
文章目录
一、STL基本知识
概述
- STL六大组件(前三个是主要的)
- 容器(Containers):使用
类模板(class template)实现的各种数据结构 - 算法(Algorithms):使用
函数模板(function template)实现的各种常用算法 - 迭代器(Iterators):使用
类模板(class template)通过重载指针操作函数实现遍历对象集合元素的泛型指针 - 仿函数(Functors):使用
重载operator()的class或class template实现函数对象(将对象像函数一样调用) - 适配器(Adaptors):使用
类模板(class template)通过修饰容器、仿函数接口或迭代器实现功能的转换 - 分配器(Allocators):使用
类模板(class template)实现内存资源的管理
- 容器(Containers):使用
- 特点
- STL模板主要由算法、容器、迭代器三者组成,将数据和算法分离。算法通过迭代器操作容器存储的数据,其中迭代器和容器一一对应。
- STL主要依赖于模板思想,提供了足够的通用性,减少了对OOP的依赖。

容器
- 分类
- 序列式容器:按位置索引,逻辑结构为线性表
- 数组容器
array<T, N> - 向量容器
vector<T> - 双端队列容器
deque<T> - 链式容器
list<T> - 正向链容器
forward_list<T>
- 数组容器
- 关联式容器:按键值索引,逻辑结构为树
- set / multiset / unordered_set / unordered_multimap
- map / multimap / unordered_map / unordered_multimap
- 容器适配器:以序列式容器为底层构造的适配器,不是容器
- 栈
stack<T> - 队列
queue<T> - 优先队列
priority_queue <T>
- 栈
- 序列式容器:按位置索引,逻辑结构为线性表
| 集合 | 底层实现 | 是否有序 | 数值重复 | 更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| set | 红黑树 | 有序 | 否 | 否 | O(log n) | O(log n) |
| multiset | 红黑树 | 无序 | 是 | 否 | O(log n) | O(log n) |
| unordered_set | 哈希表 | 无序 | 否 | 否 | O(1) | O(1) |
| unordered_multiset | 哈希表 | 无序 | 是 | 否 | O(1) | O(1) |
| map | 红黑树 | 有序 | 不可重复 | 不可修改 | O(log n) | O(log n) |
| multimap | 红黑树 | 有序 | 可重复 | 不可更改 | O(log n) | O(log n) |
| unordered_map | 哈希表 | 无序 | 不可重复 | 不可更改 | O(1) | O(1) |
| unordered_multimap | 哈希表 | 无序 | 可重复 | 不可更改 | O(1) | O(1) |
二、序列式容器详述
数组容器array
- 原理:在
普通数组的基础上,增加了一些功能函数 - 特点
- 大小固定,无法进行动态的增删
- 可以进行随机访问或更改
- 功能函数的作用示例
- at(n):返回容器中n处位置元素的引用,该函数自动检查n是否在有效的范围内,如果不是则抛出out_of_range异常
向量容器vector
- 原理
- 底层为数组,使用三个迭代器(指针)表示,start表示容器首部位置,finish表示已使用末尾位置,end_of_storage表示整个容器的末尾位置(最大容量)

- 底层为数组,使用三个迭代器(指针)表示,start表示容器首部位置,finish表示已使用末尾位置,end_of_storage表示整个容器的末尾位置(最大容量)
- vector扩容
- 扩容原理
- 寻找新内存:内存中寻找一个与前一段空间相比
两倍大小的空间作为扩充空间 - 拷贝旧数据:调用
拷贝构造函数将原数据拷贝到新内存空间的前半段 - 释放旧内存:调用
析构函数释放原内存空间
- 寻找新内存:内存中寻找一个与前一段空间相比
- 注意:一旦发生内存扩容,指向原空间的迭代器可能失效,即迭代器指针指向不变,但是内容变了,eg:erase()和insert()移动部分元素和扩容操作
- 相关函数
- push_back():未达最大容量,则直接在备用空间上建构元素,并调整迭代器finish,使vector变大。已达最大容量,则进行扩容。
- insert():未达到最大容量,则把当前要插入元素的位置后面的元素向后移动,然后把待插入元素插入到相应的位置。已达到最大容量进行扩容。

- 扩容原理
- 为什么扩容是双倍增长
- 不同的编译器,vector有不同的扩容大小。在vs下是1.5倍,在GCC下是2倍;空间和时间的权衡。简单来说, 空间分配的多,平摊时间复杂度低,但浪费空间也多。使用k=2增长因子的问题在于,每次扩展的新尺寸必然刚好大于之前分配的总和,也就是说,之前分配的内存空间不可能被使用。这样对内存不友好,最好把增长因子设为(1, 2),也就是1-2之间的某个数值。对比可以发现采用采用成倍方式扩容,可以保证常数的时间复杂度,而增加指定大小的容量只能达到O(n)的时间复杂度,因此,使用成倍的方式扩容。
- vector的swap释放
- 由于vector的内存占用空间只增不减,比如你首先分配了10,000个字节,然后erase掉后面9,999个,留下一个有效元素,但是内存占用仍为10,000个。所有内存空间是在vector析构时候才能被系统回收。empty()用来检测容器是否为空的,clear()可以清空所有元素。但是即使clear(),vector所占用的内存空间依然如故,无法保证内存的回收。
vector(Vec).swap(Vec); // 将Vec中多余内存清除;
vector().swap(Vec); //清空Vec的全部内存;
- 元素的访问
- operator[]:直接跳转位置访问元素,速度是很快的,时间复杂度为O(1)
- at():本质调用operator[],此外增加了越界检查
- 初始化
//定义具有10个整型元素的向量(尖括号为元素类型名,它可以是任何合法的数据类型),不具有初值,其值不确定 vector<int>a(10); //定义具有10个整型元素的向量,且给出的每个元素初值为1 vector<int>a(10,1); //用向量b给向量a赋值,a的值完全等价于b的值 vector<int>a(b); //将向量b中从0-2(共三个)的元素赋值给a,a的类型为int型 vector<int>a(b.begin(),b.begin()+3); //从数组中获得初值 int b[7]={1,2,3,4,5,6,7}; vector<int> a(b,b+7); - 常用内置函数
#include<vector> vector<int> a,b; //b为向量,将b的0-2个元素赋值给向量a a.assign(b.begin(),b.begin()+3); //a含有4个值为2的元素 a.assign(4,2); //返回a的最后一个元素 a.back(); //返回a的第一个元素 a.front(); //返回a的第i元素,当且仅当a存在 a[i]; //清空a中的元素 a.clear(); //判断a是否为空,空则返回true,非空则返回false a.empty(); //删除a向量的最后一个元素 a.pop_back(); //删除a中第一个(从第0个算起)到第二个元素,也就是说删除的元素从a.begin()+1算起(包括它)一直到a.begin()+3(不包括它)结束 a.erase(a.begin()+1,a.begin()+3); //在a的最后一个向量后插入一个元素,其值为5 a.push_back(5); //在a的第一个元素(从第0个算起)位置插入数值5, a.insert(a.begin()+1,5); //在a的第一个元素(从第0个算起)位置插入3个数,其值都为5 a.insert(a.begin()+1,3,5); //b为数组,在a的第一个元素(从第0个元素算起)的位置插入b的第三个元素到第5个元素(不包括b+6) a.insert(a.begin()+1,b+3,b+6); //返回a中元素的个数 a.size(); //返回a在内存中总共可以容纳的元素个数 a.capacity(); //将a的现有元素个数调整至10个,多则删,少则补,其值随机 a.resize(10); //将a的现有元素个数调整至10个,多则删,少则补,其值为2 a.resize(10,2); //将a的容量扩充至100, a.reserve(100); //b为向量,将a中的元素和b中的元素整体交换 a.swap(b); //b为向量,向量的比较操作还有 != >= > <= < a==b;
双端队列容器deque
- 原理:由一个
中控器和多个缓冲区组成,中控器中的每个节点指向一片连续的缓冲区,在逻辑上形成连续的双端队列// deque的迭代器数据结构 _Elt_pointer _M_cur; //用于保存迭代器当前位置 _Elt_pointer _M_first; //保存迭代器当前所属buffer的开始位置 _Elt_pointer _M_last;//保存迭代器当前所属buffer的结束位置 _Map_pointer _M_node; //用于保存迭代器当前所属的节点位置
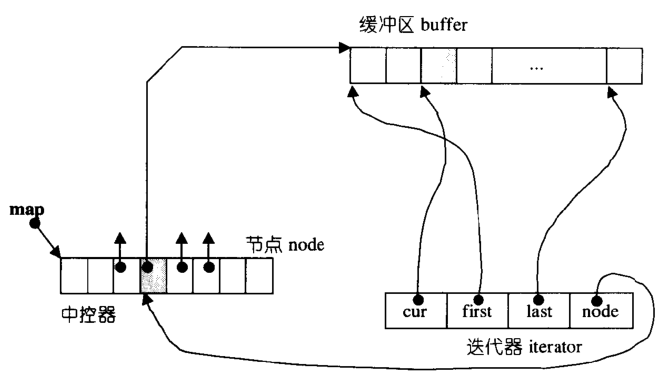
- 特点
双端进行插入和删除,时间复杂度为O(1),特别是头部插入比vector快。- 支持
随机访问O(1),但顺序访问比vector慢,这是由deque数据结构决定的 - 中控器节点数量 = max(元素数量/512 + 2, 8),512是默认的每个buffer大小。
- 头端插入
push_front()(尾部插入与该原理类似)- 头部buffer空间足够时,直接从后往前插入
- 头部buffer不足时
- 当中控器节点足够时,则申请一个头部buffer
- 当中控器节点不足时,重新申请一整块中控器节点内存,并将buffer地址进行浅拷贝
- 中间插入
insert()- 检测插入位置
- 若在前半部分则从后向前移动1位
- 若在后半部分则从前向后移动1位
- 移动前,现在头部或尾部进行一次尝试插入,如果buffer不足则进行扩容,足够则插入。
- 检测插入位置
链式容器list
- 原理:底层数据结构为一个
双向循环链表(SGI STL版本,有些只是用双向链表实现),相比双向链表只需要一个指针即可表示首尾元素(另一个通过指针的自增或自减获得)template<typename T,...> // 头节点 class list { //... //指向链表的头节点,并不存放数据 __list_node<T>* node; //...以下还有list 容器的构造函数以及很多操作函数 } //链表节点数据结构 struct __List_node{ //... __list_node<T>* prev;// prev 指针用于指向前一个节点 __list_node<T>* next;// next 指针用于指向后一个节点 T myval;// myval 用于存储当前元素的值 //... }
- 特点
- 链表中的迭代器只能进行前移和后移操作,通过重载运算符实现的
- 插入删除比较方便,而且不会造成迭代器失效
- STL中list和vector是两个最长被用的容器
- 基本操作
size();//返回容器中元素的个数。
empty();//判断容器是否为空。
//重新指定容器的长度为num,若容器变长,则以默认值填充新位置。
//如果容器变短,则末尾超出容器长度的元素被删除
resize(num);
//重新指定容器的长度为num,若容器变成,则以elem值填充新位置。
//如果容器变短,则末尾超出容器长度的元素被删除。
resize(num,elem);
push_back(elem); //在容器尾部加入一个元素
pop_back(); //删除容器中最后一个元素
push_front(elem); //在容器开头插入一个元素
pop_front(); //从哪个容器开头移除第一个元素
insert(pos,elem); //在pos位置插elem元素的拷贝,返回新数据的位置
insert(pos,n,elem); //在pos位置插入n个elem数据,无返回值。
insert(pos,beg,end); //在pos位置插入[beg,end)区间的数据,无返回值
clear(); //移除容器的所有数据
erase(beg,end); //删除[beg,end)区间的数据,返回下一个数据的位置
erase(pos); //删除pos位置的数据,返回下一个数据的位置
remove(elem); //删除容器中所有与elem值匹配的元素。
- 基本操作
vector<vector<int>> vec = {[1,2], [3,4]}; list<vector<int>> seq(vec.begin(), vec.end());// 使用vector初始化链表 for(auto itr = seq.begin(); itr != seq.end();++itr){// 循环遍历 vector<int> &itrv = *itr;// 访问迭代器指向的链表数据域 cout << itr[0]; seq.erase(next(itr, 1));// 迭代器指向的下一个链表元素 seq.erase(prev(itr, 3));// 删除迭代器指向的向前第三个元素 }
正向链容器forward_list
原理:底层数据结构为
单链表,只能使用正向迭代器进行顺序遍历。特点
- 因为只能通过自增前面元素的迭代器来到达序列的终点,所以back()、push_back()、pop_back()、emplace_back()也无法使用
- forward_list 的操作比 list 容器还要快,而且占用的内存更少

二、关联式容器详述
红黑树RB-Tree
- 定义
- 红黑树是一种自平衡的二叉查找树,左小右大。
- 左右子树高度差可能大于1(与平衡二叉树的差别)
- 每个节点具有红黑的颜色性质
- 每个结点的颜色必定是红色或黑色
- 根节点是黑色的
- 所有叶子节点都是黑色的NULL结点(除叶子节点每个节点都是具有两个孩子)
- 每个红色结点的两个子结点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色结点)
- 从任一结点到其每个叶子的所有路径都包含相同数目的黑色结点
- 结论
- 原理:颜色性质约束了红黑树的大致平衡,即
从根到叶子的最长的可能路径不多于最短的可能路径的两倍长,在最坏的情况下也能保证O ( l o g 2 N ) O(log_2N)O(log2N)的时间复杂度 - 证明:最短的可能路径都是黑色结点,最长的可能路径有交替的红色和黑色结点。因为根据所有最长的路径都有相同数目的黑色结点,这就表明了没有路径能多于任何其他路径的两倍长。
- 原理:颜色性质约束了红黑树的大致平衡,即
- 特点
- 操作比如插入、删除和查找某个值的最坏情况时间都要求与树的高度成比例,这个在高度上的理论上限允许红黑树在最坏情况下都是高效的,而不同于普通的二叉查找树
- 红黑树不会像二分搜索树一样退化为链表。
- 红黑树能够以O(log2 n)的时间复杂度进行搜索、插入、删除操作。此外,由于它的设计,任何不平衡都会在三次旋转之内解决
- 红黑树的旋转
- 原因:插入和删除操作可能导致无法维持红黑树的性质
- 基本旋转
- 左旋:左右左,也就是左旋是把该节点作为其右孩子的左孩子
- 右旋:右左右,也就是右旋就是把该节点作为其左孩子的右孩子
- 一般默认插入的节点为红色,只有出现连续的红色操作才会引发自平衡操作,如果出现
- 将插入节点的父节点变为黑色,持续向根节点进行变红的试探,如果不满足,再进行旋转操作

- 红黑树RBT和平衡二叉树ALV的比较
- 结构对比: RBT牺牲了高度平衡特性,换取插入和删除的引起不平衡后旋转操作的减少。
- 查找对比: AVL 查找时间复杂度最好,最坏情况都是O(logN),RBT在最坏情况实际略差。
- 插入删除对比: 插入和删除结点很容易造成树结构的不平衡,而RBT的平衡度要求较低。
- 当插入节点引起树的不平衡时,当插入一个结点都引起了树的不平衡,AVL和RBT都最多需要2次旋转操作。但在大量数据插入的情况下,RBT需要通过旋转变色操作来重新达到平衡的频度要小于AVL。
- 当删除节点引起树的不平衡时,AVL最多需要logN 次旋转操作,而RBT最多只需要3次。
- 应用
- 着名的Linux的的进程调度完全公平调度程序,用红黑树管理进程控制块,进程的虚拟内存区域都存储在一颗红黑树上,每个虚拟地址区域都对应红黑树的一个节点,左指针指向相邻的地址虚拟存储区域,右指针指向相邻的高地址虚拟地址空间。
- IO多路复用的epoll的的的实现采用红黑树组织管理的的的sockfd,以支持快速的增删改查。
- Nginx的的的中用红黑树管理定时器,因为红黑树是有序的,可以很快的得到距离当前最小的定时器。
哈希表
- 原理
- 在
关键字和存储地址间使用散列函数建立直接映射关系,使查找元素的时间复杂度为O(1)
- 在
- 常用散列函数
- 直接定址法:简单算数运算进行映射,简单不会产生冲突,只适合关键字分布基本连续的情况,空位较多会造成存储空间的浪费
- 除留余数法:选取小于等于元素个数的最大质数,进行取余运算。冲突主要取决于选取的余数
- 数字分析法:选取数码分布较为均匀的其中几位作为散列地址(手机号)
- 平方取中法:取关键字平方值的中间几位作为散列地址
- 哈希冲突的处理
- 开放定址法:存放新表项的空闲地址既向它的同义词表项开放,又向它的非同词表项开放
- 线性探测法:冲突发生时,顺序查看下一个表中的单元直到找到一个空闲单元。但是可能造成相邻散列地址的堆积,导致查找效率下降
- 平方探测法:每次查找的步数呈指数增长,不能探测所有单元,但是可以探测一半
- 再散列法:使用两个散列函数,当通过第一个散列函数得到的地址发生冲突时,再利用第二个散列函数
- 伪随机序列法:出现碰撞时使用生成的伪随机序列作为增量
- 缺点:开放定址法不能随便删除元素,可以给要删除的元素做一个标记,进行逻辑删除,防止中断查找路径
- 拉链法:顺序数组作为散列后的地址,数组中的每个数据元素指向发生冲突的同义词链表
- 开放定址法:存放新表项的空闲地址既向它的同义词表项开放,又向它的非同词表项开放
map
- map插入数据的方式
// 用insert函数插入pair数据 mapStudent.insert(pair<int, string>(1, "student_one")); // 用insert函数插入value_type数据 mapStudent.insert(map<int, string>::value_type (1, "student_one")); // 在insert函数中使用make_pair()函数 mapStudent.insert(make_pair(1, "student_one")); // 用数组方式插入数据 mapStudent[1] = "student_one"; - map中[]与find的区别
- map的下标运算符[]:以key为下标进行查找,并返回对应的值;如果不存在这个key,就将一个
具有该关键码和值类型的默认值的项插入这个map,其中int的默认值为0。 - map的find函数:用关键码执行查找,找到了返回该位置的迭代器;如果不存在这个key,就返回尾迭代器
- map的下标运算符[]:以key为下标进行查找,并返回对应的值;如果不存在这个key,就将一个
三、容器适配器详述
栈stack
- 定义:STL中的栈是以某种容器(默认为deque容器)为底层结构的适配器
- 常用成员函数:
st.top();//返回栈顶元素 st.push(5);//在栈顶插入新元素 5 st.emplace(5);//在栈顶创建新元素 5 st.pop();//删除栈顶元素 st.size();//返回容器目前的元素个数 st.empty();//容器为空返回 true, 否则返回 false st.swap(st1);//交换两个容器的内容
队列queue
- 定义:STL中的队列是以某种容器(默认为deque容器)为底层结构的适配器
- 常用成员函数:
// 构造函数 queue<T> que; // 队列对象的默认构造形式 queue(const queue &que); // 拷贝构造函数 // 赋值操作 queue& operator=(const queue &que); // 数据存取 push(elem); // 向队尾添加元素 pop(); // 从队头移除第一个元素 back(); // 返回最后一个元素 front(); // 返回第一个元素 // 大小操作dv empty(); // 判断堆栈是否为空 size(); // 返回栈的大小
优先队列priority_queue
原理: 优先级队列默认使用vector 作为其底层容器,并使用堆算法构造成大根堆(完全二叉树)。
特点:在优先队列中,元素被赋予优先级。当访问元素时,具有最高优先级的元素最先删除。优先队列具有最高级先出 (first in, largest out)的行为特征
template <class T, class Squence = vector<T>,
class Compare = less<typename Sequence::value_tyoe> >
class priority_queue{
...
protected:
Sequence c; // 底层容器
Compare comp; // 元素大小比较标准
public:
bool empty() const {return c.empty();}
size_type size() const {return c.size();}
const_reference top() const {return c.front()}
void push(const value_type& x)
{
c.push_heap(x);
push_heap(c.begin(), c.end(),comp);
}
void pop()
{
pop_heap(c.begin(), c.end(),comp);
c.pop_back();
}
};
四、迭代器
- 常见容器对应的迭代器
| 容器 | 迭代器 |
|---|---|
| vector、deque | 随机访问迭代器 |
| stack、queue、priority_queue | 无 |
| list、(multi)set/map | 双向迭代器 |
| unordered_(multi)set/map、forward_list | 前向迭代器 |
- 迭代器:++obj、obj++哪个好
- 前置不会产生临时对象,后置会临时对象,而临时对象的构造会产生较大开销
五、萃取器
- 定义:C++萃取器是一种模板技巧,用于获取
迭代器所指向元素的类型 - SFINAE机制(Substitution failure is not an error ,置换失败不是一个错误):
有且唯一时,我们希望编译器可以挑出那个唯一的来,即更加匹配的。- eg:对于重载的函数签名的匹配失败不是一个错误,可以继续匹配直到成功
- 作用:保证编译器在泛型函数、偏特化、及一般重载函数中遴选函数原型的候选列表时不被打断。除此之外,它还有一个很重要的元编程作用就是实现部分的编译期自省和反射。
- 使用
#include<type_traits>
六、分配器
- STL的空间分配器使用二级空间配置器
- 缺点
- 因为自由链表的管理问题,它会把我们需求的内存块自动提升为8的倍数,这时若你需要1个字节,它会给你8个字节,即浪费了7个字节,所以它又引入了内部碎片的问题,若相似情况出现很多次,就会造成很多内部碎片;
- 二级空间配置器是在堆上申请大块的狭义内存池,然后用自由链表管理,供现在使用,在程序执行过程中,它将申请的内存一块一块都挂在自由链表上,即不会还给操作系统,并且它的实现中所有成员全是静态的,所以它申请的所有内存只有在进程结束才会释放内存,还给操作系统,由此带来的问题有:1.即我不断的开辟小块内存,最后整个堆上的空间都被挂在自由链表上,若我想开辟大块内存就会失败;2.若自由链表上挂很多内存块没有被使用,当前进程又占着内存不释放,这时别的进程在堆上申请不到空间,也不可以使用当前进程的空闲内存,由此就会引发多种问题。

参考博客
版权声明:本文为qq_43840665原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。