简介
java的io是实现输入和输出的基础,可以方便的实现数据的输入和输出操作。在java中把不同的输入/输出源(键盘,文件,网络连接等)抽象表述为“流”(stream)。通过流的形式允许java程序使用相同的方式来访问不同的输入/输出源。流是一种有顺序的,有起点和终点的字节集合,是对数据传输的总称或抽象。即数据在两个设备间的传输成为流,流的本质是数据传输。
流的分类:
● 按流向:输入流、输出流;
● 按数据类型:字节流(8位字节)、字符流(16位字节)。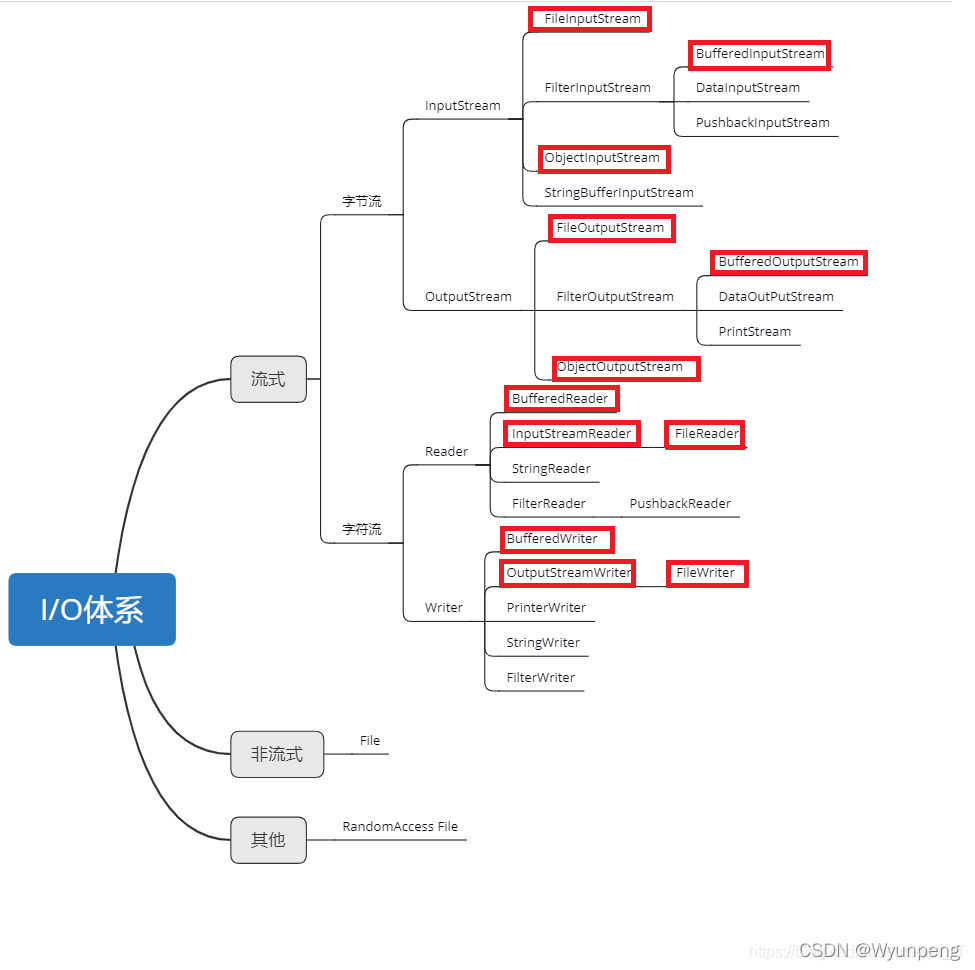
字节流
继承关系
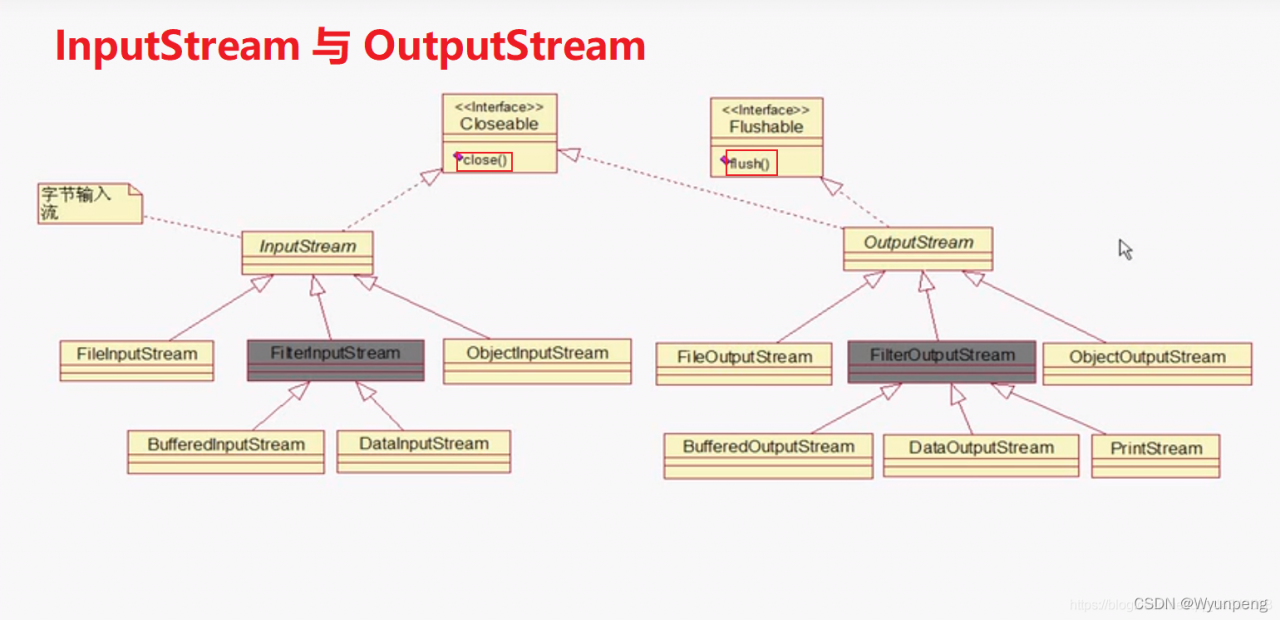
字节输出流(OutPutStream)
java.io.OutPutStream抽象类是表示字节输出流的所有类的超类(父类),将指定的字节信息写出到目的地;它定义了字节输出流的基本共性功能方法。
基本方法
public void close():关闭此输出流并释放与此流相关联的任何系统资源;public void flush():刷新此输出流并强制任何缓冲的输出字节被写出;public void write(byte[] b):将 b.length个字节从指定的字节数组写入此输出流;public void write(byte[] b, int off, int len):从指定的字节数组写入 len字节,从偏移量 off开始输出到此输出流。 也就是说从off个字节数开始读取一直到len个字节结束;public abstract void write(int b):将指定的字节写入输出流。
子类实例演示(FileOutputStream)
- 构造方法
a.public FileOutputStream(File file):根据File对象为参数创建对象;
b.public FileOutputStream(String name):根据名称字符串为参数创建对象。
c.public FileOutputStream(File file, boolean append):创建新的输出流对象并指定是否追加续写;
在构造过程中,程序做了三件事:
- 调用系统功能去创建文件(输出流对象才会自动创建);
- 创建OutputStream对象;
- 把FileOutputStream对象指向这个文件。
注:创建输出流对象的时候,系统会自动去对应位置创建对应文件,而创建输出流对象的时候,文件不存在则会报FileNotFoundException异常,也就是系统找不到指定的文件异常。
- 代码演示
package com.wyp.mall_study;
import java.io.*;
public class Test {
public static void main(String[] args) throws Exception{
OutputStream out = new FileOutputStream("test.txt");
// 写入单个字节
out.write(97);
//换行
out.write("\r\n".getBytes());
// 写入字节数组
byte[] b = new String("abcde").getBytes();
out.write(b);
out.write("\r\n".getBytes());
// 写入指定长度的字节数组
out.write(b,1,2);
// 关闭资源
out.close();
}
}
/**
* 文件内容:
* a
* abcde
* bc
*/
字节输入流(InputStream)
java.io.InputStream抽象类是表示字节输入流的所有类的超类(父类),可以读取字节信息到内存中。它定义了字节输入流的基本共性功能方法。
基本方法
public void close():关闭此输入流并释放与此流相关联的任何系统资源;public abstract int read():从输入流读取数据的下一个字节;public int read(byte[] b):该方法返回的int值代表的是读取了多少个字节,读到几个返回几个,读取不到返回-1。
子类实例演示(FileInputStream)
- 构造方法
a.FileInputStream(File file): 通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件系统中的 File对象 file命名。
b.FileInputStream(String name): 通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件系统中的路径名name命名。 - 实例
package com.wyp.mall_study;
import java.io.*;
/**
* 文件内容
* abcde
*/
public class Test {
public static void main(String[] args) throws Exception{
// 使用文件名称创建流对象.
InputStream in = new FileInputStream("test.txt");
// 定义字节数组,作为装字节数据的容器
byte[] b = new byte[2];
// 循环读取
while (in.read(b) != -1){
// 每次读取后,把数组变成字符串打印
System.out.println(new String(b));
}
// 关闭资源
in.close();
}
}
/**
* 输出:
* ab
* cd
* ed
*/
可以看到该输出并不符合我们的预期,这是因为在最后一次读取时,只读取了一个字节即’e’,而数组中上一次读取的’d’并没有被替换掉;改进版如下:
package com.wyp.mall_study;
import java.io.*;
/**
* 文件内容
* abcde
*/
public class Test {
public static void main(String[] args) throws Exception{
// 使用文件名称创建流对象.
InputStream in = new FileInputStream("test.txt");
// 定义字节数组,作为装字节数据的容器
byte[] b = new byte[2];
// 定义变量,作为有效个数
int len;
while ((len = in.read(b)) != -1){
// 每次读取后,把数组的有效字节部分,变成字符串打印
// len为每次读取的有效字节个数
System.out.println(new String(b,0,len));
}
// 关闭资源
in.close();
}
}
/**
* 输出:
* ab
* cd
* e
*/
字符流
因为数据编码的不同,因而有了对字符进行高效操作的流对象,字符流本质其实就是基于字节流读取时,去查了指定的码表,而字节流直接读取数据会有乱码的问题(读中文会乱码)。尽管字节流也能有办法决绝乱码问题,但是还是比较麻烦,于是java就有了字符流,以字符为单位读写数据,字符流专门用于处理文本文件。如果处理纯文本的数据优先考虑字符流,其他情况就只能用字节流了(图片、视频、等等只文本例外)。从另一角度来说:字符流 = 字节流 + 编码表。
继承关系
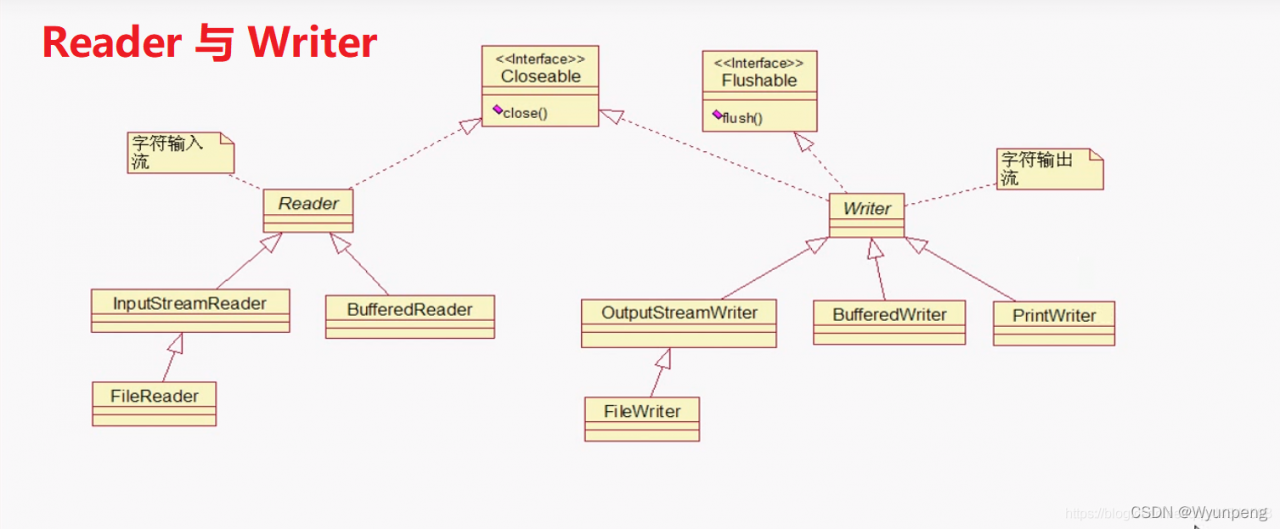
字符输出流(Writer)
java.io.Writer抽象类是字符输出流的所有类的超类(父类),将指定的字符信息写出到目的地。它同样定义了字符输出流的基本共性功能方法。
基本方法
void write(int c): 写入单个字符;void write(char[] cbuf):写入字符数组;abstract void write(char[] cbuf, int off, int len):写入字符数组的某一部分,off数组的开始索引,len写的字符个数;void write(String str):写入字符串;void write(String str, int off, int len):写入字符串的某一部分,off字符串的开始索引,len写的字符个数;void flush():刷新该流的缓冲;void close():关闭此流,但要先刷新它。
子类实例演示(FileWriter)
package com.wyp.mall_study;
import java.io.*;
public class Test {
public static void main(String[] args) throws Exception{
// 创建流对象
Writer writer = new FileWriter("test.txt");
writer.write(97);
writer.write('b');
writer.write("fsdfs");
//关闭资源时,与FileOutputStream不同。 如果不关闭,数据只是保存到缓冲区,并未保存到文件。
writer.flush();
writer.close();
}
}
【注意】 关闭资源时,与FileOutputStream不同。 如果不关闭,数据只是保存到缓冲区,并未保存到文件。
关闭close和刷新flush
因为内置缓冲区的原因,如果不关闭输出流,无法写出字符到文件中。但是关闭的流对象,是无法继续写出数据的。如果我们既想写出数据,又想继续使用流,就需要flush
方法了。flush:刷新缓冲区,流对象可以继续使用。close:先刷新缓冲区,然后通知系统释放资源;流对象不可以再被使用了。
字符输入流(Reader)
java.io.Reader抽象类是字符输入流的所有类的超类(父类),可以读取字符信息到内存中。它定义了字符输入流的基本共性功能方法。
基本方法
public void close():关闭此流并释放与此流相关联的任何系统资源;public int read(): 从输入流读取一个字符;public int read(char[] cbuf): 从输入流中读取一些字符,并将它们存储到字符数组 cbuf中。
缓冲流
缓冲流,也叫高效流。能够高效读写缓冲流,能够转换编码的转换流,能够持久化存储对象的序列化对象等等。它是四个基本File流的增强,所以也是4个流,按照数据类型分类。
● 字节缓冲流:BufferedInputStream,BufferedOutputStream
● 字符缓冲流:BufferedReader,BufferedWriter
缓冲流的基本原理,是在创建流对象时,会创建一个内置的默认大小的缓冲区数组,通过缓冲区读写,减少系统IO读取次数,从而提高读写的效率。
构造方法
● 字节缓冲流
// 创建一个新的字节缓冲输入流
BufferedInputStream(InputStream in)
BufferedInputStream(InputStream in, int size)
// 将数据写入指定的底层输出流
BufferedOutputStream(OutputStream out)
// 将具有指定缓冲区大小的数据写入指定的底层输出流
BufferedOutputStream(OutputStream out, int size)
● 字符缓冲流
// 创建一个新的缓冲字符输入流
BufferedReader(Reader in)
BufferedReader(Reader in, int sz)
// 创建一个新的缓冲字符输出流
BufferedWriter(Writer out)
BufferedWriter(Writer out, int sz)
序列化流
构造方法
// 序列化流
public ObjectOutputStream(OutputStream out)
// 反序列化流
public ObjectInputStream(InputStream in)
序列化与反序列化
简介
- 序列化:把对象转化为可传输的字节序列过程称为序列化;
- 反序列化:把字节序列还原为对象的过程称为反序列化;
序列化的作用
- 对象随着程序的运行而被创建,然后在不可达时被回收,生命周期是短暂的。但是如果我们想长久地把对象的内容保存起来怎么办呢?把它转化为字节序列保存在存储介质上即可。那就需要序列化。
- 所有可在网络上传输的对象都必须是可序列化的,比如RMI(remote method invoke,即远程方法调用),传入的参数或返回的对象都是可序列化的,否则会出错;所有需要保存到磁盘的java对象都必须是可序列化的。通常建议:程序创建的每个JavaBean类都实现Serializeable接口
- 进程间传递对象,Android是基于Linux系统,不同进程之间的java对象是无法传输,所以我们此处要对对象进行序列化,从而实现对象在 应用程序进程 和 ActivityManagerService进程 之间传输。
序列化版本号serialVersionUID
所有实现序列化的对象都必须要有个版本号,这个版本号可以由我们自己定义,当我们没定义的时候JDK工具会按照我们对象的属性生成一个对应的版本号。其实这个版本号就和我们平常软件的版本号一样,你的软件版本号和官方的服务器版本不一致的话就告诉你有新的功能更新了,主要用于提示用户进行更新。序列化也一样,我们的对象通常需要根据业务的需求变化要新增、修改或者删除一些属性,在我们做了一些修改后,就通过修改版本号告诉 反序列化的那一方对象有了修改你需要同步修改。
实例
● 对象类
public class Employee implements Serializable {
int id;
String name;
public Employee(int id, String name) {
this.id = id;
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
● 序列化
public class Demo {
public static void main(String[] args) throws IOException, ClassNotFoundException {
Employee e = new Employee(1,"wyp");
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("test.txt"));
out.writeObject(e);
out.close();
ObjectInputStream in = new ObjectInputStream(new FileInputStream("test.txt"));
Employee e1 = (Employee) in.readObject();
in.close();
System.out.println(e1.getId()+":"+e1.getName());
}
}
/**
* 输出
* 1:wyp
*/
如果对象未实现Serializable接口的话,会报如下错误: