降维,就是降低特征的维数。假如每个样本有1000维的特征,通过降维可以用100维的特征来代替原来1000维的特征。
1.降维的好处一:数据压缩
数据压缩后不仅使得数据占用较少的计算机内存或磁盘空间,也对学习算法进行了加速。
例如将数据从三维降至二维: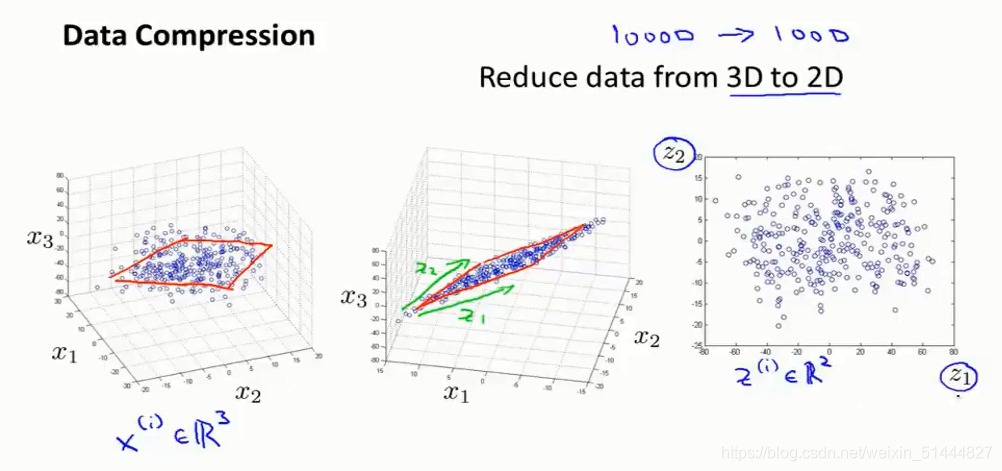
将三维向量投射到一个二维的平面上,使得所有的数据都在同一个平面上,降至二维的特征向量。
2.降维的好处二:可视化
通过降维得到更直观的视图。但问题在于降维的算法只负责减少维数,新产生的特征的意义就必须由自己去发现。
3.主成分分析(PCA)问题
最常见的降维算法是主成分分析。
PCA是寻找一个低维的空间对数据进行投影,以便最小化投影误差的平方(最小化每个点与投影后的对应点之间的距离的平方值 )
例如: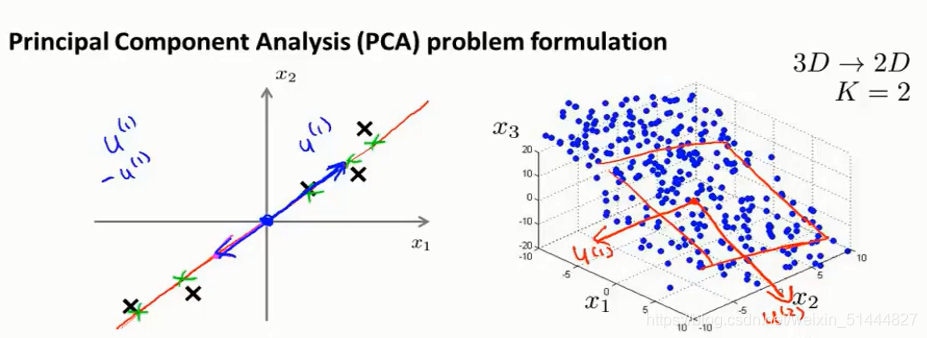
2维→1维:点到直线的垂直距离
3维→2维:点到平面的垂直距离
主成分分析与线性回归的比较:
主成分分析与线性回归是两种不同的算法。主成分分析最小化的是投影误差,而线性回归尝试的是最小化预测误差。线性回归的目的是预测结果,而主成分分析不作任何预测。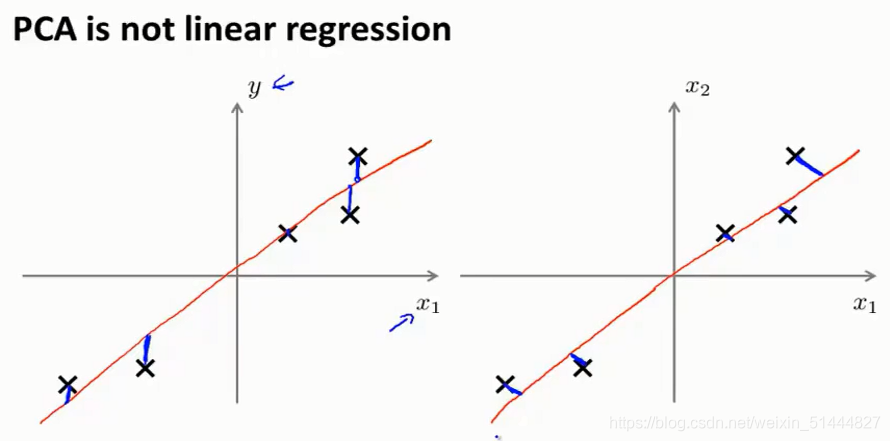
上图中,左边的是线性回归的误差(垂直于横轴投影),右边则是主要成分分析的误差(垂直于红线投影)。
4.主成分分析算法
PCA减少n维到k维:
1)均值归一化,计算出所有特征的均值u_j,然后令x_j = x_j - u_j。如果特征是在不同的数量级上,还需将其除以标准差。
2)计算协方差矩阵?(Sigma):
3)计算协方差矩阵?的特征向量:[U, S, V]= svd(sigma)

上式中的?是一个与数据之间最小投影误差的方向向量构成的矩阵。如果希望将数据从?维降至?维,只需要从?中选取前?个向量,获得一个? × ?维度的矩阵,我们用?_??????表示,然后通过如下计算获得要求的新特征向量?^(?):
其中?是? × 1维的,因此结果为? × 1维度。
5.主成分数量的选择
主成分分析是减少投影的平均均方误差:
训练集的方差为:
希望在平均均方误差与训练集方差的比例尽可能小的情况下选择尽可能小的?值。
可以先令? = 1,然后进行主成分分析,获得?_??????和?,然后计算比例是否小于1%。如果不是的话再令? = 2,如此类推,直到找到可以使得比例小于1%的最小? 值。
当在 Octave 中调用“svd”函数的时候,我们获得三个参数:[U, S, V] = svd(sigma)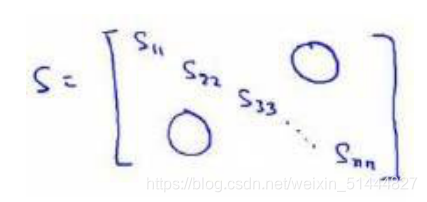
其中?是一个? × ?的矩阵,只有对角线上有值,而其它单元都是0。可以使用这个矩阵来计算平均均方误差与训练集方差的比例: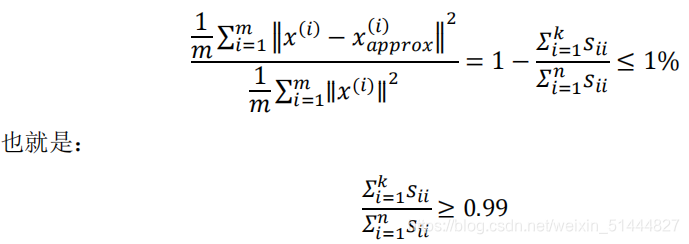
6.重建的压缩表示
PCA 作为压缩算法,可能需要通过PCA把 1000 维的数据压缩为100 维特征,或具有三维数据压缩到一或二维表示。所以怎么能回到原有的高维数据的一种近似: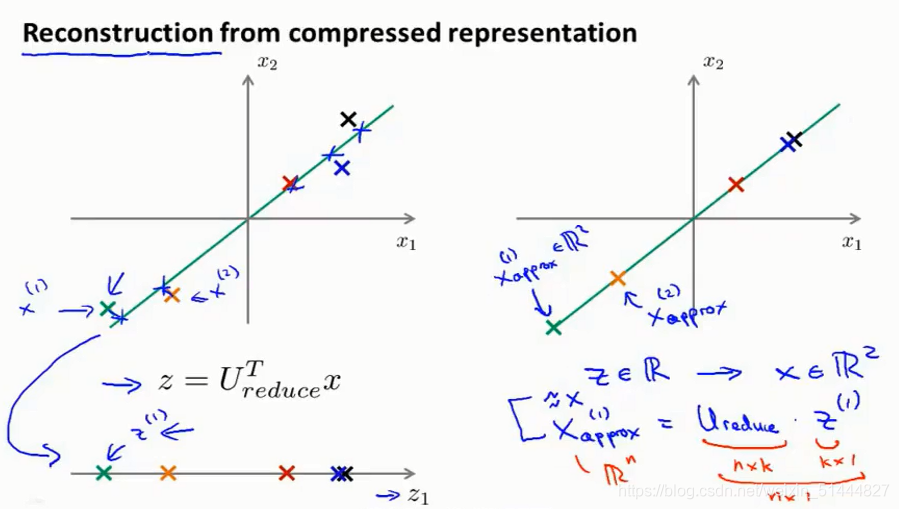
? = ?^?_?????? *?,相反的方程为:
?_????? = ?_?????? * ?,?????? ≈ ?
7.主成分分析法的应用建议
假如正在针对一张100×100像素的图片进行某个计算机视觉的机器学习,即总共有10000个特征。
对于这种高维的特征向量,运行学习算法会非常慢,可运用PCA算法减少数据的维度,使得算法运行更加高效。步骤为:
1.第一步是运用主成分分析将数据从10000个压缩至 1000 个特征
2.然后对训练集运行学习算法(如神经网络)。
3.在预测时,采用之前学习而来的?_??????将输入的特征?转换成特征向量?,然后再进行预测。
注意:PCA所做的是定义一个从x到z的映射,这个映射只能通过在训练集上运行PCA来定义。具体地说,PCA学习的这个映射所做的就是计算一系列参数,进行特征缩放和均值归一化等等;在训练集上找到所有的参数后,可以把这个映射用在交叉验证集或者测试集的其他样本中。
错误运用主成分分析的情况:
1)尝试用PCA去防止过拟合(减少特征的数量)。这样做非常不好,不如尝试正则化处理。原因在于主成分分析只是近似地丢弃掉一些特征,它并不考虑任何与结果变量有关的信息,因此可能会丢失非常重要的特征。然而当我们进行正则化处理时,会考虑到结果变量,不会丢掉重要的数据。
2)默认地将主成分分析作为学习过程中的一部分。这虽然很多时候有效果,但最好还是从所有原始特征开始,只在有必要的时候(算法运行太慢或者占用太多内存)才考虑采用主成分分析。