计算操作的数量和操作数的数量估计性能和能耗
Conv2D 函数
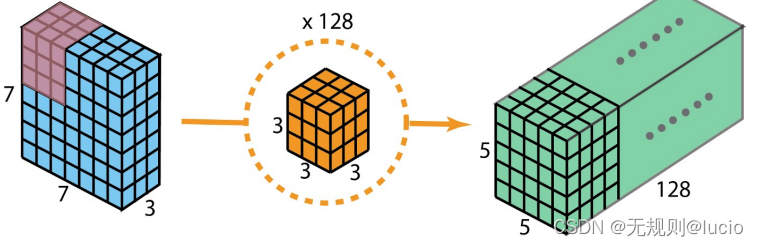
权重数:对于每一个(输入和输出)通道对,有一个3*3内核:
3 x 3 x 3 x 128 = 3456 weights
偏移:每个输入通道,有一个偏差,共有:
128偏差
公式解读
(K,K) 内核,F 滤波器,S 步长(stride),P 填充(padding)
输入为:批量bi,高hi,宽wi,通道ci
输出为:
» Bo = Bi
» Co = F
» Ho = (Hi + 2 x P - K) / S + 1
» Wo = (Wi + 2 x P - K) / S + 1
权重和偏移量:
w = Ci x K x K x Co
b = Co
SeparableConv2D
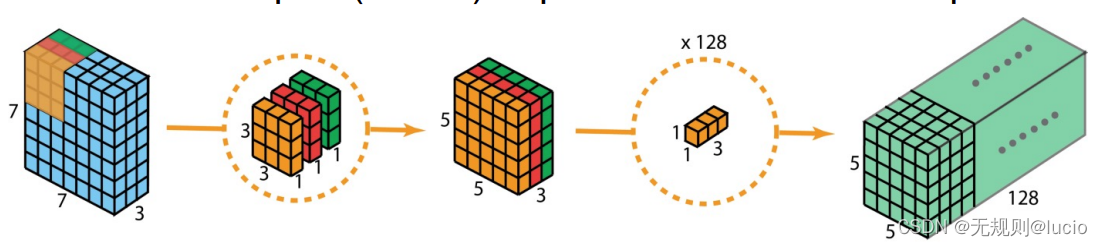
对于depthwise(深度)
权重数:3 x 3 x 3 = 27 weights;
偏移数: 0 (bias not used)
对于pointwise(点式)
权重数:3 x 1 x 1 x 128 = 384 weights
偏移数:128 biases
共有411/128 weights/biases
所以有:
(3456+128)/(411+128) = 6.6x fewer #params
公式解读
与Conv2D有同样的输入输出,但权重和偏移量为:
w = Ci x ( K x K + Co )
b = Co
权重比率(weight ratio):Co/(1+ (Co/K∙K))
Dense
输入:bi,xi 批量和输入数组尺寸
输出:bo,yo 批量和输出数组尺寸大小
权重数:w = Xi x Yo
偏移量:b = Yo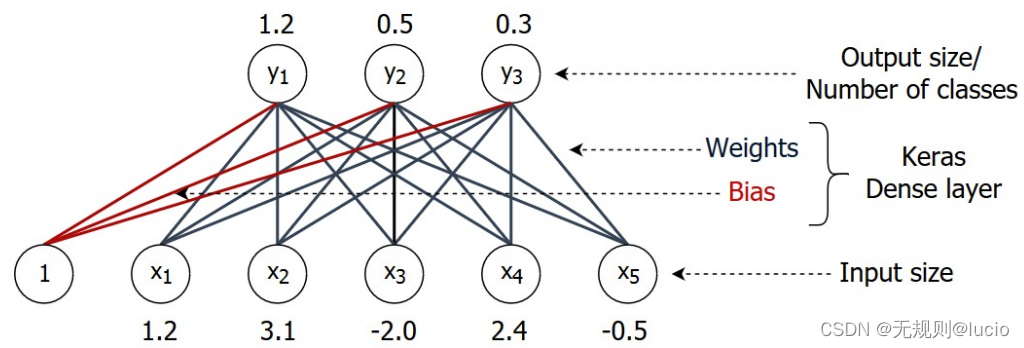
MaxPooling2D
和Conv2D和SeparableConv2D的输出张量尺寸相同。无可训练参数权重和偏移量
AveragePooling2D
和AveragePooling2D一样。
Batch Normalization
输入:bi,hi,wi,ci。批量,高度,宽度,通道
输出:(Bo,Ho,Wo,Co) = (Bi,Hi,Wi,Ci)
gamma和beta参数可训练:
pt = 2 x Ci = 2 x Co
其他参数,mean和variance不能训练:
p = 4 x Ci = 4 x Co
激活数(#activs)
正常激活数的参数:
- 当激活停留在片上缓冲区,参数存储在外部DRAM中。
- 我们需要在片上给参数留出空间,这样可以在需要它的时候从DRAM中提取参数。
我们需要根据实际数据类型计算出实际的存储需求(memory requirement),为参数和激活函数。
操作的数量(#OPs)
卷积层(convolutional)和全连接层(Full-connected layer)主导操作数量。
MULs和ADDs决定计算的要求(computing requirement)。
Conv2D层的操作数量
输出张量的每个Co x Ho x Wo元件:
MULs: K x K x Ci
ADDs: K x K x Ci
一共2 x Co x Ho x Wo x K x K x Ci个操作
SeparableConv2D层的操作数量
MULs: K x K
ADDs: K x K-1 (no bias addition)
对于Depthwise:
一共有2 x Ci x Ho x Wo x K x K个操作
对于Pointwise:一共2 x Co x Ho x Wo x 1 x 1 x Ci个操作
总共有2 x Ho x Wo x (K x K + Co) x Ci个操作
Dense层的操作数量
MULS: Xi
ADDs: Xi
一共2 x Yo x Xi 个操作
Shallownet Sequential
// 浅谈顺序性
def shallownet_sequential(width, height, depth, classes):
# initialize the model along with the input shape to be
# "channels last" ordering
model = Sequential()
i_s = (height, width, depth)
# define the first (and only) CONV => RELU layer
model.add(Conv2D(32, (3, 3), padding="same", input_shape=i_s))
model.add(Activation("relu"))
# softmax classifier
model.add(Flatten())
model.add(Dense(classes))
model.add(Activation("softmax"))
# return the constructed network architecture
return model
这里我们可以计算出Conv2D的浮点操作的数量为:
#FLOPs = 2 x Co x Ho x Wo x K x K x Ci= 2 x 32 x 32 x 32 x 3 x 3 x 3 = 1,769,472
这里我们可以计算出Dense的浮点操作的数量为:
#FLOPs = 2 x Yo x Xi= 2 x 10 x 32768 = 655,360
全部的浮点操作的数量为:
#FLOPs = 2,424,832 ~ 2.4M
检查

对于conv2d:
w = Ci x K x K x Co = 3 x 3 x 3 x 32 = 864
b = Co = 32
#params = 864 + 32 = 896
对于dense:
w = Xi x Yo = 32768 x 10 = 327680
b = Yo = 10
#params = 327690
FP32(四个字节):(328586 x4)/2^20 = 1.25 MB
INT8(一个字节): (328586 x1)/2^10 = 320 kB
总结:
#FLOPs: 2424832 = 2.3 MOP
需要多大的存储器?
对内存的快速访问意味着更好的推理吞吐量。
半导体存储器要么速度快,要么密度大,但不能兼具。
需要压缩参数尺寸,可以用小数量类型。
需要多大能量?
每次内存访问会消耗大量能量,所以我们越少访问DRAM,性能越好。
最好的情况就是我们读取一次参数(这里要有足够的片上缓存区可以方便临时存储)
对于FP32:
Edram(FP32) = 1.25MB / 4B x 640pJ = 0.2 mJ
对于INT8:
Edram(INT8) = 320 kB / 4B x 640pJ = 0.05 mJ (4x less)
而对于操作来说,一半MULs,一半是ADDs最好:
Eops(FP32) = 2.4 M x 0.5 x (3.7 + 0.9) pJ = 0.0055 mJ
Eops(INT8) = 2.4 M x 0.5 x (0.2 + 0.03) pJ = 0.00028 mJ (20x less)
激活函数所使用的内存
激活张量的大小会影响性能
而与参数不同,激活函数产生后几乎立即被消耗
激活函数应该存储在一个局部存储器去减少数据连接时间并且减少能量。
为了评估内存需求,我们需要评估中间层的尺寸中的最大值。
屋顶线模型(Roofline model)
Conv2D
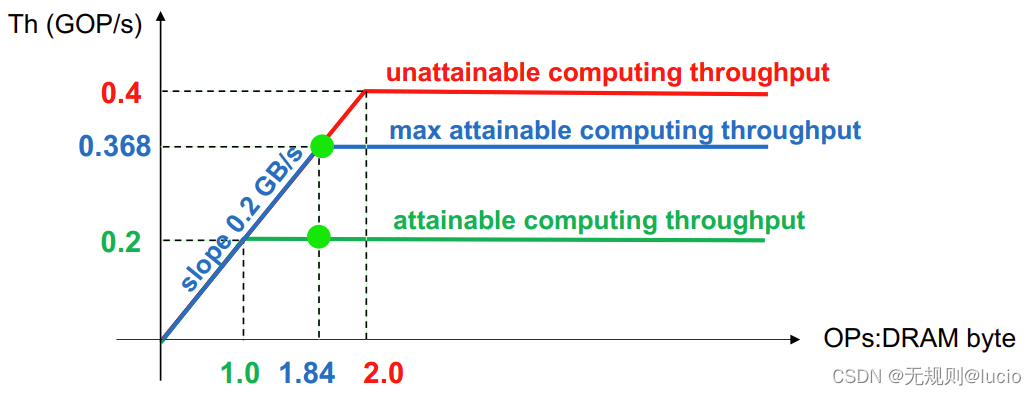
DDR bus @100MHz, 8 bits, Fck=100 MHz, 2 MAC:
此时峰值带宽为: 2x100M = 0.2 GB/s
无法实现的计算吞吐量为:0.4 GOP/s (2 MACs = 4 OPs)
实际的计算吞吐量为:TH = 0.368 GOP/s
延时为: #FLOPs/TH = 1000 x 2.3M / 368M = 6.25 ms(由上面得知 #FLOPs: 2,424,832 = 2.3 MOP)
最大激活数: 32768 = 128 kB, if FP32
帧率(frame rate):= 1000 / 6.25 = 160 fps
SeparableConv2D
若将Conv2D换成SeparableConv2D,将会发生什么?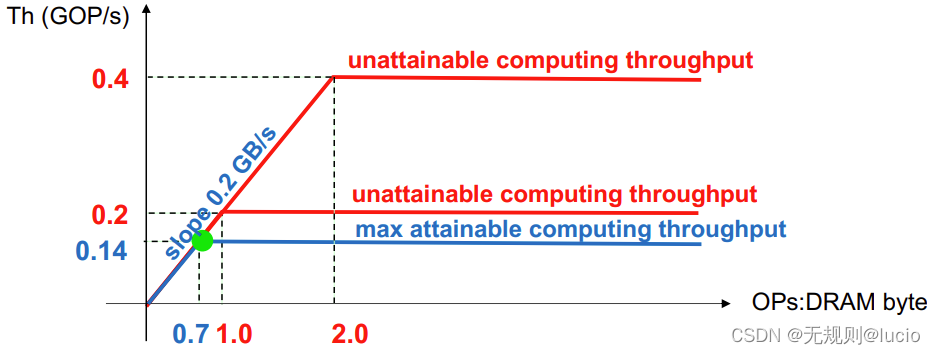
#PARAMS: 327845 = 1.25 MB
#FLOPs: 907264 =0.865 MOP
0.7 OP/BYTE
实际的吞吐量为:TH = 0.14 GOP/s
延时为: #OPs/TH = 1000 x 0.865M / 140M = 6.18 ms
Frame rate(帧率):1000 / 6.18 = 162 fps
minigooglenet(LeNet)
框架
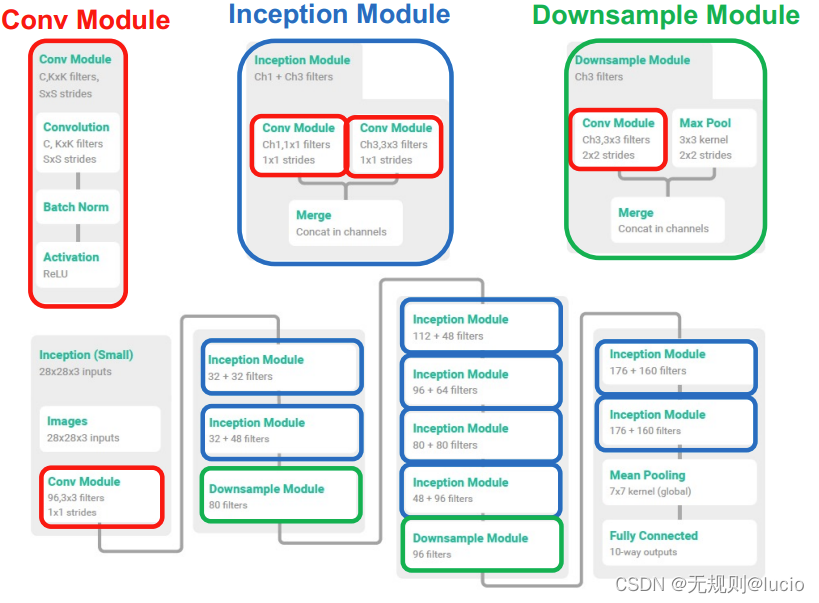
代码如下:
def minigooglenet_functional(width, height, depth, classes):
. . . #previously defined functions
# initialize the input shape to be "channels last"
inputShape = (height, width, depth)
chanDim = -1
# define the model input and first CONV module
inputs = Input(shape=inputShape)
x = conv_module(inputs, 96, 3, 3, (1, 1), chanDim)
# two Inception modules followed by a downsample module
x = inception_module(x, 32, 32, chanDim)
x = inception_module(x, 32, 48, chanDim)
x = downsample_module(x, 80, chanDim)
# four Inception modules followed by a downsample module
x = inception_module(x, 112, 48, chanDim)
x = inception_module(x, 96, 64, chanDim)
x = inception_module(x, 80, 80, chanDim)
x = inception_module(x, 48, 96, chanDim)
x = downsample_module(x, 96, chanDim)
# two Inception modules followed by global POOL and dropout
x = inception_module(x, 176, 160, chanDim)
x = inception_module(x, 176, 160, chanDim)
x = AveragePooling2D((7, 7))(x)
x = Dropout(0.5)(x)
# softmax classifier
x = Flatten()(x)
x = Dense(classes)(x)
x = Activation("softmax")(x)
# create the model
model = Model(inputs, x, name="minigooglenet")
return model
这里MiNiGoogLeNet仅仅作为一个Keras函数API模型
Conv Modules
def minigooglenet_functional(width, height, depth, classes):
def conv_module(x, K, kX, kY, stride, chanDim, padding="same"):
# define a CONV => BN => RELU pattern
x = Conv2D(K, (kX, kY), strides=stride, padding=padding)(x)
x = BatchNormalization(axis=chanDim)(x)
x = Activation("relu")(x)
# return the block
return x
Inception Modules
def inception_module(x, numK1x1, numK3x3, chanDim):
#define two CONV modules, then concatenate across the
#channel dimension
conv_1x1 = conv_module(x, numK1x1, 1, 1, (1, 1), chanDim)
conv_3x3 = conv_module(x, numK3x3, 3, 3, (1, 1), chanDim)
x = concatenate([conv_1x1, conv_3x3], axis=chanDim)
#return the block
return x
Downsample Module
def downsample_module(x, K, chanDim):
#define the CONV module and POOL, then concatenate
#across the channel dimensions
conv_3x3=conv_module(x,K,3,3,(2,2),chanDim,padding="valid")
pool=MaxPooling2D((3, 3), strides=(2, 2))(x)
x=concatenate([conv_3x3, pool], axis=chanDim)
#return the block
return x
操作的数量
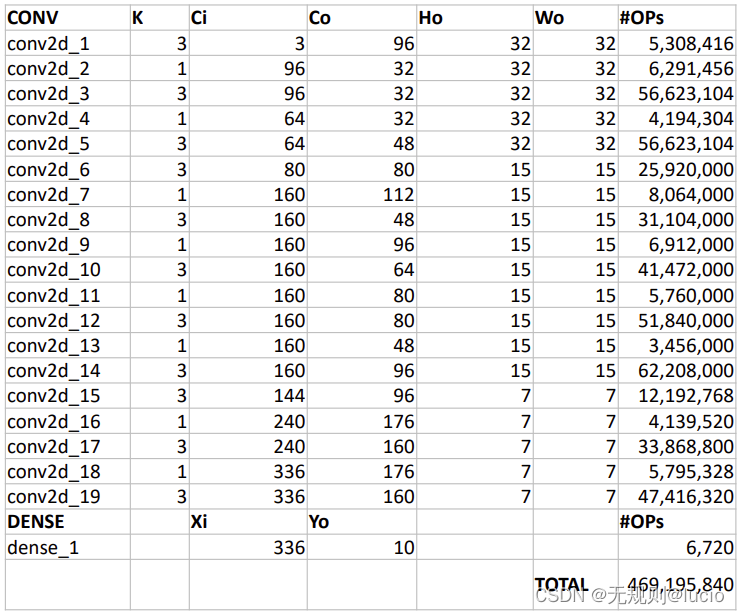
Conv2D
激活张量(activation tensor)可以存在片上存储器
参数(weight和biases)不能被存在片上存储器,已经占据了6.3MB。
- 但6.3MB已经超过了片上存储器的尺寸
- 每个批量从外部DRAM去获取参数,所耗能为:6.3 MB / 4B x 640 pJ = 1 mJ
操作数:469 MOPS (FP32)
一个带FPU的CPU在1GHz运行下,需要0.5s去运行推理(即两帧2 fps)。若想实现60帧,需要30个FPU并行运行。
所有操作的耗能为:
469 M x 0.5 x (3.1+0.9) pJ = 0.9 mJ
SeparableConv2D

所以当使用FP32时,从6.3MB降低到了1.3MB。这样就可以使得参数可以存储在片上存储器或者片外存储器中,都使得性能和能耗得到了极大的改善。
对比
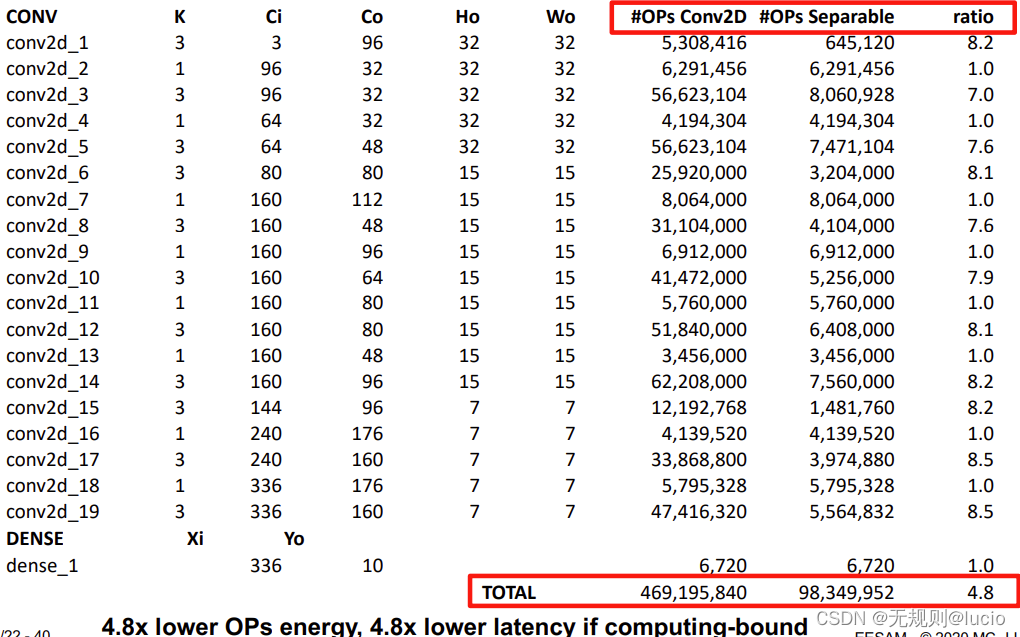
练习1
评估在Intel Movidius上的Shallownet和MiniGoogleNet的性能(latency和fps)
“Myria X ”片上系统有以下特征:
– 16 SHAVE processors, each with one 128-bit vector unit
– Clock frequency: 700 MHz
– On-die memory 2.5 MB, 450 GB/s access bandwidth
– DDR4 DRAM 4 Gbit @1600 MHz, 32 bit
答案
每个vector unit 吞吐量:128/32 = 4 OP / cycle(FP32)
吞吐量峰值: 16 x 4 OP/cycle x 0.7 GHz = 44.8 GOP/s
注意,片上存储器可以很好的存储激活并且足够快的速度维持最大吞吐量。
参数需要访问DDR,先了解DDR带宽:2 x 1.6 GHz x 4B = 12.8 GB/s
每字节操作数:
- 对于MiniGoogleNet:469M/6.3M = 74.4 OP/B
- 对于ShallowNet: 2.3M/1.25M = 1.84 OP/B
Movidius SOC可以全速运行MiniGoogleNet
Latency:#OPs / Th = 469 MOP / 44.8 GOP/s = 10.5 ms
– Frames per second:1 / 0.0105 = 95 fps
但是由于内存墙(memory wall)导致速度太快,Movidius SOC不能全速运行ShallowNet
– Latency: #OPs / Th = 2.3 MOP / 23.6 GOP/s = 0.1 ms
– Frames per second:: 1 / 0.1ms = 10 kfps