一、前言
对数据库的使用越来越频繁,良好的数据库sql操纵能力,能提升数据库的应用能力,提升工作效率。下面整理一些的数据库内置函数与自己在开发中常用的SQL。平时能够用到的数据库函数虽然不多,但是在对数据库的操作中,充分利用各种嵌套、分组、多种函数组合使用、存储过程等能提升工作效率,减少工作投入时间。
二、数据库内置函数
数字统计函数:
求平均值: AVG(column)
统计记录数:count(column) 不包含null 值 count(column) 包含null值
求和:sum(column)
最大值:max(column)
最小值:min(column)
求字段存储长度:length(column)
操作函数字符
字符串截取:left(str,len) 返回字符左边len长度的 字符串
字符串截取:right(str,len) 返回右边了len长度的字符串
字符串截取:substr(str,9,4),第九个字符开始,往后4位
例如:update pm_offer aset a.rel_id=concat(concat(110,substr(offer_id,8,7)),substr(com_spec_id,9,4))where a.offer_id='110009210089'
字符拼接:concat(str1,str2)
返回字符个数:CHAR_LENGTH (column)
转成小写:lower(column)
转成大写:upper(column)
反转字符串:REVERSE(column)
去掉左右两边的空格:LTRIM (column) RTRIM(str)
字符串替换:`REPLACE`(str,from_str,to_str) 在ste中找到 from_str 子字符串用to_str替换
子字符串开始出现的位置:SELECT INSTR(a.offer_name,'fa') from pm_offer a where a.offer_name='aafadfd'
时间函数
返回当前系统时间:now()
获取当前时间戳为:select unix_timestamp(now())
插入操作:
可以根据查到的数据,取其中的字段插入到另外一个表。例如
insert into pm_cha (CHA_SPEC_ID, CHA_SPEC_TYPE, CHA_SPEC_NAME, SHOW_MODE, FIELD_NAME, FIELD_TYPE, DESCRIPTION, STATUS, DONE_CODE, CREATE_DATE, DONE_DATE, OP_ID, ORG_ID, REMARK)
select
concat(a.offer_code,30032), '0', 'd', '0', '30032', 'D', '折扣', '1', 9999, to_date('28-05-2017 21:26:31', 'dd-mm-yyyy hh24:mi:ss'), to_date('28-05-2017 21:26:31', 'dd-mm-yyyy hh24:mi:ss'), 'songxw', '00000', 'test'
from pm_offer a where a.code in(
select t.attr_code from td_bt where t.attr_obj='DIS' and t.attr_value between '9207345003' and '9207345004'
)
三、常用SQL
排序 : order by 字段 升序asc 序降 desc
例如:select a.*from td_b awhere a.attr_bbc='DIS' and a.attr
in(
'9200371901','9200373901','9200374901'
)order by attr asc
多重嵌套:
select a.*from offer_join awhere a.rel_offer_idin(
select k.offer_idfrom pm_offer kwhere k.offer_codein(
select t.attr_codefrom ucr_cen1.td_b_attr_biz twhere t.attr_obj='DD' and t.attr_codein('33333','22222','3321','1111')
)
)order by a.rel_offer_idasc
左右关联: left right
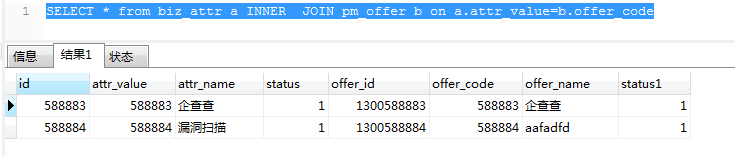
左关联:SELECT * from biz_attr a LEFT JOIN pm_offer b on a.attr_value=b.offer_code
包含左边所有和右表满足条件的。右关联类似。
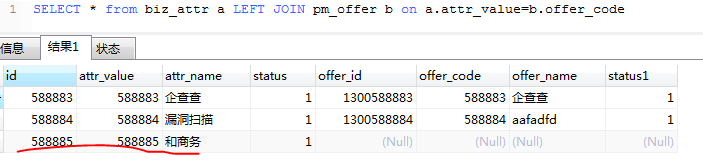
有关联:SELECT * from biz_attr a RIGHT JOIN pm_offer b on a.attr_value=b.offer_code
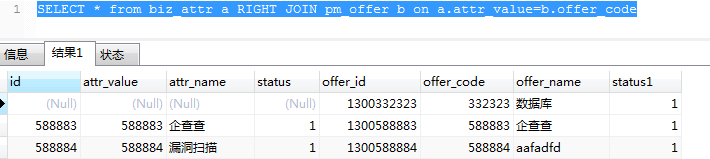
内连接:SELECT * from biz_attr a INNER JOIN pm_offer b on a.attr_value=b.offer_code
返回两表交集部分。
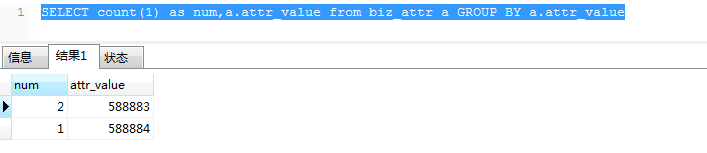
分组 group by 字段
语句常常用于结合聚合函数,根据一个或多个列对结果集进行分组统计
SELECT count(1),a.attr_value from biz_attr a GROUP BY a.attr_value 根据条件统计个数
Oracle建表
create table TD_B_DAYACCOUNT_INFO
(
OPERTYPE VARCHAR2(30),
ACCT_ID NUMBER(20),
CUST_ID NUMBER(20),
CUSTOMERNUMBER VARCHAR2(32),
BE_ID NUMBER(10),
REGION_ID NUMBER(20),
EFF_DATE DATE,
EXP_DATE DATE,
ACCT_CODE VARCHAR2(32),
RSRV_STR1 VARCHAR2(100),
RSRV_STR2 VARCHAR2(100),
RSRV_STR3 VARCHAR2(100),
INSERTTIME DATE,
NOWMONTH NUMBER(10)
)
--表空间,Oracle创建的表一定要有表空间
tablespace TBS_ACT_DSTA
pctfree 10
initrans 1
maxtrans 255
storage
(
initial 16K
next 8K
minextents 1
maxextents unlimited
);
comment on column TD_B_DAYACCOUNT_INFO.OPERTYPE
is '2:开户 9:销户';
comment on column TD_B_DAYACCOUNT_INFO.ACCT_ID
is '账户标识';
comment on column TD_B_DAYACCOUNT_INFO.CUST_ID
is '账户归属的注册客户的标识';
comment on column TD_B_DAYACCOUNT_INFO.CUSTOMERNUMBER
is '客户编码,关联7.1.4.1EC信息同步接口的CustomerNumber';
comment on column TD_B_DAYACCOUNT_INFO.BE_ID
is '对应省代码';
comment on column TD_B_DAYACCOUNT_INFO.REGION_ID
is '隶属行政区域标识';
comment on column TD_B_DAYACCOUNT_INFO.EFF_DATE
is '记录的生效时间';
comment on column TD_B_DAYACCOUNT_INFO.EXP_DATE
is '记录的失效时间';
comment on column TD_B_DAYACCOUNT_INFO.ACCT_CODE
is '账户编码';
comment on column TD_B_DAYACCOUNT_INFO.RSRV_STR1
is '备用字段1';
comment on column TD_B_DAYACCOUNT_INFO.RSRV_STR2
is '备用字段2';
comment on column TD_B_DAYACCOUNT_INFO.RSRV_STR3
is '备用字段3';
四、视图
视图是从一个或几个基本表(或视图)导出的表。它与基本表不同,是一个虚表。数据仍然存放在原来的基本表中,所以一旦基本表的数据发生变化,视图中的数据也会发生变化。
create view<视图名>
as
<子查询>
例如:
CREATE view crview
as
SELECT * from biz_attr a;
五、过程化SQL
基本的sql是高度非过程化的。嵌入式SQL 和SQL语句嵌入程序设计语言中,借助高级语言的控制功能实现过程化。过程化SQL是对SQL的扩展,使其增加了过程化的功能。
涉及:
1、常量和变量的定义
2、流程控制(条件控制 循环控制 错误处理)
过程化sql块的基本结构包含
1、定义部分
2、执行部分
具体应用之中有存储过程、函数、触发器、下面来简单的描述这几个的用法。
六、存储过程
存储过程是由过程化SQL语句书写的过程,这个过程经编译和优化后存储在数据库服务器走过,因此称它为存储过程。使用时调用即可。
创建存储过程:create procedure 存储过程名(参数)//可定义的参数类型有:输入、输出、输入/输出三种类型
例如 输入参数:
CREATE PROCEDURE sp_getname(int id BIGINT)
BEGIN
select * from pm_offer where offer_id=id;
end;
调用:call sp_getname(1222);
例如 输出参数:
CREATE PROCEDURE getmax(out x BIGINT)
BEGIN
SELECT MAX(offer_id) into x from pm_offer;
end;
调用:
set @x=1; #定义
call getmax(@x); #执行
SELECT @X #查询
例如 输入输出参数类型
CREATE PROCEDURE getmin(INOUT x BIGINT)
BEGIN
select MIN(offer_id) into x from pm_offer;
end;
调用:
set @y=1111;
call getmin(@y)
select @y;
存在条件控制语句的存储过程示例
CREATE PROCEDURE exeifsql(in x BIGINT)
BEGIN
DECLARE y BIGINT default 0;
SELECT AVG(offer_id) into y from pm_offer;
if y > x
then
SELECT * from pm_offer where offer_id=x;
else
SELECT * from pm_offer;
end if;
end;
调用:类似
七、函数
数据库系统有自己的内嵌函数,也可以自己自定义函数。自定义函数是用户自己使用过程化SQL设计定义的。函数与存储过程类似。不同之处是函数必须指定返回类型。
例如:
CREATE FUNCTION tste.myfunction(mydata BIGINT) RETURNS BIGINT
BEGIN
DECLARE temp BIGINT default 2;
set temp=mydata+10;
RETURN temp;
END;
调用:SELECT tste.myfunction(100) 结果 110
八、触发器
触发器(trigger)是用户定义在关系表上的一类由事件驱动的特殊过程,一旦定义触发器将被保存在数据库服务器中,任何用户对表的增、删、改操作均由服务器激活相应的触发器。
创建触发器:
create trigger <触发器名>
{before|after}<触发事件> on <表名>
<触发类型>
<触发条件>then<触发动作体>
实例:
在修改offer表时,如果修改的offer_name的名称为企查查,同时修改另外一张表的字段attr_name的名称。
CREATE TRIGGER testTri
after update on pm_offer
for EACH ROW
BEGIN
if old.offer_name='企查查'
then
update tste.biz_attr set attr_name=new.offer_name where attr_name=old.offer_name;(不允许与触发事件表为同一个表)
end if;
END
update pm_offer set offer_name='云飞信' where offer_name='企查查'