本文是对最近上课的实践做了个总结。
值得一提的是,PSM、DID是一种计量分析工具,在实证研究中,比工具更重要的可能是如何构建因果分析框架。
PSM-DID的主要步骤如下:
- PSM
- 计算倾向得分
- 以合适的匹配方法选择控制组(0)和处理组(1)
- 平衡性检验、检验匹配前后的偏差
- 如果是多个年份的面板数据,可每年都匹配一个控制组,重复1-3步后合并数据即可
- 在PSM的基础上增加年份虚拟变量,生成年份虚拟变量和处理控制虚拟变量的交互项
- 跑回归
- 平行趋势图检验,安慰剂检验等稳健性检验
下面介绍在STATA的操作
参考文献
石大千, 丁海, 卫平, et al. 智慧城市建设能否降低环境污染[J]. 中国工业经济, 2018, No.363(06):119-137.
可以在工业经济网站下载该论文的数据附件
http://www.ciejournal.org/Magazine/show/?id=54281
网址无法直接在微信内打开,请复制后在浏览器打开或点击页尾的阅读原文
需要留意的是,由于附件中没有给出智慧城市的名单,我在网上找了一份,在处理数据过程中会多出合并数据merge这一步骤
下文回归方程的是ln_so,一氧化硫排放量的对数值
PSM
本文的数据是2005-2015年的面板数据,需要重复PSM的1-3步完成匹配,具体方法为:
- 数据预处理
merge命令合并数据merge m:1 city using 2012智慧城市名单 ,nogen
drop if pop == .
replace T = 0 if T == .选择合适的控制变量,并取对数
global xlist "pop zl gdp rgdp ex sgdp sl l so"
foreach x in $xlist{
gen ln_`x' = ln(1 + `x')
}
psmatch2命令匹配
计算倾向得分
set seed 1000
gen tmp = runiform()
sort tmp
global xlist "ln_pop ln_zl ln_gdp ln_rgdp ln_ex ln_sgdp ln_sl ln_l"
psmatch2 T $xlist , n(3) out(ln_so) logit ate前三行的目的是根据
psmatch2的help文件提示,为了保证结果可复现,需要设置种子并对数据排序。这里使用了1:3近邻匹配。关于psmatch2的其他匹配方法可以使用help psmatch2命令参考,或者参看本公众号另一篇文章——《PSM在STATA中怎么操作》平衡性检验
pstest $xlist ,both graph下图是2010年匹配后的结果,匹配前后控制组和处理组的偏差显著降低。匹配质量较好的情况下,偏差应降低到10%以内(即
*号在横轴的10以内)。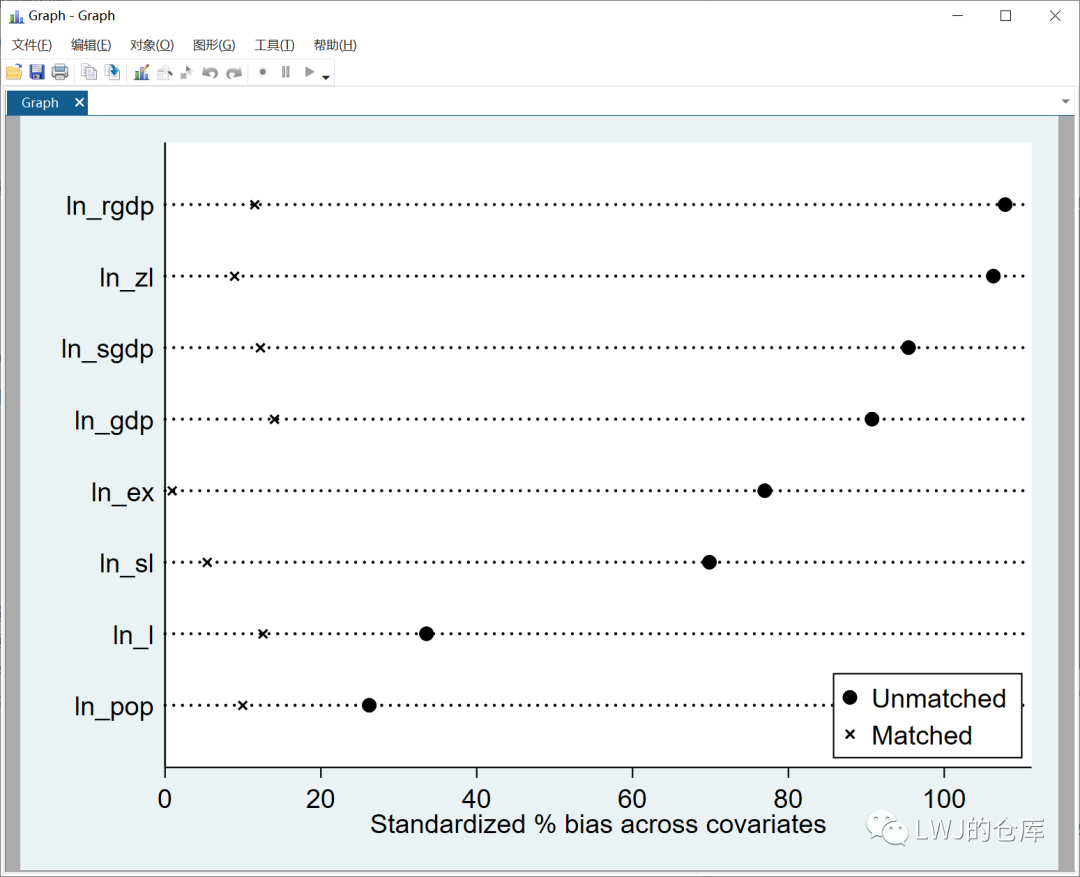
匹配质量
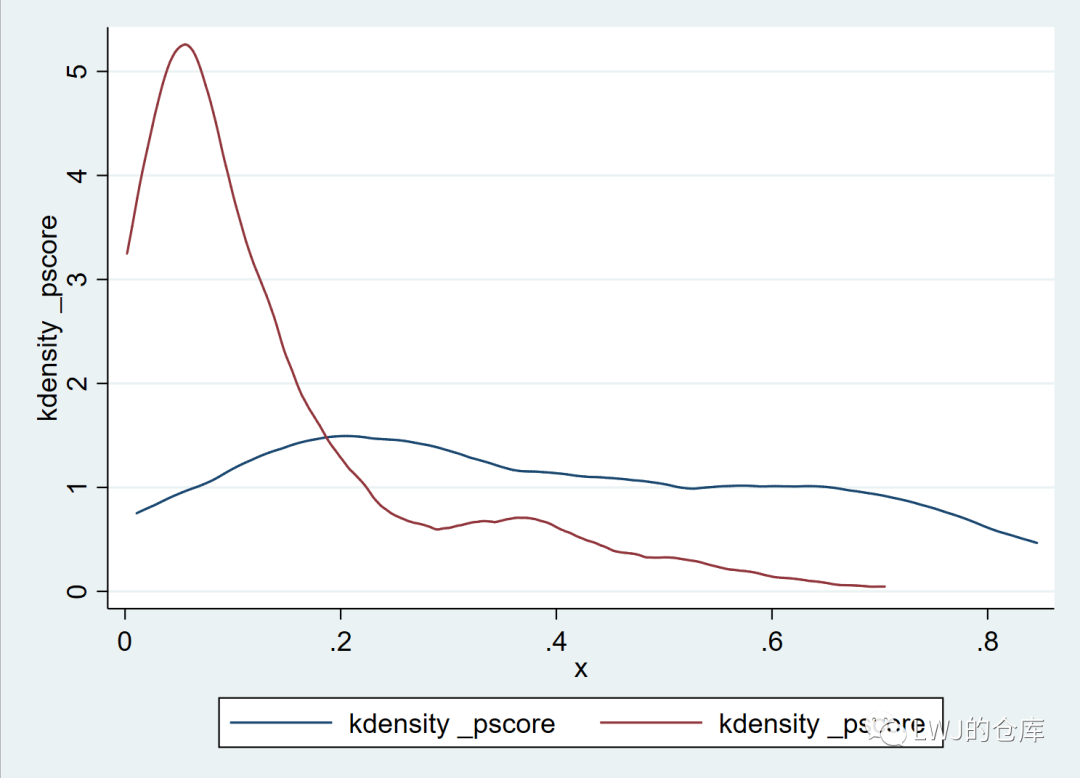
***匹配前
tw (kdensity _pscore if T == 1) ///
(kdensity _pscore if T == 0)
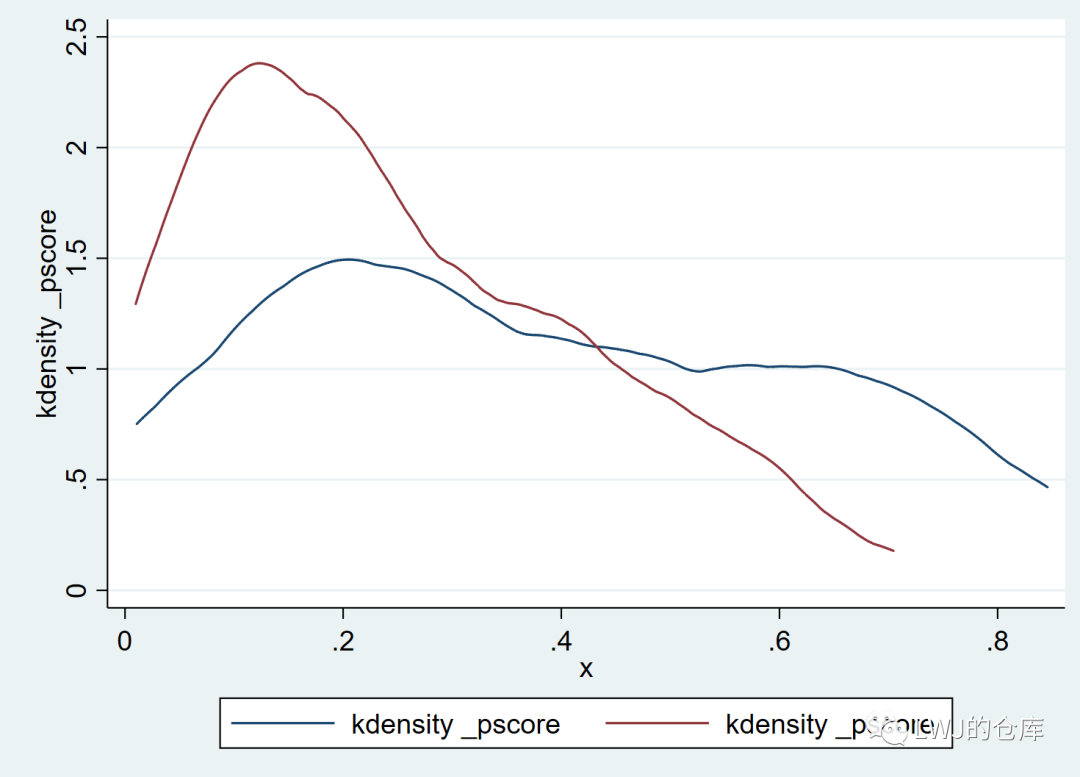
**匹配后
tw (kdensity _pscore if T == 1) ///
(kdensity _pscore if (T == 0& _weight != .))psmatch2命令运行后会生成_weight变量,当_weight变量不为空时,表示匹配成功。匹配前倾向得分的密度曲线重合度低,匹配后倾向得分的密度曲线重合度较高,密度较集中。
在理想情况下,匹配后倾向得分的密度曲线应高度重合。
在实际操作中,建议使用
graph export命令保存图片,否则运行中绘出来的图将一闪而过。
匹配前
匹配后
PSM的操作到此结束。在开始DID分析前,我们要去掉匹配不成功的城市(即_weight为空值的城市),并保存这一年的匹配结果,最后合并10年的数据。使用forvalues循环可以轻松解决10年的匹配、合并问题。
forvalues i = 2005/2015{
preserve
keep if year == `i'
/*这里填写上面的PSM匹配代码*/
drop if _weight == .
save psm_`i',replace
restore
}
use psm_2005,clear
forvalues i = 2006/2015{
append using psm_`i'
}
DID
DID的步骤比PSM稍简单,但事实上面板数据的分析涉及很多技术性计量问题,这不在本文的讨论范围内。
DID的计量方程为
上述方程省略了各类固定效应。其中:
是年份处理变量,政策实施前为0,政策实施后为1。
是控制组(0)、处理组(1)虚拟变量。
交互项的系数是我们关注的回归系数。
具体步骤如下:
生成不同城市对应的编号,并设置面板
encode city , gen(city_)
xtset year city_生成上述三个回归系数
gen time = (year>=2012)
gen treat = T
gen did = time * treat跑回归
global xlist "ln_pop ln_zl ln_gdp ln_rgdp ln_ex ln_sgdp ln_sl ln_l"
xtreg ln_so time treat did
xtreg ln_so time treat did $xlist这一步关注的时变量
did的系数。根据不同的论文不同的选材,可以选取不同的控制变量,并逐步添加固定效应。需要注意的是,若使用固定效应,
time和treat项有时可以省略。平行趋势检验
这是DID的关键假设,实际论文写作时完全可以放在回归前检验。
为了图形好看,我们使用各年中位数而不是各年均值来绘图。
DID的平行趋势绘图可参考本公众号的另一篇DID文章——DID平行趋势怎么绘图?。
bysort year T : egen median_so = median(so)
twoway (connected median_so year if T == 1, msize(large) msymbol(square) lwidth(thick) lpattern(solid)) ///
(connected median_so year if T == 0, msize(large) msymbol(diamond) lwidth(thick) lpattern(dash)) ///
, graphregion(color(white)) xline(2012,lc(black) lp(dot)) ytitle(SO emission during 2005-2015 , size(small)) xlabel(2005(1)2015) legend(size(small))绘制的图形如下,上方的为处理组,下方的为控制组,在政策实施前,其一氧化硫排放量中位数趋势基本平行,政策实施后处理组的排放量明显下降。两曲线的差距在缩小(不平行)。
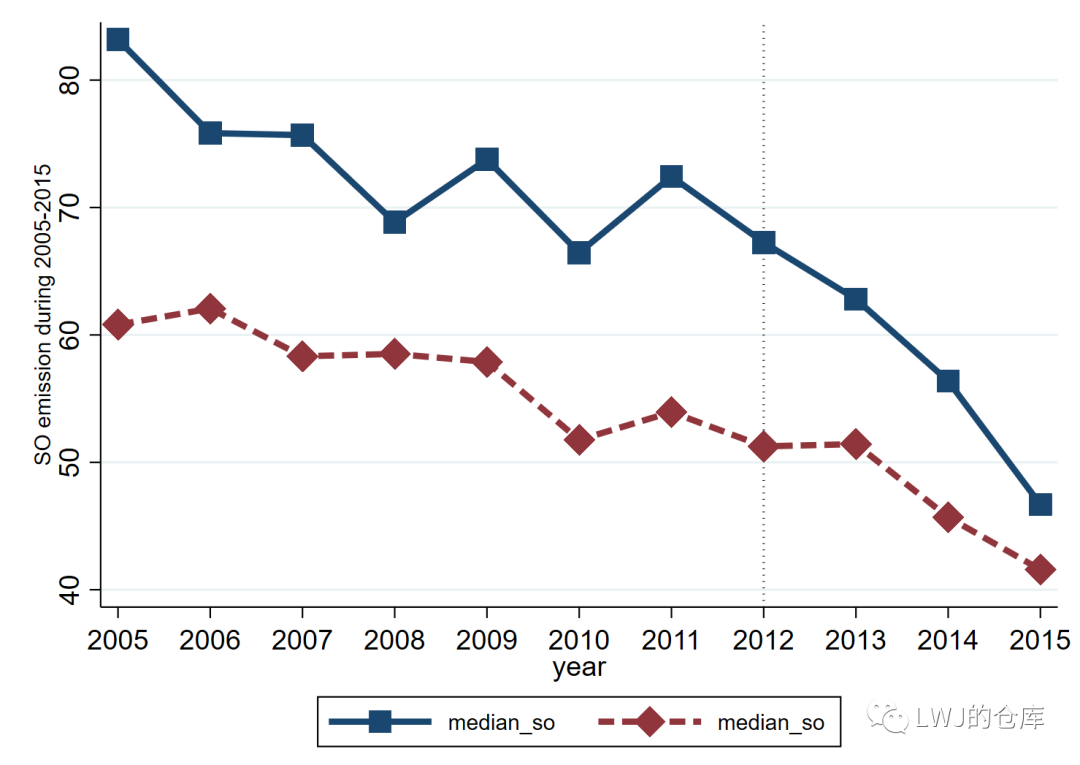
安慰剂检验
一个方法是更改第2步中的
time变量,即人为更改政策的实施时间,检验是否确实是政策发挥了作用。
写在后面:实际的实证研究中,数据的获取、预处理是很繁琐的,很多情况下比跑回归更困难更耗时的。
本推文的作者感谢石大千, 丁海, 卫平三位老师的论文和数据,可点击“阅读原文”直达《中国工业企业》网站。本文上述提及的数据和do文件可以通过下方连接获取。
链接:https://pan.baidu.com/s/1IVLjZYoPQAKW_LQouGx0XA 提取码:xeyh