1. 卡方检验
卡方检验应用于计数数据的分析,对于总体的分布不作任何假设,因此它又是非参数检验法中的一种.理论证明,实际观察次数与理论次数 ,又称期望次数)之差的平方再除以理论次数所得的统计量,近似服从卡方分布,由统计学家皮尔逊推导。
1.1 思想
根据样本数据推断总体的分布于期望分布是否有显著性差异。
1.2 本质
检测两组数据的差异。其检验假设是"两组数据是相互独立的"。
1.3 解决问题
分类问题,通过计算每个非负特征与标签之间的相关统计量,并按照卡方统计量由高到低对特征进行排名。
1.4 相关统计量
卡方检验的两个统计量卡方值和P值。卡方值很难界定有效范围,P值一般使用0.01和0.05作为显著性水平,即使用P值来判断边界。
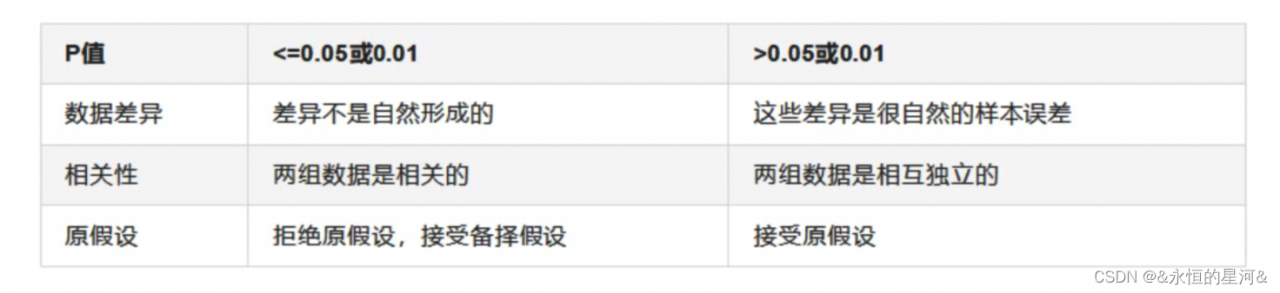
从特征角度来说,希望卡方值很大,P值小于0.5的特征,即和标签相关联的特征。
卡方值计算:
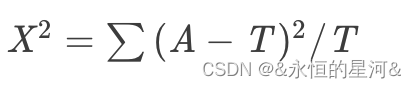
其中,A为实际值,T为理论值
卡方值解释:
- 实际值与理论值偏差的绝对大小
- 差异程度与理论值得相对大小
1.5 特征选择案例
假设我想检验一个男人有特殊着装癖好与其变态与否的关系,如果检验的结果是二者不独立,那下次在街上看见女装大佬我可能就要绕着走了。 所以该独立性检验的假设如下:
零假设 (H0):着装偏好与变态倾向独立
备选假设 (H1) :着装偏好与变态倾向不独立
卡方检验一般需要先建立列联表,表中每个格子是观察频数,表示实际观测到的同时满足两个条件的数量:
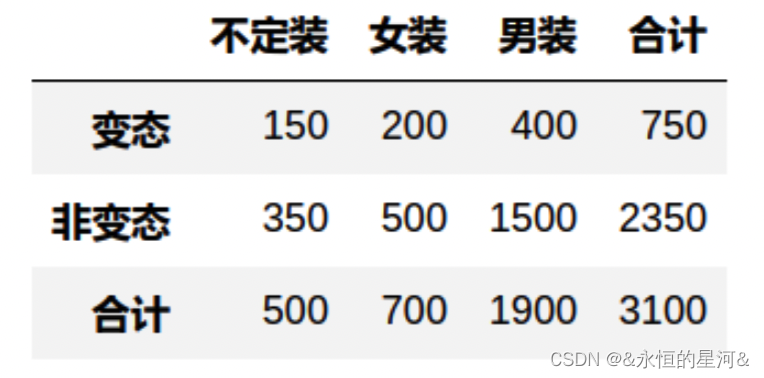
同时需要计算每个格子的期望频数,因为零假设是两个变量独立,因此依独立性的定义:
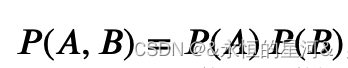
于是上表中每个格子的期望频数为:
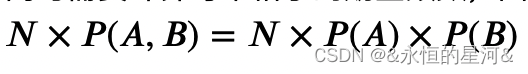
其中 N 为总数量,那么第一个格子的期望频数为:
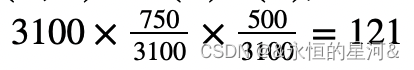
因此总体期望频数表为:
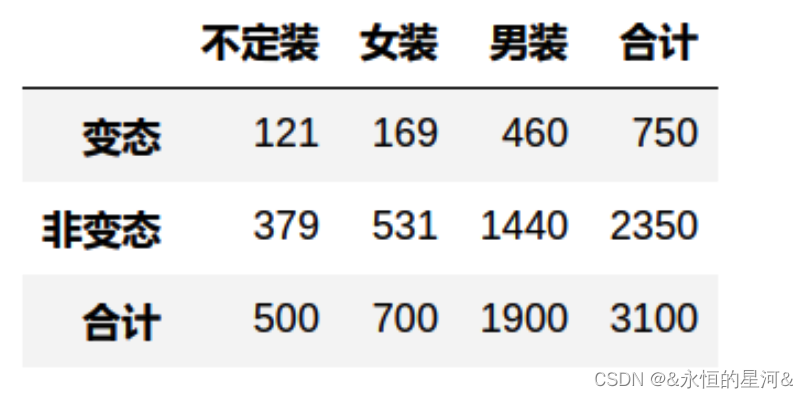
有了这两个列联表后,就可以计算检验统计量 ?2 ( ?2 表示卡方值) ,?2 越大,表示观测值和理论值相差越大,当 ?2 大于某一个临界值时,就能获得统计显著性的结论:

其中 ???为观测频数表中单元格的数值,???为期望频数表中单元格的数值,?为行数,?为列数,自由度 ??为 (2−1)×(3−1)=2 ,?2服从卡方分布,则查卡方分布表:

得 ?(?2>13.82)<0.001,而实际计算出的 ?2为 26.99,显著性很高,意味着零假设成立的情况下样本结果出现的概率小于 0.1%,因而可以拒绝零假设,接受备选假设。这意味着男性的特殊着装偏好与变态倾向具有相关性。当然这里得说明两点:
- 本数据纯属虚构。
- 相关性不代表因果性,完全可能是第三个变量 (如:国籍) 同时导致了女装和变态,致使这两个变量产生了某种相关性。
机器学习问题中动辄就有几千至上百万的特征,实际上比较关心的是特征的相对重要性。依上面的卡方分布表,检验统计量 ?2越大,越有信心拒绝零假设,接受两个变量不独立 的事实,因而可以按每个特征 ?2值的大小进行排序,去除 ?2值小的特征。
2. F检验
F 检验又称为ANOVA,用来捕捉每个特征与标签之间的线性关系的过滤方法。F检验是一类建立在 F 分布基础上的假设检验方法,服从 F 分布的随机变量与上文中卡方分布的关系如下:
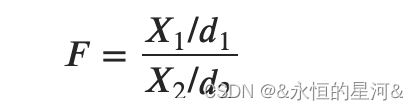
其中 ?1和 ?2分别服从自由度为 ?1和 ?2的卡方分布,即 ?1∼?2(?1),?2∼?2(?2),且 ?1与 ?2独立,则随机变量 ? 服从自由度为 (?1,?2)的F分布,记为 ?∼F(?1,?2)。
2.1 解决问题
可以用于标签是离散变量的数据,也可以是连续变量的数据。
2.2 如何选择特征
和卡方过滤一样,希望选取P值小于0.05或者0.01的特征,这些特征与标签显著线性相关。而P值大于0.05或者0.01的特征被认为是和标签没有显著线性关系的特征,应该给删除。
2.4 F检验原理
F检验可以适用于分类问题和回归问题,分别对应单因素方差分析和线性相关分析,下面分别介绍。
单因素方差分析(只适用于连续型特征)
在卡方检验中我们要测试的是被检验的特征与类别是否独立,若拒绝零假设,则特征与类别相关。而在方差分析中则采用了不同的思路: 按照不同的标签类别将特征划分为不同的总体,我们想要检验的是不同总体之间均值是否相同 (或者是否有显著性差异)。下面承接上文的例子,类别为变态与否,因为方差分析只适用于连续型特征,所以这里采用了 “身高” 这个特征:
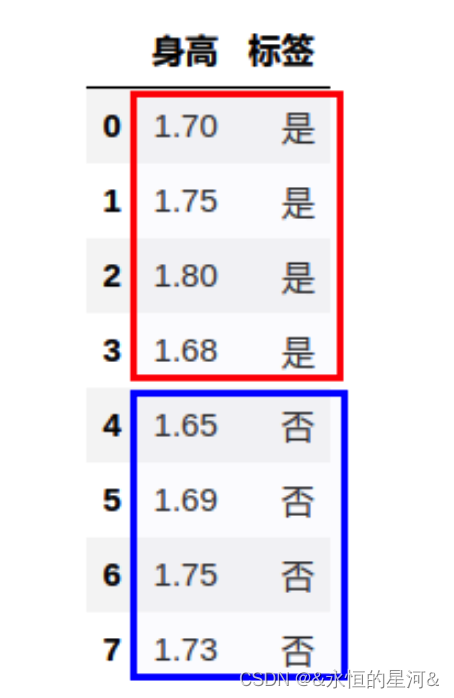
上图中红框和篮框中的特征值对应于两个类别区分出的两个不同的总体。方差分析用于特征选择的逻辑是这样: 如果样本中是变态的平均身高为 1.7 米,非变态的平均身高也为 1.7 米,凭身高无法判定一个人变态与否,那么说明身高这个特征对于类别没有区分度,则可以去除。反之,若前者的平均身高为 1.6 米,后者的平均身高为 1.9 米,那么我们有理由认为身高很能区分变态与否。因此将问题形式化为假设检验问题.
零假设 (?0): ?1=?2=⋯=??
备选假设 (?1) : ?个总体的均值不全相等
下面阐述方差分析的原理。设共有 ?个类别,总样本数为 ?,第 ?个类别的样本数为 ??,???表示第 ?个类别的第 ?个样本,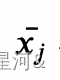 表示第 ?个类别的样本均值,即
表示第 ?个类别的样本均值,即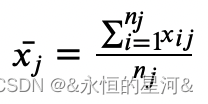 ,
,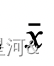 为总样本均值
为总样本均值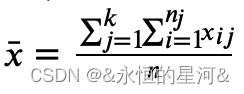 ,那么样本的总体变异为:
,那么样本的总体变异为:
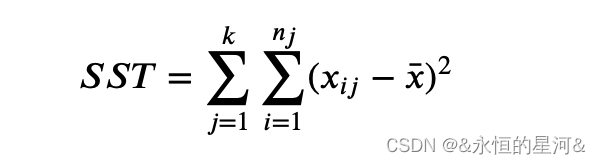
???可以分解为两部分 —— 类别内差异 ??? 和类别间差异 ???:
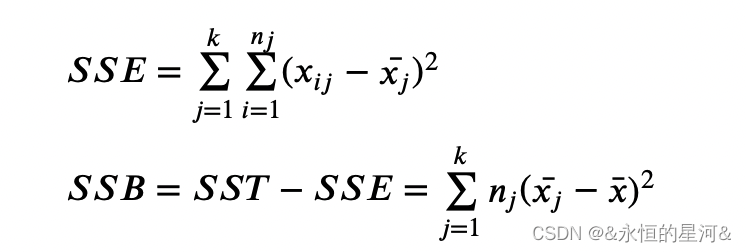
???衡量每个类别内部样本之间的差异,可以认为是随机误差。???则衡量不同类别之间的差异。方差分析的基本思想是将不同类别之间的变异与随机误差作比较,如果二者之比大于某一临界值,则可拒绝零假设接受备选假设,即不同类别间样本均值不全相等,这也意味着样本特征对于类别有一定的区分度。
而对于如何确定临界值,则终于要用到传说中的 F 分布了。本节开始定义了服从F分布的随机变量,注意到分子分母都要除以自由度,而 ???和 ???的自由度分别为 ?−1 和 ?−?,因而统计检验量 ?:
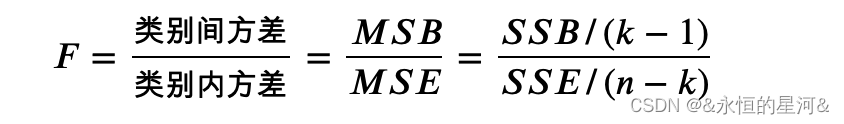
服从分子自由度为 ?−1,分母自由度为 ?−?为的 F 分布。方差分析的思想和线性判别分析 (Linear Discriminant Analysis,LDA) 非常类似 ( LDA 的思想可大致概括为 “投影后类内方差最小,类间方差最大”)。于是按假设检验的套路,零假设成立的情况下算出 F 值,查 F 分布表,若p值小于0.05 (或0.01),则拒绝零假设接受备选假设,不同类别间均值不相等。
线性相关分析
对于特征和标签皆为连续值的回归问题,要检测二者的相关性,最直接的做法就是求相关系数 ???。
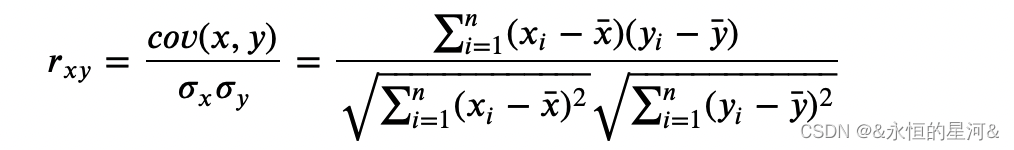
但 scikit-learn 中的 f_regression 采用的是先计算相关系数,然后转化为F值。这又是个神奇的操作,究竟是如何转换的?在线性回归中常使用判定系数 ?2作为回归方程拟合数据点的程度,或者说是因变量的总体方差能被自变量解释的比例。?2的定义以及和相关系数 ???的关系如下:
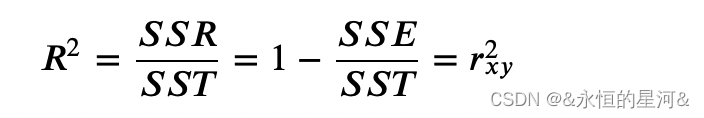
其中 ???为误差平方和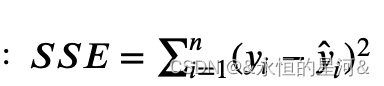 ,???为回归平方和:
,???为回归平方和: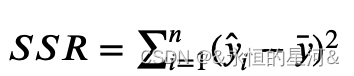 ,???为总体平方和
,???为总体平方和 ,可以看到这些式子与方差分析中的式子非常类似,不过注意这里计算的是都是标签值 ?,而不是方差分析中的 ? 。这其中的原理都是相通的,我们同样可以用 ???和 ???来计算检验统计量 ?(??? 和 ???的自由度分别为1和 n-2 ):
,可以看到这些式子与方差分析中的式子非常类似,不过注意这里计算的是都是标签值 ?,而不是方差分析中的 ? 。这其中的原理都是相通的,我们同样可以用 ???和 ???来计算检验统计量 ?(??? 和 ???的自由度分别为1和 n-2 ):
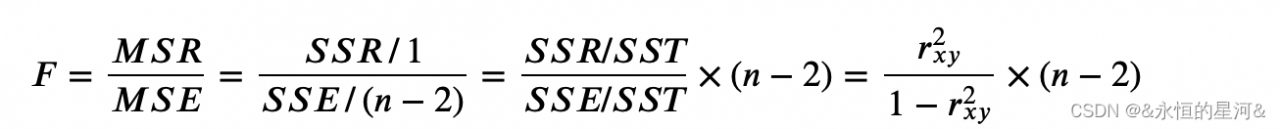
这样就可以方便地将相关系数转化为 F 值了,接下来的步骤与之前的假设检验一样。该方法的缺点是只能检测线性相关关系,但不相关不代表独立,可能是非线性相关关系。
注意:F检验对于正态分布的数据表现很好,所以再进行F检验之前可以考虑将数据归一化或标准化。
3. 互信息
F检验只能捕捉特征和标签之间的线性关系,但是如果标签与属性之间存在非线性关系是无法捕捉到的,这里就需要用到互信息法了。
互信息 (mutual information) 用于特征选择,可以从两个角度进行解释:
- 基于 KL 散度
- 基于信息增益
对于离散型随机变量 ?,?,互信息的计算公式如下:
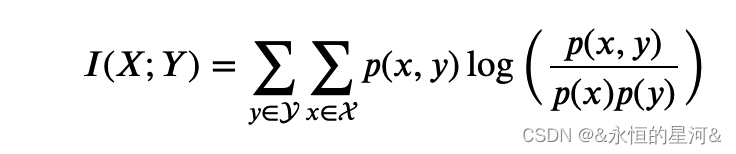
对于连续型变量:
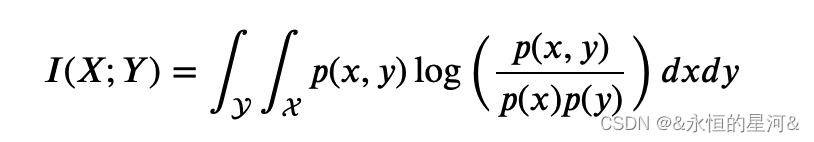
KL角度解释互信息
连续型变量互信息的需要计算积分比较麻烦,通常先要进行离散化,所以这里主要讨论离散型变量的情况。互信息可以方便地转换为 KL 散度的形式:
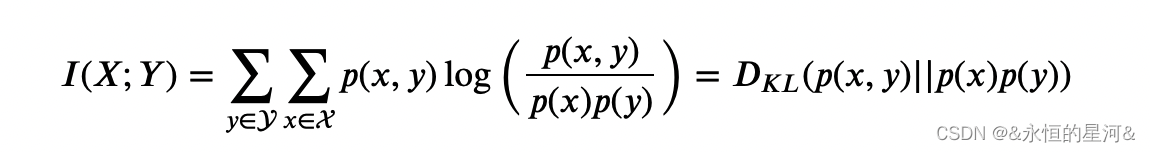
KL 散度可以用来衡量两个概率分布之间的差异,而如果 ? 和 ?是相互独立的随机变量,则 ?(?,?)=?(?)?(?),那么互信息?(?;?)的值为0。因此,若 ?(?;?)越大,则表示两个变量相关性越大,于是就可以用互信息来筛选特征。
信息增益解释互信息
互信息表示由于 ? 的引入而使 ?的不确定性减少的量。信息增益越大,意味着特征 ?包含的有助于将 ? 分类的信息越多 (即 ?的不确定性越小)。决策树就是一个典型的应用例子,其学习的主要过程就是利用信息增益来选择最优划分特征,表示由于特征 ? 而使得对数据集 ?的分类不确定性减少的程度,信息增益大的特征具有更强的分类能力。其计算公式为:
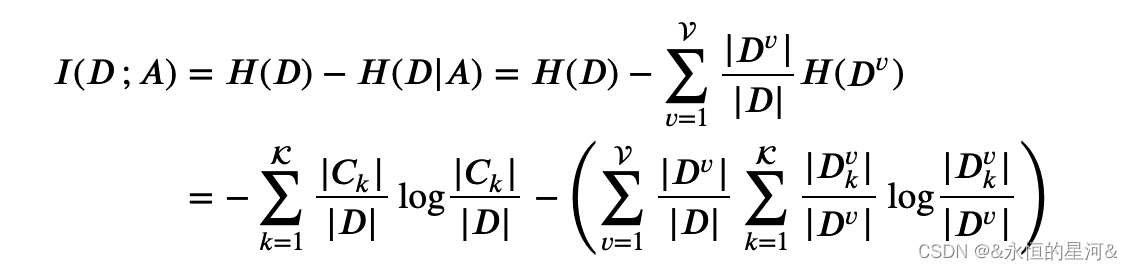
上式中,![]() 表示特征 ?有V 个可能的取值,|??|表示第 ?个取值上的样本数量。 设总共有 K 个类别,|??|表示属于第 ?类的样本数量,
表示特征 ?有V 个可能的取值,|??|表示第 ?个取值上的样本数量。 设总共有 K 个类别,|??|表示属于第 ?类的样本数量, 。 |???|表示特征 ?的取值为 ?且类别为 ?的样本数量。
。 |???|表示特征 ?的取值为 ?且类别为 ?的样本数量。
互信息和信息增益,二者是等价的。可以互相进行推导:
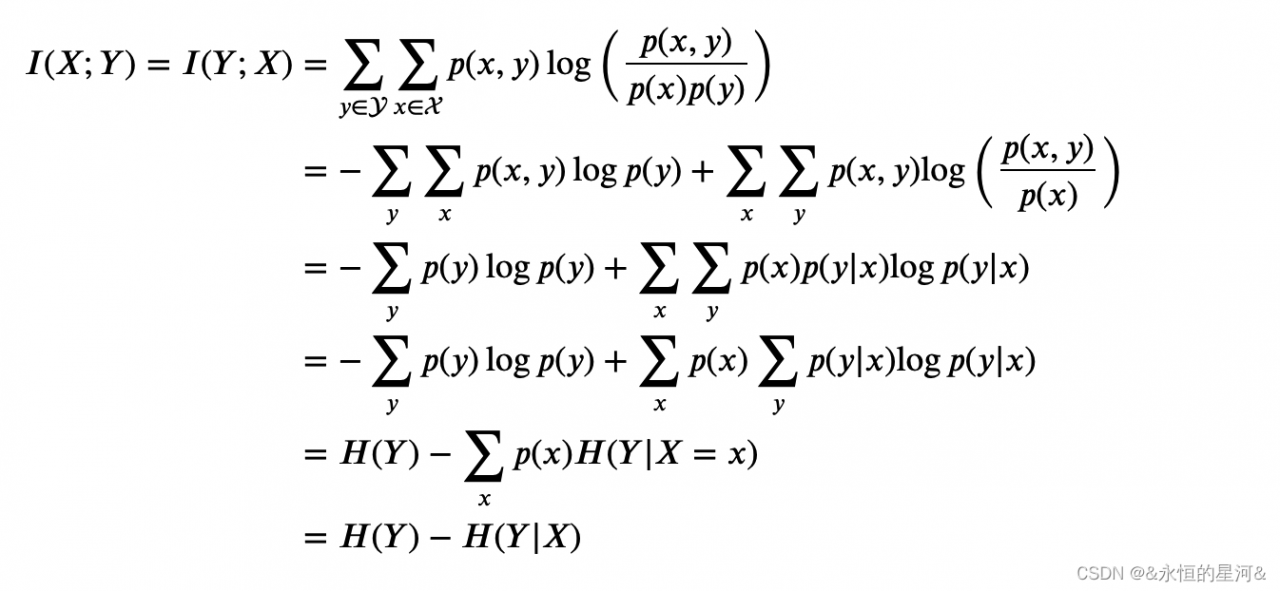
放在特征选择的语境下,我们希望 ?的不确定越小越好,这样越有助于分类,那么互信息越大,则特征 ?使得 ?的不确定性减少地也越多,即 ? 中包含的关于 ?的信息越多。因而策略还是和上文一样,计算每个特征与类别的互信息值,排序后去除互信息小的特征。
4. 皮尔逊相关系数
皮尔森相关系数是一种最简单的,能帮助理解特征和响应变量之间关系的方法,该方法衡量的是变量之间的线性相关性,结果的取值区间为[-1,1],-1表示完全的负相关(这个变量下降,那个就会上升),+1表示完全的正相关,0表示没有线性相关。通常情况下通过以下取值范围判断变量的相关强度:
- 0.8-1.0 极强相关
- 0.6-0.8 强相关
- 0.4-0.6 中等程度相关
- 0.2-0.4 弱相关
- 0.0-0.2 极弱相或无相关
Pearson相关系数原理
设(X,Y)是一个二维随机变量,且Var(X)>0,Var(Y)>0,则称
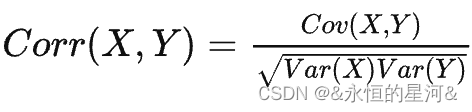
为相关系数。 Cov 为协方差。
协方差: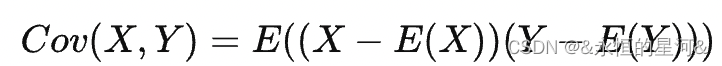
Pearson相关系数注意
假设想比较身高和体重的相关度与身高和年龄的相关度,会发现,两者的单位不一致,不太好比较。所以,为了消除量纲的影响,对协方差除以相同的量纲的量,就得到了相关系数。
Pearson相关系数缺点
Pearson相关系数的一个明显缺陷是,作为特征排序机制,他只对线性关系敏感。如果关系是非线性的,即便两个变量具有一一对应的关系,Pearson相关性也可能会接近0。
5. sklearn中相关包
方差
from sklearn.feature_selection import VarianceThreshold
卡方
from sklearn.feature_selection import chi2
F检验
from sklearn.feature_selection import f_classif
from sklearn.feature_selection import f_regression
互信息
from sklearn.feature_selection import mutual_info_classif
Pearson相关系数
from scipy.stats import pearsonr