LSM树的学习总结-简明-更新中...
LSM树的概念
- 英文全名 The Log structured Merage - Tree
LSM树的原理
- 基础原理1:内存存储速度比磁盘快
- 基础原理2:批量写入磁盘速度比随机写入磁盘速度快
- 基础原理3:日志追加写入比覆盖写入速度快
- 基础原理4:放弃部分读性能换取写性能
LSM的写入流程如下
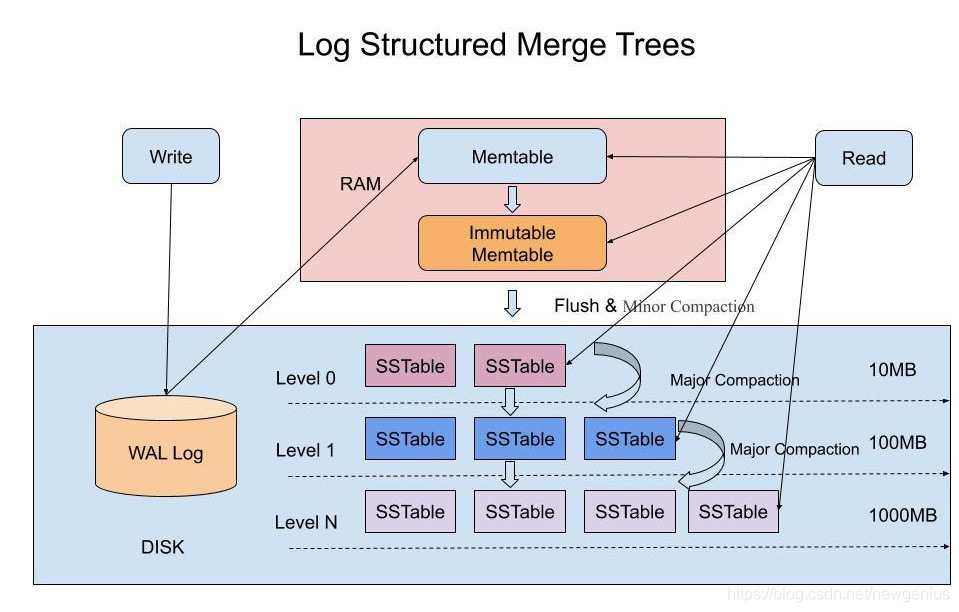
- 首先写WAL日志,避免故障导致数据丢失;
- 将数据写入C0内存中memtable,相当于在内存中保留最新的数据更新。
- 当C0内存中的数据达到一定量级的时候(大小限制)会将C0中的数据flush到磁盘C1中,并且对磁盘C1层级的数据进行合并(归并排序)。
- 当磁盘C1层级大小到一定规模,又会将C1中的数据同C2合并(归并排序)。
- 以此类推,上一层级的数据文件达到一定规模后,会向下一层级合并。
LSM树的使用
- Elasticsearch,HBase, Cassandra, RockDB 等都是基于 LSM Tree 来构建索引。
- HBase存储的设计主要思想:LSM树原理把一棵大树拆分成N棵小树,它首先写入内存中,随着小树越来越大,内存中的小树会flush到磁盘中,磁盘中的树定期可以做merge操作,合并成一棵大树,以优化读性能。
LSM树和B树、B+树的区别
- 日志结构的合并树(LSM-tree)是一种基于硬盘的数据结构,与B-tree相比,能显著地减少硬盘磁盘臂的开销,并能在较长的时间提供对文件的高速插入。适用于索引插入比检索更频繁的应用系统
- 极端情况下:基于LSM树实现的HBase的写性能比和基于B+树实现的MySQL高了一个数量级,读性能低了一个数量级。
- B树的写入过程如下:
- 查找到对应的块的位置,将新数据写入到刚才查找到的数据块中,
- 查找到块所对应的磁盘物理位置,将数据写入去。
- 当然,在内存比较充足的时候,因为B树的一部分可以被缓存在内存中,所以查找块的过程有一定概率可以在内存内完成,不过为了表述清晰,我们就假定内存很小,只够存一个B树块大小的数据吧。
- B树是一种平衡多路搜索树,B树与红黑树最大的不同在于,B树的结点可以有多个子女,从几个到几千个。
- B树:多路搜索树,每个结点存储M/2到M个关键字,非叶子结点存储指向关键字范围的子结点;所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中;
- B+树:在B-树基础上,为叶子结点增加链表指针,所有关键字都在叶子结点中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中;
- B+树虽然优点很多,但是B树也有优点,其优点在于,由于B树的每一个节点都包含key和value,因此经常访问的元素可能离根节点更近,因此访问也更迅速。
参考资料
【0】《深入理解ElasticSeach》
【1】https://www.jianshu.com/p/6043aaaccd8a
【2】https://blog.csdn.net/f1550804/article/details/88382750
【3】https://blog.csdn.net/wushiwude/article/details/84864206
【4】https://www.cnblogs.com/yefeng654321/articles/11422231.html
版权声明:本文为newgenius原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。