背景知识,推荐阅读:
Guidelines for performing Mendelian randomization investigations
讲了为什么要做MR、MR的原理、工具变量的选择、MR方法、
首先工具变量需要满足三个核心条件
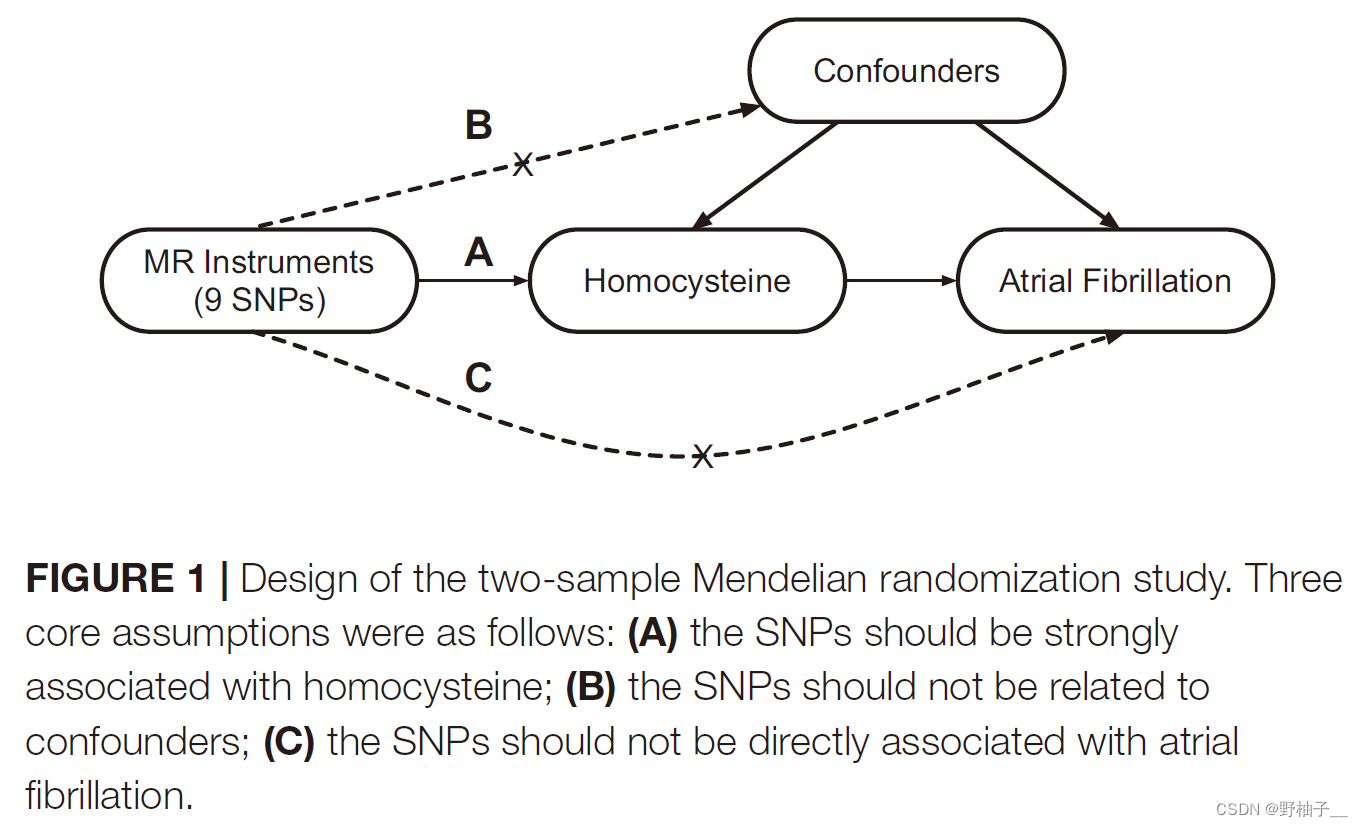
Ref:Appraising the Causal Association of Plasma Homocysteine Levels With Atrial Fibrillation Risk: A Two-Sample Mendelian Randomization Study
其中B就是horiziontal pleiotroypy,一般就是文章提到的pleiotropy多效性;即这个SNP不只和暴露相关,还和混杂相关(通往结局的通路不同);这样的SNP就是需要排除的。
还有一种就是vertiacal pleiotropy,又称indirect或mediated,就是指这个SNP和一些同样在这条通路上的其他变量相关;暴露和这些变量通往结局的通路相同,起到了中介的作用(下图a-c)。
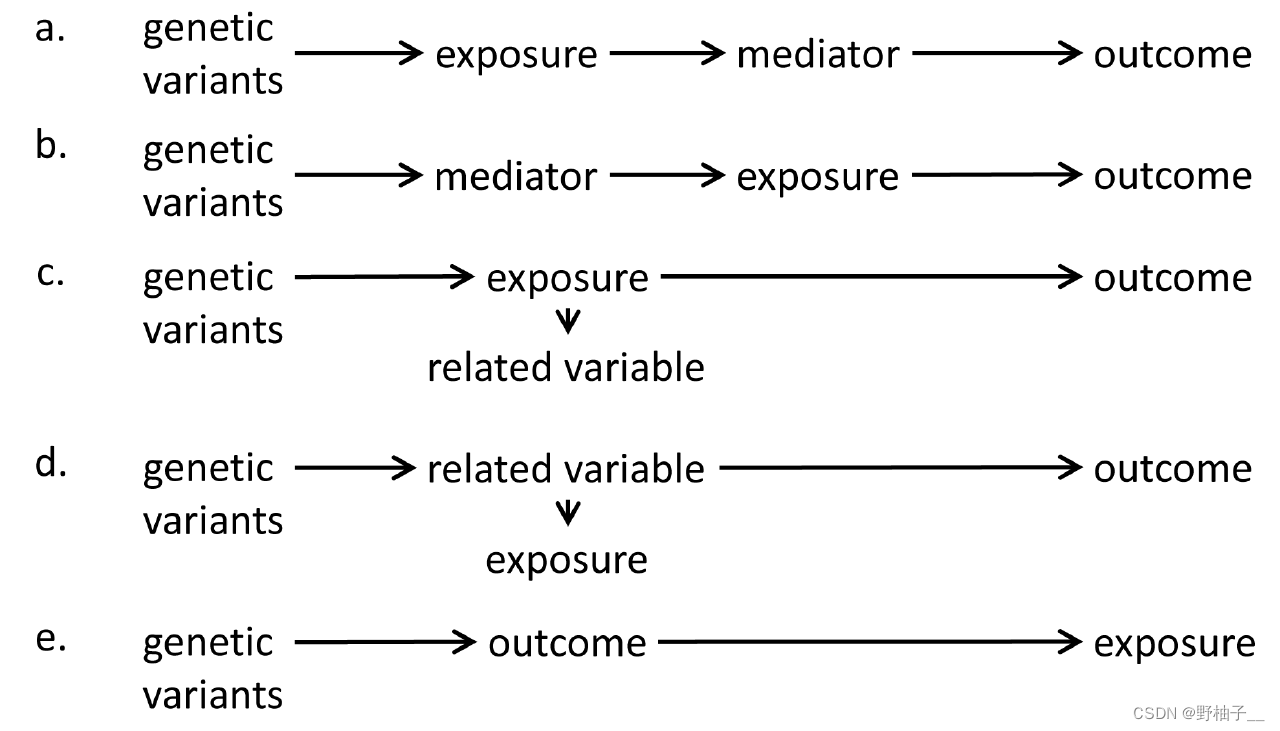

最后作者如是说…… 
一般可以通过敏感性分析来检测工具变量的多效性,如TwoSampleMR就有(可以看我另一篇教程: TwoSampleMR-R教程 两样本孟德尔随机化(原来真的就是这么简单……)
最常用的检测多效性的模型是MR-Egger、median- 或mode-based、和MR-PRESSO。
检测异质性heterogeneity的主要有Cochran’s Q statistic或 I square。
Leave-one-out 去一法,顾名思义,就是轮流去掉一个SNP,观察结果的变化。
一些更高阶的敏感性分析,比如colocalization共定位(都可以再发一篇了……)可以看一个SNP是否与多个trait相关,可以通过R包moloc或coloc实现。
基本上读完就了解了大概。在此基础上,再看几篇高分的MR文章,学他们的方法就好了。
我观察到的,基本上要么全纳入达到全基因组显著性的(尤其是one-sample MR单样本MR),要么就根据明显的多效性和弱工具变量筛。