ORM框架如何选型——各大ORM框架比较
现有ORM框架或ORM相关框架主要有Hibernate,Mybatis。这两个框架本来是为了解决直接用JDBC操作数据库带来的烦锁重复工作,但它们却引起了其它的问题。有人报怨Mybatis,很简单的操作,都要写sql语句;有人报怨当用户要用自定义sql的方式时Hibernate是如何的难用,要想熟悉Hibernate是如何的困难。除此之外,还有些问题,是它们二者都具有的,如编码复杂度为O(n)。
- 本文用到的术语解释
Suid:对数据库的SQL命令查询、更新、插入与删除(select、update、insert、delete)四种操作的简称(Suid为四种操作首字母)。
编码复杂度C(n):编码复杂度用于描述编码量与所解决问题的规模的关系。如,在MVC编程中,一般会涉及到action,service,dao,model(实体)。当用面向对象方式操作一个DB表时,要写一份dao;当操作两个表时,要写两份dao;当操作n个表时,要写n份dao;则此时编码的复杂度会随着问题规模增长为n,编码复杂度也变成n。关于问题n的编码复杂度(Coding Complexity)用C(n)表示。则上面描述问题的编码复杂度为:C(n)=O(n)。
2. 现有ORM框架存在的问题
现有ORM框架或ORM相关框架存在的问题,主要参考Hibernate和Mybatis。
- 对于每个实体,需要写一个dao接口文件。编码复杂度C(n)=O(n),即会随实体的增长,编码量呈线性增长。当n较大时,会增加许多人力物力消耗。
- 实体Javabean与DB表的map映射文件太多;或者,实体Javabean文件注解太多,难以记忆。
- 查询操作若用非id字段作为查询条件,需要在接口文件新定义方法。如一个实体有10个字段,2个字段组合一个查询方法,则有45个查询方法;若算上3个字段,4个字段的组合,则更多。
- 当一个表新增、删除或修改一个字段时,Mybatis需要修改映射文件,几乎其中的每个方法都要修改。修改字段,Mybatis在编译期不能自动发现错误。Hibernate通过xml文件或有注解的Javabean文件,同步DB的表结构时,也不能实现删除和更新。更新时,它是忽略原来的字段,然后新增一个字段,除非先删除表再新建表。要是DB的表已保存了数据,不能删除,还是要手动更改表。
- Hibernate的概念太复杂,学习成本高,更新会先查询再更新,n+1问题。Mybatis即使进行单表的Suid操作也需要人工写sql或生成sql文件,需要维护的sql太多。
- 需要写很多的判断字段是否为空(null),是否是空字符串的语句;工作重复,乏味。
- Criteria类语法风格与SQL原来的语法风格相差甚远,相当于要学一门新的SQL语言。
软件开发中,对数据库的访问操作,约80%的工作可以由简单的面向对象操作方式完成,只有约20%的工作才需要复杂的sql语句完成。当一个ORM框架为了使这20%的工作量也可以用面向对象的方式实现时,这个ORM框架的复杂度,就会随着完成这20%的比例而急剧上升,但还是避免不了用户用自定义sql语句操作数据库的情况发生。也就是说,即使一个ORM框架可以100%的实现面向对象方式操作数据库,它还是需要提供直接用原生sql语句操作数据库的接口。毕竟,有时用户为了提高性能,需要这样操作。另外,面向切面编程AOP被视为面向对象编程OOP的补充,也说明面向对象不能做完所有的事情。
3. 使用举例及对比分析
3.1 Hibernate ORM使用举例
例子是来源于Spring data的官网(https://spring.io/guides/gs/accessing-data-mysql/),采用JPA的方式。
3.1.1每个实体对应的dao接口
public interface UserDao extends CrudRepository<User, Integer> { }
public interface OrdersDao extends CrudRepository<Orders, Long> {
//不能用组合条件.若要用,需要在对应接口写方法
List<Orders> findByUseridAndTotal(String userid, BigDecimal total); }
public interface OrderitemDao extends CrudRepository<Orderitem, Long> { }
3.1.2保存和查询数据库表的举例代码
//定义userDao ,ordersDao,orderitemDao;
//...其它省略代码
User user = new User();
user.setName("testName");
userDao.save(user);
ordersDao.save(orders);//省略部分代码
orderitemDao.save(orderitem); //省略部分代码
// ordersDao.findOne(id); //不能用组合条件.若要用,需要在对应接口写方法
List<Orders> list = (List<Orders>) ordersDao.findByUseridAndTotal("Hibernate",new BigDecimal("92.22"));
3.2 Bee ORM使用举例
例子源码可浏览网址:https://github.com/automvc/bee
3.2.1每个实体对应的dao接口
不需要。
3.2.2插入和查询数据库表的举例代码
public static void main(String[] args) {
Suid suid=
BeeFactory.getHoneyFactory().getSuid();
User user = new User();
user.setName("testName");
user.setRemark(""); //empty String test
suid.insert(user); //insert
//省略orders部分代码
suid.insert(orders); //insert
//省略orderitem部分代码
suid.insert(orderitem); //insert
List<Orders> list =suid.select(orders); //可任 意组合条件查询
}
3.3结果对比
结果对比,如表1所示。
表1 结果对比
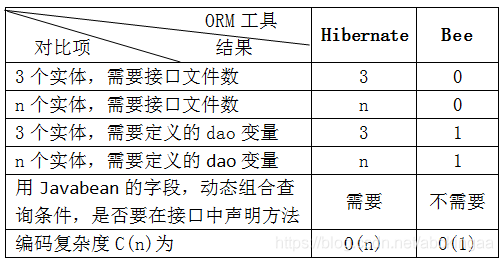
Mybatis也有类似的问题,写mapper文件,或用一种插件简化操作,但还是有同样的问题。有些人,找些了工具,自动生成一堆的代码,说生成后也可以用。但试问,这些代码要不要我们维护些,当需要有变更时,还是需要我们去更改。要是真的有直接生成就可直接能用的,就不会有那么多程序员了。还是简单为好呀。(感兴趣可以了解下当年火热一时的EJB。EJB号称强大,但很复杂,然后在那个年代,产商就自动生成些代码卖给客户。后来要维护那些代码了,客户就开始抱怨了。再后来就有了Spring了)
Bee框架中ORM的编码复杂度C(n)由O(n)变为O(1)。Bee框架使用统一的dao操作DB,即使需要完成的DB操作的Javabean增加,也不用开发人员再写任何额外的dao文件。不需要Javabean与数据库表的映射文件,降低程序所占用的内存资源,提高运行效率。Javabean模型不再有注解,利于代码移植。开发人员只需关注Bee框架的面向对象方式Suid和SuidRich接口如何使用即可。当问题规模很大时,却不需要额外的劳动付出。
Bee 是一个简单,易用,功能强大,开发速度快,编码少的 JAVA ORM 框架。
Bee主要功能特点介绍:
Bee概念简单(10分钟即可入门)、功能强大。
Bee 简化了与DB交互的编码工作量.连接,事务都可以由Bee框架负责管理。
- 1.接口简单,使用方便。Suid接口中对应SQL语言的select,update,insert,delete操作提供4个同名方法。
- 2.使用了Bee,你可以不用再另外编写dao代码,直接调用Bee的api即可完成对DB的操作。
- 3.约定优于配置:Javabean没有注解,也不需要xml映射文件,只是纯的Javabean即可,甚至get,set方法不用也可以。
- 4.智能化自动过滤null和空字符串,不再需要写判断非空的代码。
- 5.动态/任意组合查询条件,不需要提前准备dao接口,有新的查询需求也不用修改或添加接口。
- 6.支持原生SQL排序, 原生语句分页(不需要将全部数据查出来)。
- 7.支持直接返回Json格式查询结果; 链式编程。
- 8.支持事务、多个ORM操作使用同一连接、for update,支持批处理操作,支持原生SQL(自定义sql语句),支持存储过程。
- 9.支持只查询一部分字段。
- 10.支持面向对象方式复杂查询、多表查询(无n+1问题; 支持:一对一,一对多,多对一,多对多)。
- 11.一级缓存,概念简单,功能强大;一级缓存也可以像JVM一样进行细粒度调优;智能缓存,支持更新配置表,不用重启。
- 12.表名与实体名、字段名与属性名映射默认提供多种实现,且支持自定义映射规则扩展。
- 13.多种DB支持轻松扩展(MySQL,MariaDB,Oracle,H2,SQLite,PostgreSQL,SQL Server等直接可用)。
- 14.支持读写分离一主多从, 仅分库等多数据源模式(对以前的代码无需修改,该功能对代码是透明的,即无需额外编码),仅分库可同时使用多种类型数据库。
- 15.分布式环境下生成连续单调递增(在一个workerid内),全局唯一数字id;提供自然简单的分布式主键生成方式。
- 16.支持同库分表,动态表名映射。
- 17.可以不用表对应的Javabean也能操作DB。
- 18.无第三方插件依赖;可零配置使用。
- 19.性能好:接近JDBC的速度;文件小:Bee V1.8 jar 仅217k, V1.9.5 jar,仅315k。
辅助功能: - 20.支持自动生成表对应的Javabean,根据Javabean创建表,Javaweb后端代码根据模板自动生成;能打印非占位符的可执行sql,方便调试。
- 21.支持读取Excel,从Excel导入数据到DB,操作简单。