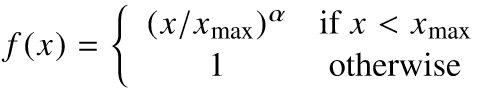分类
一、Count-based
1. LSA
介绍
LSA是基于滑动窗口的共现矩阵(co-occurence)以及SVD的方法,通过SVD来对共现矩阵进行降维,从而获得低维度的词向量。
实现:
假设window长度为1
语料库中包含三个句子:
① I like deep learning.
② I like NLP.
③ I enjoy flying.
通过滑动窗口可得到如下共现矩阵: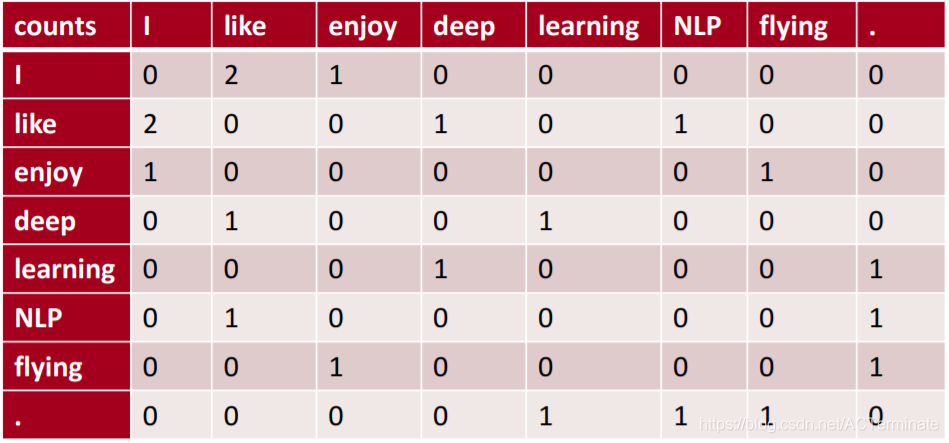
共现矩阵已经可以看成是一个包含词向量的矩阵,但是维度太高,并且具有稀疏性。因此通过SVD降维,获取矩阵奇异向量。在这里,获得的左奇异向量或者右奇异向量均可表示为词向量。
优缺点
优点:
① 训练速度快。(对于较小的共现矩阵)
② 只需要遍历一次语料库,因此可以有效利用统计信息。
缺点:
① 主要捕获的词之间的相似性。
② 对于计数大的词往往得到不成比例的重要性。
二、Direct-Prediction
1. word2vec——Skip-gram、CBOW
介绍
Skip-gram通过中心词来预测周围的词,CBOW则是刚好相反,通过周围的词来预测中心的词。CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好。这里只介绍一下Skip-gram。
Skip-gram是对语料库中每一个窗口,在某个中心词下,对周围词的概率分布进行预测,主要的任务是预测周围词汇,但我们更关注其产生的附加产物—词向量。
实现
Loss函数为:
J ( θ ) = − 1 T ∑ t = 1 T ∑ j = − m m p ( w t + j ∣ w t ; θ ) J(\theta)=-\frac{1}{T} \sum^T_{t=1}\sum^{m}_{j=-m}p(w_{t+j}|w_t;\theta)J(θ)=−T1∑t=1T∑j=−mmp(wt+j∣wt;θ)
m为窗口大小。
p ( w t + j ∣ w t ; θ ) = p ( o ∣ c ) = e x p ( u o T ∗ v c ) ∑ w = 1 V e x p ( u w T ∗ v c ) p(w_{t+j}|w_t;\theta)=p(o|c)=\frac{exp(u_o^T*v_c)}{\sum_{w=1}^Vexp(u_w^T*v_c)}p(wt+j∣wt;θ)=p(o∣c)=∑w=1Vexp(uwT∗vc)exp(uoT∗vc)
V为词库大小
模型结构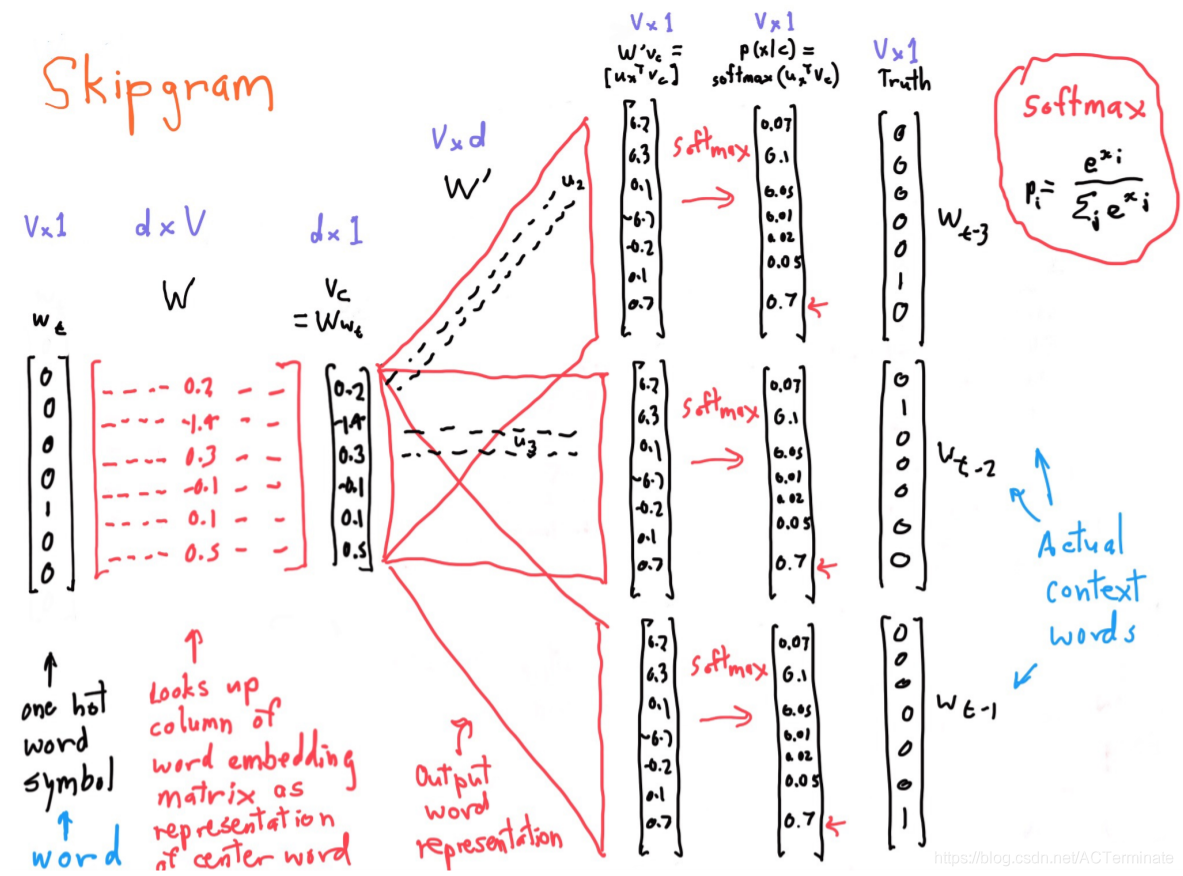
负采样
由于Softmax函数往往需要一个很大的计算量,因此可以通过负采样加速。
负采样Loss函数:![]()
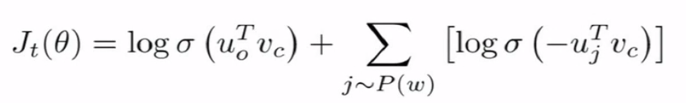
其中![]()
优缺点
优点:
① 对于下游任务会有更好的表现
② 可以捕获更复杂的特征,不只是词的相似性。
缺点:
①会缩放语料库的尺寸。
②需要遍历每一个单一窗口,因此不能有效利用统计信息。
三、GloVe
介绍
GloVe综合了Count-based与Direct-Prediction的优点,既有全局统计信息,也包含了概率模型。
实现
Loss函数: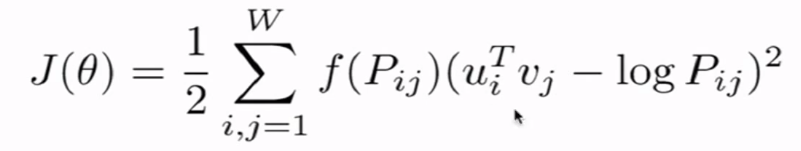
f函数用于约束出现次数非常大的单词产生的损失(α在3/4时效果最好):