r中merge合并数据
R有许多快速,优雅的方法通过公共列联接数据帧。 我想给你看三个:
- 基本R的
merge()函数, - dplyr的加入功能家族,以及
- data.table的括号语法。
获取并导入数据
在此示例中,我将使用我最喜欢的演示数据集之一-美国运输统计局的航班延误时间。 如果您想继续,请前往http://bit.ly/USFlightDelays并下载您选择的时间范围的数据,其中包含Flight Date , Reporting_Airline , Origin , Destination和DepartureDelayMinutes列 。 还要获取Reporting_Airline的查找表。
或者,在这里下载这两个数据集-加上我的R代码在一个文件中,以及解释不同类型数据合并的PowerPoint-在这里:
要读入以R为底的文件,我首先解压缩航班延误文件,然后使用read.csv()导入航班延误数据和代码查找文件。 如果您正在运行代码,则下载的延迟文件的名称可能与以下代码中的名称不同。 另外,请注意查找文件的异常.csv_扩展名。
unzip("673598238_T_ONTIME_REPORTING.zip")
mydf <- read.csv("673598238_T_ONTIME_REPORTING.csv",
sep = ",", quote="\"")
mylookup <- read.csv("L_UNIQUE_CARRIERS.csv_",
quote="\"", sep = "," )接下来,我将使用head()窥视这两个文件:
head(mydf)
FL_DATE OP_UNIQUE_CARRIER ORIGIN DEST DEP_DELAY_NEW X
1 2019-08-01 DL ATL DFW 31 NA
2 2019-08-01 DL DFW ATL 0 NA
3 2019-08-01 DL IAH ATL 40 NA
4 2019-08-01 DL PDX SLC 0 NA
5 2019-08-01 DL SLC PDX 0 NA
6 2019-08-01 DL DTW ATL 10 NA
head(mylookup)
Code Description
1 02Q Titan Airways
2 04Q Tradewind Aviation
3 05Q Comlux Aviation, AG
4 06Q Master Top Linhas Aereas Ltd.
5 07Q Flair Airlines Ltd.
6 09Q Swift Air, LLC d/b/a Eastern Air Lines d/b/a Eastern与基数R合并
mydf延迟数据帧仅通过代码包含航空公司信息。 我想在mylookup添加一列航空公司名称。 实现此目的的一种基本R方法是使用merge()函数,使用基本语法merge(df1, df2) 。 数据帧1和数据帧2的顺序无关紧要,但是第一个被认为是x,第二个是y。
如果要by.x列名称不同,则需要告诉merge要by.x列: by.x表示x数据框的列名称, by.y表示y的名称,例如作为merge(df1, df2, by.x = "df1ColName", by.y = "df2ColName") 。
您还可以使用参数all.x和all.y告诉merge是否需要所有行,包括不匹配的行,或仅匹配的行。 在这种情况下,我想要延迟数据中的所有行; 如果查询表中没有航空公司代码,我仍然需要该信息。 但是我不需要查找表中不在延迟数据中的行(有一些旧航空公司的代码不再在那里飞行了)。 因此, all.x等于TRUE但是all.y等于FALSE 。 完整代码:
joined_df <- merge(mydf, mylookup, by.x = "OP_UNIQUE_CARRIER",
by.y = "Code", all.x = TRUE, all.y = FALSE)新加入的数据框包括一个名为Description的列,该列基于航空公司的航空公司名称。
head(joined_df)
OP_UNIQUE_CARRIER FL_DATE ORIGIN DEST DEP_DELAY_NEW X Description
1 9E 2019-08-12 JFK SYR 0 NA Endeavor Air Inc.
2 9E 2019-08-12 TYS DTW 0 NA Endeavor Air Inc.
3 9E 2019-08-12 ORF LGA 0 NA Endeavor Air Inc.
4 9E 2019-08-13 IAH MSP 6 NA Endeavor Air Inc.
5 9E 2019-08-12 DTW JFK 58 NA Endeavor Air Inc.
6 9E 2019-08-12 SYR JFK 0 NA Endeavor Air Inc.与dplyr一起加入
dplyr将SQL数据库语法用于其连接功能。 左联接的意思是:包括左侧的所有内容( merge()的x数据框)以及与右侧(y)数据框匹配的所有行。 如果连接列具有相同的名称, left_join(x, y)需要left_join(x, y) 。 如果它们的名称不同,则需要一个by参数,例如left_join(x, y, by = c("df1ColName" = "df2ColName")) 。
请注意by的语法:这是一个命名向量,左右两列名称都用引号引起来。
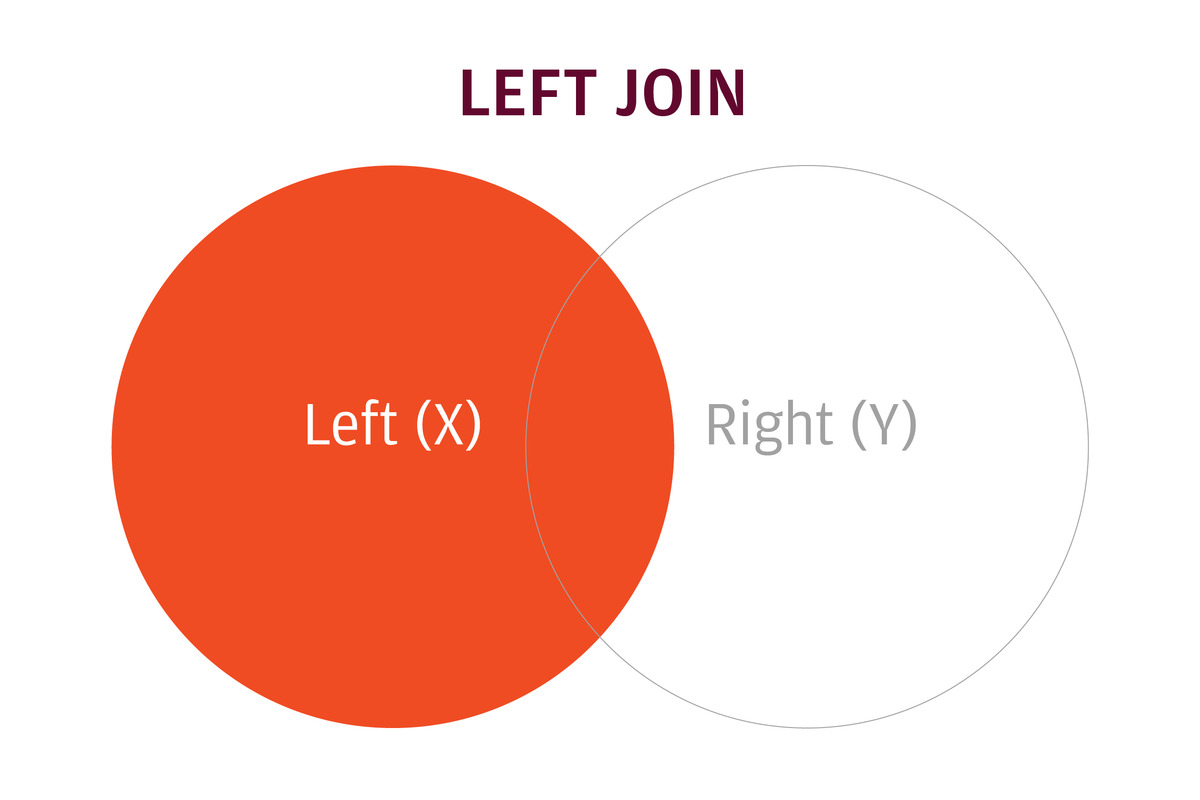 IDG
IDG左联接将所有行保留在左数据框中,而仅将匹配的行保留在右数据框中。
下面是使用left_join()导入和合并两个数据集的代码。 首先加载dplyr和readr程序包,然后使用read_csv()读取两个文件。 使用read_csv() ,我不需要首先解压缩文件。
library(dplyr)
library(readr)mytibble <- read_csv("673598238_T_ONTIME_REPORTING.zip")
mylookup_tibble <- read_csv("L_UNIQUE_CARRIERS.csv_")joined_tibble <- left_join(mytibble, mylookup_tibble,
by = c("OP_UNIQUE_CARRIER" = "Code"))read_csv()创建tibble ,这是一种具有某些额外功能的数据框。 left_join()将两者合并。 看一下语法:在这种情况下,顺序很重要。 left_join()表示包括左侧或第一个数据集的所有行,但仅包括与第二个匹配的行 。 而且,因为我需要通过两个不同名称的列进行连接,所以我加入了一个by参数。
我们可以使用dplyr的glimpse()函数查看结果的结构,这是查看数据帧前几项的另一种方法。
glimpse(joined_tibble)
Observations: 658,461
Variables: 7
$ FL_DATE <date> 2019-08-01, 2019-08-01, 2019-08-01, 2019-08-01, 2019-08-01…
$ OP_UNIQUE_CARRIER <chr> "DL", "DL", "DL", "DL", "DL", "DL", "DL", "DL", "DL", "DL",…
$ ORIGIN <chr> "ATL", "DFW", "IAH", "PDX", "SLC", "DTW", "ATL", "MSP", "JF…
$ DEST <chr> "DFW", "ATL", "ATL", "SLC", "PDX", "ATL", "DTW", "JFK", "MS…
$ DEP_DELAY_NEW <dbl> 31, 0, 40, 0, 0, 10, 0, 22, 0, 0, 0, 17, 5, 2, 0, 0, 8, 0, …
$ X6 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ Description <chr> "Delta Air Lines Inc.", "Delta Air Lines Inc.", "Delta Air …现在,此联接的数据集具有一个新列,其中包含航空公司的名称。 如果您自己运行此代码的版本,则可能会注意到dplyr比base R快得多。
接下来,让我们来看一个超快速的联接方法。
r中merge合并数据