目录
作者:bandaoyu 链接:https://blog.csdn.net/bandaoyu/article/details/95407670
一、Top
1 Top返回结果说明
统计信息区说明
top - 01:06:48 up 1:22, 1 user, load average: 0.06, 0.60, 0.48
Tasks: 29 total, 1 running, 28 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.3% us, 1.0% sy, 0.0% ni, 98.7% id, 0.0% wa, 0.0% hi, 0.0% si
Mem: 191272k total, 173656k used, 17616k free, 22052k buffers
Swap: 192772k total, 0k used, 192772k free, 123988k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1379 root 16 0 7976 2456 1980 S 0.7 1.3 0:11.03 sshd
14704 root 16 0 2128 980 796 R 0.7 0.5 0:02.72 top
1 root 16 0 1992 632 544 S 0.0 0.3 0:00.90 init
2 root 34 19 0 0 0 S 0.0 0.0 0:00.00 ksoftirqd/0
3 root RT 0 0 0 0 S 0.0 0.0 0:00.00 watchdog/0统计信息区其内容如下:
#前五行是系统整体的统计信息。第一行是任务队列信息,同 uptime 命令的执行结果。
01:06:48 当前时间
up 1:22 系统运行时间,格式为时:分
1 user 当前登录用户数
load average: 0.06, 0.60, 0.48 系统负载,即任务队列的平均长度。三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。
#第二、三行为进程和CPU的信息。当有多个CPU时,这些内容可能会超过两行。内容如下:
total 进程总数
running 正在运行的进程数
sleeping 睡眠的进程数
stopped 停止的进程数
zombie 僵尸进程数
Cpu(s):
0.3% us 用户空间占用CPU百分比
1.0% sy 内核空间占用CPU百分比
0.0% ni 用户进程空间内改变过优先级的进程占用CPU百分比
98.7% id 空闲CPU百分比
0.0% wa 等待输入输出的CPU时间百分比
0.0%hi:硬件CPU中断占用百分比
0.0%si:软中断占用百分比
0.0%st:虚拟机占用百分比
#最后两行为内存信息。内容如下:
Mem:
191272k total 物理内存总量
173656k used 使用的物理内存总量
17616k free 空闲内存总量
22052k buffers 用作内核缓存的内存量
Swap:
192772k total 交换区总量
0k used 使用的交换区总量
192772k free 空闲交换区总量
123988k cached 缓冲的交换区总量,内存中的内容被换出到交换区,而后又被换入到内存,但使用过的交换区尚未被覆盖,该数值即为这些内容已存在于内存中的交换区的大小,相应的内存再次被换出时可不必再对交换区写入。进程信息区说明
进程信息区统计信息区域的下方显示了各个进程的详细信息。首先来认识一下各列的含义。
序号 列名 含义
a PID 进程id
b PPID 父进程id
c RUSER Real user name
d UID 进程所有者的用户id
e USER 进程所有者的用户名
f GROUP 进程所有者的组名
g TTY 启动进程的终端名。不是从终端启动的进程则显示为 ?
h PR 优先级
i NI nice值。负值表示高优先级,正值表示低优先级
j P 最后使用的CPU,仅在多CPU环境下有意义
k %CPU 上次更新到现在的CPU时间占用百分比
l TIME 进程使用的CPU时间总计,单位秒
m TIME+ 进程使用的CPU时间总计,单位1/100秒
n %MEM 进程使用的物理内存百分比
o VIRT 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
p SWAP 进程使用的虚拟内存中,被换出的大小,单位kb。
q RES 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
r CODE 可执行代码占用的物理内存大小,单位kb
s DATA 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb
t SHR 共享内存大小,单位kb
u nFLT 页面错误次数
v nDRT 最后一次写入到现在,被修改过的页面数。
w S 进程状态(D=不可中断的睡眠状态,R=运行,S=睡眠,T=跟踪/停止,Z=僵尸进程)
x COMMAND 命令名/命令行
y WCHAN 若该进程在睡眠,则显示睡眠中的系统函数名
z Flags 任务标志,参考 sched.h2 Top交互操作
常用交互操作
切换内存信息:m
切换名字和路径:c
切换显示进程和CPU状态信息:t
翻页:Shift+< 上翻 , Shift+> 下翻
其他实用交互操作
下面介绍在top命令执行过程中可以使用的一些交互命令。从使用角度来看,熟练的掌握这些命令比掌握选项还重要一些。这些命令都是单字母的,如果在命令行选项中使用了s选项,则可能其中一些命令会被屏蔽掉。
Ctrl+L 擦除并且重写屏幕。
h或者? 显示帮助画面,给出一些简短的命令总结说明。
k 终止一个进程。系统将提示用户输入需要终止的进程PID,以及需要发送给该进程什么样的信号。一般的终止进程可以使用15信号;如果不能正常结束那就使用信号9强制结束该进程。默认值是信号15。在安全模式中此命令被屏蔽。
i 忽略闲置和僵死进程。这是一个开关式命令。
q 退出程序。
r 重新安排一个进程的优先级别。系统提示用户输入需要改变的进程PID以及需要设置的进程优先级值。输入一个正值将使优先级降低,反之则可以使该进程拥有更高的优先权。默认值是10。
S 切换到累计模式。
s 改变两次刷新之间的延迟时间。系统将提示用户输入新的时间,单位为s。如果有小数,就换算成m s。输入0值则系统将不断刷新,默认值是5 s。需要注意的是如果设置太小的时间,很可能会引起不断刷新,从而根本来不及看清显示的情况,而且系统负载也会大大增加。
f或者F 从当前显示中添加或者删除项目。
o或者O 改变显示项目的顺序。
l 切换显示平均负载和启动时间信息。
m 切换显示内存信息。
t 切换显示进程和CPU状态信息。
c 切换显示命令名称和完整命令行。
M 根据驻留内存大小进行排序。
P 根据CPU使用百分比大小进行排序。
T 根据时间/累计时间进行排序。
W 将当前设置写入~/.toprc文件中。这是写top配置文件的推荐方法。更改显示项目
默认情况下仅显示比较重要的 PID、USER、PR、NI、VIRT、RES、SHR、S、%CPU、%MEM、TIME+、COMMAND 列。
可以通过下面的快捷键来更改显示内容。
更改显示内容:
1)通过 f 键可以选择显示的内容。按 f 键之后会显示列的列表,按 a-z 即可显示或隐藏对应的列,最后按回车键确定。 ,
2)(centOS)按方向键选择项目。
3)(centOS)按D 选择或取消显示项目(被做选择的会显示*号)
4)按ESC退出。
更改排序顺序
按指定字段排序:top -o 字段名字,如:
- 按照内存排序:top -o %MEM 或者执行完top后,输入大写M
- 按照内存排序:top -o %CPU 或者执行完top后,输入大写P
- 按照内存排序:执行完top后,输入大写T
默认从大到小,大写R更改为从小到大排序
2,使用<>:
shift+>:向右移动一列排序,比如现在是以CPU排序,那么输入>后就按照内存排序,输入R更改排序顺序,向右移动不了了,就表示以最右边的列排序。
shift+<:向左移动一列排序
过滤
过滤字符串
top -bc |grep name_of_process #过滤含字符串“name_of_process”的
过滤用户
执行top 指令,按下“u”,顶端出现:Which user (blank for all),输入要过滤的用户名即可
其他过滤 (表达式)
执行top 指令,按下“o”,顶端出现:add filter #1 (ignoring case) as: [!]FLD?VAL :
过滤用户则输入:USER=ceph
过滤command则输入:COMMAND=/opt/h3c/bin/python
过滤PID则输入:PID=3289848
3 top使用格式
top使用格式
top [-] [d] [p] [q] [c] [C] [S] [s] [n]
参数说明
d 指定每两次屏幕信息刷新之间的时间间隔。当然用户可以使用s交互命令来改变之。
p 通过指定监控进程ID来仅仅监控某个进程的状态。
q 该选项将使top没有任何延迟的进行刷新。如果调用程序有超级用户权限,那么top将以尽可能高的优先级运行。
S 指定累计模式
s 使top命令在安全模式中运行。这将去除交互命令所带来的潜在危险。
i 使top不显示任何闲置或者僵死进程。
c 显示整个命令行而不只是显示命令名4 附常用操作命令
top //每隔5秒显式所有进程的资源占用情况
top -d 2 //每隔2秒显式所有进程的资源占用情况
top -c //每隔5秒显式进程的资源占用情况,并显示进程的命令行参数(默认只有进程名)
top -p 12345 -p 6789//每隔5秒显示pid是12345和pid是6789的两个进程的资源占用情况
top -d 2 -c -p 123456 //每隔2秒显示pid是12345的进程的资源使用情况,并显式该进程启动的命令行参
数
top -p进程1的ID -p进程2的id -p进程3的id …… //查看某几个进程的状态转自:linux的top命令参数详解;https://www.cnblogs.com/LeoBoy/p/7976612.html
二、查看磁盘 IO 性能
1.1 top 命令
top 命令通过查看 CPU 的 wa% 值来判断当前磁盘 IO 性能,如果这个数值过大,很可能是磁盘 IO 太高了,当然也可能是其他原因,例如网络 IO 过高等。

top命令的其他参数代表的含义详见top命令详解
1.2 sar 命令
sar 命令是分析系统瓶颈的神器,可以用来查看 CPU 、内存、磁盘、网络等性能。
sar 命令查看当前磁盘性能的命令为:
[root@server-68.2.stage.polex.io var ]$ sar -d -p 1 2
Linux 3.10.0-693.5.2.el7.x86_64 (server-68) 03/11/2019 _x86_64_ (64 CPU)
02:28:54 PM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
02:28:55 PM sda 1.00 0.00 3.00 3.00 0.01 9.00 9.00 0.90
02:28:55 PM sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
02:28:55 PM polex_pv-rootvol 1.00 0.00 3.00 3.00 0.01 9.00 9.00 0.90
02:28:55 PM polex_pv-varvol 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
02:28:55 PM polex_pv-homevol 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
02:28:55 PM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
02:28:56 PM sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
02:28:56 PM sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
02:28:56 PM polex_pv-rootvol 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
02:28:56 PM polex_pv-varvol 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
02:28:56 PM polex_pv-homevol 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
Average: sda 0.50 0.00 1.50 3.00 0.00 9.00 9.00 0.45
Average: sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: polex_pv-rootvol 0.50 0.00 1.50 3.00 0.00 9.00 9.00 0.45
Average: polex_pv-varvol 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: polex_pv-homevol 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00其中, “-d”参数代表查看磁盘性能,“-p”参数代表将 dev 设备按照 sda,sdb……名称显示,“1”代表每隔1s采取一次数值,“2”代表总共采取2次数值。
await:平均每次设备 I/O 操作的等待时间(以毫秒为单位)。
svctm:平均每次设备 I/O 操作的服务时间(以毫秒为单位)。
%util:一秒中有百分之几的时间用于 I/O 操作。
对于磁盘 IO 性能,一般有如下评判标准:
正常情况下 svctm 应该是小于 await 值的,而 svctm 的大小和磁盘性能有关,CPU 、内存的负荷也会对 svctm 值造成影响,过多的请求也会间接的导致 svctm 值的增加。
await 值的大小一般取决与 svctm 的值和 I/O 队列长度以 及I/O 请求模式,如果 svctm 的值与 await 很接近,表示几乎没有 I/O 等待,磁盘性能很好,如果 await 的值远高于 svctm 的值,则表示 I/O 队列等待太长,系统上运行的应用程序将变慢,此时可以通过更换更快的硬盘来解决问题。
%util 项的值也是衡量磁盘 I/O 的一个重要指标,如果 %util 接近 100% ,表示磁盘产生的 I/O 请求太多,I/O 系统已经满负荷的在工作,该磁盘可能存在瓶颈。长期下去,势必影响系统的性能,可以通过优化程序或者通过更换更高、更快的磁盘来解决此问题。
默认情况下,sar从最近的0点0分开始显示数据;如果想继续查看一天前的报告;可以查看保存在/var/log/sa/下的sar日志:
[root@server-68.2.stage.polex.io var ]$ sar -d -p -f /var/log/sa/sa11 | more
Linux 3.10.0-693.5.2.el7.x86_64 (server-68) 03/11/2019 _x86_64_ (64 CPU)
09:50:01 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
10:00:01 AM sda 0.51 0.00 9.06 17.82 0.02 37.65 14.65 0.74
10:00:01 AM sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:00:01 AM polex_pv-rootvol 0.22 0.00 2.50 11.56 0.01 37.44 14.10 0.31
10:00:01 AM polex_pv-varvol 0.30 0.00 6.55 21.97 0.01 38.55 14.73 0.44
10:00:01 AM polex_pv-homevol 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:10:01 AM sda 0.79 3.45 13.18 21.06 0.04 51.81 11.03 0.87
10:10:01 AM sdb 0.04 3.45 0.00 86.33 0.00 0.25 0.25 0.00
10:10:01 AM polex_pv-rootvol 0.26 0.00 3.08 11.85 0.01 50.21 17.88 0.46
10:10:01 AM polex_pv-varvol 0.54 3.45 10.10 24.95 0.03 52.58 7.49 0.41
10:10:01 AM polex_pv-homevol 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10:20:01 AM sda 0.65 0.00 10.43 16.11 0.03 38.67 10.99 0.71
10:20:01 AM sdb 0.04 3.46 0.00 86.33 0.00 0.08 0.08 0.001.3 iostat 命令
iostat主要用于监控系统设备的 IO 负载情况,iostat 首次运行时显示自系统启动开始的各项统计信息,之后运行 iostat 将显示自上次运行该命令以后的统计信息。用户可以通过指定统计的次数和时间来获得所需的统计信息。
[root@server-68.2.stage.polex.io var ]$ iostat -dxk 1 2
Linux 3.10.0-693.5.2.el7.x86_64 (server-68) 03/11/2019 _x86_64_ (64 CPU)
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.06 0.32 2.08 1.44 72.78 61.81 0.14 59.32 0.51 68.37 5.68 1.36
sdb 0.00 0.00 0.03 0.00 1.15 0.00 86.32 0.00 0.17 0.17 0.00 0.16 0.00
dm-0 0.00 0.00 0.00 0.24 0.02 1.56 13.22 0.01 44.55 6.36 44.71 13.25 0.32
dm-1 0.00 0.00 0.32 1.90 1.32 71.22 65.30 0.14 62.43 0.49 72.79 4.75 1.06
dm-2 0.00 0.00 0.00 0.00 0.00 0.00 26.79 0.00 28.06 4.68 38.98 5.18 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.00 0.00 3.00 0.00 16.00 10.67 0.26 86.33 0.00 86.33 42.33 12.70
sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
dm-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
dm-1 0.00 0.00 0.00 3.00 0.00 16.00 10.67 0.26 86.33 0.00 86.33 42.33 12.70
dm-2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00该命令的结果与上面 sar -d -p 1 2 命令类似,实际使用中主要还是看 await svctm %util 参数。
详情见:https://blog.csdn.net/bandaoyu/article/details/103195128
1.4 vmstat 命令
vmstat 命令使用方法很简单:
[root@server-68.2.stage.polex.io var ]$ vmstat 2
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
3 0 0 93221488 4176 69117136 0 0 0 1 0 0 4 1 94 0 0
2 0 0 93226048 4176 69117128 0 0 0 0 33326 36671 18 2 80 0 0
1 0 0 93218776 4176 69117104 0 0 0 9 26225 21588 18 2 80 0 0
1 0 0 93226072 4176 69117072 0 0 0 0 13271 25857 5 0 94 0 0
0 0 0 93223984 4176 69117040 0 0 0 5 34637 24444 20 2 78 0 0
11 0 0 93219248 4176 69117184 0 0 0 0 30736 20671 8 2 90 0 0输出结果中,bi bo 可以表示磁盘当前性能:
bi 块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是 1024 byte 。
bo 块设备每秒发送的块数量,例如我们读取文件,bo 就要大于0。bi 和 bo 一般都要接近 0,不然就是 IO 过于频繁,需要调整。
2. 测试磁盘 IO 性能
2.1 hdparm 命令
hdparm 命令提供了一个命令行的接口用于读取和设置IDE或SCSI硬盘参数,注意该命令只能测试磁盘的读取速率。
例如,测试 sda 磁盘的读取速率:
[root@server-68.2.stage.polex.io var ]$ hdparm -Tt /dev/polex_pv/varvol
/dev/polex_pv/varvol:
Timing cached reads: 15588 MB in 2.00 seconds = 7803.05 MB/sec
Timing buffered disk reads: 1128 MB in 3.01 seconds = 374.90 MB/sec从测试结果看出,带有缓存的读取速率为:7803.05MB/s ,磁盘的实际读取速率为:374.90 MB/s 。
2.2 dd 命令
Linux dd 命令用于读取、转换并输出数据。dd 可从标准输入或文件中读取数据,根据指定的格式来转换数据,再输出到文件、设备或标准输出。
我们可以利用 dd 命令的复制功能,测试某个磁盘的 IO 性能,须要注意的是 dd 命令只能大致测出磁盘的 IO 性能,不是非常准确。
测试写性能命令:
[root@server-68.2.stage.polex.io var ]$ time dd if=/dev/zero of=test.file bs=1G count=2 oflag=direct
2+0 records in
2+0 records out
2147483648 bytes (2.1 GB) copied, 13.5487 s, 159 MB/s
real 0m13.556s
user 0m0.000s
sys 0m0.888s可以看到,该分区磁盘写入速率为 159M/s,其中:
- /dev/zero 伪设备,会产生空字符流,对它不会产生 IO 。
- if 参数用来指定 dd 命令读取的文件。
- of 参数用来指定 dd 命令写入的文件。
- bs 参数代表每次写入的块的大小。
- count 参数用来指定写入的块的个数。
- offlag=direc 参数测试 IO 时必须指定,代表直接写如磁盘,不使用 cache 。
测试读性能命令:
[root@server-68.2.stage.polex.io var ]$ dd if=test.file of=/dev/null iflag=direct
4194304+0 records in
4194304+0 records out
2147483648 bytes (2.1 GB) copied, 4.87976 s, 440 MB/s可以看到,该分区的读取速率为 440MB/s
2.3 fio 命令
fio 命令是专门测试 iops 的命令,比 dd 命令准确,fio 命令的参数很多,这里举几个例子供大家参考:
顺序读:
fio -filename=/var/test.file -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=test_r
随机写:
fio -filename=/var/test.file -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=test_randw
顺序写:
fio -filename=/var/test.file -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=test_w
混合随机读写:
fio -filename=/var/test.file -direct=1 -iodepth 1 -thread -rw=randrw -rwmixread=70 -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=test_r_w -ioscheduler=noop更多:FIO命令详解(一):https://blog.csdn.net/bandaoyu/article/details/113190057
定时执行命令
watch 命令,定时执行linux命令。
watch -n 2 'ps -aux|grep osd'
命令参数:
-n 指定间隔的时间,缺省每2秒运行
-d 高亮显示变化的区域。 而-d=cumulative选项会把变动过的地方(不管最近的那次有没有变动)都高亮显示出来。
-t 关闭watch命令在顶部的时间间隔,命令,当前时间的输出。
-h, --help 查看帮助文档
每天一个linux命令(48):watch命令:https://www.cnblogs.com/peida/archive/2012/12/31/2840241.html
查看线程
你可以用 ps -eLf |grep XXX 来查看程序运行所产生的线程情况; 也可以用 ps axms | grep XXX;
ALL CPU平均值
语法:mpstat [-P {|ALL}] [internal [count]]
mpstat;默认输出所有CPU使用情况的平均值,
mpstat -P 1 查看当前编号1的CPU使用情况(cpu编号0开始)
mpstat -P ALL 查看当前所有的CPU使用情况
mpstat -P ALL 2 30 查看所有的CPU使用情况,2秒采集一次,采集30次
mpstat(MultiProcessor Statistics)实时系统监控CPU统计信息,存放在/proc/stat文件中。能查看所有CPU的平均状况信息,也能查看特定CPU的信息。
下面只介绍mpstat与CPU相关的参数,mpstat的语法如下:
mpstat [-P {|ALL}] [internal [count]]
-P {|ALL} 表示监控哪个CPU, cpu在[0,cpu个数-1]中取值
internal 相邻的两次采样的间隔时间
count 采样的次数,count只能和delay一起使用
当没有参数时,mpstat则显示系统启动以后所有信息的平均值。有interval时,第一行的信息自系统启动以来的平均信息。
显示占用CPU最多的20个进程
ps -eo pcpu,pid,user,args | sort -k 1 -r | head -20
atop监控工具
(转自:http://www.361way.com/atop/5162.html)
零、即看即用
实时查看:atop
保存日志 atop -w log.txt
3.查看输出日志 atop -r log.txt , 按 t 查看 下一个样本的性能数据 ,按T查看 上一个样本的性能数据。
4. -P 可以 将 日志 输出成可解析的格式,默认是 压缩的格式,都是乱码。
atop 默认日志保存地址:/var/log/atop
atop 默认采集频率:每10分钟采集一次数据。 配置位置:/etc/atop/atop.daily
一、atop简介
atop监控Linux系统资源与进程,以一定的频率记录(CPU、内存、磁盘和网络)使用情况和进程运行情况,并能以日志文件的方式保存在磁盘中。
服务器出现问题后,我们可获取相应的atop日志文件进行分析,其比较强大的地方是其支持我们分析数据时进行排序、视图切换、正则匹配等处理。
需要注意的是,这里如果想查看网络的详细视图,还需要安装netatop包,该包安装时,需要linux下有kernel 的相关编译环境,需要编译出一个.ko文件,在内核中加载后才可以使用,netatop不安装 ,不影响CPU、mem、disk、io的性能监控。
二、atop日志位置和采集频率配置
数据文件存默认放在/var/log/atop目录下。日志文件按天进行保存,默认以"atop_YYYYMMDD"的方式命名、每10分钟采集一次数据、保留最近28天的数据 。
以上内容是在配置文件/etc/atop/atop.daily 中进行控制的,如下:
[root@localhost ~]# cat /etc/atop/atop.daily #!/bin/bash CURDAY=`date +%Y%m%d` #保留的文件名,可以进行自定义修改,如:加上主机名 LOGPATH=/var/log/atop BINPATH=/usr/bin PIDFILE=/var/run/atop.pid INTERVAL=600 # interval 10 minutes ,此处可以修改为30秒或1分钟采集一次 # verify if atop still runs for daily logging # if [ -e $PIDFILE ] && ps -p `cat $PIDFILE` | grep 'atop$' > /dev/null then kill -USR2 `cat $PIDFILE` # final sample and terminate CNT=0 while ps -p `cat $PIDFILE` > /dev/null do let CNT+=1 if [ $CNT -gt 5 ] then break; fi sleep 1 done rm $PIDFILE fi # delete logfiles older than four weeks # start a child shell that activates another child shell in # the background to avoid a zombie # ( (sleep 3; find $LOGPATH -name 'atop_*' -mtime +28 -exec rm {} \;)& ) #保留最近28天的数据,可以修改为最近一周的 # activate atop with interval of 10 minutes, replacing the current shell # echo $$ > $PIDFILE exec $BINPATH/atop -a -R -w $LOGPATH/atop_$CURDAY $INTERVAL > $LOGPATH/daily.log 2>&1
三、监控字段的含义

ATOP列:该列显示了主机名、信息采样日期和时间点
PRC列:该列显示进程整体运行情况
- sys、usr字段分别指示进程在内核态和用户态的运行时间
- #proc字段指示进程总数
- #zombie字段指示僵死进程的数量
- #exit字段指示atop采样周期期间退出的进程数量
CPU列:该列显示CPU整体(即多核CPU作为一个整体CPU资源)的使用情况,我们知道CPU可被用于执行进程、处理中断,也可处于空闲状态(空闲状态分两种,一种是活动进程等待磁盘IO导致CPU空闲,另一种是完全空闲)
- sys、usr字段指示CPU被用于处理进程时,进程在内核态、用户态所占CPU的时间比例
- irq字段指示CPU被用于处理中断的时间比例
- idle字段指示CPU处在完全空闲状态的时间比例
- wait字段指示CPU处在“进程等待磁盘IO导致CPU空闲”状态的时间比例
CPU列各个字段指示值相加结果为N*100%,其中N为cpu核数。
cpu列:该列显示某一核cpu的使用情况,各字段含义可参照CPU列,各字段值相加结果为100%
CPL列:该列显示CPU负载情况
- avg1、avg5和avg15字段:过去1分钟、5分钟和15分钟内运行队列中的平均进程数量
- csw字段指示上下文交换次数
- intr字段指示中断发生次数
MEM列:该列指示内存的使用情况
- tot字段指示物理内存总量
- free字段指示空闲内存的大小
- cache字段指示用于页缓存的内存大小
- buff字段指示用于文件缓存的内存大小
- slab字段指示系统内核占用的内存大小
SWP列:该列指示交换空间的使用情况
- tot字段指示交换区总量
- free字段指示空闲交换空间大小
PAG列:该列指示虚拟内存分页情况
swin、swout字段:换入和换出内存页数
DSK列:该列指示磁盘使用情况,每一个磁盘设备对应一列,如果有sdb设备,那么增多一列DSK信息
- sda字段:磁盘设备标识
- busy字段:磁盘忙时比例
- read、write字段:读、写请求数量
NET列:多列NET展示了网络状况,包括传输层(TCP和UDP)、IP层以及各活动的网口信息
- XXXi 字段指示各层或活动网口收包数目
- XXXo 字段指示各层或活动网口发包数目
四、视图模视与按键
1、默认视图(Generic information)
atop信息界面,按g键可以从其他视图跳到默认视图。
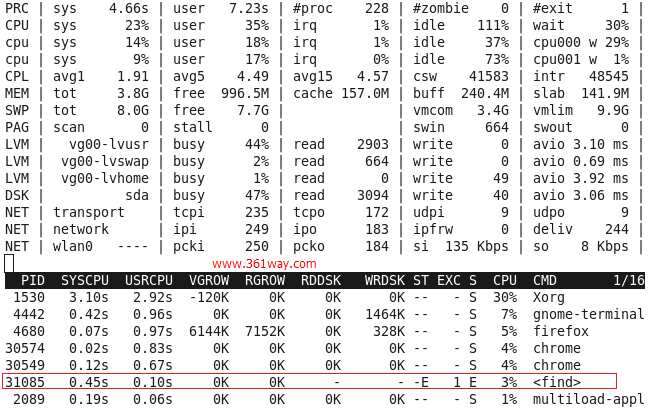
以下图为例,我们可以看到PID为31085的find进程在退出前在内核模式下占用了0.45秒CPU时间,在用户模式下占用了0.10秒CPU时间,相对10分钟采样周期,CPU时间占用比例为3%,ST列表示进程状态,N表示该进程是前一个采样周期新生成的进程,E表示该进程已退出,EXC列指示进程的退出码。从进程名在“<>”符号中,我们亦可知该进程已退出。
2、内存视图(Memory consumption)
按m键可进入内存视图,内存视图展示了进程使用内存情况,如下图:
上图下半部分展示了每个进程占用的虚拟内存空间(VSIZE)、内存空间(RSIZE)大小,以及在上一个采样周期中虚拟内存和物理内存增长大小(VGROW、RGROW),MEM列指示进程所占物理内存大小。从上图的PAG列的信息,我们可以知道此时系统内存负载较高,页交换比较频繁,而且可以看出物理内存几乎完全不可用,swap分区也比较繁忙,从进程视图中VGROW和RGROW列可看出 lekker 进程占用内存量大量增长,部分进程占用的内存减少(VGROW或RGROW字段为负值),为lekker进程腾出空间。
3、命令视图(Command line)
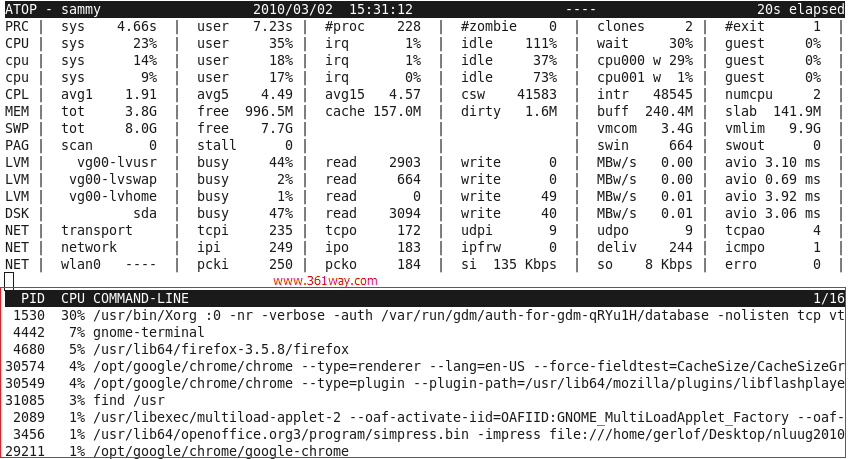
按c键可进入内存视图。
这个对于查看具体某个命令的详细参数,很容易通过该模式下查看到。比如,我们有多个java程序,普通视图下,可能看到的只显示为java ,但通过命令模式,我们可以方便的区分出,到底是哪个java程序占用资源比较高。如下图:
4、磁盘视图
通过按键d 可以进入磁盘视图,可以查看每个进程占用IO的情况。
5、快捷键汇总
读取atop日志文件: atop -r XXX
前进翻页: t
后退翻页: T
进程列表前进翻页: ctrl + f
进程列表后退翻页: ctrl + b
按时间跳转:
b
Enter new time (format hh:mm):
按hh:mm格式输入时间
进程视图:
g —— 默认输出
m —— 内存相关输出
d —— 磁盘相关输出
n —— 网络相关输出
c —— 命令行输出
u 查看对应的用户资源使用情况
p 显示所有每个进程的所有信息占用情况(disk、mem、io)
P(大写) 正则匹配,显示所有匹配到的进程
退出atop:q
五、atopsar 及其他
atopsar是一个类似于sar 的工具,其可以实时获取数据,也可以通过读取历史文件获取主机的 cpu、load 、io、mem等信息,不过该命令查看到的是全局信息,不是会显示具体某个进程的占用信息(O G D N 几个参数可以显示占用最高的前三个进程),具体用法如下:
SUSEt:/var/log/atop # atopsar --help
atopsar: invalid option -- '-'
Usage: atopsar [-flags] [-r file|date] [-R cnt] [-b hh:mm] [-e hh:mm]
or
Usage: atopsar [-flags] interval [samples]
Today's atop logfile is used by default!
Generic flags:
-r read statistical data from specific atop logfile
(pathname, or date in format YYYYMMDD, or y[y..])
-R summarize <cnt> samples into one sample
-b begin showing data from specified time
-e finish showing data after specified time
-S print timestamp on every line in case of more resources
-x never use colors to indicate overload (default: only if tty)
-C always use colors to indicate overload (default: only if tty)
-M use markers to indicate overload (* = critical, + = almost)
-H repeat report headers (in case of tty: depending on screen lines)
-a print all resources, even when inactive
Specific flags to select reports:
-A print all available reports
-c cpu utilization
-p process(or) load
-P processes & threads
-m memory & swapspace
-s swap rate
-l logical volume activity
-f multiple device activity
-d disk activity
-n NFS client mounts
-j NFS client activity
-J NFS server activity
-i net-interf (general)
-I net-interf (errors)
-w ip v4 (general)
-W ip v4 (errors)
-y icmp v4 (general)
-Y icmp v4 (per type)
-u udp v4
-z ip v6 (general)
-Z ip v6 (errors)
-k icmp v6 (general)
-K icmp v6 (per type)
-U udp v6
-t tcp (general)
-T tcp (errors)
-O top-3 processes cpu
-G top-3 processes memory
-D top-3 processes disk
-N top-3 processes network1、实时显示
如下为显示,每60s 刷新一次结果,共显示5次,如下官方的示例中,只有一个cpu ,如果有多个CPU,会显示每个core的占用情况。
$ atopsar -c 60 5
myhost 2.6.18.3up #7 Wed May 30 13:57:06 CEST 2009 i686 2009/08/17
-------------------------- analysis date: 2009/08/17 --------------------------
14:22:11 cpu %usr %nice %sys %irq %softirq %steal %wait %idle _cpu_
14:23:11 all 2 0 8 1 1 0 88 0
14:24:11 all 32 0 38 1 1 0 28 0
14:25:11 all 43 0 45 2 1 0 0 9
14:26:11 all 2 0 2 1 1 0 15 79
14:27:11 all 2 0 1 0 0 0 11 86
2、读取文件,指定范围
下面的示例中,指定了读取哪一天的数据文件,并指定起止时间,-A 参数是输出所有项
$ atopsar -A -b 13:00 -e 13:35 -r atop_20130818
myhost 2.6.18.3up #7 Wed May 30 13:57:06 CEST 2009 i686 2009/08/17
-------------------------- analysis date: 2009/08/17 --------------------------
13:00:01 cpu %usr %nice %sys %irq %softirq %steal %wait %idle _cpu_
13:10:01 all 6 0 8 4 4 0 54 24
13:20:01 all 10 0 12 4 4 0 56 15
13:30:01 all 31 0 9 3 3 0 35 19
13:00:01 pswch/s devintr/s clones/s loadavg1 loadavg5 loadavg15 _load_
13:10:01 8042 6256 0.33 1.12 0.99 0.51
13:20:01 8575 5806 0.34 1.31 1.28 0.89
13:30:01 6594 4397 0.39 1.29 1.54 1.22
13:00:01 clones/s pexit/s curproc curzomb thrrun thrslpi thrslpu _procthr_
13:10:01 0.33 0.33 150 0 1 167 0
13:20:01 0.28 0.26 151 0 1 163 0
13:30:01 0.71 0.72 143 0 2 173 0
13:00:01 memtotal memfree buffers cached slabmem swptotal swpfree _mem_
13:10:01 995M 12M 48M 718M 56M 1983M 1895M
13:20:01 995M 13M 60M 705M 57M 1983M 1895M
13:30:01 995M 13M 62M 702M 57M 1983M 1895M
………………输出太多,省略
3、其他
atop启动后,除了atop 进程本身外,还会启动一个atopacctd 进程,该进程是一个计数进程,其数据文件存放在如下路径:
/var/run/pacct_source
/var/run/pacct_shadow.d/current
/var/r
top、iftop、iotop、htop、atop工具区别
top
实时显示linux的资源
Iftop
主要用来显示本机网络流量情况及各相互通信的流量集合,如单独同那台机器间的流量大小,非常适合于代理服务器和iptables服务器使用
Iotop
是一个用来监视磁盘 I/O 使用状况的 top 类工具。如下图所示,Iotop 具有与 top 相似的 UI,其中包括 PID、用户、I/O、进程等相关信息Iotop 使用 Python 语言编写而成,要求 Python 2.5(及以上版本)和 Linux kernel 2.6.20(及以上版本)。
htop
htop 是Linux系统中的一个互动的进程查看器,一个文本模式的应用程序(在控制台或者X终端中),需要ncurses。与Linux传统的top相比,htop更加人性化。它可让用户交互式操作,支持颜色主题,可横向或纵向滚动浏览进程列表,并支持鼠标操作。
htop相比较top的优势:
可以横向或纵向滚动浏览进程列表,以便看到所有的进程和完整的命令行。
在启动上比top 更快。
杀进程时不需要输入进程号。
htop 支持鼠标选中操作(反应不太快)。
Atop----有日志
atop 是一个系统性能监控工具,可以在系统级别监控 CPU、内存、硬盘和网络的使用情况。
atop 不仅可以以交互式的方式运行,还可以一一定的频率,将性能数据写入日志中。所以当服务器出现问题之后,便可分析 atop 日志文件来判断是否有进程异常退出、内存和 CPU 方面的异常。
atop用法_atop 简单使用:https://blog.csdn.net/weixin_39631951/article/details/111803887
slabtop
简介:实时显示内核slab内存缓存信息
powertop
iotop
jnettop
BandwidthD
NetHogs
dstat