总结一下用golang 写的服务中接入kafka消息队列的记录和有用链接:
golang有两个主流的kafka lib, sarama和confluent-kafka-go, 在编译运行时均需要用到gcc。构建镜像需要加入apk add build-base- 关于consumer, consumer group, partition,replicate等关系, 在官网已有图文并茂解释。
- 搭建单
broker的测试kafka集群很方便, 下面是可用的docker-compose.yaml
version: '2'
services:
zookeeper:
image: wurstmeister/zookeeper
ports:
- "2181:2181"
kafka:
build: .
image: wurstmeister/kafka
volumes:
- /var/run/docker.sock:/var/run/docker.sock
ports:
- "9092:9092"
- "29092:29092"
environment:
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_LISTENERS: PLAINTEXT://:9092,PLAINTEXT_HOST://:29092
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092,PLAINTEXT_HOST://localhost:29092
kafka-manager:
image: sheepkiller/kafka-manager
environment:
ZK_HOSTS: zookeeper
ports:
- "9000:9000"
镜像wurstmeister/kafka在下载失败时多试几次。另外用windows主机连接以上测试kafka可能会有域名解析错误, 此时可以修改windows的host文件。
开发实施:
Publisher 信息发布模块
参考sarama的example, 操作的简单程度与将key/value键值对放到redis类似。若没有特殊要求, 以下的简单配置便能满足生产需求:
[kafka]
brokers = ["xxx.xxx.xxx.xxx:9092,"xxx.xxx.xxx.xxx:9092","xxx.xxx.xxx.xxx:9092"]
verbose = true
max_retry = 10
flush_frenquency = 500
topic = "xxxx"
publisher可分布式多实例部署和运行, kafka会处理多实例写入问题。
Consumer 消费者模块
参考sarama consumer group的example,sarama提供kafka consumer group的接口, 将example改为从配置文件读入, 关注consumer group的配置即可。
brokers =["xxx.xxx.xxx.xxx:9092,"xxx.xxx.xxx.xxx:9092","xxx.xxx.xxx.xxx:9092"]
group = "xxx"
topics = ["xxx"] # topic to be subscribed
clientID = "xxx"
verbose = true # debug info output
oldest = true # read from oldest log
注意:
example可以以多实例运行, 如一个topic有6个partition, 如以3实例的形式运行该consumer group代码段的进程, 查看管理界面的consumer group,会出现以下情况: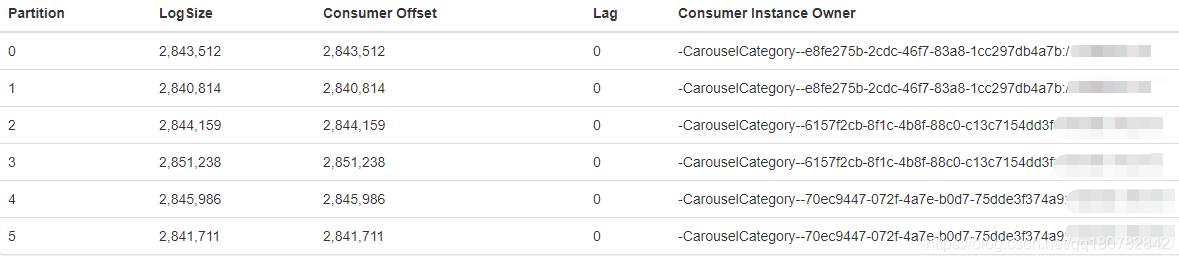
即consumer group已处理好加组,partition上的消息分配和load balancing等问题。- 队列的信息会过期被删除(
kafka集群配置,如kafkaManagedOffsetGroupExpireDays, 和topic的retention.ms), 过期后LogSize不会变, 只是当新的consumer group加入的时候,即使consumer group的配置使用的是oldest, 但是consumer
只能从被删除的后队列的最旧的offset读起。 - 若需要避免因服务本身或
consumer group重启而重复消费信息, 必须将已读信息标记为已读, 如sarama的session.MarkMessage(message, ""), 否则在oldest = true情况下, 应用实例的周期变化(重启等)会引起重复消费。 顺带一提python的lib, 用的是commit, - 通过直接查看
kafka原生个管理UI点击Consumer板块即可直接查看lag, 可通过弹性控制consumer group进程数确保及时消费。
关于kafka connect
kafka connect 可以帮助用户将既有系统的数据转换成数据流。如MySql -> kafka
- 序列化和反序列化协议使用Protobuf,降低解析开销。
- 对于
MySql(producer) -> kafka -> subscriber,subscriber可以捕捉的db的create(insert)\delete\update等事件。举例,subscriber可过滤获得insert事件,即可获得MySql db的数据增量, 实现一些离线业务的计算和统计等。
关于kafka 的使用场景
web service处理请求, 将需要分析或统计的数据以异步线程的调用producer入队, 额外的数据分析进程订阅相关topic作离线分析。 这种场景将数据分析业务与主要业务解耦, 对与离线分析进程, 也可以通过弹性控制其进程实例数,做到贴近实时统计分析效果。对分析结果存疑时, 也可通过变更consumer group的办法对数据重新消费和统计。
版权声明:本文为qq180782842原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。