,在此时间之前,即命中缓存。这种方式有一个明显的缺点,由于失效时间是一个绝对时间,所以当服务器与客户端时间偏差较大时,就会导致缓存混乱。
Cache-Control
Cache-Control 是 http1.1 时出现的 header 信息,主要是利用该字段的 max-age 值来进行判断,它是一个相对时间,例如 Cache-Control:max-age=3600,代表着资源的有效期是 3600 秒。cache-control 除了该字段外,还有下面几个比较常用的设置值:
no-cache:需要进行协商缓存,发送请求到服务器确认是否使用缓存。
no-store:禁止使用缓存,每一次都要重新请求数据。
public:可以被所有的用户缓存,包括终端用户和 CDN 等中间代理服务器。
private:只能被终端用户的浏览器缓存,不允许 CDN 等中继缓存服务器对其缓存。
Cache-Control 与 Expires 可以在服务端配置同时启用,同时启用的时候 Cache-Control 优先级高。
协商缓存
当强缓存没有命中的时候,浏览器会发送一个请求到服务器,服务器根据 header 中的部分信息来判断是否命中缓存。如果命中,则返回 304 ,告诉浏览器资源未更新,可使用本地的缓存。
这里的 header 中的信息指的是 Last-Modify/If-Modify-Since 和 ETag/If-None-Match.
Last-Modify/If-Modify-Since
浏览器第一次请求一个资源的时候,服务器返回的 header 中会加上 Last-Modify,Last-modify 是一个时间标识该资源的最后修改时间。
当浏览器再次请求该资源时,request 的请求头中会包含 If-Modify-Since,该值为缓存之前返回的 Last-Modify。服务器收到 If-Modify-Since 后,根据资源的最后修改时间判断是否命中缓存。
如果命中缓存,则返回 304,并且不会返回资源内容,并且不会返回 Last-Modify。
缺点:
短时间内资源发生了改变,Last-Modified 并不会发生变化。
周期性变化。如果这个资源在一个周期内修改回原来的样子了,我们认为是可以使用缓存的,但是 Last-Modified 可不这样认为,因此便有了 ETag。
ETag/If-None-Match
与 Last-Modify/If-Modify-Since 不同的是,Etag/If-None-Match 返回的是一个校验码。ETag 可以保证每一个资源是唯一的,资源变化都会导致 ETag 变化。服务器根据浏览器上送的 If-None-Match 值来判断是否命中缓存。
与 Last-Modified 不一样的是,当服务器返回 304 Not Modified 的响应时,由于 ETag 重新生成过,response header 中还会把这个 ETag 返回,即使这个 ETag 跟之前的没有变化。
Last-Modified 与 ETag 是可以一起使用的,服务器会优先验证 ETag,一致的情况下,才会继续比对 Last-Modified,最后才决定是否返回 304。
浏览器缓存的优点
- 减少了冗余的数据传输;
- 减少了服务器的负担,大大提升了网站的性能;
- 加快了客户端加载网页的速度
DNS
什么是DNS
全称 Domain Name System ,即域名系统
万维网上作为域名和IP地址相互映射的一个分布式数据库,能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串。DNS协议运行在UDP协议之上,使用端口号53。
DNS解析
DNS解析过程就是将输入的域名解析成ip地址的过程。
比如访问 www.baidu.com
- 首先,会向浏览器缓存查找是否有域名对应的
ip地址,如果有则返回; - 如果浏览器缓存中没有,则查找本地
hosts文件中是否存在域名对应的ip地址,如果有则返回; - 如果
hosts文件中没有,则查找本地 DNS 服务器,如果有则返回; - 如果本地 DNS 服务器中没有,则向根域名服务器查询,根域名服务器会返回
.com的ip地址; - 本地DNS服务器根据
.com的ip地址到顶级域名服务器查询baidu.com的ip地址并返回; - 本地 DNS 服务器根据
baidu.com的 ip 地址到权威域名服务器查询www.baidu.com的 ip 地址,到此,域名 ip 地址 找到了,返回给本地 DNS 服务器; - 本地 DNS 服务器再将查询到的 ip 地址返回给浏览器,由浏览器根据 ip 地址发送请求。
浏览器向本地DNS服务器查询的过程一般是 递归查询,本地DNS服务器向其他DNS服务器之间的查询一般是 迭代查询
浏览器请求数据
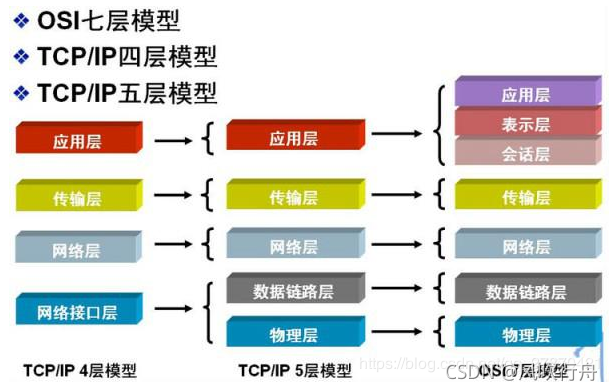
TCP/IP协议的分层
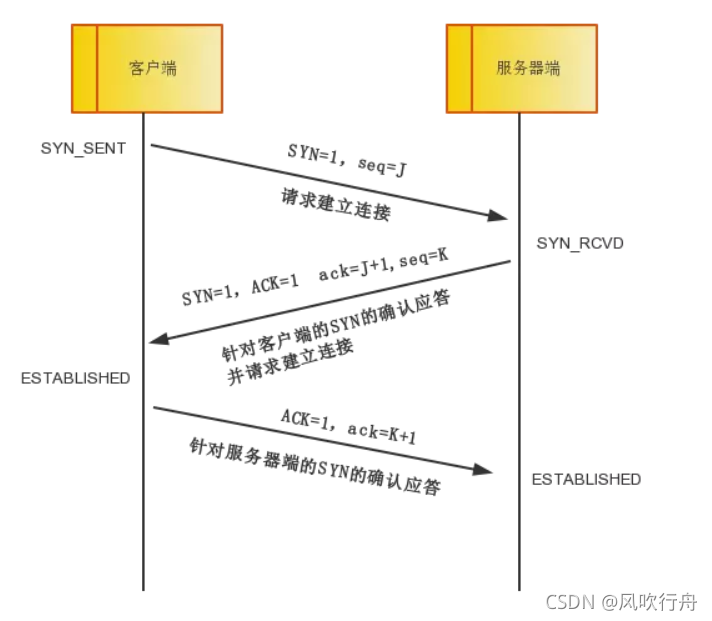
TCP三次握手和四次挥手
三次握手
为什么需要三次握手?
如果是两次握手的话,客户端向服务端发送一次连接请求,服务端响应,但是这时候由于网络原因,响应迟迟未到客户端,客户端就会以为服务端未收到连接请求,就重新发送连接请求建立新的连接,但是服务端并不知道第一次的连接已经失效,还会等待客户端通过第一次的连接传输数据,这样服务端的资源就被浪费掉了。
采用三次握手的话,第一次的连接需要服务端收到客户端的确认之后才会建立,客户端由于没有收到服务端的确认,所以并不会向服务端发送确认信号,所以连接不会建立。
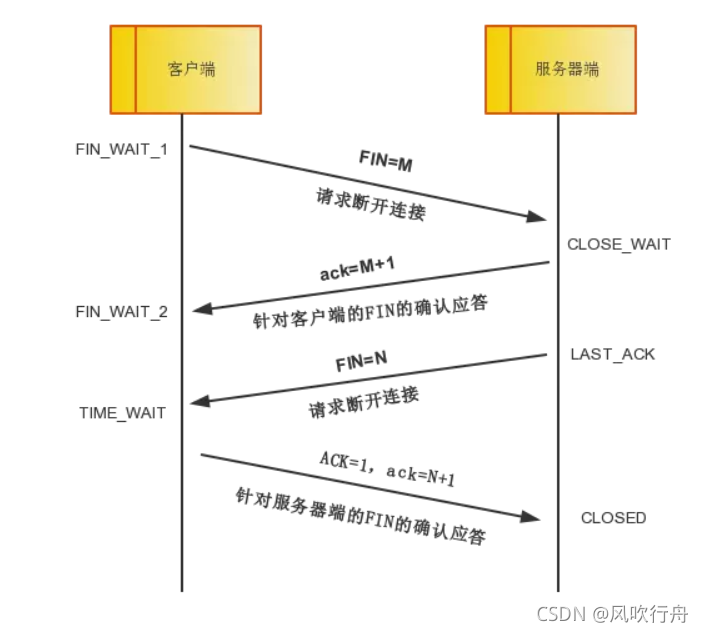
四次挥手
TCP拥塞控制算法
UDP
特点:
面向无连接
UDP不用像TCP一样需要三次握手建立连接之后再发送数据,而是想发就发,不会对报文进行任何拆分和凭借操作
有单播、多播、广播的功能
UDP不止支持一对一的传输方式,还支持一对多,多对多的方式
UDP是面向报文的
不可靠性
不可靠性体现在无连接上,收到什么数据就传递什么数据
头部开销小,传输数据报文时是很高效的
TCP和UDP的区别
| UDP | TCP | |
|---|---|---|
| 是否连接 | 无连接 | 面向连接 |
| 是否可靠 | 不可靠传输,不使用流量控制和拥塞控制 | 可靠传输,使用流量控制和拥塞控制 |
| 连接对象个数 | 支持一对一,一对多,多对一和多对多交互通信 | 只能是一对一通信 |
| 传输方式 | 面向报文 | 面向字节流 |
| 首部开销 | 首部开销小,仅8字节 | 首部最小20字节,最大60字节 |
| 适用场景 | 适用于实时应用(IP电话、视频会议、直播等) | 适用于要求可靠传输的应用,例如文件传输 |
请求头和响应头常见字段
HTTP 1.0,1.1,2.0,3.0
HTTP 1.0和1.1的区别
长连接
由于HT TP 1.0规定浏览器和服务器之间的只保持短暂的连接,浏览器每次请求都与服务器建立一个新的连接,浏览器接收到服务器的响应后,立即断开TCP连接,每次建立和关闭来连接是一个相对比较费时的过程,会严重影响浏览器和服务器的性能。
http1.1支持了长连接和请求的流水线来处理,在一个TCP连接上可以传送多个http请求和响应,减少了建立和关闭连接的消耗和延迟,在http1.1当中默认开启长连接keep-alive(在请求头和响应头中会有connection: keep-alive字段),一定程度上弥补了HTTP1.0每次请求都要创建连接的缺点。HTTP1.1需要使用keep-alive参数来告知服务器端要建立一个长连接。
节约带宽
HTTP1.0中存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能。HTTP1.1支持只发送header信息(不带任何body信息),如果服务器认为客户端有权限请求服务器,则返回100,客户端接收到100才开始把请求body发送到服务器;如果返回401,客户端就可以不用发送请求body了节约了带宽。
缓存处理
在HTTP1.0中主要使用header里的Expires(强缓存),Last-Modify/If-Modified-Since(协商缓存)来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Cache-Contral(强缓存),Etag/If-None-Match(协商缓存)等更多可供选择的缓存头来控制缓存策略。
HTTP 1.1的缺陷
- 高延迟-队头阻塞
- 无状态特性-阻碍交互
- 不安全性-明文传输
如何避免长连接浪费资源:
- 客户端请求头设置 connection: close
- 服务端配置长连接超时时间
- 系统内核参数设置:
net.ipv4.tcp_keepalive_time = 60,连接闲置60秒后,服务端尝试向客户端发送侦测包,判断TCP连接状态,如果没有收到ack反馈就在net.ipv4.tcp_keepalive_intvl = 10,就在10秒后再次尝试发送侦测包,直到收到ack反馈,一共会net.ipv4.tcp_keepalive_probes = 5,一共会尝试5次,要是都没有收到就关闭这个TCP连接了
HTTP 2
二进制分帧
**帧:**HTTP/2 数据通信的最小单位消息:指 HTTP/2 中逻辑上的 HTTP 消息。例如请求和响应等,消息由一个或多个帧组成。
**流:**存在于连接中的一个虚拟通道。流可以承载双向消息,每个流都有一个唯一的整数ID。
HTTP/2 采用二进制格式传输数据,而非 HTTP 1.x 的文本格式,二进制协议解析起来更高效。 HTTP / 1 的请求和响应报文,都是由起始行,首部和实体正文(可选)组成,各部分之间以文本换行符分隔。HTTP/2 将请求和响应数据分割为更小的帧,并且它们采用二进制编码。
**HTTP/2 中,同域名下所有通信都在单个连接上完成,该连接可以承载任意数量的双向数据流。**每个数据流都以消息的形式发送,而消息又由一个或多个帧组成。多个帧之间可以乱序发送,根据帧首部的流标识可以重新组装。
头部压缩
HTTP/2对消息头采用HPACK(专为http 2头部设计的压缩格式)进行压缩传输,能够节省消息头占用的网络的流量。
多路复用
**HTTP/2 中,同域名下所有通信都在单个连接上完成,该连接可以承载任意数量的双向数据流。**每个数据流都以消息的形式发送,而消息又由一个或多个帧组成。多个帧之间可以乱序发送,根据帧首部的流标识可以重新组装。
服务端推送
服务端可以在发送页面HTML时主动推送其它资源,而不用等到浏览器解析到相应位置,发起请求再响应。例如服务端可以主动把JS和CSS文件推送给客户端,而不需要客户端解析HTML时再发送这些请求。
服务端可以主动推送,客户端也有权利选择是否接收。如果服务端推送的资源已经被浏览器缓存过,浏览器可以通过发送RST_STREAM帧来拒收。主动推送也遵守同源策略,服务器不会随便推送第三方资源给客户端。
HTTP 2的缺陷
- 头部阻塞没有彻底解决
- 多路复用导致服务器压力上升
- 多路复用容易timeout
cookie
属性:Name、Value、Domain、Path、Expires/Max-age、Size、HttpOnly、Secure、SameSite和Priority
name和value
Name和Value是一个键值对。Name是Cookie的名称,Cookie一旦创建,名称便不可更改,一般名称不区分大小写;Value是该名称对应的Cookie的值,如果值为Unicode字符,需要为字符编码。如果值为二进制数据,则需要使用BASE64编码。
Domain
Domain决定Cookie在哪个域是有效的,也就是决定在向该域发送请求时是否携带此Cookie,Domain的设置是对子域生效的,如Doamin设置为 .a.com,则b.a.com和c.a.com均可使用该Cookie,但如果设置为b.a.com,则c.a.com不可使用该Cookie。Domain参数必须以点(".")开始。
Path
Path是Cookie的有效路径,和Domain类似,也对子路径生效,如Cookie1和Cookie2的Domain均为a.com,但Path不同,Cookie1的Path为 /b/,而Cookie的Path为 /b/c/,则在a.com/b页面时只可以访问Cookie1,在a.com/b/c页面时,可访问Cookie1和Cookie2。Path属性需要使用符号“/”结尾。
Expires/Max-age
Expires和Max-age均为Cookie的有效期,Expires是该Cookie被删除时的时间戳,格式为GMT,若设置为以前的时间,则该Cookie立刻被删除,并且该时间戳是服务器时间,不是本地时间!若不设置则默认页面关闭时删除该Cookie。 Max-age也是Cookie的有效期,但它的单位为秒,即多少秒之后失效,若Max-age设置为0,则立刻失效,设置为负数,则在页面关闭时失效。Max-age默认为 -1。
size
Size是此Cookie的大小。在所有浏览器中,任何cookie大小超过限制都被忽略,且永远不会被设置。各个浏览器对Cookie的最大值和最大数目有不同的限制,整理为下表(数据来源网络,未测试):
HttpOnly
HttpOnly值为 true 或 false,若设置为true,则不允许通过脚本document.cookie去更改这个值,同样这个值在document.cookie中也不可见,但在发送请求时依旧会携带此Cookie。
Secure
Secure为Cookie的安全属性,若设置为true,则浏览器只会在HTTPS和SSL等安全协议中传输此Cookie,不会在不安全的HTTP协议中传输此Cookie。
SameSite
SameSite用来限制第三方 Cookie,从而减少安全风险。它有3个属性,分别是:
Strict
Scrict最为严格,完全禁止第三方Cookie,跨站点时,任何情况下都不会发送Cookie
Lax
Lax规则稍稍放宽,大多数情况也是不发送第三方 Cookie,但是导航到目标网址的 Get 请求除外。
None
网站可以选择显式关闭SameSite属性,将其设为None。不过,前提是必须同时设置Secure属性(Cookie 只能通过 HTTPS 协议发送),否则无效。
另外:关闭SameSite的方法
操作方法谷歌浏览器地址栏输入:chrome://flags/ 找到:SameSite by default cookies、Cookies without SameSite must be secure设置上面这两项设置成 Disable
Priority
优先级,chrome的提案,定义了三种优先级,Low/Medium/High,当cookie数量超出时,低优先级的cookie会被优先清除。
cookie 和 session
什么是Cookie
HTTP Cookie是服务器发送到浏览器并保存到本地的一小块数据,他会在浏览器下次向服务器发送请求的时候被携带发送到服务器。
Cookie主要用于以下三个方面:
- 会话状态管理(如登录状态、购物车、游戏分数或其他需要记录的数据)
- 个性化设置(如用户自定义设置,主题等)
- 浏览器行为跟踪(如跟踪分析用户行为等)
什么是session
Session代表着服务器和客户端一次会话的过程。
Session对象存储特定用户会话所需要的属性和配置。这样,当用户在Web页面之间跳转时,存储在Session对象中的变量将不会丢失,而是在整个用户对话中保存下去。
当客户端关闭会话,或者Session超时失效时会话结束。
Cookie和Session有什么不同
- 作用范围不同,Cookie保存在客户端(浏览器),Session保存在服务器端;
- 存取方式不同,Cookie只能保存ASCII,Session可以保存任意数据类型;
- 有效期不同,Cookie可设置为长时间保存,比如经常使用的默认登录功能,Session一般失效时间较短,客户端关闭或者Session超时都会失效;
- 隐私策略不同,Cookie存储在客户端,比较容易遭到不法获取,Session存储在服务端,安全性相对Cookie要好一些;
- 存储大小不同,单个Cookie保存的数据不能超过4K,Session可存储数据远高于Cookie。
Cookie和Session有什么关联,为什么需要他们
由于浏览器是没有状态的(HTTP协议无状态),这意味着浏览器并不知道是谁在和服务器打交道。所以这个时候需要一个机制来告诉服务器,本次操作用户是否登录,是哪个用户在执行这个操作,这套机制的实现就需要Cookie和Session的配合。
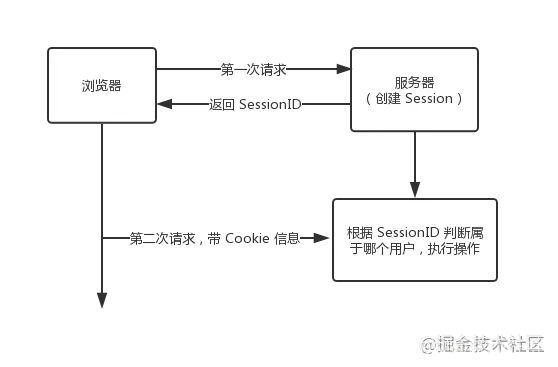
用户第一次请求服务器时,服务器根据用户提交的相关信息,创建对应的Session,请求返回时将此Session的唯一标识SessionID返回给浏览器,浏览器接收到服务器返回的SessionID信息后,会将信息保存到Cookie里面,同时Cookie记录此SessionID属于哪个域名。
当用户第二次请求时,请求会自动判断当前域名下是否存在Cookie信息,如果存在则自动将Cookie信息也发送给服务端,服务端会从Cookie中获取SessionID,再根据SessionID查找对应的Session信息,如果没有找到,则说明用户没有登录或者登录失效,如果找到Session证明用户已经登录可以执行后面操作。
如果浏览器中禁止了Cookie,如何保障整个机制的正常运转
第一种方案,每次请求中都携带一个 SessionID 的参数,也可以 Post 的方式提交,也可以在请求的地址后面拼接
xxx?SessionID=123456...。第二种方案,Token 机制。Token 机制多用于 App 客户端和服务器交互的模式,也可以用于 Web 端做用户状态管理。
Token 的意思是“令牌”,是服务端生成的一串字符串,作为客户端进行请求的一个标识。Token 机制和 Cookie 和 Session 的使用机制比较类似。
当用户第一次登录后,服务器根据提交的用户信息生成一个 Token,响应时将 Token 返回给客户端,以后客户端只需带上这个 Token 前来请求数据即可,无需再次登录验证。
如何考虑分布式Session问题
在互联网公司为了可以支撑更大的流量,后端往往需要多台服务器共同来支撑前端用户请求,那如果用户在 A 服务器登录了,第二次请求跑到服务 B 就会出现登录失效问题。
分布式 Session 一般会有以下几种解决方案:
- Nginx ip_hash 策略,服务端使用 Nginx 代理,每个请求按访问 IP 的 hash 分配,这样来自同一 IP 固定访问一个后台服务器,避免了在服务器 A 创建 Session,第二次分发到服务器 B 的现象。
- Session 复制,任何一个服务器上的 Session 发生改变(增删改),该节点会把这个 Session 的所有内容序列化,然后广播给所有其它节点。
- 共享 Session,服务端无状态化,将用户的 Session 等信息使用缓存中间件来统一管理,保障分发到每一个服务器的响应结果都一致。
建议采用第三种方案。
参考资料
cookie、sessionStorge和localStroge的区别
| 特性 | Cookie | localStorage | sessionStorage |
|---|---|---|---|
| 数据的生命期 | 一般由服务器生成,可设置失效时间。如果在浏览器端生成Cookie,默认是关闭浏览器后失效 | 除非被清除,否则永久保存 | 仅在当前会话下有效,关闭页面或浏览器后被清除 |
| 存放数据大小 | 4KB左右 | 一般为5MB | 同localstroage |
| 与服务器端通信 | 每次都会携带在HTTP头中,发送给服务端。但是使用cookie保存过多数据会带来性能问题 | 仅在客户端(即浏览器)中保存,不和服务器的通信 | 同localstroage |
get和post请求
GET在浏览器回退时是无害的,而POST会再次发起请求GET请求会被浏览器主动缓存,而POST不会,除非手动设置GET请求参数会被保留在浏览器历史记录里,而POST中的参数不会被保留GET请求在URL中传递的参数有长度限制(浏览器限制大小不同),而POST没有限制GET参数通过URL传递,POST放在Request body中GET产生的URL地址可以被收藏,而POST不可以GET没有POST安全,因为GET请求参数直接暴露在URL上,所以不能用来传递敏感信息GET请求只能进行URL编码,而POST支持多种编码方式对参数的数据类型,
GET只接受ASCII字符,而POST没有限制GET产生一个TCP数据包,POST产生两个数据包(Firefox只发一次)。GET浏览器把 http header和data一起发出去,响应成功200,POST先发送header,响应100 continue,再发送data,响应成功200
常用响应码
1xx:
表示目前协议处理的中间状态,还需要后续操作
- 101Switching Protocols。在HTTP升级为WevSocket的时候,如果如果服务器同意变更,就会发送状态码 101.
2xx:
表示成功状态
- 200 OK 是见得最多的状态码,通常响应体中有数据
- 204 No Content 含义与200相同,但响应头后没有body数据
- 206 Partial Content顾名思义,表示部分内容,它的使用场景为 HTTP 分块下载和断点续传,当然也会带上相应的响应头字段
Content-Range。
3xx:
重定向状态,资源位置发生变动,需要重新请求
- 301 Moved Permanently 即永久重定向
- 302 Found 即临时重定向
- 304 Not Modified 当协商缓存命中时会返回该状态码
4xx:
- 400 Bad Request: 开发者经常看到一头雾水,只是笼统地提示了一下错误,并不知道哪里出错了。
- 403 Forbidden: 这实际上并不是请求报文出错,而是服务器禁止访问,原因有很多,比如法律禁止、信息敏感。
- 404 Not Found: 资源未找到,表示没在服务器上找到相应的资源。
- 405 Method Not Allowed: 请求方法不被服务器端允许。
- 406 Not Acceptable: 资源无法满足客户端的条件。
- 408 Request Timeout: 服务器等待了太长时间。
- 409 Conflict: 多个请求发生了冲突。
- 413 Request Entity Too Large: 请求体的数据过大
- 414 Request-URI Too Long: 请求行里的 URI 太大
- 429 Too Many Request: 客户端发送的请求过多。
- 431 Request Header Fields Too Large请求头的字段内容太大。
请求报文有误
5xx:
服务端发生错误
500 Internal Server Error: 仅仅告诉你服务器出错了,出了啥错咱也不知道。
501 Not Implemented: 表示客户端请求的功能还不支持。
502 Bad Gateway: 服务器自身是正常的,但访问的时候出错了,啥错误咱也不知道。
503 Service Unavailable: 表示服务器当前很忙,暂时无法响应服务。
HTTPS
对称加密
加密和解密使用同一个密钥,加解密过程:
- 浏览器发送给服务器一个client-random和一个支持的加密方法列表
- 服务器给浏览器返回一个server-random和双方都支持的加密方法
- 然后双方使用client-random和server-random生成密钥,这就是双方通信时使用的密钥
非对称加密
一对密钥,有公钥(public key)和私钥(private key),其中一个密钥加密后的数据,只能用另一个密钥进行解密。加解密过程:
- 浏览器发送给服务器一个client-random和一个支持的加密方法列表
- 服务器发送给浏览器一个server-random、双方都支持的加密方法和公钥
- 浏览器将client-random和server-random使用公钥进行加密,生成密钥,这个密钥只能用私钥解密
TLS
使用 对称 和 非对称 两种加密方法的混合加密。使用 非对称加密 交换 对称加密 的密钥,再使用对称加密进行加解密数据传输。
- 浏览器发送给服务器client-random和一个支持的加密方法列表
- 服务器发送给浏览器server-random、公钥、和双方都支持的加密方法
- 浏览器又生成一个pre-random,使用公钥加密后发送给服务器
- 服务器使用私钥解密
- 双方用三个随机数用加密方法生成最终密钥
摘要算法
主要用于保证数据的完整性。常见的又 MD5算法、散列算法、哈希函数算法,特点是 单向性、无法反推原文
ca证书(数字证书)
用于验证 服务器身份。
数字证书需要向有权威的认证机构(CA)获取授权给服务器。首先,服务器和CA机构分别有一对密钥(公钥和私钥)。
证书生成:
- CA机构通过摘要算法,生成服务器公钥的摘要
- CA机构通过 CA私钥 及特定的签名算法加密摘要,生成签名
- 把 签名、服务器公钥 等信息打包放入 数字证书,并返回给服务器
服务器配置好证书,以后客户端连接服务器,都先把证书发给客户端验证并获取服务器的公钥。
证书验证:
- 使用 CA私钥 和 声明的签名算法 对CA证书中的签名进行解密,得到服务器公钥的摘要
- 再使用摘要算法对证书里面的服务器公钥生成摘要,再把生成的摘要和上一步解析出来的摘要进行对比,如果相同则说明证书合法,里面的公钥也是正确的。
RSA握手
早期的TLS密钥交换法就是使用RSA握手
- 浏览器发送给服务器client-random和一个支持的加密方法列表
- 服务器发送给浏览器server-random、公钥、和双方都支持的加密方法
- 浏览器又生成一个pre-random,使用公钥加密后发送给服务器
- 服务器使用私钥解密
- 双方用三个随机数用加密方法生成最终密钥
TLS 1.2版
HTTP和HTTPS的区别
浏览器渲染
我的总结:My Summary
参考资料