Intel Image Classification With Pytorch
加载库
import numpy as np
import pandas as pd
import os
import torch
import torchvision
import numpy as np
import matplotlib.pyplot as plt
import torch.nn as nn
import torch.nn.functional as F
from torchvision.transforms import ToTensor
import torchvision.transforms as tt
from torchvision.utils import make_grid
from torch.utils.data.dataloader import DataLoader
from torchvision.datasets import ImageFolder
from torch.utils.data import random_split
%matplotlib inline
训练数据准备以及定义计算每个通道均值和标准差的函数
train = ImageFolder("archive/seg_train", transform = tt.Compose([
tt.Resize(64),
tt.RandomCrop(64),
tt.ToTensor(),
]))
train_dl = DataLoader(train, 64, shuffle=True, num_workers=3, pin_memory=True)
def get_mean_std(dl):
sum_, squared_sum, batches = 0,0,0
for data, _ in dl:
sum_ += torch.mean(data, dim = ([0,2,3]))
squared_sum += torch.mean(data**2, dim = ([0,2,3]))
batches += 1
mean = sum_/batches
std = (squared_sum/batches - mean**2)**0.5
return mean,std
mean, std = get_mean_std(train_dl)
mean, std

定义图像处理组件----变形,随机剪切,随机翻转,标准化。
stats = ((0.4951, 0.4982, 0.4979), (0.2482, 0.2467, 0.2807))
train_transform = tt.Compose([
tt.Resize(64),
tt.RandomCrop(64),
tt.RandomHorizontalFlip(),
tt.ToTensor(),
tt.Normalize(*stats,inplace=True)
])
test_transform = tt.Compose([
tt.Resize(64),
tt.RandomCrop(64),
tt.ToTensor(),
tt.Normalize(*stats,inplace=True)
])
读取图像
train = ImageFolder("archive/seg_train/seg_train", transform = train_transform)
test = ImageFolder("archive/seg_test/seg_test",transform = test_transform)
random_seed = 42
torch.manual_seed(random_seed)
切分数据集
val_size = int(len(train) * 0.2)
train_size = len(train) - val_size
train_ds, val_ds = random_split(train, [train_size, val_size])
len(train_ds), len(val_ds)
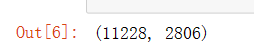
使用读取器加载图像
batch_size = 128
# PyTorch data loaders
train_dl = DataLoader(train_ds, batch_size, shuffle=True, num_workers=2, pin_memory=True)
valid_dl = DataLoader(val_ds, batch_size*2, num_workers=2, pin_memory=True)
test_dl = DataLoader(test, batch_size*2, num_workers=2, pin_memory=True)
查看图像
def denormalize(images, means, stds):
means = torch.tensor(means).reshape(1, 3, 1, 1)
stds = torch.tensor(stds).reshape(1, 3, 1, 1)
return images * stds + means
def show_batch(dl):
for images, labels in dl:
fig, ax = plt.subplots(figsize=(12, 12))
ax.set_xticks([]); ax.set_yticks([])
denorm_images = denormalize(images, *stats)
ax.imshow(make_grid(denorm_images[:64], nrow=8).permute(1, 2, 0).clamp(0,1))
break
show_batch(train_dl)

设备的使用
def get_default_device():
"""Pick GPU if available, else CPU"""
if torch.cuda.is_available():
return torch.device('cuda')
else:
return torch.device('cpu')
def to_device(data, device):
"""Move tensor(s) to chosen device"""
if isinstance(data, (list,tuple)):
return [to_device(x, device) for x in data]
return data.to(device, non_blocking=True)
class DeviceDataLoader():
"""Wrap a dataloader to move data to a device"""
def __init__(self, dl, device):
self.dl = dl
self.device = device
def __iter__(self):
"""Yield a batch of data after moving it to device"""
for b in self.dl:
yield to_device(b, self.device)
def __len__(self):
"""Number of batches"""
return len(self.dl)
定义计算准确率以及训练过程中使用的函数
def accuracy(outputs, labels):
_, preds = torch.max(outputs, dim=1)
return torch.tensor(torch.sum(preds == labels).item() / len(preds))
class ImageClassificationBase(nn.Module):
def training_step(self, batch):
images, labels = batch
out = self(images) # Generate predictions
loss = F.cross_entropy(out, labels) # Calculate loss
return loss
def validation_step(self, batch):
images, labels = batch
out = self(images) # Generate predictions
loss = F.cross_entropy(out, labels) # Calculate loss
acc = accuracy(out, labels) # Calculate accuracy
return {'val_loss': loss.detach(), 'val_acc': acc}
def validation_epoch_end(self, outputs):
batch_losses = [x['val_loss'] for x in outputs]
epoch_loss = torch.stack(batch_losses).mean() # Combine losses
batch_accs = [x['val_acc'] for x in outputs]
epoch_acc = torch.stack(batch_accs).mean() # Combine accuracies
return {'val_loss': epoch_loss.item(), 'val_acc': epoch_acc.item()}
def epoch_end(self, epoch, result):
print("Epoch [{}], last_lr: {:.5f}, train_loss: {:.4f}, val_loss: {:.4f}, val_acc: {:.4f}".format(
epoch, result['lrs'][-1], result['train_loss'], result['val_loss'], result['val_acc']))
查看设备
device = get_default_device()
device

加载数据到设备
train_dl = DeviceDataLoader(train_dl, device)
valid_dl = DeviceDataLoader(valid_dl, device)
test_dl = DeviceDataLoader(test_dl, device)
搭建resnet网络
def conv_block(in_channels, out_channels, pool=False):
layers = [nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)]
if pool: layers.append(nn.MaxPool2d(2))
return nn.Sequential(*layers)
class ResNet9(ImageClassificationBase):
def __init__(self, in_channels, num_classes):
super().__init__()
self.conv1 = conv_block(in_channels, 64)
self.conv2 = conv_block(64, 128, pool=True)
self.res1 = nn.Sequential(conv_block(128, 128), conv_block(128, 128))
self.conv3 = conv_block(128, 256, pool=True)
self.conv4 = conv_block(256, 512, pool=True)
self.res2 = nn.Sequential(conv_block(512, 512), conv_block(512, 512))
self.classifier = nn.Sequential(nn.AdaptiveMaxPool2d(1),
nn.Flatten(),
nn.Dropout(0.2),
nn.Linear(512, num_classes))
def forward(self, xb):
out = self.conv1(xb)
out = self.conv2(out)
out = self.res1(out) + out
out = self.conv3(out)
out = self.conv4(out)
out = self.res2(out) + out
out = self.classifier(out)
return out
按照该网络,输入一个12836464大小的图片,经过该网络后所得的尺寸为1286,其过程为。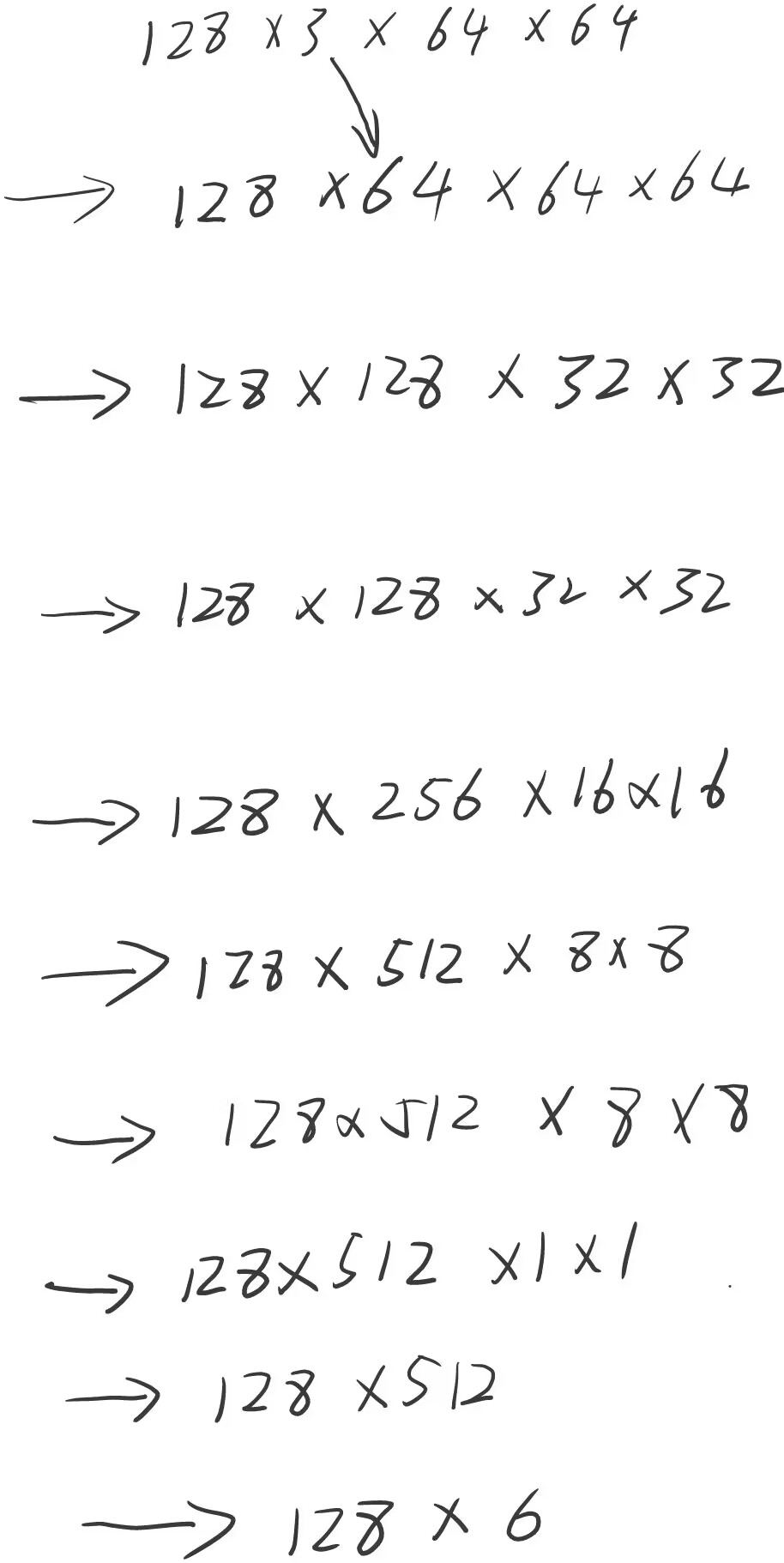
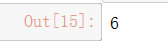
分类数
no_of_classes = len(train.classes)
no_of_classes
模型创建
model = to_device(ResNet9(3, no_of_classes), device)
model
定义训练函数
@torch.no_grad()
def evaluate(model, val_loader):
model.eval()
outputs = [model.validation_step(batch) for batch in val_loader]
return model.validation_epoch_end(outputs)
def get_lr(optimizer):
for param_group in optimizer.param_groups:
return param_group['lr']
def fit_one_cycle(epochs, max_lr, model, train_loader, val_loader,
weight_decay=0, grad_clip=None, opt_func=torch.optim.SGD):
torch.cuda.empty_cache()
history = []
# Set up cutom optimizer with weight decay
optimizer = opt_func(model.parameters(), max_lr, weight_decay=weight_decay)
# Set up one-cycle learning rate scheduler
sched = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr, epochs=epochs,
steps_per_epoch=len(train_loader))
for epoch in range(epochs):
# Training Phase
model.train()
train_losses = []
lrs = []
for batch in train_loader:
loss = model.training_step(batch)
train_losses.append(loss)
loss.backward()
# Gradient clipping
if grad_clip:
nn.utils.clip_grad_value_(model.parameters(), grad_clip)
optimizer.step()
optimizer.zero_grad()
# Record & update learning rate
lrs.append(get_lr(optimizer))
sched.step()
# Validation phase
result = evaluate(model, val_loader)
result['train_loss'] = torch.stack(train_losses).mean().item()
result['lrs'] = lrs
model.epoch_end(epoch, result)
history.append(result)
return history
初始时的损失值和准确率
history = [evaluate(model, valid_dl)]
history
一些参数
epochs = 12
max_lr = 0.01
grad_clip = 0.1
weight_decay = 1e-4
opt_func = torch.optim.Adam
训练
%%time
history += fit_one_cycle(epochs, max_lr, model, train_dl, valid_dl,
grad_clip=grad_clip,
weight_decay=weight_decay,
opt_func=opt_func)

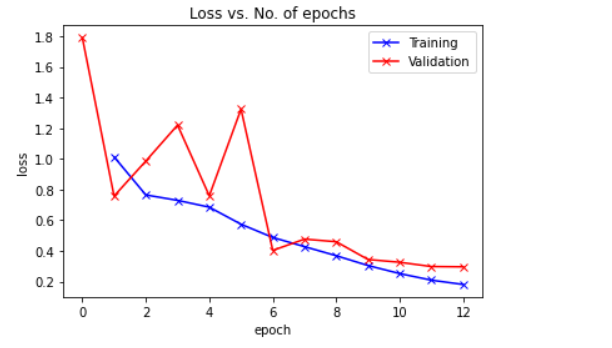
图表
def plot_losses(history):
train_losses = [x.get('train_loss') for x in history]
val_losses = [x['val_loss'] for x in history]
plt.plot(train_losses, '-bx')
plt.plot(val_losses, '-rx')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['Training', 'Validation'])
plt.title('Loss vs. No. of epochs');
plot_losses(history)
def plot_lrs(history):
lrs = np.concatenate([x.get('lrs', []) for x in history])
plt.plot(lrs)
plt.xlabel('Batch no.')
plt.ylabel('Learning rate')
plt.title('Learning Rate vs. Batch no.');
plot_lrs(history)
测试集上的损失值和准确率
test_loader = DeviceDataLoader(test_dl, device)
result = evaluate(model, test_loader)
result
参考地址:
https://www.kaggle.com/code/mihirpaghdal/intel-image-classification-with-pytorch
版权声明:本文为qq_53817374原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。