今天做数据仓库这个项目因为用到了hive,把hive的元数据信息存到mysql里面,所以配置了一个mysql,先来说说HA的mysql是什么回事。先看一下图片: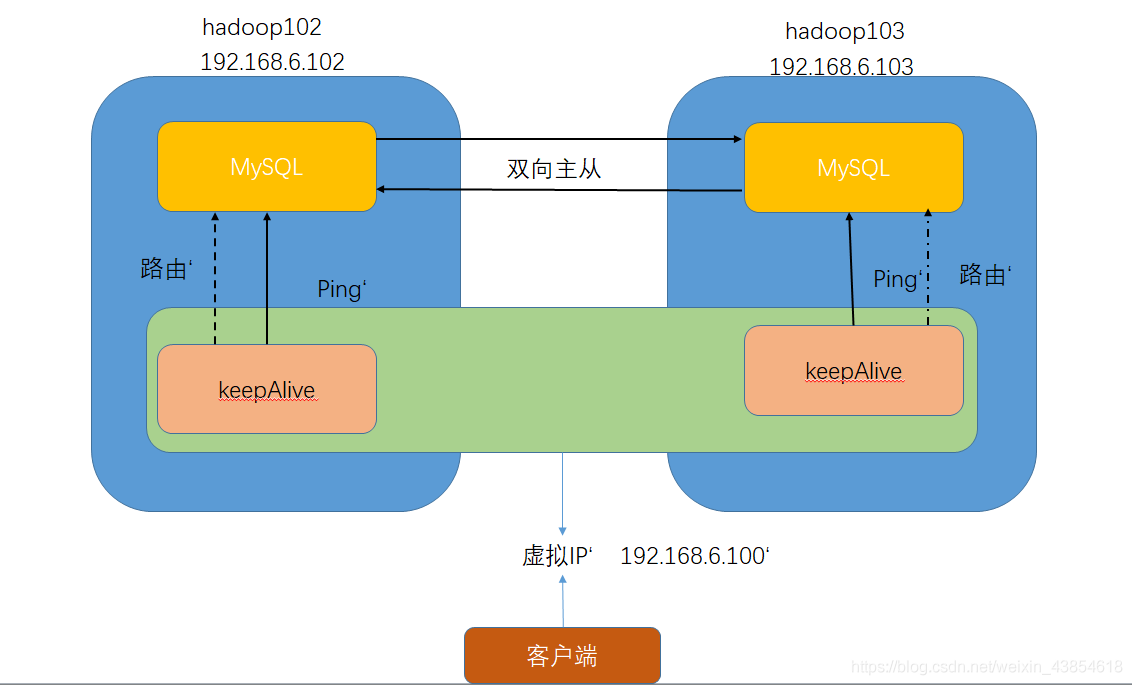
我这里配置的是一个双向主从的集群,双向主从的意思就是两台机器都有可能成为master和slave,他们对外只提供一个IP,这两台机器的数据会同步一致,这是怎么做到的呢?其实就是安装一个keepAlive,两台机器的keepAlive只有一个会占用这个虚拟IP,keepAlive定期向mysql进程发送心跳,如果当mysql进程宕掉了,keepAlive进程收不到回复,它就会自动结束自己的进程,如果是当前占用着这个IP的keepAlive自杀了的话另一个keepAlive就会迅速占用这个虚拟IP,这样达到一个高可用的目的。
这里需要注意一个小细节,在开机后,因为mysql进程和keepAlive进程都是开机自动启动的,这里就会有一个先后问题,如果是keepAlive先启动的,而mysql还没启动,keepAlive发送心跳包没有回应,keepAlive就会自动结束进程,这样就会使对外的IP少了一台机器。
如何查看一个自启动服务在开机时的启动顺序?所有自启动的开机服务,都会在/etc/init.d下生成一个启动脚本!例如mysql的开机自启动脚本就在 /etc/init.d/mysql,keepalived的开机自启动脚本就在 /etc/init.d/keepalived在这脚本里面,就有这个进程启动的信息,如下: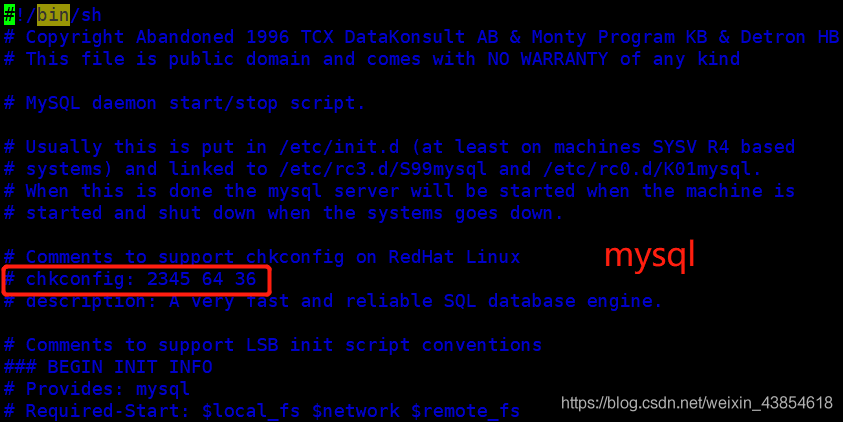
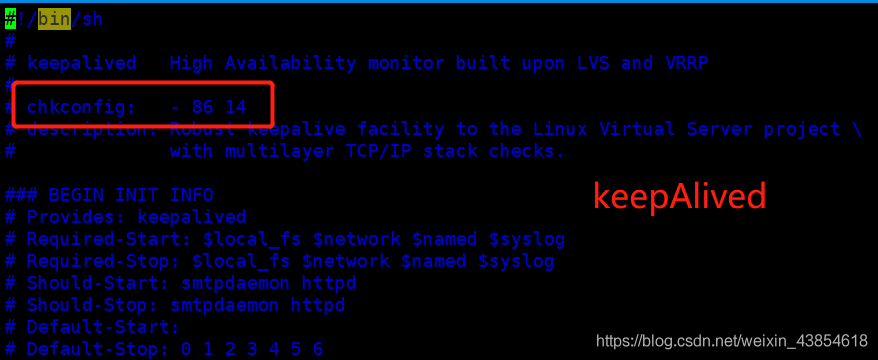
红框里面的参数在这里解释一下,例如mysql那里:2345(启动级别,-代表全级别) 64(开机的启动的顺序,号小的先启动) 36(关机时服务停止的顺序) ,因为64<86,所以mysql会先于keepAlive启动,所以不用担心上述问题。如果不是这样的顺序的话建议不要随便改,因为这是系统的进程启动程序,改了可能会与某些进程顺序冲突,或者某些进程原来要先于某些进程的,改了导致顺序改变了,系统会有问题,所以这个要慎重修改。
说完原理,接下来说一下部署过程:
在两台机器上安装好mysql
编辑my.cnf
到/usr/share/mysql下找mysql服务端配置的模版执行:sudo cp my-default.cnf /etc/my.cnf
在[mysqld]下配置:
server_id = 103
log-bin=mysql-bin
binlog_format=mixed
relay_log=mysql-relay
另外一台,配置也一样,只需要修改servei_id重启mysql服务
service mysql restart
- 在主机上使用root@localhost登录,授权从机可以使用哪个用户登录
GRANT replication slave ON *.* TO 'slave'@'%' IDENTIFIED BY '123456';
- 查看主机binlog文件的最新位置
在mysql下执行如下命令,第二列即为binlog文件的最新位置,这个需要记住,等下要用,图片是我使用mysql一段时间后截的,所以数值和我执行的命令那里有点不匹配。
show master status;
- 在从机上执行以下语句
change master to master_user='slave', master_password='123456',master_host='192.168.218.103',master_log_file='mysql-bin.000001',master_log_pos=311;
- 在从机上开启同步线程
start slave;
- 查看同步线程的状态
如果圈里面的两个属性都是yes的话就是配置成功,因为我不部署的是双向主从,所以要在另一台机执行同样的操作。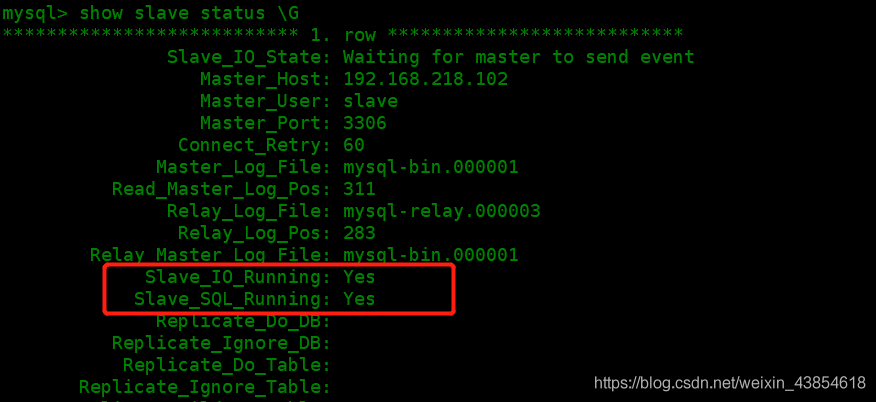
show slave status \G
- 在hadoop103和hadoop102安装keepalive软件
1.安装
sudo yum install -y keepalived
2.配置
sudo vim /etc/keepalived/keepalived.conf
参考配置文件
3.编辑当前机器keepalived检测到mysql故障时的通知脚本
sudo vim /etc/keepalived/keepalived.conf
添加如下内容:
#!/bin/bash
#停止当前机器的keepalived进程
sudo service keepalived stop
4.开机自启动keepalived服务
sudo chkconfig keepalived on
5.启动keepalived服务,只需要当前启动,以后都可以开机自启动
sudo service keepalived start